
 起点课堂会员权益
起点课堂会员权益深度学习:技术原理、迭代路径与局限

本文尝试复盘梳理深度学习目前的技术要点,深度学习中模型迭代的方向,以及改进后存在的局限。
第一部分:深度学习技术基本要素:神经元、神经网络、分类器、可视化框架
在深度学习领域,神经元是深度学习的基本单位。
神经元从数学角度来看,为一个线性函数公式(如下图神经元里的公式)+非线性函数(激励函数)组成。线性函数(包括降维后的线性函数,此处不细展开)用于深度学习神经网络的模型训练,这其中,很可能出现欠拟合(欠拟合是指相对简单的线性函数,分类处理信息时,因为分类标签数量或准确度不足以做有效区分)。于是,在处理这一个问题时,工程师们人为设置了激励函数,来平衡线性函数无法解决的问题:激活函数是神经元中非线性部分,用来减低线性部分造成的误差。
经由神经元作为节点连接而成的网络,是神经网络。最基本的神经网络,有两个神经元,分别处在隐含层、输出层,如下图:
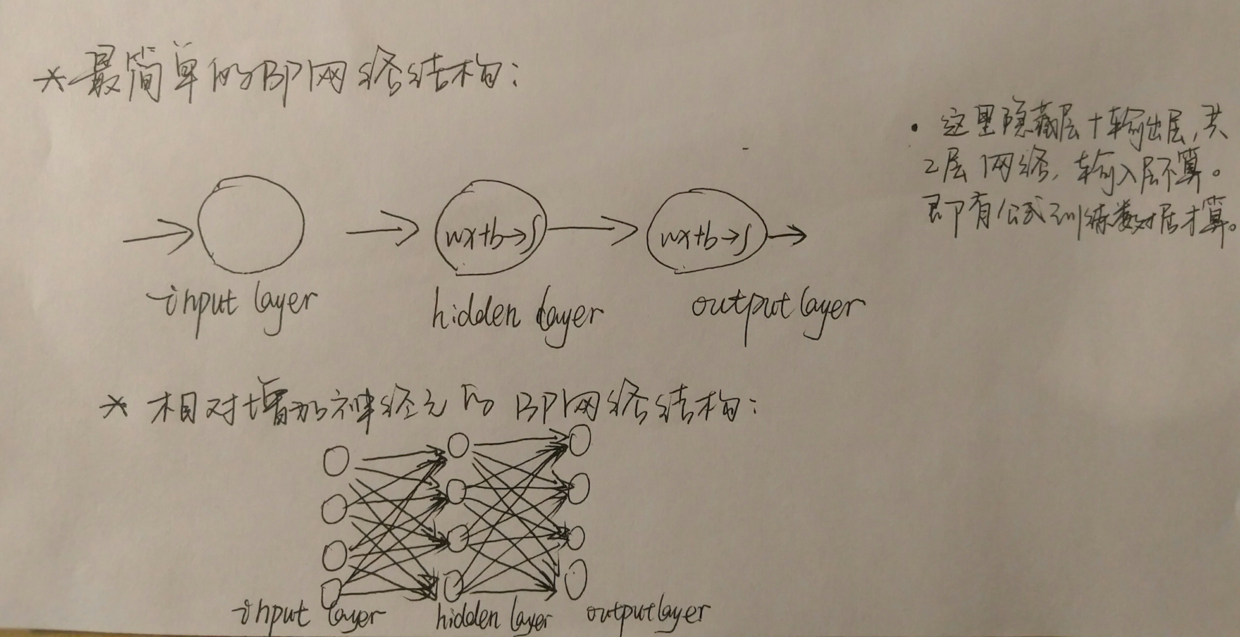
最简神经网络结构示意图
深度神经网络,是由含多层隐含层神经元组成的神经网络。具体的原理和实践会在下文再做展开,展开之前,不妨先了解深度学习技术层面到底解决了什么问题?
