起点课堂会员权益
起点课堂会员权益谷歌最新机器学习术语表:A-L的定义解释(上)

谷歌在不久前发布了机器学习术语表,本文主要列出A-L的机器学习术语和TensorFlow 专用术语的定义,与大家一起探讨学习。
一、A
1.A/B 测试 (A/B testing)
一种统计方法,用于将两种或多种技术进行比较,通常是将当前采用的技术与新技术进行比较。A/B 测试不仅旨在确定哪种技术的效果更好,而且还有助于了解相应差异是否具有显著的统计意义。
A/B 测试通常是采用一种衡量方式对两种技术进行比较,但也适用于任意有限数量的技术和衡量方式。
2.准确率 (accuracy)
分类模型的正确预测所占的比例。在多类别分类中,准确率的定义如下:

在二元分类中,准确率的定义如下:

请参阅真正例和真负例。
3.激活函数 (activation function)
一种函数(例如 ReLU 或 S 型函数),用于对上一层的所有输入求加权和,然后生成一个输出值(通常为非线性值),并将其传递给下一层。
4.AdaGrad
一种先进的梯度下降法,用于重新调整每个参数的梯度,以便有效地为每个参数指定独立的学习速率。如需查看完整的解释,请参阅这篇论文。
5.ROC 曲线下面积 (AUC, Area under the ROC Curve)
一种会考虑所有可能分类阈值的评估指标。
ROC 曲线下面积是,对于随机选择的正类别样本确实为正类别,以及随机选择的负类别样本为正类别,分类器更确信前者的概率。
二、B
1.反向传播算法 (backpropagation)
在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
2.基准 (baseline)
一种简单的模型或启发法,用作比较模型效果时的参考点。基准有助于模型开发者针对特定问题量化最低预期效果。
3.批次 (batch)
模型训练的一次迭代(即一次梯度更新)中使用的样本集。
另请参阅批次规模。
4.批次规模 (batch size)
一个批次中的样本数。例如:SGD 的批次规模为1,而小批次的规模通常介于10到1000之间。批次规模在训练和推断期间通常是固定的。不过,TensorFlow 允许使用动态批次规模。
5.偏差 (bias)
距离原点的截距或偏移。偏差(也称为偏差项)在机器学习模型中以b或w0表示。例如:在下面的公式中,偏差为b
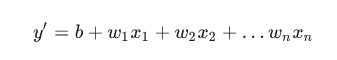
请勿与预测偏差混淆。
6.二元分类 (binary classification)
一种分类任务,可输出两种互斥类别之一。例如:对电子邮件进行评估并输出“垃圾邮件”或“非垃圾邮件”的机器学习模型就是一个二元分类器。
7.分箱 (binning)
请参阅分桶。
8.分桶 (bucketing)
将一个特征(通常是连续特征)转换成多个二元特征(称为桶或箱),通常是根据值区间进行转换。
例如:您可以将温度区间分割为离散分箱,而不是将温度表示成单个连续的浮点特征。
假设温度数据可精确到小数点后一位,则可以将介于0.0到15.0度之间的所有温度都归入一个分箱,将介于15.1到30.0度之间的所有温度归入第二个分箱,并将介于 30.1 到 50.0 度之间的所有温度归入第三个分箱。
三、C
1.校准层 (calibration layer)
一种预测后调整,通常是为了降低预测偏差。调整后的预测和概率应与观察到的标签集的分布一致。
2.候选采样 (candidate sampling)
一种训练时进行的优化,会使用某种函数(例如 softmax)针对所有正类别标签计算概率,但对于负类别标签,则仅针对其随机样本计算概率。
例如:如果某个样本的标签为“小猎犬”和“狗”,则候选采样将针对“小猎犬”和“狗”类别输出,以及其他类别(猫、棒棒糖、栅栏)的随机子集计算预测概率和相应的损失项。
