
 起点课堂会员权益
起点课堂会员权益OCR在NLP场景中的应用
在NLP的产品体系中,OCR是关于文档、文件处理的基础步骤,是无法回避和绕开的。
关于OCR的基础知识,也就成了NLP产品经理必不可少的知识储备了——只有产品详细地了解了关于OCR的处理原理和步骤,才能充分发挥现有技术的优势,规避其弱点,创造出更大的价值。

什么是OCR?
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
那么既然是通过扫描,或者摄像的方式获取,就会遇到很多诸如背景复杂、分辨率低等情况,在没有针对OCR技术实质性的了解下,有的朋友都会认为OCR识别,是一件非常easy的事情,不值得进行讨论。
事实上,自然环境下的OCR要面临、要解决的问题还是相当多的,例如:
- 背景复杂;
- 存在如底纹、水印、底线、框线;
- 加盖印章干扰叠加 ;
- 图像对比度低;
- 文字倾斜、模糊;
- 污迹、磨损;
- 防伪标识;
- 字体种类繁多;
- 字的笔画深浅,印刷受墨多寡等等情况。
通常情况下,衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
传统OCR的处理过程
下面,我们通过一张图来简要了解一下传统OCR的处理过程:
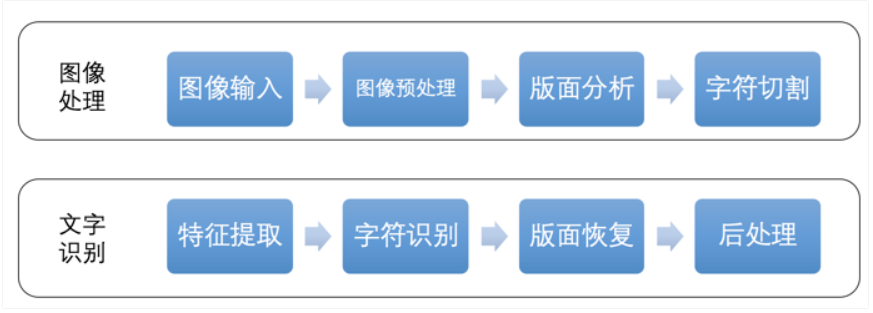
图像预处理
预处理一般包括诸如倾斜校正、灰度化、图像降噪、二值化处理等等。
二值化:
二值化就是让图像的像素点矩阵中的每个像素点的灰度值为0(黑色)或者255(白色),也就是让整个图像呈现只有黑和白的效果。在灰度化的图像中灰度值的范围为0~255,在二值化后的图像中的灰度值范围是0或者255。
二值化的做法一般分为以下几种:
- 版面分析:是将扫描得到的图像,将文本按照不同的属性划分出区域块。对于各个不同的区域块,如:横排正文、竖排正文、表格、图片等。
- 字符切割:对图像中的文本进行字符级的切割,需要注意的是字符粘连等问题。
- 特征提取:对字符图像提取关键特征并降维,用于后续的字符识别算法。