首先,深度学习与传统机器学习处理输入信息方式,有一个根本的差异:
传统机器学习主要是通过四种基于人为整理、明确分类维度逻辑关系的方式处理输入的信息。包括朴素贝叶斯,用概率量化计算模型;决策树,用合适的维度降低分类信息熵;回归模型,建模降低预测值与训练目标值的差距;SVM(支持向量机),寻找超平面保证分类的置信度最大。
在深度学习中,有大量的线性与非线性分类器,分类器是自动对信息进行处理,并不需要人为事先明确特征、标签分类。
相对而言,不需要预先准确分类标签的深度学习解决了传统机器学习的两大问题:
- 特征清晰度要求降低。训练中不再只是在固定明确的标签下处理,还允许模糊、噪声存在,对不同特征偏向的数据敏感程度自动忽略。
- 不可分类变为可分。由于没有明确分类的前提,使得原本大量(人为)无法分类的特征,可以变成(机器)可分类的特征,且相对高效地进行。(人为分类总是有局限的,因为需要明确定义、标签,一来需要时间、二来需要有效共识的达成)
接着,可以大致了解目前深度学习使用的框架有哪些,比如TensorFlow、Caffe、Chainer、Torch、Theano等。在这里我想强调的是深度学习中主流选用的框架TensorFlow的部分特性。
在一个前沿技术领域,一个框架是否值得使用(或者更准确地说,在这里我想提到的是能否下一步扩大使用范围),比如,TensorFlow是否值得使用,专业的工程师可能会提到:框架性能、社区活跃度、语言、环境与集群支持等等。就我目前的了解到的,有两个我觉得(面向用户,很受启发的)值得关注的地方:一个是使用的社区活跃度,一个是使用界面是否可视化。社群活跃度意味着这个框架使用时,开发者之间的交流与相互促进程度,如果是一个非常小众、其他开发者不愿参与的框架,那么是不利于下一步扩大使用范围的。使用界面可视化,TensorFlow 有Tensorboard,Tensorboard支持可视化的训练网络过程——事实上,可视化操作,一直是开发者与使用者(无论是相对原创开发者而言后来的开发者、还是普通用户)之间达成相对简单沟通的一个非常重要的环节。
