
 起点课堂会员权益
起点课堂会员权益成为AI产品经理之前,可以先读下这篇文章

本文致力于让完全没有学习过AI的朋友可以轻松读懂,enjoy~
先说一下,你阅读本文可以得到什么。你能得到AI的理论知识框架;你能学习到如何成为一个AI产品经理并且了解到AI产品经理如何在工作中发挥作用,以及AI产品经理需要从哪些方面锻炼能力。最重要的是,通过本文,一切都特别快(手打滑稽)。
PS:目前只针对弱人工智能(我喜欢简称,此处我们简称为“弱智”)进行学习。

首先我们必须要掌握的是AI的专业知识框架,然后了解AI的市场情况,最后要明白AI产品经理的工作流程及在项目的价值体现。本文致力于让完全没有学习过AI的朋友可以轻松读懂,获取干货。即使你不能完整理解AI也没关系,最起码看完本文之后你可以完美装13,文末会有特别的装13技巧送给你。
一、AI是什么
1. AI的定义
凡是通过机器学习,实现机器替代人力的技术,就是AI。机器学习是什么呢?机器学习是由AI科学家研发的算法模型,通过数据灌输,学习数据中的规律并总结,即模型内自动生成能表达(输入、输出)数据之间映射关系的特定算法。这整个过程就是机器学习。
AI模型是个“中间件”,不能直接与用户完成交互,所以AI还是需要借助传统的应用程序,应用程序直接与用户进行交互,同时提交输入数据给模型,模型处理后返回输出数据给应用程序,应用程序再转化为合适的呈现方式反馈给用户。
AI解决方案比互联网解决方案有什么优势:再也不需要去归纳总结知识和规律,然后进行越来越复杂的编程,只需要用数据喂养机器,让机器完成所有工作。而且传统的互联网解决方案遇到需要求变时,是个头痛的事,因为直接让工程师对程序、算法进行修改的过程中会需要考虑很多既有程序带来的限制及改动后的未知风险(同时也容易造成人力成本更高),而AI模型是可以迁移、叠加利用的,所以需求变化时,少了很多既有积累的东西带来的问题。
2. AI的根基
AI的根基从数学理论开始,数学理论(包括:线性代数、概率论、统计学、微积分)的基础上我们得以有机器学习理论,机器学习理论(包括:监督学习、无监督学习、强化学习、迁移学习、深度学习)的基础上我们得以有基础技术,基础技术(包括:机器学习ML、深度学习DL、语音识别ASR、语音合成TTS、计算机视觉CV、机器视觉MV、自然语言理解NLU、自然语言处理NLP、专家系统)的基础上AI应用得以实现。
特别提醒:不仅是数学理论,物理理论也是AI的根基。在更深度的AI建模等理论需求中,很多所谓的“数学理论”其实原型来自于“物理理论”。比如熵的概念,比如多维空间的概念,都是出于物理学中的概念。
3. 机器学习理论详解及算法模型介绍
关于模型算法的结果导向理解:
- 对数据进行分类;
- 找到输入数据与输出数据之间的规律。
机器学习方式有多种,每种机器学习方式又有多种算法。机器学习方式可以配合利用,且各种算法模型也可以结合利用。
机器学习的抽象流程是:
- 训练机器阶段,让模型对输入数据进行分类,且找到规律;
- 测试阶段,数据进入模型时,模型对数据进行分类,每一个测试数据都归类到训练数据类别中对应的一个类别,然后根据训练找到的规律计算出输出值(即答案);
- 欠拟合或者过拟合的情况下,要清洗训练数据、调整参数以及重复训练;达到最佳拟合后,机器学习完成。
3.1 监督学习
通俗解释:准备好许多组问题和对应答案,然后对机器说:当你看到这个问题的时候,你就告诉人家这个答案。多次重复这样的训练,然后机器从每一次的训练问题和对应答案中找到了其中的规律(即算法)。然后你跟你朋友吹嘘说,我的机器机灵得跟猴似的,不信你问它问题。你这位朋友开始提一大堆问题,提的问题大可以跟你训练的问题不同,机器人只是根据自己之前总结的规律推测出答案给对方。如果发现机器人说出的答案中错误太多,那你就要修理修理它,再重新用更丰富的有标记答案的问题训练一番,直到你的机器被人提问时回答准确率特别高,达到你的期望了。这时候你就可以放心的跟你朋友炫耀:我的机器机灵得跟猴似的。
专业解释:准备样本(样本通常准备两组:训练数据和测试数据),先将训练数据(即标记样本)给到机器,同时提供标准答案(有答案的样本数据属于“标记样本”),机器尽量从训练数据中找到因变量和自变量之间的关系,让自己推测的答案尽量跟标准答案靠近。训练过程中机器尝试生成我们需要的算法,这个算法就是我们要机器学习出来的结果。然后我们给机器测试样本(测试数据),不提供标准答案,看机器推理出答案的准确率怎么样,如果准确率太低(欠拟合),那我们就要调整模型的参数,并且再训练机器,接着又用测试数据测试,直到机器达到了我们期望的准确率。
抽象一个最简单的逻辑公式:线性代数y=kx。我们提供n组x值及对应y值作为训练数据,模型经过计算推测出k值(推测出k值这个过程我们叫做“回归”),然后我们再用m组测试数据,但是此时只输入x值,看机器得出的y值是否跟我们已知的正确答案y值是否相同。当有多个纬度的特征时,应该抽象公式应该是y=kx1+kx2+kx3,或者y=k1x1+k2x2+k3x3。当然还有可能要考虑其他一些参数,此时公式应该为y=kx1+kx2+kx3+b,或y=k1x1+k2x2+k3x3+b。参数b是我们的AI工程师可以直接调整的,以便让机器训练的结果最接近我们想要的结果。
监督学习的算法分类:
(1)KNN临近算法
在训练阶段时,机器将训练数据进行分类(根据数据的feature,即数据的特征)。(逻辑推理出,在某些情况下模型可以找出来的数据之间的映射不止一条,即可能每一类数据会有一个映射关系。)当测试数据输入时,机器会根据输入数据的特征判断该输入数据跟哪一类的训练数据为同一类,在此判断基础上,机器便决定用哪一个映射关系来推测当下输入测试数据对应的输出数据(即答案)。机器是如何判断测试时的输入数据更接近哪一类训练数据的呢?用数学逻辑解释就是,模型内是一个多维空间,有一个多维坐标,每一纬是一个特征,当一个训练数据输入时,该数据坐落在坐标上某一点,训练数据量大了之后,模型里的坐标上有无数点。当测试数据输入后,根据测试数据的特征在坐标上为它找到一个点,机器会找与该点欧式距离最近的点(训练数据的点)是哪一个,并且将该点视为与找到的距离最近的训练数据的点为同一类。
