
 起点课堂会员权益
起点课堂会员权益Facebook 首席 AI 科学家图文演讲:如何让 AI 学习常识, AI 未来趋势又在何方

4 月 26日,GMIC 北京 2018 在北京国际会议中心召开,Facebook 首席 AI 科学家杨立昆( Yann LeCun)通过视频连线做了题为《AI 的最新技术趋势》的演讲。以下为演讲内容:
杨立昆:大家晚上好!我这边是晚上,你们那边应该是上午,非常抱歉我不能亲自到会场上来。我叫杨立昆,来自 Facebook 人工智能研究院以及纽约大学。今天我想讲一下关于深度学习的一些情况,同时也会提及深度学习的未来,以及我们所面临的关于深度学习方面的挑战,即如何让机器变得更加智能。
从监督学习开始
我们看一下今天的 AI 系统,如今所有的应用,不管是影像、声音或者是图像的识别,或者语言间的翻译等,这些内容 AI 都需要通过监督学习来获得。
比如说:向它展示一些车的图像,告诉它这些都是车,下次再向机器展示车的图像的话,它就会告诉你答案是车。所以你可以看到,监督学习,对于计算机的学习非常重要。

我们现在的有监督学习,或者说深度有监督学习,就是组合起来一些可以训练的模块,形成端到端的一个学习过程。一端是原始的输入,另一端就可以得到结果。通过这种方式,计算机会更好地了解我们的世界。
实际上这个想法可以回溯到上个世纪八十年代的时候,当时提出的卷积神经网络可以识别图像,同时也有很多其他的应用。比如:说可以用于语言处理和语言识别和其他很多的应用,这就是我们如今在使用的一些常见应用的模型雏形。
我们知道神经网络是非常庞大且复杂的,只有在算力很强的计算机上才可以运用。在深度学习变得普遍之前,我们需要确保机器学习的系统可以顺利应用。
比如说:我们在 2009 年、2010 年在纽约大学的一个合作项目,即利用 ConvNets 进行语义分割。我们可以看到:它能识别图像,能把马路上的建筑、天空以及路上的车和人等等在像素级别上分开。当时的识别技术还算不上非常完美。

但在几年后,我们可以看到有一些公司利用上述技术做了一些工作,系统可以识别出道路上的车辆和行人,这也是实现智能驾驶的重要组成部分。随着深度学习的发展、网络的深度越来越深,越来越多的人相信深度学习是可以奏效的。

大家可以看到几种常见的神经网络,比如 :VGG、GoogLeNet、ResNet 还有 DenseNet 等;比如说:有 100 层或者 180 层的一些人工神经网络。
像在 Facebook 中我们会广泛使用深度神经网络来识别图像。
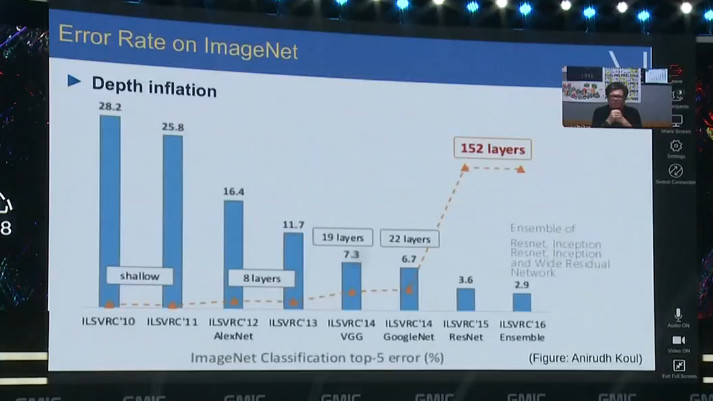
随着网络深度的不断增加,识别 ImageNet 图像的错误率也在不断下降,现在已经表现得比人还要好。在 ImageNet 上的表现已经太好了,以至我们现在都已经不再把它作为首选的评价标准了 。我们现在也在研究更复杂的问题,不只是识别图像,还要能够进行本地化处理。
Mask R-CNN 是我们在 Facebook 人工智能研究院所做的研究,可以看到它的表现非常好,不仅仅可以识别出对应的物体是什么,还可以对图像进行精细的分割,只是部分可见的东西都可以分得清。