开发者/工程人员致力于用最简洁的语言(无论是否友好,甚至可能晦涩难懂)来运行工程,但这个结果,很可能是后来者、用户的“艰难”读取。这不难让我想到一个《硅谷》( Silicon Valley,HBO)电视剧中一个情节:Pied Piper最初上线时,用户界面异常简陋,男主Richard Hendricks还有他的所有工程界的朋友都完全没有意识到这一点——他们觉得非常适合自己使用,但作为普通用户+投资人的女主Monica Hall(本来是对Pied Piper抱着极大期待的)在内测使用时,第一反应是觉得界面一点都不友好,没有继续使用的兴趣。后来Pied Piper用户数一直徘徊在万人左右,没有上升趋势,教育用户后接受使用的人数也没有明显提升。
这个可视化(友好面向用户的一种)是题外话了,不过回到深度学习,无论是其目前主流选择的框架(如TensorFlow)还是编程语言(如Python),都是往面向用户友好/易用的方向行进的。
上面提到深度学习技术实现的基本元素,包括神经元、激活函数、神经网络和深度神经网络,目前深度学习使用的主流框架及其选择标准。此外,还提到深度学习可以解决传统机器学习无法突破的“明确的特征”局限。
第二部分:深度学习模型迭代/改进方向,改进后对应局限
接下来,回到前面提到的目前深度学习基于上面提到的基本元素,真正落地的深度神经网络工程原理和实践。这一部分会按前馈神经网络、卷积神经网络、循环神经网络、深度残差网络、强化学习、对抗学习的顺序展开。我会比较详细介绍前馈神经网络在工程训练中的流程,其他会把它们分别要解决的问题以及可能的局限。
前馈神经网络