举个栗子:Mary喜欢玩探探,在她眼里,探探里的男银分3类。第一类是不喜欢,左划;第二类是喜欢,右划;第三类是超级喜欢,点星星。第一类男银的共同点是单眼皮、低鼻梁、秃顶、穿安踏;第二类的共同点是双眼皮、高鼻梁、茂密的头发,穿西装;第三类的共同点是带名牌手表,照片旁边有一辆跑车。AI了解Mary后,开始为Mary把关。当AI看到一个男银上探探,就会看这个男银是否单眼皮,鼻梁接近于高还是低,头发多少,着装幼稚还是成熟,然后将这个男银为第一类或者第二类,第一类的直接帮Mary划掉,第二类的直接帮Mary点喜欢。还有,当AI看到一个男银带名牌表,有豪车,直接帮Mary点一个超级喜欢。然后Mary不用那么累地全部都要点一遍,AI帮她选的人她都挺满意,她一脸的满足。
(2)决策树ID3算法
基于“决策树”的理论的一种算法。根据数据特征进行分支,直到不可再分支,此时决策树成形,数据也被分出一类来,成形的一个决策树表现了这一类数据的所有特征。
示意图(Jennifer去相亲):
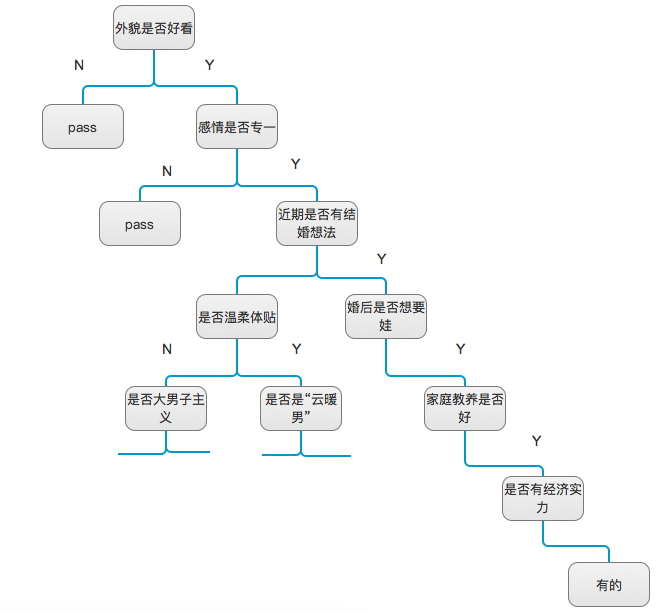
该决策树形成后(一条分枝将特征消化完之后),我们视满足该条分枝上所有特征的为同一类人(即我们分出了一类数据)。凭经验推测,这类人就是Jennifer最后选择的结婚对象。(如果你不知道我指的是哪一条,那你这辈子一定都找不到老婆)
决策树ID3算法与KNN算法的区别在于:KNN算法需要始终保存并持续使用所有训练数据,决策树ID3算法完成决策树之后,可以不再保存所有的训练数据了(可以清清内存),只需要将决策树模型保留下来,便可以对新数据进行高准确率地分类。
(3)logistic逻辑回归算法
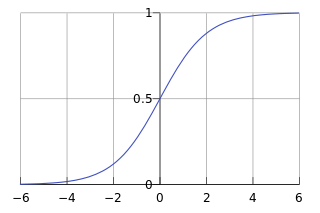
当特征和结果不满足线性时(函数大于一次方时),就可以用逻辑回归算法。逻辑回归是一个非线性模型,它的因变量(x)跟线性回归函数不相同。逻辑回归同样用来解决分类问题,呈二项分布(示意图1),它只输出两种结果,0或1(实际情况是输出为0~0.5,或0.5~1,小于0.5取值0,大于等于0.5取值1),0和1分别代表两个类别。作为产品经理,我们不需要去理解模型内部是怎么回事(反正我目前也没看懂模型内部到底怎么回事),我们只需要了解,当特征和结果,即X与Y之间的关系不满足线性关系(函数大于一次方),就可以利用逻辑回归算法,算法得出的值约等于1或约等于0,约等于1时该输入数据属于一类,约等于0时该输入数据属于另一类。或许以后在实战中,你的AI工程师搭档会跟你讲解,看了这篇文章,你在听你的AI工程师解释的时候不会茫然吧。
逻辑回归的基础公式:
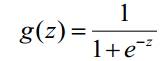
示意图1:
(4)支持向量机SVM
主要优势就是可以判断到分类是否正确。
先给大家举一个例,当我们要分割一个平面,会用一条线,即分割二维数据用一维数据;如果我们要分割一个立体空间,会用一个面,即分割三维数据用二维数据。理解例子后,就可以理解SVM的原理了。
SVM的原理就是用一个N-1维的“分割超平面”线性分开N维空间,而所有数据都在这个空间内各为一点。每一次分割超平面开始切分,都在将空间内的数据分为两部分(假设为A、B两边),模型的目的就是让分出来的两部分数据是两个类别,我们要理解在A这边的每个数据点到分割超平面的距离为正值,那么另一边(B那边)的数据点到分割超平面的距离就一定为负值(我们把分割超平面看作是临界面吧,或者看作是“海平面”,两边的点朝着临界面直线出发时,方向是相对的,这样解释大家就能明白为什么说一边为正值另一边就为负值了)。
当模型计算所有特征相同的数据各自到分割超平面的距离时,若都为正值(我们默认这些特征相同的数据所占边是A边),那么分割正确,我们就知道空间内所有数据被准确无误地分为两类了。若发现有出现负值的,那一定是有至少一个数据站错边了,换一种说法是我们这个分割超平面分割得不对,分割超平面就会重新分割,直到分割完全正确。因为理论上讲,分割超平面是一个多维空间的任意维度的“面”,它可以在数据任何分布的情况下都刚好把不同类(不同特征)的数据一分为二,保证它的分割不会让任意一个数据“站错边”。
借用几张经典示意图帮助理解:
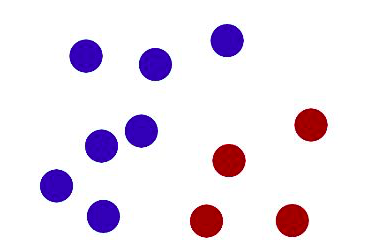
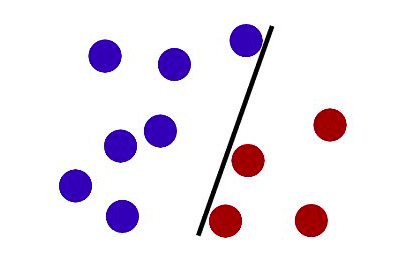
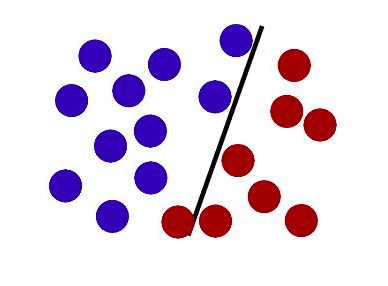
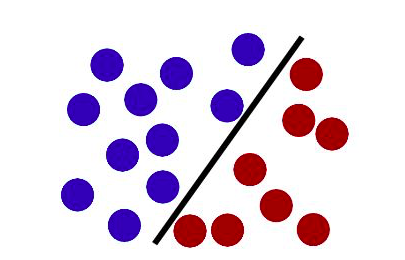
这只是一个简单示意图,但是我们要发挥空间想象力,如果不能看起来是一条直线分割两边,那就让看起来是一条曲线的分割超平面分割两边,但是这条曲线其实不是曲线,它是一个多维面。(这个多维空间真的烧脑,我记得网上有个很经典的10分钟理解多维空间的视频,大家可以去搜一搜)
(5)朴素贝叶斯分类算法
首先说明一点:KNN算法、决策树ID3算法、logistic回归算法、SVM都是属于判别方法,而朴素贝叶斯算法是属于生成方法。朴素贝叶斯算法的逻辑是:每一个训练数据输入时,计算该数据被分到每一个类别的概率,最后视概率最大的那一个为该输入数据的类别。跟逻辑回归一样,作为产品经理,大家只要记住宏观逻辑就好了(手打调皮)。
公式:
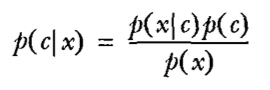
3.2 无监督学习
通俗解释:你准备一大堆问题丢给你的机器,每一个问题都不告诉它答案,叫它自己把问题分类了。它开始识别所有问题分别都是什么特征,然后开始将这些问题分类,比如A类、B类、C类。分类好了之后,你又对你朋友炫耀:我的机器机灵得跟猴似的,不信你问它问题。然后你朋友问它: “女朋友说自己感冒了应该怎么回复她?”机器想了想,发现这个问题跟自己归类的A类问题一样,于是它就随口用A类问题里的一个代表性问题作为回答:“女朋友说自己大姨妈来了该怎么回复,你就怎么回复。”你的朋友觉得机器是理解了他的问题,但是他还是不知道该怎么回复女朋友啊,失望的走了。这个时候你发现你的机器回答方式不好呀,于是你告诉机器,不要用问题回答问题,你顺便给了他的A类问题一个统一答案,就是“多喝热水”。然后你叫你朋友再问一次机器,你朋友又来问了一次机器:“女朋友说自己感冒了我该怎么回复。”机器马上回答:“叫她多喝热水呀。”你朋友一听,恍然大悟,开开心心地走了。