- 字符识别:依据特征向量,基于模版匹配分类法或深度神经网络分类法,识别出字符。版面恢复:识别原文档的排版,按照原排版的格式将识别结果输出。
- 后处理:引入一些纠错机制或者语言模型,针对一些形近字进行修正。
当然,上述传统的OCR识别方法已经有点儿过时了,现在更流行的做法是基于深度学习的端到端的文字识别,即我们不需要显式加入文字切割这个环节,而是将文字识别转化为序列学习问题。
虽然输入的图像尺度不同,文本长度不同,但是经过DCNN和RNN后,在输出阶段经过一定的翻译后,就可以对整个文本图像进行识别,也就是说,文字的切割也被融入到深度学习中去了。
OCR处理的技术框架
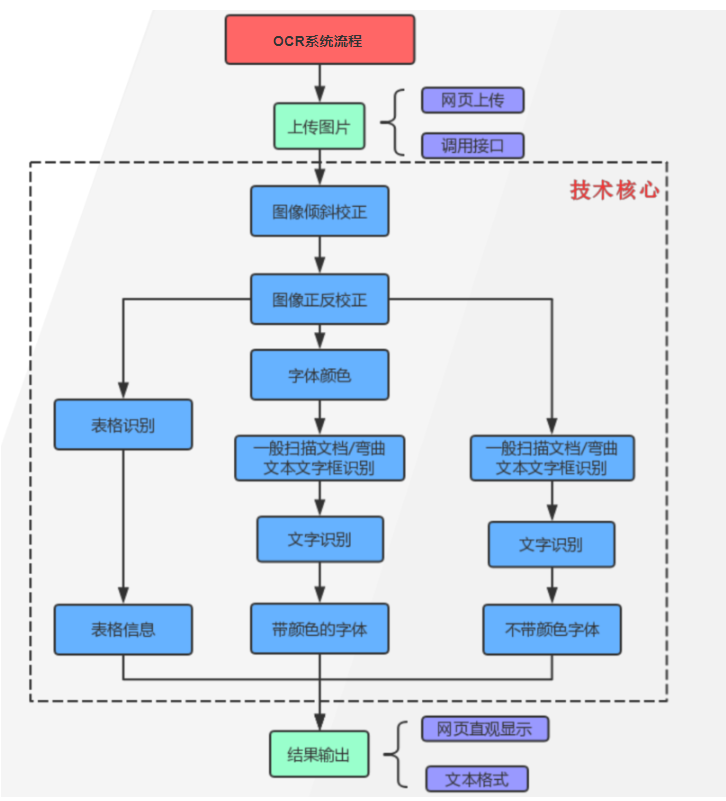
根据上面的技术框架图,简要介绍一下其中几个关键步骤的模型:
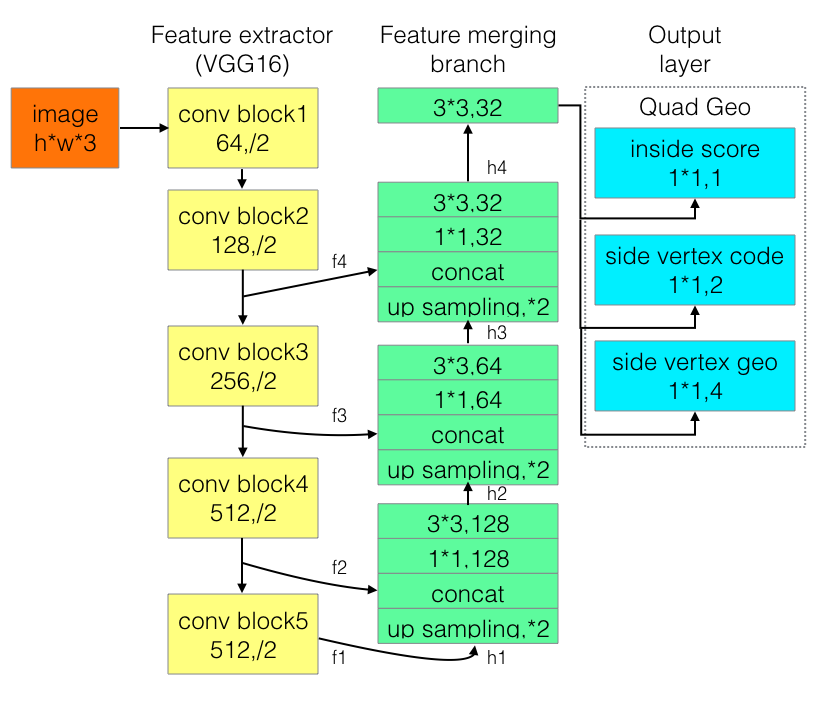
第一,倾斜校正,采用深度学习模型AdvancedEast,进行像素级别的分割。
它是一种用于场景图像文本检测的算法,主要基于EAST:一种高效且准确的场景文本检测器,并且还提供了显着的改进,这使得长文本预测更准确。它的网络结构图如下:
第二,采用PixelLink识别文字条的位置。
该模型是浙大联合阿里提出,其核心思想是基于图像分割来实现场景文字检测,比起之前的很多基于检测的场景文字检测模型来说在性能与准确率方面都有比较明显的提升。PixelLink网络模型架构如下:
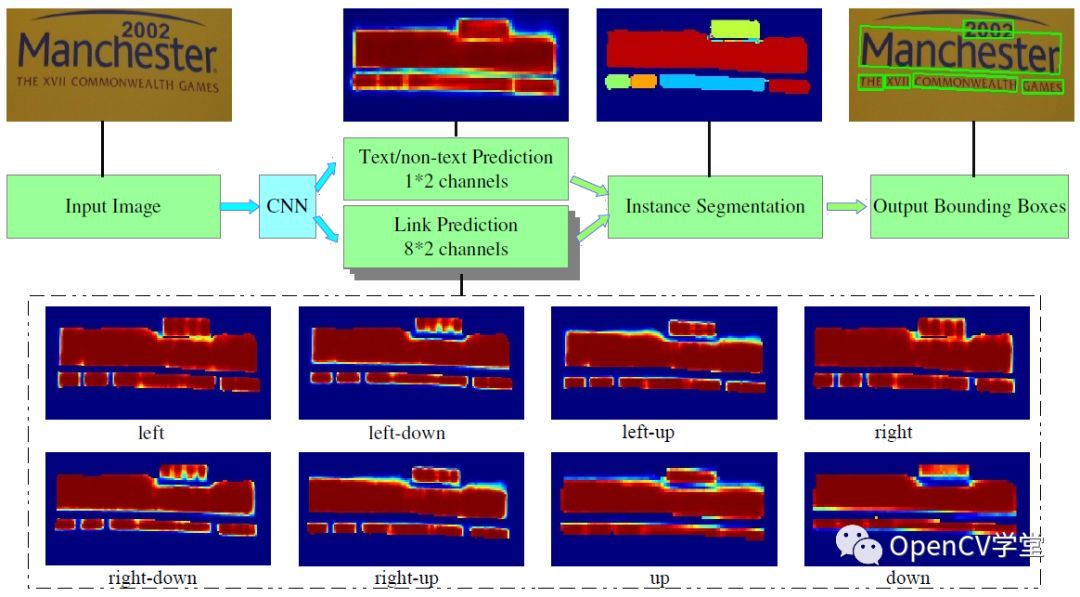
其中CNN部分采用了VGG16做为特征提取网络,对输出分为两个部分:
- 像素分割,判断每个像素是否为text/non-text
- 链接预测,对每个像素点八领域进行链接预测,如果是positive则合并为text像素,如果不是则放弃。
通过上述两步之后得到叠加的TEXT图像mask,对mask图像进行连通组件发现即可得到最终检测框输出。
第三,采用CRNN模型进行文字识别,它的网络结构是这样的:
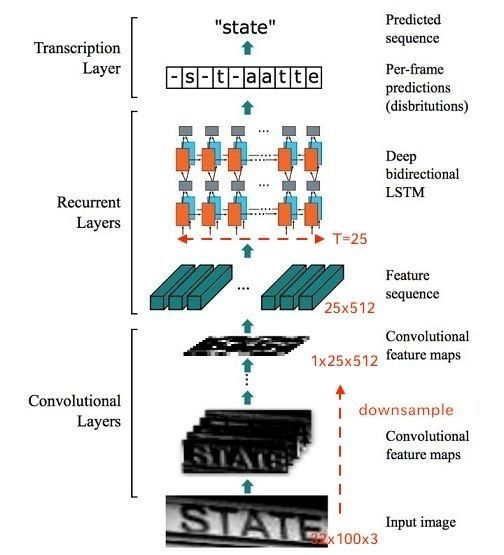