大家可以看到:它可以识别电脑、酒杯、人、桌子,还可以统计它们的数量,而且也可以识别出道路、汽车等。
如果五年前让系统来解决这些问题的话,我们当时可能认为需要 10-20 年时间才能达到今天呈现的效果。这个模型也是我们开源的 Dectectron 物体检测平台的一部分,大家可以下载其中的代码,预训练好的模型可以检测 200 多种不同的类别。
Facebook 在 AI 方面做研究的方式是——我们不仅仅发布了一些论文,同时连代码也开源出来,这样的话全世界都能更好了解这些成果。
当然还包括其他很多项目,在 Facebook,我们利用这样的技术设计了 DensePose,它在一个单一的 GPU 上运行,可以预测密集人体姿态估计,而且系统能够实时运行。
这个系统可以追踪很多人的行为,生成视频,而且对姿势的判断也非常准确。此外,它可以实时地生成分片 3D 模型,相应的代码也是开源的。

当然利用这样的技术不仅仅可以进行图像识别,也可以进行面部识别,还能识别人的行动,甚至可以用来翻译。FairSeq 是 Facebook 在加州所做的研究,我们可以用我们的系统进行翻译工作。
在 Facebook 经常有各国语言,采用这种技术可以把一些文字从一种语言翻译到另外一种语言。
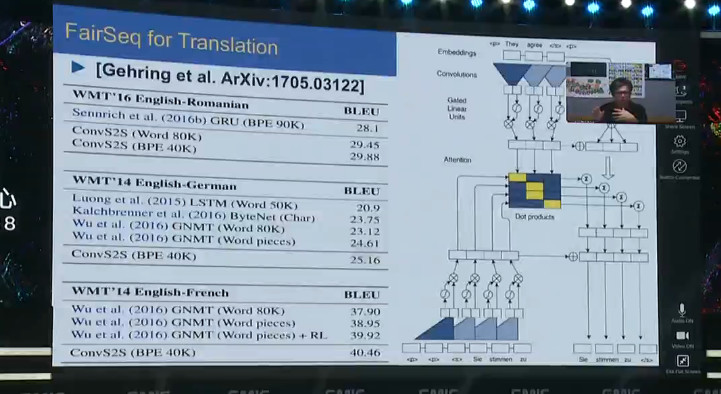
我觉得对于行业来说,进行这样的开发研究将是会是一个非常有用的过程。对于我们研究团队来说,不仅仅要开发对我们公司来说非常有用的技术,同时我们也希望所开发的技术能够引导整个社区,能够解决我们所感兴趣的问题。
我们认为 AI 不仅仅会帮助 Facebook 解决问题,同时还会帮助人类解决很多自己无法解决的挑战,所以我们会与我们的科学团队一起朝这方面努力。
以下是在过去的几年里, 所发布的一些开源项目,包括像深度学习网络、深度学习框架,还有关于深度学习的应用。

我刚才讲到:Facebook 每天都会有一些新的应用发布,比如:医学影像分析、自动驾驶、语言翻译等等,在科学方面也有很多应用。
我们也可以看到,深度学习的广泛应用会进一步推动科学方面的研究,在接下来几年里,我们会看到深度学习会发生更大的变革。