专业解释:机器学习是否有监督,就看训练时输入的数据是否有标签(标签即标注输入数据对应的答案)。无监督学习即训练时输入数据无标签,无监督学习利用聚类算法。无监督学习不利用“回归”方式找到规律。其他的跟监督学习基本相同。
(1)K-聚类(聚类算法)
K-means聚类是一种矢量量化的方法,给定一组向量,K-means算法将这些数据组织成k个子集,使得每个向量属于最近的均值所在的子集。在特征学习中,K-means算法可以将一些没有标签的输入数据进行聚类,然后使每个类别的“质心”来生成新的特征。
换种说法就是:K个子集中每个子集都计算出一个均值,每个均值在空间里都为一个“质心”,根据输入数据的特征及特征值为它找到一个点,这个点最接近哪个“质心”,我们就视该数据属于哪个子集,即与该子集所有数据为同一类。
(2)主成分分析法
容我偷个懒,这个我自己还未真正学习懂,所以就不写了,后面出现未具体解释的东西都是我还未学习明白的内容。争取只写我真正自己学懂的东西,怕未完全明白的基础上写的东西容易出现误导。但是我会在接下来的学习中把余下的AI知识都学好,并尽量再发文跟大家分享。
3.3 半监督学习
半监督学习其实就是监督学习和非监督学习的方法合并利用,训练数据有一部分是有标签的,有一部分是无标签的,通常无标签的数据量比有标签的数据量大很多。
半监督学习的好处是:
- 降低打标签的人工成本的情况下让模型可以得到很好的优化;
- 大量的没办法打标签的数据得以被利用起来,保证训练数据的量,从而让训练结果更佳。
狭义上【半监督学习】要分为transductive SVM、inductive SVM、Co-training、label propagation;我们可以尝试用另外一种方法分类【半监督学习】,即“分类半监督”、“聚类半监督”。
- 分类半监督--举例说明就是先用标签数据进行训练,然后加入无标签数据训练,无标签数据输入时,会根据数据特征及特征值,看该数据与有标签数据分类中哪一类更接近(支持向量机SVM的方法就可以帮助找到最接近哪一类),就视为该类数据;或者是,看该数据与有标签数据哪一个最接近(KNN的方法就可以找到最接近的那个数据),则把该无标签数据替换为该标签数据。
- 聚类半监督–通常是在有标签数据的“标签不确定”的情况下利用(比如这个输入数据的答案可能是xxx),“聚类半监督”就是重点先完成数据的分类,然后尝试根据标签数据训练提供的标签预测结果。
- S3VM算法
- S4VM算法
- CS4VM算法
- TSVM算法
3.4 强化学习
通俗解释:你准备一大堆问题,每个问题有多个答案选项,其中只有一个选项是正确答案。手里拿着皮鞭,让你的机器一个个问题的从选项里挑答案回答,回答正确了,你就温柔的默默它的头,回答错误了,你就抽它丫的。所有问题都回答完了之后,再重复一次所有问题。然后你就发现,你的机器每一次重复,正确率都提高一些,直到最后正确率达到你的期望值了,这时候机器基本也从抚摸和抽打中找到了每一个问题的正确答案。机器通过一次次去猜测问题和答案之间的规律(即算法),一次次更新规律,最后也找到了最准确那条规律(最佳算法),这时,它机灵得跟猴一样。(当然实际过程里,只需要奖励机制就够了,但是你想同时给惩罚机制,也可以的。)
专业解释:我自己的理解,把强化学习理论分一和二,其中一是完全按照马尔科夫决策过程的理论,需要理解环境,在每一步动作时都得到一个反馈并计算下一步该怎么动作更好;二是不需要理解环境,只需要在执行完之后接收环境反馈的信号,然后它才明白之前的动作好不好,下次会坚持或改变同样情况下要执行的动作。
(1)强化学习理论一
agent(下文会讲agent是什么,此处可以理解为机器本身)需要理解环境、分析环境,并且要推测出完成一个动作得到奖励的概率。该理论完全满足马尔科夫决策。马尔可夫的核心:在一个状态下,可以采取一些动作,每一个动作都有一个“转化状态”且可以得出对应“转化状态”的概率(或该“转化状态”能获取奖励的概率)。而强化学习的目标就是学习怎样让每一次行动都是为了达到最有价值的“转化状态”上。
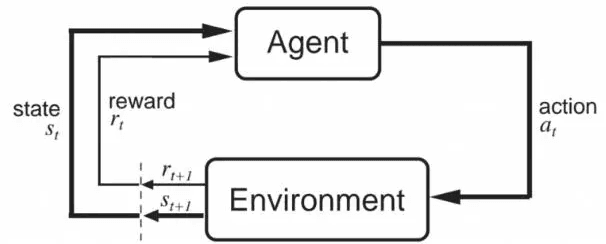
- model based(算法:Qleaning, Sarsa, Policy Gradients):理解真实环境,建立一个模拟环境的模型,有想象能力,根据想象预判结果,最后选择想象中结果最好的那一种作为参考进行下一步。
- policy based(算法:Policy Gradients, Actor-critic):通过感官分析环境,推测出下一步要进行的各种动作的概率,取概率最大的作为实际行动的参考。
- value based(算法:Qleaning, Sarsa):推测出所有动作的价值,根据价值最高的作为实际动作的参考。
- On policy(算法:Sarsa, Sarsa lambda):必须亲自参与
- Off policy(算法:Qleaning, Deep-Q-Network):可亲自参与;也可以不亲自参与,通过观看其他人或机器,对其他人或机器进行模仿。
(2)强化学习理论二
agent不需要理解环境、分析环境时,做出决策,该决策正确时奖励,错误时不奖励或惩罚。agent不会在动作时去计算是否得到奖励的概率。
强化学习中的4个要素:agent(一个智能体,可以为一个算法模型,或直接理解成机器本身)、environment(环境,环境对于agent是独立的,它可以是一个硬件设备、强化学习之外的某种机器学习模型等,它的任务就是当action结束后用它的方式给agent一个信号)、action(动作)、reward(奖励)。