网络结构包含三部分,从下到上依次为:
- 卷积层,使用CNN,作用是从输入图像中提取特征序列;
- 循环层,使用RNN,作用是预测从卷积层获取的特征序列的标签(真实值)分布;
- 转录层,使用CTC,作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果;
CRNN借鉴了语音识别中的LSTM+CTC的建模方法,不同点是输入进LSTM的特征,从语音领域的声学特征(MFCC等),替换为CNN网络提取的图像特征向量。
CRNN算法最大的贡献,是把CNN做图像特征工程的潜力与LSTM做序列化识别的潜力,进行结合。它既提取了鲁棒特征,又通过序列识别避免了传统算法中难度极高的单字符切分与单字符识别,同时序列化识别也嵌入时序依赖。
目前市面上都能提供哪些类型的文本识别呢?
通用文字识别
一般是指不规则文档类的识别,例如PDF之类的。
卡证识别
身份证、银行卡、营业执照、名片、护照、港澳通行证、户口本、驾驶证、行驶证等等
票据识别
增值税发票、定额发票、火车票、出租车票、行程单、保单、银行单据等等。
其他
车牌、车辆合格证、印章检测等等。
应用场景
最后我们来聊一下关于OCR的应用场景,在开头的时候,我们提到,在NLP的相关产品中,OCR扮演着不可或缺的角色,主要是在关于文档处理的一些场景中,例如,pdf等格式的文档抽取、文档审核、文档比对等等。
远程身份认证
结合OCR和人脸识别技术,实现用户证件信息的自动录入,并完成用户身份验证。应用于金融保险、社保、O2O等行业,有效控制业务风险。
内容审核与监管
自动识别图片、视频中的文字内容,及时发现涉黄、涉暴、政治敏感、恶意广告等不合规内容,规避业务风险,大幅节约人工审核成本。
纸质文档票据电子化
通过OCR实现纸质文档资料、票据、表格的自动识别和录入,减少人工录入成本,提高输入效率。
本文由 @燕然未勒 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash ,基于 CC0 协议。









默默的问一下,你这里的NLP指的是啥?
自然语言处理