前馈神经网络是深度学习中最简单的神经网络,一般分为:反向传播神经网络(BP网络),径向基函数神经网络(RBF网络)。在这里我会相对详细地梳理这个最朴素的神经网络是如何落地的。
首先,我们来看一下前馈神经网络最基础的网络结构,以BP网络为例,这个我们在上文最基础的神经网络中就给出了示意图。上文的示意图中,神经元里的(wx+b)->,其实是简化了的,具体函数表达式会如下图:
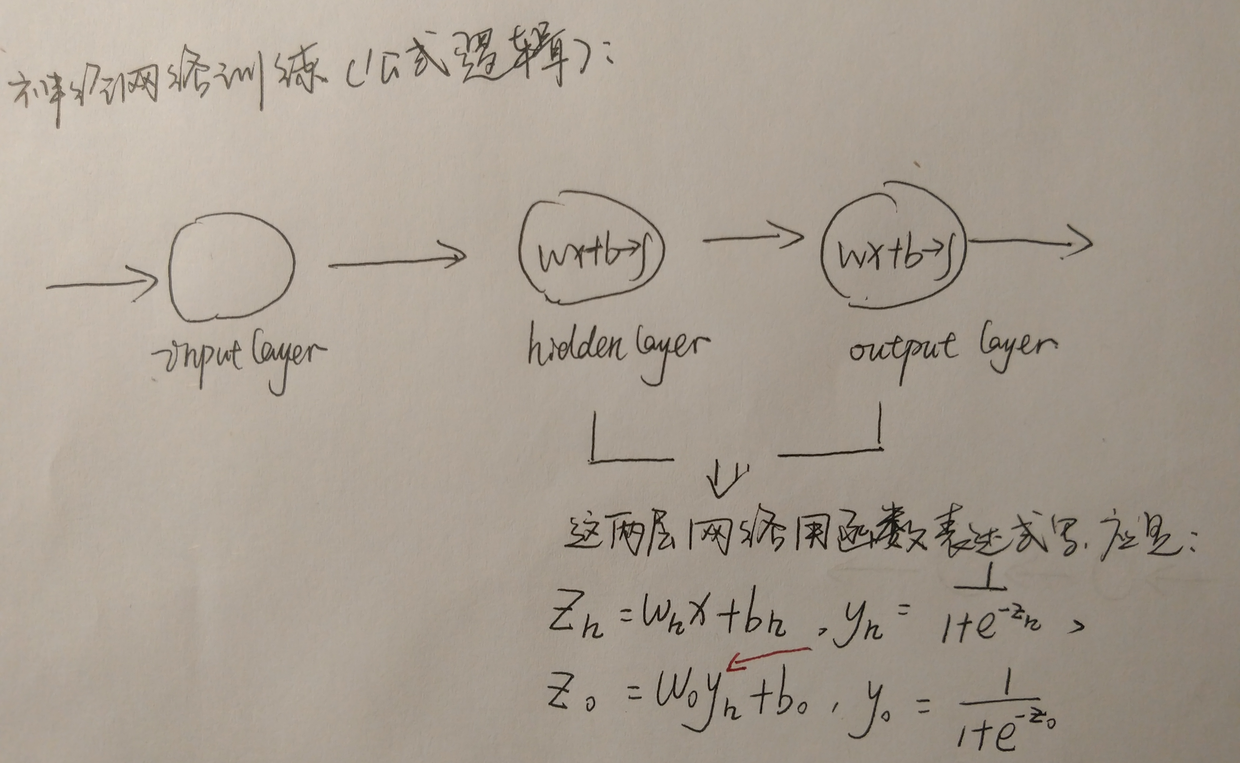
神经网络函数表达式
这个神经网络进入工程训练,需要经过以下三个环节:
- 准备样本(可以是文本、图片、音频以及音视频结合等训练样本)
- 清洗处理(目的是帮助网络更高效、准确分类)
- 正式训练(将训练样本代入训练模型,即上述示图公式)
在上面三个环节中,正式训练的时候,训练过程不断迭代使得w、b的值越来越适合(拟合)要训练的模型,为了求出w、b,深度学习中有梯度下降法(迭代法思维),来获取逼近最优w、b值。再进一步,由于梯度下降法训练时候要动用比较重的样本训练,后来又出现了随机梯度下降法(即随机抽样而不是全部样本进行处理),来获得相对较优的w、b值。
值得注意的是,从梯度下降法到随机梯度下降,这样的思维转化,在深度学习领域是非常常见的:深度学习面向万级以上的海量样本,如何使训练由相对重的模式变成比较轻的模式,从总体到随机抽样,是一种解决方案——核心就是在无限成本取得最优到有限成本取得次优之间权衡。
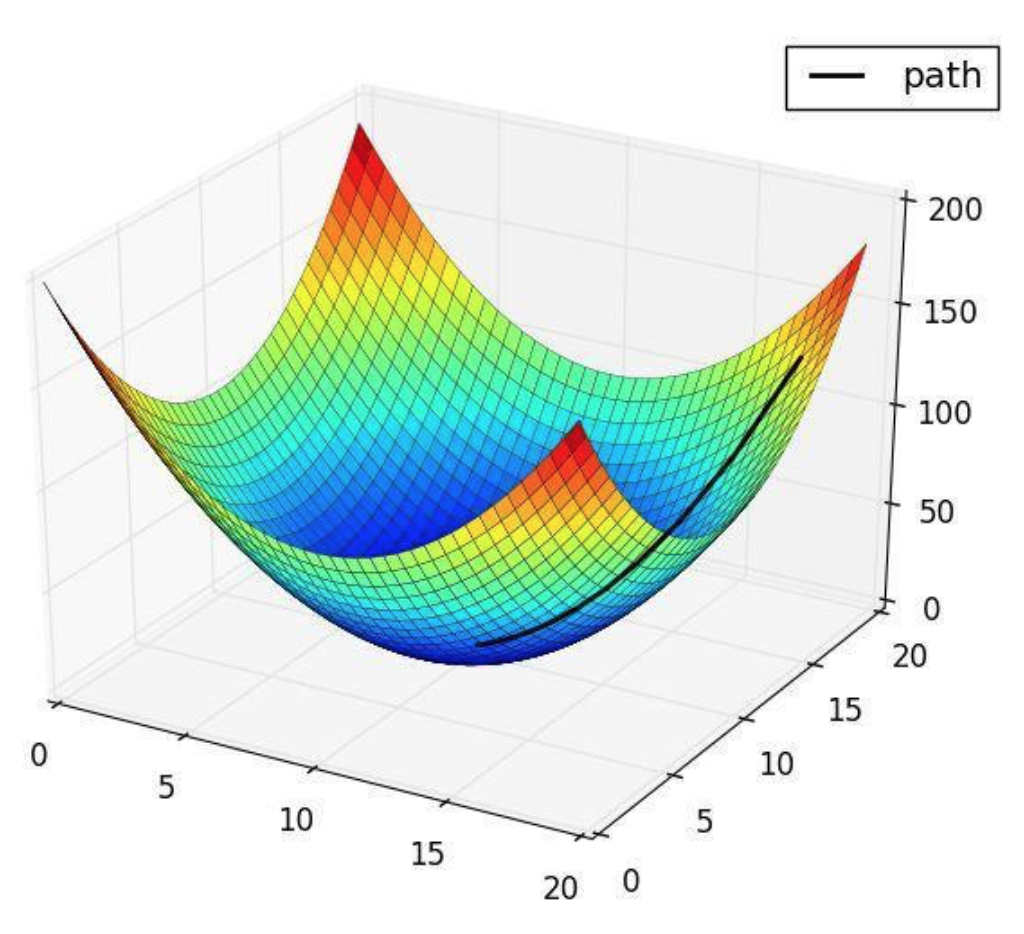
梯度下降法:求取(w,b)极值,使损失最小化
另外,在求取w、b值的过程中,无论是取任何值,难以避免产生的是一个误差值,在训练过程中,工程师们会引入一个损失函数Loss,而上述的梯度下降求取w、b最优解的同时便是求出最小损失函数的过程。