agent能够执行多种action,但它每次只能选择一个action来执行,agent任意执一个action来改变当前状态,一个action被执行后,environment会通过观测得出一个observation,这个observation会被agent接收,同时会出现一个reward也会被agent接收(这个reward也来自于environment,environment可以通过推测或直接判断action结束时达到的效果是否是AI工程师想要的效果来决定这个reward是正值还是负值,当然负值相当于是“惩罚”了)。
agent在执行action时并不会知道结果会怎样,当agent接收到environment的observation时,agent仍然是一无所知的(因为agent不理解environment),但由于environment同时反馈reward,agent才知道执行的action好还是不好。agent会记住这次reward是正值还是负值,以后的action都会参考这次记忆。强化学习理论二对比一的区别就是:二并非在每一步都计算一个概率(所以二并非完全符合马尔科夫决策)。
- model free(算法:Qleaning, Sarsa, Policy Gradients):不理解环境,等待环境反馈,根据反馈进行下一步。
- Monte-carlo update(算法:Policy Gradients, Monte-carlo leaning):等待所有过程结束,事后总结所有转折点
- Temporal difference update(算法:Qleaning, Sarsa):过程中每一步都总结一下
- On policy(算法:Sarsa, Sarsa lambda):必须亲自参与
- Off policy(算法:Qleaning, Deep-Q-Network):可亲自参与;也可以不亲自参与,通过观看其他人或机器,对其他人或机器进行模仿。
强化学习不纠结于找出一条规律/算法,它只关心结果输出时能否得到奖励。之前提到的机器学习都是解决分类问题,而强化学习是解决“决策”问题。
3.5 迁移学习
通俗解释:当你的机器用以上几种方式中任何一种方式学习完之后,你叫你的机器把学习后找到的规律(算法)写在它的笔记本上。然后换一种学习方式,让它继续学习,叫它用第二种方法学习的时候要看笔记本,把新学到的知识也写上去,但是不能跟原笔记冲突,也不能修改原笔记。连续用多种方法让你的机器学习,它肯定比猴更机灵。
专业解释:将一个已经开发过的任务模型(源域)重复利用,作为第二个任务模型(目标域)的起点。深度学习中会经常用到迁移学习,迁移时(复用时),可以全部使用或部分使用第一个模型(源任务模型),当然这取决于第一个模型的建模逻辑是否允许。迁移学习是特别好的降低(获取样本数据、打标签)成本的方法。
(1)样本迁移法
看看目标域的样本数据跟源域中训练数据哪部分相似,把目标域中这部分样本数据的特征值照着相似的源域中的样本数据的特征值调整,尽量调到一样,然后再把调过的数据权重值提高。这个方法是最简单的迁移学习方法,不过人工去调,如果经验不足,容易造成极大误差。
(2)特征迁移法
找到源域同目标域的数据中的共同特征,将这些共同特征的数据都放到同一个坐标空间里,形成一个数据分布。这样就可以得到一个数据量更大且更优质的模型空间。(之前提到很多模型算法对输入数据分类时都要依靠模型里虚拟的空间,这个空间的质量越好,分类效果越好)。
(3)模型迁移法
源域的整个模型都迁移到目标域。最完整的迁移,但是可能会因为源域模型的特有的那些对目标域来说没有的数据、特征、特征值等,在目标域中反而会有干扰效果(类似与“过拟合”)。
(4)关系迁移法
当两个域相似时,可以直接将源域的逻辑网络关系在目标域中进行应用。比如我们将人的大脑神经网络的逻辑关系迁移到AI神经网络中,因为从逻辑上这两者我们觉得是一样的。
3.6 深度学习
深度学习可以理解为是多个简单模型组合起来,实现多层神经网络,每层神经网络(也可以叫做神经元)处理一次数据,然后传递到下一层继续处理。这种多层的结构比起浅层学习的模型优势在于,可以提取出数据特征(无需人工提取)。“深度”并没有绝对的定义,语音识别的模型中4层神经网络就算深了,但在图像识别的模型中,20层也不算很深。
(1)DNN深度神经网络
深度神经网络是深度学习最基础的神经网络。有很多层(每一层为一个神经元)从上往下排列,每一个层相互连接。有个缺点就是,正因为每一层之间连接起来,出现了参数数量膨胀问题(因为每一层涉及到一个算法,每一个算法都有自己的各种参数),这样的情况下容易过拟合(实现了局部最佳但整体拟合不佳)。
(2)CNN卷积神经网络
卷积神经网络有“卷积核”,这个“卷积核”可以作为介质连接神经元,用“卷积核”连接神经元时就不需要每一层都连接了。
(3)RNN循环神经网络
因为DNN还有一个缺点,无法对时间序列上发生的变化进行建模,如果在语音识别、自然语言处理等应用中使用AI模型时,数据的时间顺序影响很大。所以RNN就出现了,RNN能弥补DNN的缺点,可以在时间序列上发生的变化进行建模。
4. 重要的关键词解释
4.1 拟合
拟合是用来形容训练结束后效果好坏的。
(1)欠拟合
当训练数据少、数据质量差的时候,训练出来的模型质量就差(或者说损失函数过大),这时进行测试的时候,就会出现误差大,即“欠拟合”状况。
(2)过拟合
在训练阶段,反复用同样的训练数据进行训练,可以让训练效果变得更好(损失函数小),但同时机器会因为要达到最好的训练效果,将训练数据中不重要的特征或只有训练数据才有的某些特征进行利用得太重或开始学习不需要的细节,也就是说机器对训练数据太过依赖,最后就会出现在训练数据上表现特别好,但在其他数据上表现不佳。这样的情况叫做“过拟合“。
(3)最佳拟合
欠拟合、过拟合都不是我们需要的。我们要的是最佳拟合。所以我们在训练机器时要注意平衡。最佳点在哪里呢?最佳点在训练的损失函数还在减小,而测试的损失函数在减小之后突然开始增大的该点上。此时我们就达到了“最佳拟合”。
4.2 泛化性
训练好的模型在其他数据上的表现好坏用泛化性形容。在其他数据上表现越好,泛化性越高。
4.3 损失函数