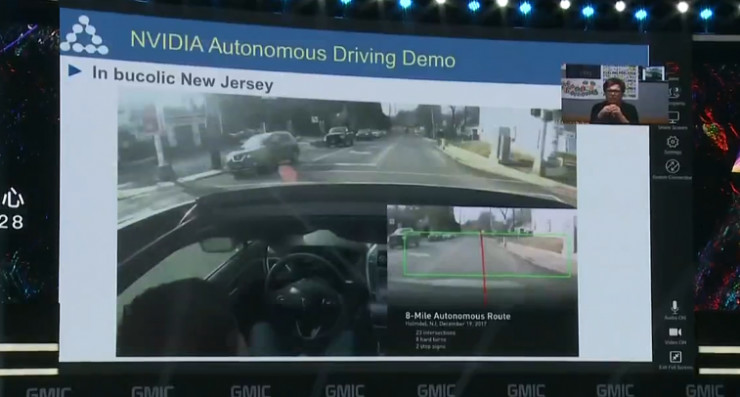
这是一个 NVIDIA 训练的自动驾驶的 demo 视频,它是用卷积网络做模仿学习。模仿人类驾车,它会识别摄像头拍到的路况,然后把结果映射为方向盘的角度,它可以在郊外的路上连续开几分钟而不需要人的干预。
可微分编程:深度学习与推理的联姻
我们再来看一下可微分编程。
实际上我们可以从另外一个角度来理解深度学习,深度学习并不是一定需要构建一个固定架构的神经网络然后训练,它也可以是写程序代码,但程序代码可以被解释为神经网络。这样的程序里会带有一些参数,然后可以通过训练来优化这些参数,这些参数的最终取值也就取决于训练数据。
当然了我们也需要写第二个程序,计算输入关于参数的导数的梯度,就可以往正确的方式调整这些参数的值了。这样动态改变了最终网络的结构,它也就可以适应不同的任务。这就是可微分编程。
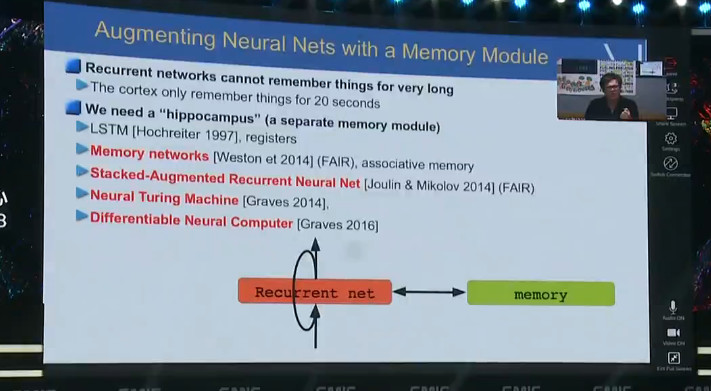
这是几年前所开展的一项典型的工作,Facebook 和纽约大学一起合作的,用记忆模块增强神经网络,网络的结构也就是动态的,这样的做法也会影响未来我们用什么样的工具开发神经网络。

这是另外一个关于动态计算的例子。如果你要建立一个系统能够回答复杂问题的话,比如:下面的这副图中,红色的立方体,是不是要比别的大一些?或者立方体有没有比某个颜色的东西更多?
这是几年前 Facebook 和斯坦福大学合作的研究,它的关键思想是:通过循环神经网络 LSTM 输入问题,问题会被编码成向量的形式,然后向量再被另一个网络解码,解码后的结果像是一种程序,程序解释后的结果是几个模块连接形成的计算图。这样最终我们就解答了这个问题。
比如:对于问题「立方体有没有比黄色的东西更多」,我们首先需要一个立方体的检测器,然后需要检测黄色东西的检测器,分别数出来都有多少,最后对比两个数字得到了结果。动态计算就可以端到端地训练出执行这样任务的程序,决定它的组成结构的也就是用来训练它的数据。

刚才看到的都是一些已经做到的深度学习成就,那么我们还需要看一下:距离达成「真正的 AI」我们还缺了什么?
现在我们已经可以构建出更安全的车辆或者说自动驾驶车辆,我们有更好的医学影像分析、还不错翻译软件、差不多能用的聊天机器人,但我们还做不出来有「常识」的机器人、做不出真正有智慧的个人助理、做不出可以替代洗碗机的管家机器人。
我们缺了一些重要的东西。
强化学习是我们缺的那块拼图吗?

