
 起点课堂会员权益
起点课堂会员权益用可量化操作打造AI好声音
本文将为大家分享实战经验:团队如何评估和影响语音合成的效果,从而帮助AI“说人话”。

AI产品“能说话”由基础算法和交互设计师来保障,但是说的话能不能让你听懂、是否像人,就要考验语音合成的功力了。本文将用实战经验分享:团队如何评估和影响语音合成的效果,从而帮助AI“说人话”。
一、评估原则
二、方法选择
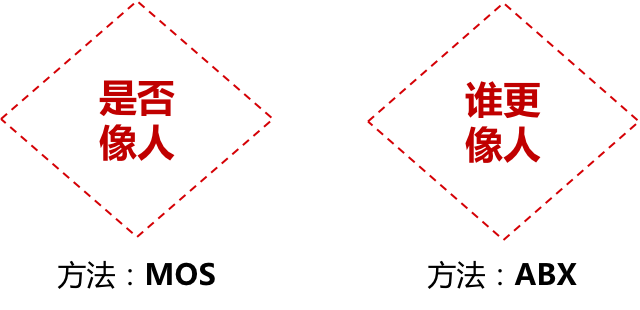
【MOS评价法】一般用于单一语音库的合成水平评估。选择了行业相对通用的“MOS评价法”,即主观质量评分法 Mean Opinion Score,进行主观评价。用户根据听到的声音质量,在李克特5级量表中给出一个主观评分评价质量优劣,1最差-5最优。
【注】MOS评价法初期用于语音通讯中的语音质量评估,常用李克特5级量表。近年随着语音合成技术的出现,这一评价工具被应用于合成语音效果的评估,行业均值3.5,高于这个分数则被认为高于行业一般水平。但2017-2018年见,随着语料库的迅速积累、语音合成技术也不断完善,行业均值有所提升。
(1)我们为自己产品所用的合成语音定下的最基本评价原则:是否像人。像人ok,不像out!所以会涉及到一个最主要的评估指标(MKPI)『还原度』。为了得到合成语音在MKPI上的表现,需要将合成语音与人声比较,还原度高=像人=ok,还原度低=不像人=out!
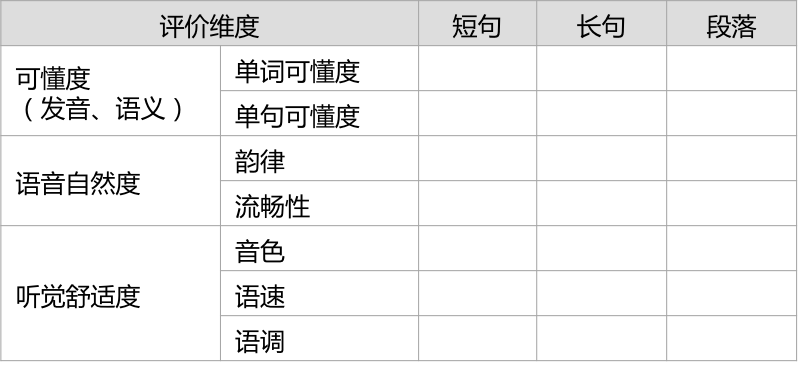
(2)为了获取合成音相较人声的还原度,让指标可以量化,做了指标拆解:用户在充分认识某一人声特质的基础上,比较合成音对「人声特质的保留水平」,以及在一句话中「特质保留水平是否稳定」。
(3)还是有点抽象,那就将指标进行操作定义:所以在专家打分和文献研究的基础上,确定了3个一级指标及其下6个二级指标。
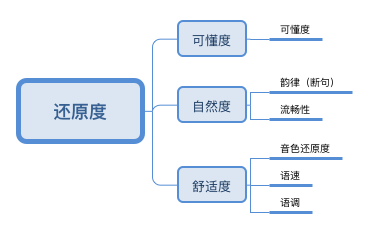
(4)还原度/mos评价维度释义
- 可懂度-TTS的播报是否能让用户听懂(语音准确清晰);
- 流畅性-字与字、句子成分之间的连接是否流畅自然;
- 音色-还原度TTS播报的音色是否令用户满意;
- 语速-TTS播报的速度是否让用户感觉舒适友好;
- 语调-TTS播报的语调是否稳定?语调尤其字音是否发音准确?