用于评估“不准确”的程度,它是衡量模型估算值和真实值差距的标准。损失函数(loss)越小,则模型的估算值和真实值的差距越小,通常情况下我们要把loss降到最低。
4.4 香农熵
形容信息量大小。机器学习中重要是用于衡量特征的数量多少。一个数据的特征越多,说明我们可以从这个数据中获得的信息越多,也就可以说香农熵高。顺便提一下,决策树的生成过程,就是降低香农熵的过程。
4.5 标签
指给数据标记的答案。标记好答案的数据叫做“标签数据”。
4.6 特征值
特征(feature)的值。比如房子有特征(feature):空间、价格。它的特征值:(空间)200平方米、(价格)1500万。一般在机器学习的监督学习中,我们需要对训练数据进行特征提取的处理,即标记好每个数据有哪些特征和对应特征值。
当特征值损失的情况:
在实际的机器学习过程中,有时候会发生数据缺失的问题,比如一个数据有X个特征,但是由于意外发生,我们只得到部分(小于X)特征的值,在这种情况下,为了不浪费整个样本资源,且可以顺利的继续机器学习,我们需要有一些弥补措施:
- 认为设置某些特征的特征值(根据经验),然后利用;
- 找到相似的另一组样本,用另一组样本的特征平均值代替缺失的特征值;
- 用其他的机器学习模型专门针对缺失的特征值进行学习然后利用该模型找出缺失特征值;
- 使用已有特征值的均值来替代未知特征值;
- 在机器学习过程中用一些方法,让机器忽略已缺失特征值的数据。
4.7 类别
物以类聚人以群分,特征相同的数据就是同一类别。机器学习中特别重要的一个步骤就是利用算法将数据分类(学习算法里边会提到多种实现数据分类的算法),机器会尽量将所有输入数据进行分类,分类的逻辑就是通过数据的“特征”,特征接近的数据会被机器认为是同一类别的数据。
4.8 分类&聚类
分类是目前最简单也是效果最好的一类算法(比如KNN、决策树ID3、logistic回归、SVM等都属于分类算法)。分类算法的前提条件是训练数据必须带有标签。
聚类是目前相对分类更复杂同时效果更差的一类算法(无监督学习就是用聚类算法)。聚类算法的优势是可以训练数据不需要标签。表面上看来分类算法比聚类算法好用很多,那我们还要用聚类算法的理由是什么呢?其实,在实际情况下,训练机器时,要给数据打标签是个人工消耗极大的工作,不仅工作量大,很多时候对数据打准确的标签难度也大。
4.9 决策树
根据数据的特征值对数据进行不断分支,直到不可再分支(附 决策树形象图)。决策树的每一次对数据分支,就消耗一个特征值。当所有特征值消耗完后,决策树成形。决策树的每一个节点,即每一次对特征分支时,通常以yes/no的判断形式进行划分(所以才叫“决策树”嘛)。
决策树帮助机器对数据进行分类(根据特征,决策树的分裂点即特征分别点),决策树形成后,满足一条分枝上所有分裂点条件的为同一类数据。要注意的是,有时候决策树分枝太长,会导致过拟合。因为决策树很可能把训练数据中不太有代表性的特征放在分裂点上,这样形成的决策树不适应与训练数据之外的数据了。如果出现这种情况,需要“剪枝”,枝越长,说明模型可能越依赖训练数据,在枝的长短上,要做一个平衡,平衡的原则请参考本文提到的“欠拟合”与“过拟合”的关键词解释。
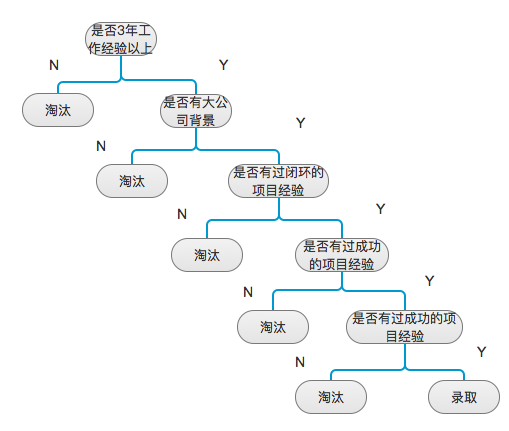
我们用最简单的决策树二叉树抽象示意图来表达我们招聘产品经理时的一个面试判断过程:
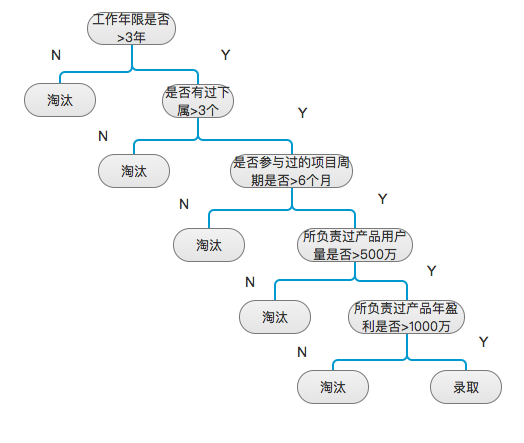
有时候分裂点上有数值判断,这些数值都叫做“阈值”。在决策树中,对阈值的使用越合理,训练形成的决策树效果越好,用在数据上越精确。请查看简化决策树示意图2:
4.10 知识图谱
知识图谱是模拟物理世界的实物与实物之间的关系,知识图谱呈现为无限扩散的类网状结构。它的结构组成为“实体”–“关系”–“实体”,以及“实体”–“属性”–“值”。知识图谱使得AI找到一个信息时,同时也获得了更多跟跟这个信息相关的其他信息。希望大家可以具体去看知识图谱相关书籍,该知识还是相对容易看明白的。
知识图谱简化示意图:
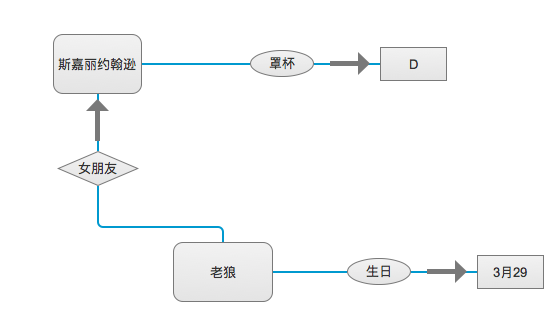
其中“老狼–女朋友–斯嘉丽约翰逊”,就是实体–关系–实体,“老狼–生日–3月29”和“斯嘉丽约翰逊–罩杯–D”就是实体–属性–值。举一个利用知识图谱的常见栗子:当有人问AI:“老狼有女朋友吗?”AI有自然语言处理的支撑,就可以识别到这个人在向它提问,且在询问老狼的女朋友这件事。同时有知识图谱的支撑,AI就可以准确回答:“老狼有个叫斯嘉丽约翰逊的女朋友,是个D罩杯的美女呢。”
5. 基础技术
5.1 语音识别(ASR)
一句话定义就是:将人类声音转化成文字的过程。
按识别范围分类为“封闭域识别”和“开放域识别”。
- 封闭域识别:在预先指定的字/词集合内进行识别。如此可将声学模型和语音模型进行剪裁,识别引擎的计算量也变低。可以将引擎封装于嵌入式芯片或本地化SDK,脱离云端,且不会影响识别率;
- 开放域识别:在整个语言大集合中识别。引擎计算量大,直接封装到嵌入式芯片或本地SDK中,耗能高且识别效果差,所以一般都只以云端形式提供。(更详细的介绍可看文末分享的脑图)
5.2 计算机视觉(CV)
一句话定义:计算机对生物视觉的模拟。通过采集图片、视频进行处理,以获取相应场景的三维信息。
计算机视觉的三步骤为成像、早期视觉、识别理解。其中成像原理跟相机原理相同,成像质量受光照影响、模糊、噪声、分辨率的影响,我们需要去找到好的方法来解决光照、模糊等问题。早期视觉又有图像分割(将特定影像分割成“区域内部属性一致”而“区域间不一致”的技术)、边缘求取(找到图像中的亮度变化剧烈的像素点构成的集合,即找出轮廓)、运动及深度估计三种方法。识别理解是最后一步,即把一张图片对应到一个文字或标签(根据机器找到的映射关系得出输出)。
计算机视觉的三种应用介绍:人脸识别、多目标跟踪、光学符号识别。
- 人脸识别的技术流程:人脸采集–人脸检测–图像预处理–特征提取–人脸匹配与识别。在实际流程当中,每一个环节都有对应的注意事项,详情请看老狼在文末准备的脑图。