在训练过程中,有两个主要环节,一个是训练集训练,一个是验证集测试。前者是搭建最合适模型所需,后者是检验所搭建模型是否合适使用。在检验的过程中,可能会出现过拟合(Overfitting)问题,深度学习中高VC维的分类器,可能使模型过度拟合,降低模型的准确性——验证集验证过程中会基于Loss损失函数和准确率(Accuracy)来判断是否在较优的准确度。在搭建模型完成后,还有第三步,就是用测试集,检验搭建模型的效用了。
以上便是一个基础神经网络的流程框架,和在训练处理中引入的比较核心的思维。
介绍完最简单的神经网络工程流程,接下来,我会针对卷积神经网络、循环神经网络、深度残差网络要解决的问题和目前的局限来分享。
之所以以这个角度,是因为,在学习深度学习的过程中,我们会很容易发现,基于上述提到的最基础的神经网络结构,开发者们是一一针对工程实践时,遇到的瓶颈,找到对应的解决办法。而这些办法,慢慢建立成为新的落地模型。所以,我们是可以基于最简单网络模型,再进一步了解这些更新的神经网络模型的(它们的特性与功能)。
这些模型,既可以解决最基本神经网络无法突破的部分问题,同时,也面临着其他具体的局限。
卷积神经网络(CNN)
CNN,也是一种BP网络,,不过与之前的相比,其神经元可响应一部分覆盖范围的周围单元、通关权值共享的方式使得下一层工作量大大较少(可参照下图)。而之前提到的是全连接网络。
全连接网络的好处是,最大程度让整个网络节点不会漏掉(就像上面的神经网络示意图,每一个上一层神经元全部连接到下一层的神经元)。但是,就像上文也提到的,深度学习要处理的是万级以上的海量数据,要对海量数据进行全连接处理,是一种非常重的模式,训练过程中,收敛速度会很慢。
CNN,相较而言,就是比较轻的模式(这里再一次提到用有限成本处理海量信息的方案了),可以在训练中,较少更新权重、明显快于全连接网络地完成收敛。