有的人会说:答案就是强化学习。强化学习当然也很有力,但是它只能在游戏的、虚拟的环境里发挥。

玩 DOOM、下围棋,都没有问题,但是因为强化学习需要很多的尝试,AlphaGo 甚至自我对局了上百万局,这些都是现实世界里做不到的,所以强化学习并不适合解决现实生活中的问题。
玩 Atari 游戏需要上百个小时才能玩到人类玩几分钟的水平,学开车就更是要先撞坏很多车才能学会,现实世界里的尝试也没办法加速时间,这都是不可接受的。
所以确实我觉得人类和动物的那种学习方式,现在的机器并不具备。
机器需要学习常识

我们想想婴儿是怎么学习的呢?
比如:我们给婴儿看左上角的这张图,那个小车漂浮在空中,虽然没有下面没有任何支撑,但是并没有掉下来。不到 6 个月大的婴儿看到这张图片并不会觉得惊讶,但是更大的婴儿已经知道了没有东西支撑的话是会掉下来的,看到这张图片就会很惊讶,像左下角的图这样。
我的一位朋友,她是在巴黎工作,她给我们展示了婴儿在每个月分别能学会哪些概念,而且他们也能够了解到一些物理最基本的原理。这是他们在生命的最初几个月学到的一些概念,也就有假说认为这就是「常识」萌芽的时期。
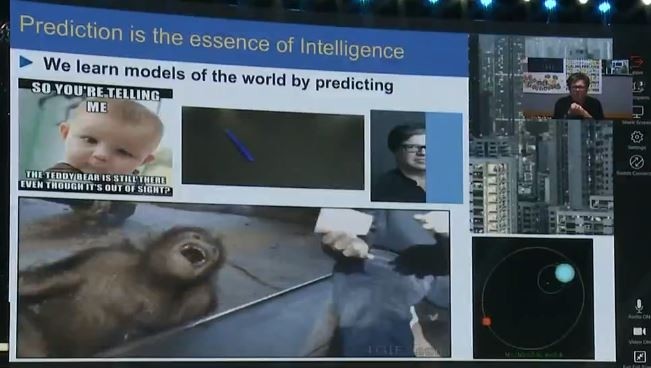
动物也有一定程度的常识,比如:这只幼年的猩猩,我们给它变了个魔术,在杯子里放了东西然后把它变没了。猩猩本来期待着东西还在里面的,当它看到不见了的时候就笑得躺在地上了,这只猩猩就对这个世界有着较为准确的认知模型。

那么我们需要做的,也就是让机器具备对这个世界的模型,我把这个称作「自我监督学习」或者「预测学习」。机器要尝试预测自己看到的东西的各个方面,这也可能就是能让机器像人类一样高效地学习的关键。