- 多目标追踪的技术流程:图像采集–图像预处理–基于深度学习的多目标检测识别–多目标跟踪–输出结果。在实际流程当中,每一个环节都有对应的注意事项,详情请看老狼在文末准备的脑图。
- 光学符号识别的技术流程:图像采集–图像预处理–特征提取–文字定位–光学识别。在实际流程当中,每一个环节都有对应的注意事项,详情请看老狼在文末准备的脑图。
5.3 自然语言处理(NLP)
一句话定义:自然语言处理(NLP)是指机器理解并解释人类写作、说话方式的能力。
NLP又包含NLU(自然语言理解)、NLG(自然语言生成)。自然语言处理中最重要的3个环节是分词、锁定关键词、文本相似度计算。因为目前机器的语言识别其实都是基于对词的识别,任何句子进行自然语言处理时第一步都是要分词,比如:“我是产品经理”,分词后变成“我-是-产品-经理”。分词之后,要找到“关键词”,“关键词”是提供重要信息、最多信息的词,比如在“我是产品经理”句子被分词后,机器会选择“产品”、“经理”为该句子“关键词”。文本相似度有欧氏距离、曼哈顿距离等算法,详情看老狼的脑图。
6. 技术分层
从技术实现的效果的角度将AI技术进行分层:
- 认知,通过收集、解析信息对世界和环境进行认知。包括图片处理技术、语音识别、自然语言识别技术。
- 预测行为和结果。比如在用户行为研究的基础上根据对用户当前行为的识别,预测用户下一步想做什么,然后主动满足用户。
- 确定实现的方式和路径。比如AI代替医生给病人看病,得出病症和治病方案。
7. AI的常用语言及框架
市场上有的AI框架包括TensorFlow、Caffe、Torch、Theano等等,目前大部分工程师利用的是Tensorflow。AI编程可以利用多种计算机语言,目前最常用的是C++和python。
想要实操练习的小伙伴,到Google官方网站,按照官方的教程安装TensorFlow,安装好之后,你就可以用它提供的多个API来训练机器学习模型了。
8. AI的价值
互联网的价值在于降低成本、提高效率;而AI 可以替代人力,让成本直接为0,其蕴含的市场价值比互联网技术的市场价值更高。
二、AI的边界
要理解AI的边界,就必须从AI三要素切入。三要素分别为算法、计算力、数据。我们通过对已有模型算法的理解,计算力的认知以及对可获取数据的判断,就可以推测出我们落地时可实现哪些,以及可实现到什么程度。
有一个宏观判断边界的快捷法,叫做“1秒法则”:当前的AI可以实现到处理人1秒内可以想到答案的问题。而且这个问题还得满足以下特点:大规模、重复性、限定领域。
三、AI的市场情况
1. AI应用分类
关键性应用:需要算法准确度在99.9999%以上的应用。比如无人驾驶汽车、手术机器人等。
非关键性应用:只需要算法准确度在99%或95%以上的应用。例如人脸识别、广告推送等。
关键性应用对算法要求极高,需要特别优秀的AI算法专家来推动实现。非关键性应用对算法要求相对低,借助开源算法即可以进行落地。关键性应用的关键角色是AI算法专家(AI 科学家)、非关键性应用的关键角色则是AI PM 。
2. AI的市场化
由于云计算解决了计算力的问题,又有开源算法以及Google等公司开放的框架可利用,很多AI产品的落地条件只剩下找到数据了。而一些有数据积累的互联网公司在这一点上具备先发优势,比如百度、阿里、腾讯,都开始抢夺下一个商业风口(AI)了。百度已经是all in AI 了,目前百度的无人汽车驾驶已经初见成效,离大规模商品化不远。阿里利用AI为自己的服务进行各种升级,比如人脸识别、人脸解锁等等,现在阿里布局的新零售线下无人超市等必不可缺AI支持。腾讯的计算机识别相关软件已经成熟并等待深度商业化。另外一些小一点且针对领域相对垂直的互联网公司,如喜马拉雅、美团等,都开始为自己的应用或服务AI 赋能。(此处针对非关键性应用介绍)
过去多年互联网的发展很好地打下了数据基础,互联网应用是很好的数据采取端口。产品经理要负责AI产品的时候同样需要多花心思设计应用的数据采集体系,使得可更高效地采集数据,且采集数据更便于形成优质样本。
顺便说下短期市场趋势——专家系统。“专家系统”也是AI模型里很重要的一部分,我们可以简单理解为“专家系统”就是针对一个专业领域进行专业知识的训练而获得的模型,“专家系统”其实就是机器复制行业专家的专业能力,并替代其完成工作。比如医疗专家系统AI、股票专家系统AI。前者是替代医生进行诊断看病并输出结果,后者是替代股票专家帮用户分析股市及推荐股票。“专家系统”的训练要依靠行业专家或专家总结的专业知识,行业专家要参与训练和测试效果。目前市场里某些领域的“专家系统”已经相当成熟了,“专家系统”也是最容易直接创造商业价值的AI。目前大公司的AI框架所开放的API已经足够训练成熟的“专家系统”,只需要满足条件:1)有专家知识;2)有足够多的优质数据。
3. 硬件&软件
AI的产品可以分为硬件AI(包括硬软结合AI)、软件AI。其中硬件AI产品的落地成本更高、风险更大、周期更长,所以目前市场资本对软件AI公司更偏好一些,拿到投资的这类公司的量也多一些。2018年开始后的两三年内,亮相市场的AI产品应该大量都是软件类,甚至说大量的AI产品就来自于移动互联网产品的升级(AI赋能)。比如美团外卖app已经加了AI机器人服务功能,还有微软识花等纯AI的app…
4. AI市场的人才需求
目前人才需求是市场第一需求。人才包括新兴岗位:AI算法科学家、AI工程师、人工智能训练师、AI产品经理、数据标注专员。涉及到关键性应用时,AI算法科学家、AI工程师是最稀缺且第一需求人才;涉及到非关键性应用时,AI产品经理为最稀缺且第一需求人才。
目前市场在尝试各行各领域的AI产品,但由于AI产品经理的匮乏,大部分进展过慢或难以开展。市场需要更多的合格的AI产品经理,合格的AI产品经理需要对AI认知全面且懂得如何与实际的市场需求相联系,同时还需要有对新的需求场景的开发、摸索(所以AI产品经理还是得具备行业经验,对行业理解深刻)。
四、AI项目中的分工
1. AI科学家
岗位职责:
研究机器学习算法、AI模型(通常只有关键性应用的项目才会需要AI科学家)。