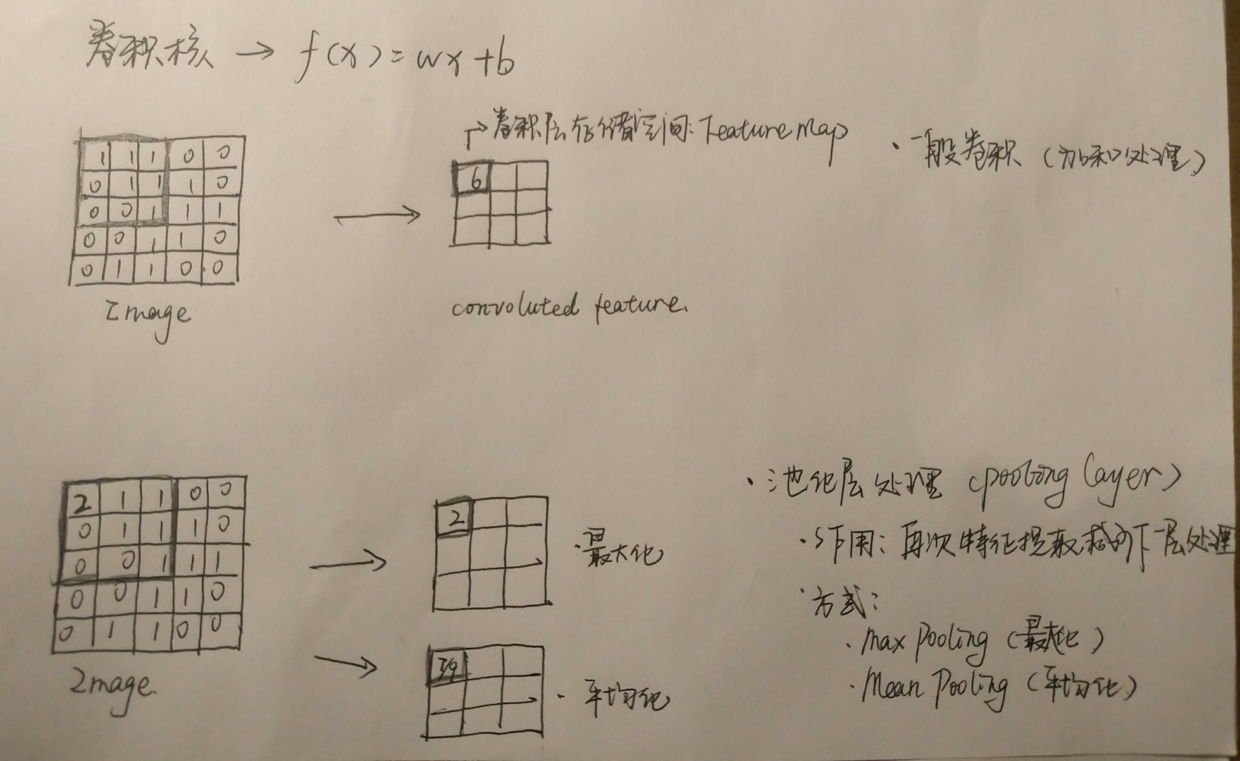
卷积网络处理数据过程及方式
CNN的训练过程如上图所示,除了一般处理方式(图中加和处理的模式,即将所有卷积的数据汇总),还有池化层处理的方式。池化层处理,主要分为两种路径,一种是取最大值,一种是取平均值。无论是哪种路径,目的都在于对数据进行又一次特征提取,减少下一层的数据处理量,同时获得相对抽象、模糊的信息,提高泛化性(想象一下,目标是找到所有人的共性。那上一步是:只提取一个人的特性,和找到几个人的共性,哪一种方式的更快、特征更有效)。
当然,上面提到的池化层会对信息进行模糊化处理,算是一种有损压缩。与之对应的,是整个卷积神经网络,在卷积核对输入向量进行特征提取的过程(将高维向量映射成低维向量),其实也是一种有损压缩。
到这里,又可以解答卷积神经网络可以解决什么的问题了。在开始的时候,我们提到,CNN神经元通过权值共享加快训练过程中的收敛速度,现在我们可以发现,CNN可以解决的另一个问题:减少噪声、讹误对分类的影响。(当然这个可能需要更具体的工程流程展示才会比较清楚,感兴趣的读者可以进一步了解)
循环神经网络(RNN)
它要解决的问题是什么呢?是上下文场景记忆的问题。
上文提到的神经网络模型都不能解决“记忆暂存功能”(对比较远期输入的内容无法进行量化,与当前内容一起反应到网络中进行训练),循环神经网络可以解决,在自然语言处理(NLP)中也应用最广泛。
在讲RNN如何实现上下文场景记忆问题时,无法跳过的一个基础是:隐马尔可夫模型(HMM)。隐马尔可夫模型中,有马尔可夫链。马尔可夫链的核心是:在给定当前知识和信息的前提下,观察对象过去的历史状态,对将来的预测来说是无关的。在RNN中,隐含状态下的马尔可夫链会处理神经元之间的信息传递。