这种采样基于的想法是,只要正类别始终得到适当的正增强,负类别就可以从频率较低的负增强中进行学习,这确实是在实际中观察到的情况。候选采样的目的是——通过不针对所有负类别计算预测结果来提高计算效率。
3.分类数据 (categorical data)
一种特征,拥有一组离散的可能值。以某个名为 house style 的分类特征为例:该特征拥有一组离散的可能值(共三个),即 :Tudor、ranch、 colonial。
通过将 house style 表示成分类数据,相应模型可以学习 Tudor、ranch 和 colonial 分别对房价的影响。
有时,离散集中的值是互斥的,只能将其中一个值应用于指定样本。例如:car maker 分类特征可能只允许一个样本有一个值 (Toyota)。在其他情况下,则可以应用多个值。
一辆车可能会被喷涂多种不同的颜色,因此,car color分类特征可能会允许单个样本具有多个值(例如:red和white)。
分类特征有时称为离散特征,与数值数据相对。
4.检查点 (checkpoint)
一种数据,用于捕获模型变量在特定时间的状态。借助检查点,可以导出模型权重,跨多个会话执行训练,以及使训练在发生错误之后得以继续(例如作业抢占)。
请注意,图本身不包含在检查点中。
5.类别 (class)
为标签枚举的一组目标值中的一个。例如:在检测垃圾邮件的二元分类模型中,两种类别分别是:“垃圾邮件”和“非垃圾邮件”;在识别狗品种的多类别分类模型中,类别可以是:“贵宾犬”、“小猎犬”、“哈巴犬”等等。
4.分类不平衡的数据集 (class-imbalanced data set)
一种二元分类问题。在此类问题中,两种类别的标签在出现频率方面具有很大的差距。
例如:在某个疾病数据集中,0.0001 的样本具有正类别标签,0.9999 的样本具有负类别标签,这就属于分类不平衡问题;但在某个足球比赛预测器中,0.51 的样本的标签为其中一个球队赢,0.49的样本的标签为另一个球队赢,这就不属于分类不平衡问题。
5.分类模型 (classification model)
一种机器学习模型,用于区分两种或多种离散类别。例如:某个自然语言处理分类模型可以确定输入的句子是法语、西班牙语还是意大利语。请与回归模型进行比较。
6.分类阈值 (classification threshold)
一种标量值条件,应用于模型预测的得分,旨在——将正类别与负类别区分开,将逻辑回归结果映射到二元分类时使用。
以某个逻辑回归模型为例:该模型用于确定指定电子邮件是垃圾邮件的概率。如果分类阈值为 0.9,那么逻辑回归值高于 0.9 的电子邮件将被归类为“垃圾邮件”,低于 0.9 的则被归类为“非垃圾邮件”。
7.协同过滤 (collaborative filtering)
根据很多其他用户的兴趣来预测某位用户的兴趣,协同过滤通常用在推荐系统中。
8.混淆矩阵 (confusion matrix)
一种 NxN 表格,用于总结分类模型的预测成效,即——标签和模型预测的分类之间的关联。在混淆矩阵中,一个轴表示模型预测的标签,另一个轴表示实际标签,N 表示类别个数。在二元分类问题中,N=2。
例如,下面显示了一个二元分类问题的混淆矩阵示例:

上面的混淆矩阵显示:在19个实际有肿瘤的样本中,该模型正确地将18个归类为有肿瘤(18个真正例),错误地将1个归类为没有肿瘤(1个假负例)。同样,在458个实际没有肿瘤的样本中,模型归类正确的有452个(452 个真负例),归类错误的有6个(6个假正例)。
多类别分类问题的混淆矩阵有助于确定出错模式。
例如:某个混淆矩阵可以揭示,某个经过训练以识别手写数字的模型往往会将4错误地预测为9,将7错误地预测为1。混淆矩阵包含计算各种效果指标(包括精确率和召回率)所需的充足信息。
10.连续特征 (continuous feature)
一种浮点特征,可能值的区间不受限制,与离散特征相对。
11.收敛 (convergence)