2. AI工程师
岗位职责:
利用模型进行编程,负责调整模型参数,以及数据训练的操作。
3. AI训练师
(1)岗位职责
通过分析产品需求及相关数据,制定数据标注规则,提高数据标注工作质量和效率,同时累积细分领域通用数据。
(2)岗位需求背景
- 数据标注是AI项目中最重要的环节之一。一般情况下需要由数据标注员来完成数据标注(即给训练数据打标签),但是数据标注员对数据的理解的不同会造成标注质量差异大,导致整个标注工作的效率和效果都不好。
- AI公司在其细分领域可能累积了大量数据,但是由于缺少对数据的正确管理,使得这些数据难以沉淀、复用,使用一次之后难以再发挥价值。所以AI训练师成为了必要。
(3)具体工作内容
- 通过聚类算法、标注分析等方式,以及凭借对行业的理解,从数据中结合行业场景提取特征。输出表达清晰准确的数据标注规则。
- 辅助AI工程师的工作,并进行数据验收。参与核心指标的制定以及指标监督。日常跟踪数据。(偏向于运营的工作)
- 根据细分领域的数据应用需求,从已有数据中挑选符合要求的通用数据,形成数据沉淀、积累。
- 提出细化的数据需求,以及提出产品优化建议。该工作需要和AI产品经理进行大量沟通
- 分配数据标注员的工作,对数据标注员的工作进行培训、指导。以及验收数据(检查数据标注员工作结果)。该工作需要和数据标注员进行大量沟通。
(4)两个侧重方向
AI训练师有两个侧重方向:
- 一是重前期的数据挖掘工作及辅助AI工程师的工作,保证产品落地;
- 二是重后期的产品运营,提升产品体验。根据不同项目的需求而定侧重方向。
(5)能力模型
- 数据能力——会使用科学的数据获取方法,能利用excel之类的数据处理工具。
- 行业背景——熟悉公司行业领域知识,以及数据特点(比如语言、图像)。
- 分析能力——基于产品数据需求,提炼问题特征,输出优化方案。
- 沟通能力——能通俗易懂的阐释专业术语,与各岗位同事交流都能切换频道。
- AI技术理解力——特别是跟AI工程师交流时能厘清AI概念,并判断技术边界(能不能做,能做到什么程度)。
- AI行业理解力——具备AI行业知识框架。
4. AI产品经理
(1)岗位职责
理解行业及用户,收集/挖掘需求、分析需求,做出产品战略规划,并设计产品解决方案、分析最佳的AI解决方案(比如用什么AI技术、哪一个模型),与AI训练师沟通、AI工程师沟通,完成产品demo,推动产品上线,跟踪数据,做出产品优化方案。
(2)岗位需求背景
无论在哪个领域,做产品都需要产品经理。只不过在AI领域,需要对AI行业知识理解深刻的产品经理,这样的产品经理具备边界判断的能力以及判断最佳解决方案的能力,我们把这样的产品经理叫AI产品经理。
(3)具体工作内容
- 调研行业,理解行业业务,收集或挖掘行业需求;
- 深刻理解需求,分析目标用户,输出用户画像;
- 定位产品,制定产品战略(结合对市场发展趋势、竞品等的理解);
- 找出解决需求的方案,并转化为AI产品;选择最佳AI解决方案(带着需求和产品规划与AI工程师、AI训练师深度沟通),并判断落地可行性及可实现程度;参与制定数据标注规则;
- 设计产品,输出产品demo及各种文档(流程图、PRD等);
- 向AI训练师收集产品优化建议;
- 优化产品;
- 评估产品,计划开发(UI设计及开发)阶段、周期。制定验收标准;
- 验收产品,与运营对接,上线。
(4)能力模型
- AI技术理解力——跟AI工程师交流时能厘清AI概念,判断技术边界(能不能做,能做到什么程度);能结合产品体验,做好交互设计,使得AI部分的表现形式最佳;了解需要什么样的数据,甚至设计最佳数据采集功能,使应用可以更好的采集高质量数据,累积以备利用。
- AI行业理解力(加创造力)——具备AI行业知识框架。能结合系统的AI知识展开逻辑性的思维发散,考虑AI带来的新行业的可能性。
- 传统互联网产品经理的通用能力
5. 数据标注员
(1)岗位职责
负责给数据打标签的执行工作。
(2)岗位需求背景
数据标注是个工作量极大的工作,且专业度要求不高。
(3)具体工作内容
- 按照规则预训练,评估规则及工时;
- 按规则完成要求的数据标签;
- 交付已标注数据。
PS:AI产品经理和AI训练师具备类似的能力模型,只是工作侧重点不同,AI训练师负责更细分的数据工作。目前市场上的AI训练师大部分来自产品经理的转型。而AI 产品经理可以直接兼顾AI训练师的职责,即不需要AI训练师,只要AI产品经理。
五、PM对互联网产品AI升级
很多移动互联网的产品都可以进行AI升级,所以建议产品经理们进行AI学习,可以为自己的产品进行AI赋能。(此处我们只针对于分关键性应用进行讨论,即不需要AI科学家的岗位,只需要懂得利用开源框架和模型即可。)
1. 用AI解决方案代替传统的算法解决方案
举例:新闻app的智能推荐功能
例如,以前今日头条的智能推荐功能是基于对用户行为路径的研究得出的用户模型,根据用户的过去行为产生的数据,对用户当下想看的或喜欢的内容进行预测并推送。概括讲就是通过研究先找到用户行为跟用户喜欢之间的映射关系,然后根据映射关系写好算法。
该解决方案的缺陷是:
- 找到准确的映射关系难度大,并且很可能遗漏很多规律;
- 需要对用户体验进行优化就需要更新算法,工作量大,且优化周期偏长;
- 产品体验跟算法工程师的技术能力直接相关,并非每一个公司都有足够优秀的算法工程师。
用AI方案替代:直接利用数据进行训练,让模型在学习的过程中自己找到映射关系,然后接入应用。优点是:
- 可以找到人未能总结出的一些规律,效果可能出乎意料;
- AI自己时时刻刻通过数据进行自我升级;
- 即使没有算法工程师,也可以实现智能推送效果。
2. 在原app上添加AI功能
举例:外卖app
利用AI增加个性化界面功能——让app调用AI模型,利用用户数据对AI模型进行训练,让AI找到不同行为的用户分别有什么点餐习惯或者说属于什么用户行为模型。当用户进入app时,根据用户之前的行为数据,展示界面定制化呈现。
利用AI帮助用户更快做出更佳选择——用户进入外卖app时,可以直接语音提问:
- 今天哪些店铺活动中?