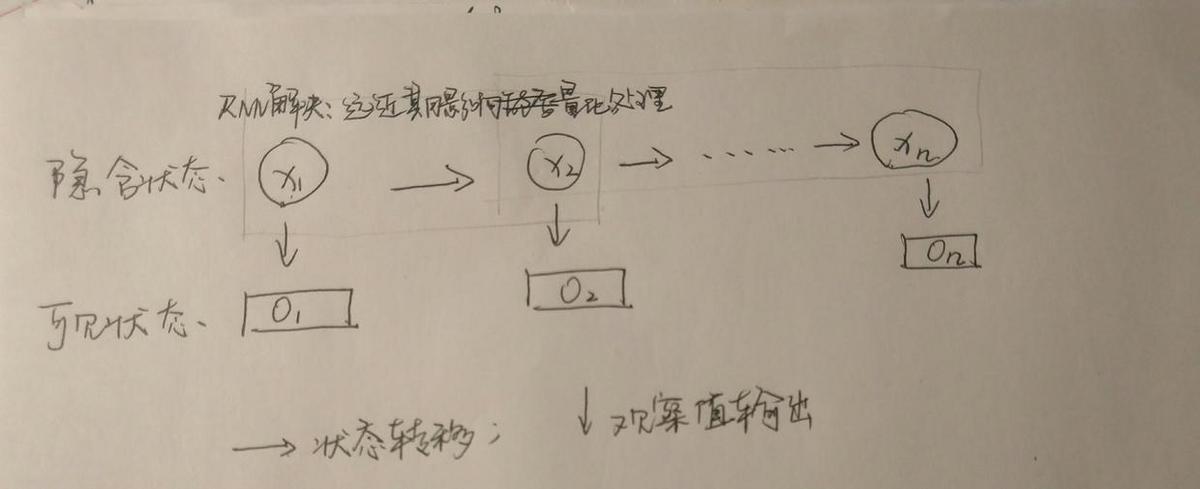
不过,理论上RNN是行得通的,但在实践上工程师们发现训练效果并不佳,所以现在用了LSTM(Long Short-Term Memory,长短期记忆网络)来取代传统的RNN。LSTM规避了传统RNN中遇到的问题,并启动了一个有效的机制:忘记门(Forget Gate),在训练过程中LSTM会把有潜在影响的关系学习,忽略无效(不具有影响)的关系。
LSTM目前应用在翻译器、聊天机器人、分类器等场景。
说到局限性,训练过程中,目前只支持相对固定、边界划定清晰的场景,LSTM对多场景问题也是无能为力的(这也是深度学习所有网络模型没有本质突破的问题,观点取自参考书籍)。
深度残差网络(DRN)
它要解决的问题是:传统深度学习网络中,网络到一定深度后,学习率、准确率会下降的问题。目前,DRN在图像分类、对象检测、语义分割等领域都有较好的识别确信度。
强化学习、对抗学习、其他
强化学习(Reinforcement Learning)和对抗学习,相对来说,都是深度学习比较前沿的部分。
强化学习,严格来说,是AI在训练中得到策略的训练过程,强调的是一个过程,而不同于上述各种神经网络强调的是搭建模型的方式。
那强化学习要解决的问题是什么?上面我们提到的神经网络大部分是在完成分类问题,判断样本标签类别等,那机器如何更智能表现呢?强化学习就作为一种机器自学习的状态,来解决上面神经网络相对来说需干预才可学习的局限。比如在AlphaGo围棋学习中,就会用到强化学习这样的自学习过程。
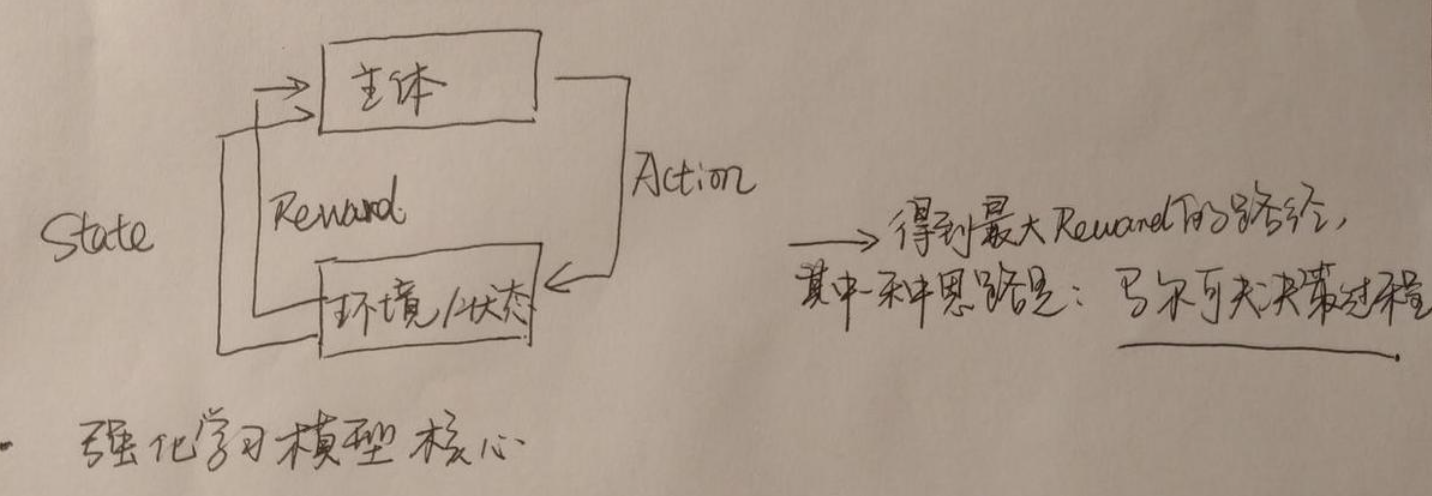
强化学习模型核心
强化学习要做的主要有两步:
- 将奖励、损失定义好