通俗来说,收敛通常是指:在训练期间达到的一种状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变化都非常小或根本没有变化。也就是说,如果采用当前数据进行额外的训练将无法改进模型,模型即达到收敛状态。
在深度学习中,损失值有时会在最终下降之前的多次迭代中保持不变或几乎保持不变,暂时形成收敛的假象。
另请参阅早停法。
另请参阅 Boyd 和 Vandenberghe 合著的 Convex Optimization(《凸优化》)。
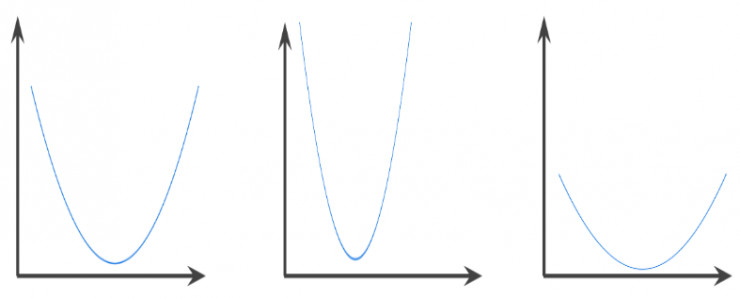
12.凸函数 (convex function)
一种函数,函数图像以上的区域为凸集。典型凸函数的形状类似于字母U。例如,以下都是凸函数:
相反,以下函数则不是凸函数。请注意图像上方的区域如何不是凸集:
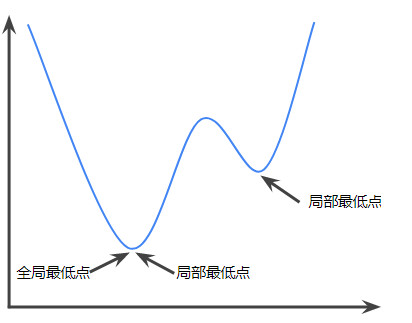
严格凸函数只有一个局部最低点,该点也是全局最低点。经典的 U 形函数都是严格凸函数。不过,有些凸函数(例如直线)则不是这样。
很多常见的损失函数(包括下列函数)都是凸函数:
- L2 损失函数
- 对数损失函数
- L1 正则化
- L2 正则化
梯度下降法的很多变体,都一定能找到一个接近严格凸函数最小值的点。同样,随机梯度下降法的很多变体,都有很高的可能性能够找到接近严格凸函数最小值的点(但并非一定能找到)。
两个凸函数的和(例如 L2 损失函数 + L1 正则化)也是凸函数。
深度模型绝不会是凸函数。值得注意的是:专门针对凸优化设计的算法,往往总能在深度网络上找到非常好的解决方案,虽然这些解决方案并不一定对应于全局最小值。
13.凸优化 (convex optimization)
使用数学方法(例如:梯度下降法)寻找凸函数最小值的过程。机器学习方面的大量研究都是专注于如何通过公式将各种问题表示成凸优化问题,以及如何更高效地解决这些问题。
如需完整的详细信息,请参阅 Boyd 和 Vandenberghe 合著的 Convex Optimization(《凸优化》)。
14.凸集 (convex set)
欧几里得空间的一个子集,其中任意两点之间的连线仍完全落在该子集内。例如,下面的两个图形都是凸集:

相反,下面的两个图形都不是凸集:
15.成本 (cost)
16.交叉熵 (cross-entropy)
对数损失函数向多类别分类问题进行的一种泛化。交叉熵可以量化两种概率分布之间的差异。另请参阅困惑度。
17.自定义 Estimator (custom Estimator)
您按照这些说明自行编写的 Estimator,与预创建的 Estimator 相对。
四、D
1.数据集 (data set)
一组样本的集合。
2.Dataset API (tf.data)
一种高级别的 TensorFlow API,用于读取数据并将其转换为机器学习算法所需的格式。
tf.data.Dataset 对象表示一系列元素,其中每个元素都包含一个或多个张量。tf.data.Iterator 对象可获取 Dataset 中的元素。
如需详细了解 Dataset API,请参阅《TensorFlow 编程人员指南》中的导入数据。
3.决策边界 (decision boundary)
在二元分类或多类别分类问题中,模型学到的类别之间的分界线。例如:在以下表示某个二元分类问题的图片中,决策边界是橙色类别和蓝色类别之间的分界线:

4.密集层 (dense layer)
是全连接层的同义词。
5.深度模型 (deep model)
一种神经网络,其中包含多个隐藏层。深度模型依赖于可训练的非线性关系,与宽度模型相对。
6.密集特征 (dense feature)
一种大部分数值是非零值的特征,通常是一个浮点值张量。参照稀疏特征。
7.衍生特征 (derived feature)