【ABX迫选法】一般用于不同版本迭代效果/竞品评估。选择心里测量工具——迫选量表。设计单盲实验施测,用户在听到的A\B\X\……两两配对的声音中,选择一个主观认为较人声原声还原度最高的。最终统计A\B\X\……各自频次,频次较高的版本较好。
三、建议实施步骤
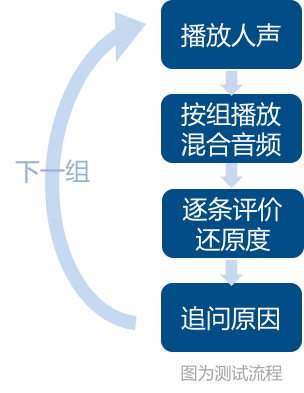
【MOS评价法】从6个维度对各条语音进行mos评分,发现短板、比较与人声的差异。
- 测试前培训用户,为用户播放评价演示素材,并确保用户明确评价方法。发放纸质mos评价表
- 用户戴耳机,主持人发用笔记本电脑随机为用户播放待测试语音
- 人声、合成音按内容分组配对。主持人随机播放各组语料
- 每一句语料播放完毕,邀请用户对该句语料进行6个维度的mos评分
- 全部施测完成,主试统计各维度/总体mos评分均值,比较各产品的总体mos水平,确定相对优劣。以下为各维度/总体比较标准,其中3.5分为行业平均水平
 【ABX迫选法】人声PK多版本合成语音,分别比较集内内容与集外内容的还原度。
【ABX迫选法】人声PK多版本合成语音,分别比较集内内容与集外内容的还原度。
- 主持人为用户介绍评价方式,并发放纸质A/B/X量表
- 用户戴耳机,主持人测试笔记本电脑
- 人声、多版本合成音按内容分组配对。主持人随机播放各组语料
- 播放后邀请用户配对呈现的声音进行比较,并作出选择:A/B/X
- 全部施测完成,主试统计选择频次。以下为评价标准

【注】集内内容:语音合成的训练集中的人声语料,因为做过针对性的训练,所以该内容生成质量轮上比集外内容更好;集外内容:相对集内内容的概念,从未进行过针对训练的随机挑选的语料。
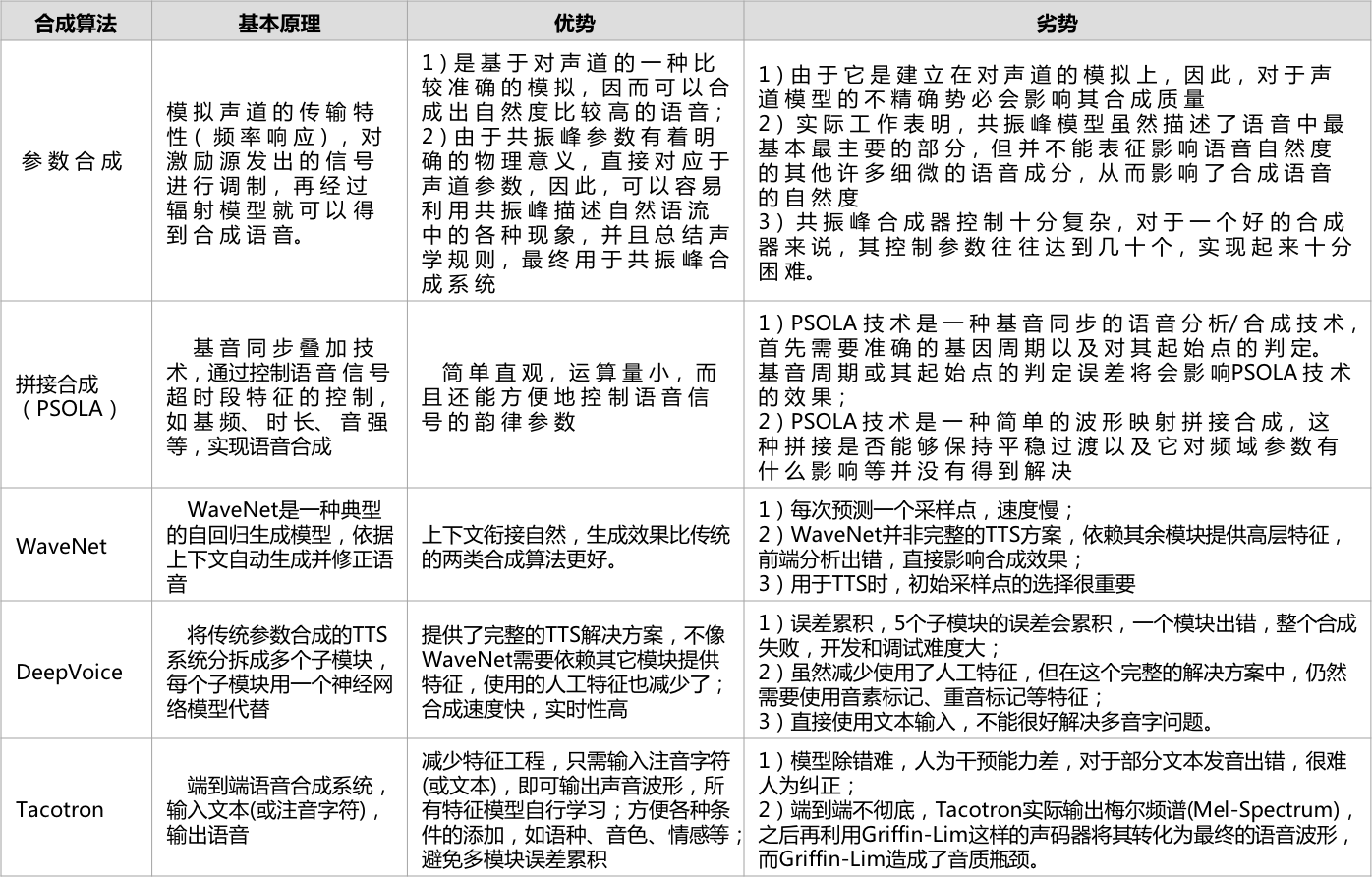
四、合成算法比较
语音合成算法发展也是与时俱进,算法选择的成功可以事半功倍。(仅比较主流算法之间应用场景和优劣,详细算法原理介绍的文章很多不一一列出)
按出现的年代由远及近排列,如下表:
本文联合作者:
于爽 | 网易杭研不高级用户研究员,做了一年半智能音箱
利莹 | 现回归高校音乐管理专业的人民教师,前网易人工智能事业部策划
参考文献:
1. 吴志勇 ,蔡莲红,《语音合成技术的原理》,清华大学计算机系智能技术与系统国家重点实验室,2007
2. 语音合成技术概述 http://www.cnblogs.com/mengnan/p/9474111.html
本文由 @钢镚儿yu 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