这种学习主要靠观察,没有监督,和世界只有很少的互动。它们除了接收,还要可以规划和行动,这正是构建自动化机器的关键。

所以不管下次的变革在哪个点,我觉得它都不会是监督学习,当然也不会是纯强化学习的。它应该会有某种自我监督或者无监督学习,而且也会在这样的变革当中出现一些常识性的学习。
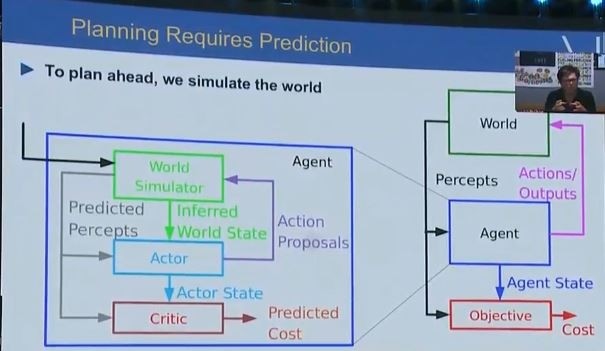
我总结一下:这也就是我们近期在 Facebook 做的预测学习,学习如何预测、推理以及计划,也就是学习「常识」。它的核心思想是——自动的智能机器人应当有一个内部的世界模型,可以在它做出行动之前自己进行模拟,预知自己的动作的结果。
这是一种最优控制中常见的方法,但在机器学习中就不那么常见了。这里我们遇到的问题也就是如何让人工智能学会对世界建模、从而用这个模型帮助自己规划现实世界中的行为。
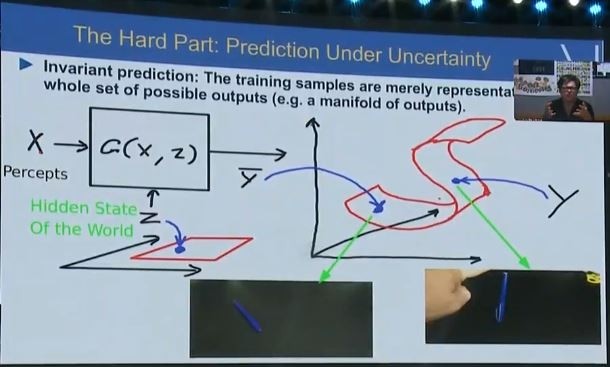
预测的时候还需要处理不确定性,在桌子上立一支笔,然后松手,它就会倒下来。我们只确定它会倒下来,但是不确定具体会倒向哪个方向。这种时候我们也就需要对抗性训练,训练模型不只给出一个答案,而是多个可能的答案。
这里需要两个模型:一个模型做预测,另一个模型来评判哪些结果还不错、哪些结果是现实世界不太可能发生的。做预测的模型也就要尝试让自己的预测越来越好,让做评判的模型分不清哪些是真的会发生的,哪些只是预测出的结果。

根据这样的思路,早几年的 GANs 就可以生成卧室的照片,今年 NVIDIA 也可以生成非常逼真的高清明星照片。
所以,对抗性训练也就是我们希望可以帮助建立预测机器的方法。预测应当是智慧的核心,我相信能训练出具有预测能力的模型也就能在未来几年中为我们带来大的进步。
AI 发展趋势的预测

我最后做一下总结:对于 AI 学术研究的趋势,监督学习和强化学习即便不会被取代,也会被自我监督学习和无监督学习大大地增强。学习具有预测能力的模型也会成为未来几年内的研究热点,这能让我们从无模型的强化学习来到基于模型的强化学习以及模仿学习,它们的效率都会提升很多,所需的尝试次数也会少很多。
另一件事是:让模型具有推理的能力,但同时还和深度学习是兼容的。就是让深度学习方法可以做符号表示方法可以做的事情,把符号换成了向量,把逻辑变成了可微分的程序操作。
目前的固定结构的网络会变成动态的、由数据决定的网络结构。这也会需要在计算方法方面有新的探索,从而成为系统性的问题。深度学习本身我认为也会有一些进化,它们操作的不再是数值或者高维向量,而是操作图结构之类的复杂数据结构,更多的深度学习理论也可能会出现。

在 AI 的技术应用方面,我认为监督学习会变少,更多的会是无监督特征学习、监督微调,这样可以在更多没有充足数据的场景下工作。比如:小语种的翻译,只有很少的双语对照语料。
我们也会看到新的深度学习框架出现,为动态网络提供编译器,PyTorch 就在尝试向这个方向发展。对于不同框架之间的可协作性,我们也和微软、亚马逊等公司一起合作设计了 ONNX。
让神经网络在移动、低功耗设备上做推理也有很多研究,这已经成为了一个非常重要的问题。对于 Facebook 这样的公司来说,每天用户要上传 20 亿张照片,而且每张照片都需要被一系列卷积网络识别,分析不同的信息。
这会消耗很多电力,尤其是想要拓展到处理视频等一些别的任务中的话,所以也就需要研究如何在低功耗设备上运行神经网络。现在手机上也已经出现了 GPU 之外的专用深度学习处理器。
感谢各位的倾听,我就讲这么多。谢谢。
作者:奕欣
来源:https://www.leiphone.com/news/201804/mlmeciEv6i0BGUxd.html
本文来源于人人都是产品经理合作媒体@雷锋网,作者@奕欣
题图来自 Pixabay,基于 CC0 协议






- 目前还没评论,等你发挥!