8.离散特征 (discrete feature)
一种特征,包含有限个可能值。例如:某个值只能是“动物”、“蔬菜”、“矿物”的特征便是一个离散特征(或分类特征),与连续特征相对。
9.丢弃正则化 (dropout regularization)
一种形式的正则化,在训练神经网络方面非常有用。丢弃正则化的运作机制是,在神经网络层的一个梯度步长中移除随机选择的固定数量的单元。丢弃的单元越多,正则化效果就越强。这类似于训练神经网络以模拟较小网络的指数级规模集成学习。
如需完整的详细信息,请参阅 Dropout: A Simple Way to Prevent Neural Networks from Overfitting(《丢弃:一种防止神经网络过拟合的简单方法》)。
10.动态模型 (dynamic model)
一种模型,以持续更新的方式在线接受训练。也就是说,数据会源源不断地进入这种模型。
五、E
1.早停法 (early stopping)
一种正则化方法,涉及在训练损失仍可以继续减少之前结束模型训练。使用早停法时,您会在基于验证数据集的损失开始增加(也就是泛化效果变差)时结束模型训练。
2.嵌套 (embeddings)
一种分类特征,以连续值特征表示。通常,嵌套是指将高维度向量映射到低维度的空间。例如:您可以采用以下两种方式之一来表示英文句子中的单词。
- 表示成包含百万个元素(高维度)的稀疏向量,其中所有元素都是整数。向量中的每个单元格都表示一个单独的英文单词,单元格中的值表示相应单词在句子中出现的次数。由于单个英文句子包含的单词不太可能超过 50 个,因此向量中几乎每个单元格都包含 0。少数非 0 的单元格中将包含一个非常小的整数(通常为 1),该整数表示相应单词在句子中出现的次数。
- 表示成包含数百个元素(低维度)的密集向量,其中每个元素都包含一个介于 0 到 1 之间的浮点值。
这就是一种嵌套。
在 TensorFlow 中,会按反向传播损失训练嵌套,和训练神经网络中的任何其他参数时一样。
3.经验风险最小化 (ERM, empirical risk minimization)
用于选择可以将基于训练集的损失降至最低的模型函数,与结构风险最小化相对。
4.集成学习 (ensemble)
多个模型的预测结果的并集。您可以通过以下一项或多项来创建集成学习:
- 不同的初始化
- 不同的超参数
- 不同的整体结构
深度模型和宽度模型属于一种集成学习。
5.周期 (epoch)
在训练时,整个数据集的一次完整遍历,以便不漏掉任何一个样本。因此,一个周期表示(N/批次规模)次训练迭代,其中 N 是样本总数。
6.Estimator
tf.Estimator 类的一个实例,用于封装负责构建 TensorFlow 图并运行 TensorFlow 会话的逻辑。您可以创建自己的自定义 Estimator(如需相关介绍,请点击此处),也可以将其他人预创建的 Estimator 实例化。
7.样本 (example)
数据集的一行。一个样本包含一个或多个特征,此外还可能包含一个标签。另请参阅有标签样本和无标签样本。
六、F
1.假负例 (FN, false negative)
被模型错误地预测为负类别的样本。例如:模型推断出某封电子邮件不是垃圾邮件(负类别),但该电子邮件其实是垃圾邮件。
2.假正例 (FP, false positive)
被模型错误地预测为正类别的样本。例如:模型推断出某封电子邮件是垃圾邮件(正类别),但该电子邮件其实不是垃圾邮件。
3.假正例率(false positive rate, 简称 FP 率)
ROC 曲线中的 x 轴。FP 率的定义如下:

4.特征 (feature)
在进行预测时使用的输入变量。
5.特征列 (FeatureColumns)
一组相关特征,例如:用户可能居住的所有国家/地区的集合,样本的特征列中可能包含一个或多个特征。
TensorFlow 中的特征列内还封装了元数据,例如:
- 特征的数据类型
- 特征是固定长度还是应转换为嵌套
特征列可以包含单个特征。
“特征列”是 Google 专用的术语。特征列在 Yahoo/Microsoft 使用的 VW 系统中称为“命名空间”,也称为场。
6.特征组合 (feature cross)
通过将单独的特征进行组合(相乘或求笛卡尔积)而形成的合成特征,特征组合有助于表示非线性关系。
7.特征工程 (feature engineering)
指以下过程:确定哪些特征可能在训练模型方面非常有用,然后将日志文件及其他来源的原始数据转换为所需的特征。
在 TensorFlow 中,特征工程通常是指将原始日志文件条目转换为 tf.Example proto buffer。另请参阅 tf.Transform。
特征工程有时称为特征提取。
8.特征集 (feature set)
训练机器学习模型时采用的一组特征。例如,对于某个用于预测房价的模型,邮政编码、房屋面积以及房屋状况可以组成一个简单的特征集。
9.特征规范 (feature spec)
用于描述如何从 tf.Example proto buffer 提取特征数据。由于 tf.Example proto buffer 只是一个数据容器,因此您必须指定以下内容:
- 要提取的数据(即特征的键)
- 数据类型(例如 float 或 int)
- 长度(固定或可变)
Estimator API 提供了一些可用来根据给定 FeatureColumns 列表生成特征规范的工具。
10.完整 softmax (full softmax)
请参阅 softmax。与候选采样相对。
11.全连接层 (fully connected layer)
一种隐藏层,其中的每个节点均与下一个隐藏层中的每个节点相连。全连接层又称为密集层。
七、G
1.泛化 (generalization)
指的是:模型依据训练时采用的数据,针对以前未见过的新数据做出正确预测的能力。
2.广义线性模型 (generalized linear model)
最小二乘回归模型(基于高斯噪声)向其他类型的模型(基于其他类型的噪声,例如泊松噪声或分类噪声)进行的一种泛化。广义线性模型的示例包括:
- 逻辑回归
- 多类别回归
- 最小二乘回归
可以通过凸优化找到广义线性模型的参数。
广义线性模型具有以下特性:
- 最优的最小二乘回归模型的平均预测结果等于训练数据的平均标签。
- 最优的逻辑回归模型预测的平均概率等于训练数据的平均标签。
广义线性模型的功能受其特征的限制。与深度模型不同,广义线性模型无法“学习新特征”。
3.梯度 (gradient)
偏导数相对于所有自变量的向量。在机器学习中,梯度是模型函数偏导数的向量。梯度指向最速上升的方向。
4.梯度裁剪 (gradient clipping)
在应用梯度值之前先设置其上限。梯度裁剪有助于确保数值稳定性以及防止梯度爆炸。
5.梯度下降法 (gradient descent)
一种通过计算并且减小梯度将损失降至最低的技术,它以训练数据为条件,来计算损失相对于模型参数的梯度。
通俗来说,梯度下降法以迭代方式调整参数,逐渐找到权重和偏差的最佳组合,从而将损失降至最低。
6.图 (graph)
TensorFlow 中的一种计算规范,图中的节点表示操作,边缘具有方向,表示将某项操作的结果(一个张量)作为一个操作数传递给另一项操作。可以使用 TensorBoard 直观呈现图。
八、H
1.启发法 (heuristic)
一种非最优但实用的问题解决方案,足以用于进行改进或从中学习。
2.隐藏层 (hidden layer)
神经网络中的合成层,介于输入层(即特征)和输出层(即预测)之间。神经网络包含一个或多个隐藏层。
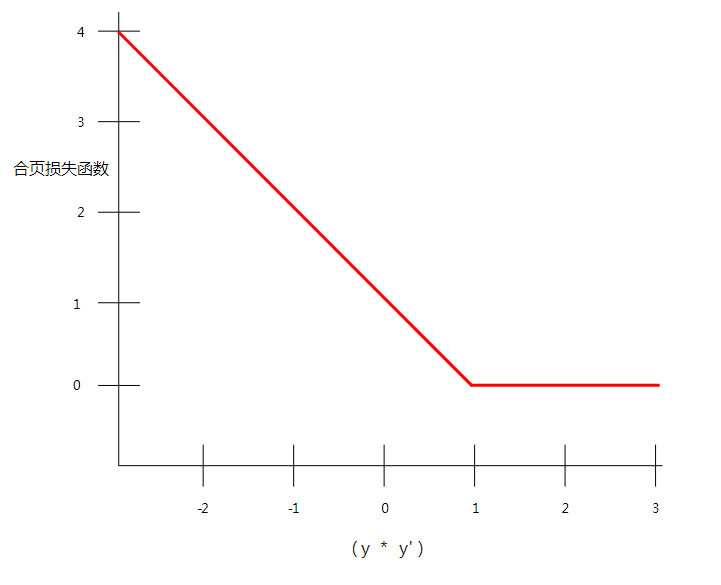
3.合页损失函数 (hinge loss)