- 以主体较低成本不断尝试,总结不同状态(State)下,奖励(Reward)大的工作方式。(其中一种思路就是上图提到的马尔可夫决策过程,可参照RNN部分)
对抗学习,目前主要是指生成对抗网络(Generative Adversarial Networks,GAN)。GAN是通过模拟一种数据概率分布的生成器,使得概率分布与观测数据的概率统计分布一致或者尽可能接近。这个过程涉及纳什均衡中的博弈机制,具体包括在训练中,判别模型(Discriminative Model)——尽可能提取特征正确率增加的模型,生成模型(Generative Model)——尽可能“伪造”让判别模型以为是真的结果。
其他,还有相对更前沿的,包括条件生成对抗网络(CGAN)、深度卷积对抗网络(DCGAN)等等。这些前沿方向,对应解决的,包括对抗学习稳定性不高、训练数据还原度及质量水平等问题。
到这里,全文梳理了深度学习的基本元素、目前比较核心的神经网络模型、较为前沿的训练模式,以及它们要解决的问题、在实践中对应的局限。如果想进一步了解深度学习,你下一步可以学习的方向是:在这个框架之下,基于更具体的算法、问题与案例,实践代码工程。
本文是作者学习《白话深度学习与TensorFlow》一书后的笔记与复盘,其中算法模型大部分参考此书。欢迎交流AI相关,Wechat:Danbchpk
作者:何沛宽
原文地址:http://36kr.com/p/5119949.html
版权:人人都是产品经理遵循行业规范,任何转载的稿件都会明确标注作者和来源,若标注有误,请联系主编QQ:419297645
编辑:编辑部
来源公众号:新智元(ID:AI_era),“智能+”中国主平台,致力于推动中国从“互联网+”迈向“智能+”。
本文由人人都是产品经理合作媒体 @新智元 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!