- 有什么粤菜新店?
- ……
经过语音识别、语音合成、专家系统训练的AI会迅速得出答案并回复用户,同时带上链接。如此用户就可以快速完成下单。(其实AI对移动互联网的升级有更多方式,这个需要靠产品经理对业务、用户需求有足够深度的理解并挖掘出来)。
六、AI产品经理需要参与、推动的重要流程
(1)分析用户需求,找到痛点并思考用什么样的AI方案进行解决
(2)设计产品的后台数据采集功能,保证数据的采集更方便机器学习时利用(设计产品时,要分析出机器学习时需要的数据量、数据类型以及数据特征)
(3)与AI训练师沟通制定数据标注规则
(4)与AI工程师进行交流,告知AI工程师需要的AI模型,预期效果,以及与客户端的数据交互需求。与用户端工程师进行交流,告知AI如何与客户端进行数据交互
(5)设计客户端,推动客户端开发实现
(6)数据训练机器
准备样本数据(训练数据和测试数据)–为训练数据打标签–输入带标签的训练数据–输入测试数据–查看拟合度,或调整模型参数–循环训练直至达到最佳拟合。
(7)检查训练后的AI模型是否满足需求。若不满足,与AI工程师共同分析问题并找出解决方案
(8)将成型的AI产品面对“用户角色”测试,无问题后上线正式运营
好了,要转型做一个AI产品经理的快学习指南就先到这里了,文末会有知识结构的脑图下载地址,以及参考文献、推荐阅读书籍。希望大家看完老狼的分享后,脑里可形成一个学习大纲,有了清晰的学习思路。
还有一个特别重要的事!如果你看完老狼的分享,还是对AI一无所知,为了让你没有白花时间看这篇文章,老狼告诉你一个特别的装13技巧,当大家都在各种拿AI吹水的时候,你点上一支香烟,45度抬头,看着那一缕青烟,轻描淡写地说道:其实AI很简单,它不过是一个函数。
云盘分享:脑图分享–AI PM学习指南大纲
作者:邓生,5年产品经验
本文由 @老狼几点了 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Pexels,基于 CC0 协议










老兄,想要转AI产品经理,有联系方式吗,想抱大腿
有没有想在广州工作的宝妈PM?有的话请留言哦
感谢分享,厉害,刚好需要有人帮助把知识点串起来。
厉害了,总结好全面
能不能留个微信向你学习啊。。。。。我的 miami291202
写的不仅专业而且非常详细,目前正在学习AIPM的知识准备转型,谢谢你的分享
写的特别特别特别好,感谢分享!但是请问您的脑图有图片版的嘛?嘻嘻
这得加好友 🙂
nice,我是传统B端产品经理,有转型AI产品的想法, 但是苦于没有系统化的教材,一直找不到方向,你这篇文章对于我来说非常受用!另外有比较基础的入门的书、以及算法介绍的书,可以推荐一下吗?
非常好的文章,专门按照脉络记录了笔记,最喜欢你把算法讲得这么通俗易懂,期待你后面的文章!
忙完了,就抽时间更新
MD,这是我目前见的文章中,最有良心的文章了。很多人写的文章不是宽泛、不具体,就是到处copy烂大街的文章,这篇文章就PM日常工作内容都阐述了,良心好文!
谢谢认可哈
你好,我之前是做iOS开发的大概做了4年,专业是计算机 ,女生如果转向AI这个方向的话,有什么样的一些建议吗?谢谢啦
这个我就想不到建议咯。我的眼里,男女平等 🙂 都一样的。
谢谢,总结很详细。
不用谢,对大家有用就好
赞赞赞!不过没找到“推荐阅读书籍”,在脑图里吗,找了几遍没找到 😥
良心文章啊!!!
非常清晰,内容庞大。一次看不完。留个爪
看得我好晕 🙁
本人互联网b端产品经理,现在想转型AI产品经理,请问楼主能否推荐下适合AI新人学习的书籍呢,感谢!
起点学院有一门《15天入门AI产品经理》的课程,已经开办8期,帮助2500+同学成功入门,有需要的话可以加蘑菇微信了解哈(id:qdxymg)
老狼?广州的么,貌似和你一起玩过桌游,受教了
您好,对于AI产品经理的职责,有2个问题请假下,有劳指点迷津啦:
(1)分析最佳的AI解决方案(比如用什么AI技术、哪一个模型)
这方面,采用什么技术、什么模型,这方面不应该是拉算法团队一起开需求评审会,或者技术方案讨论会么? 这个问题的主导,是不是应该推动算法团队去决策?
(2)同样的问题,是对于“数据训练机器”部分,提到的查看拟合度、调整算法参数。也应该是同样配合技术团队,一起操作吧?
我理解这方面工作,产品经理只是可以配合,做简单实验、测试
(1),分享一个案例。我之前做一个问答功能,出题人不仅出题目,还会预埋答案,AI要以出题人预埋答案作为参考判断答题人的答案得分。我们发现这跟中学考试一样,其实是看答题人回答中体现了多少知识点,体现相关知识点越多,说明答得越好。我们首先想到要从文本相似度算法中找一个最佳算法。通过对欧式距离算法、编辑距离算法、jacaard相似度算法等的理解(可以自己去了解这些文本相似度算法),选择了jaccard相似度算法。因为jacaard的算法逻辑是两个文本之间相同的词越多,相似度越高。
(2),工程师是负责跟机器直接沟通的人
不好意思,我写的文章不商用
我现在很纠结,我从事人力很多年了,对计算机类不懂,现在想转型,想从0开始学习Ai产品经理这块,我不知道自己适合不?要不要培训机构……
最好的方法是参与一个AI产品。或者参与一些广告类产品,搜索引擎类产品
赞赞赞
😥 很良心的一篇文了,把最流行的人工智能算法全梳理了一遍,重点是:免费,免费,有没有
又回来刷了一遍,上次是重点看算法,这次是看产品经理这么做
😎
做什么
前辈非常厉害,学习了! ❓
过奖了,欢迎持续关注,haha
厉害
谢谢哈
脉络梳理的非常清晰,赞👍
谢谢鼓励,希望持续关注,文章有写的不好的地方欢迎点评
赞赞
谢谢鼓励,以后尽量多写
机器学习只是人工智能的一个分支,当然现在主流这个
目前也正在从事ai产品工作,楼主这篇文章算是比较好的科普文章了,支持
谢谢支持哦
赞
谢谢鼓励
感谢作者的文章,非常棒。但目前感觉AI产品经理门槛很高,学完之后找不到工作 😀
如果没有过AI经验,那么有搜索产品经验、广告业务经验等,找AI工作机会也会大一些。而且呢,产品经理就是产品经理,AI只是一个相对细分的产品方向罢了。争取先到小公司做相关的项目,有经验之后便可以找到满意的工作了。祝好运
有没有相关教程推荐呢?我看文字感觉超级枯燥,看不下去
起点学院有一门《15天入门AI产品经理》的课程,已经开办8期,帮助2500+同学成功入门,有需要的话可以加蘑菇微信了解哈(id:qdxymg)