一系列用于分类的损失函数,旨在找到距离每个训练样本都尽可能远的决策边界,从而使样本和边界之间的裕度最大化。KSVM 使用合页损失函数(或相关函数,例如平方合页损失函数)。对于二元分类,合页损失函数的定义如下:
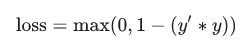
其中“y’”表示分类器模型的原始输出:
![]()
“y”表示真标签,值为 -1 或 +1。
因此,合页损失与 (y * y’) 的关系图如下所示:
4.维持数据 (holdout data)
训练期间故意不使用(“维持”)的样本,验证数据集和测试数据集都属于维持数据。维持数据有助于评估模型向训练时所用数据之外的数据进行泛化的能力,与基于训练数据集的损失相比,基于维持数据集的损失,有助于更好地估算基于未见过的数据集的损失。
5.超参数 (hyperparameter)
在模型训练的连续过程中,您调节的“旋钮”。例如:学习速率就是一种超参数,与参数相对。
6.超平面 (hyperplane)
将一个空间划分为两个子空间的边界。例如:在二维空间中,直线就是一个超平面,在三维空间中,平面则是一个超平面。
在机器学习中更典型的是:超平面是分隔高维度空间的边界,核支持向量机利用超平面将正类别和负类别区分开来(通常是在极高维度空间中)。
九、I
1.独立同分布 (i.i.d, independently and identically distributed)
从不会改变的分布中提取的数据,其中提取的每个值都不依赖于之前提取的值。i.i.d. 是机器学习的理想气体 – 一种实用的数学结构,但在现实世界中几乎从未发现过。
例如:某个网页的访问者在短时间内的分布可能为 i.i.d.,即——分布在该短时间内没有变化,且一位用户的访问行为通常与另一位用户的访问行为无关。不过,如果将时间窗口扩大,网页访问者的分布可能呈现出季节性变化。
2.推断 (inference)
在机器学习中,推断通常指以下过程:通过将训练过的模型应用于无标签样本来做出预测。
在统计学中,推断是指在某些观测数据条件下拟合分布参数的过程。(请参阅维基百科中有关统计学推断的文章。)
3.输入函数 (input function)
在 TensorFlow 中,用于将输入数据返回到 Estimator 的训练、评估或预测方法的函数。例如:训练输入函数用于返回训练集中的批次特征和标签。
4.输入层 (input layer)
神经网络中的第一层(接收输入数据的层)。
5.实例 (instance)
是样本的同义词。
6.可解释性 (interpretability)
模型的预测可解释的难易程度,深度模型通常不可解释。也就是说,很难对深度模型的不同层进行解释。相比之下,线性回归模型和宽度模型的可解释性通常要好得多。
7.评分者间一致性信度 (inter-rater agreement)
一种衡量指标,用于衡量在执行某项任务时评分者达成一致的频率。如果评分者未达成一致,则可能需要改进任务说明。有时也称为注释者间一致性信度或评分者间可靠性信度。
另请参阅 Cohen’s kappa(最热门的评分者间一致性信度衡量指标之一)。
8.迭代 (iteration)
模型的权重在训练期间的一次更新,迭代包含计算参数在单个批量数据上的梯度损失。
十、K
1.Keras
一种热门的 Python 机器学习 API。Keras 能够在多种深度学习框架上运行,其中包括 TensorFlow(在该框架上,Keras 作为 tf.keras 提供)。
2.核支持向量机 (KSVM, Kernel Support Vector Machines)
一种分类算法,旨在通过将输入数据向量映射到更高维度的空间,来最大化正类别和负类别之间的裕度。
以某个输入数据集包含一百个特征的分类问题为例:为了最大化正类别和负类别之间的裕度,KSVM 可以在内部将这些特征映射到百万维度的空间。
KSVM 使用合页损失函数。
十一、L
1.L1 损失函数 (L₁ loss)
一种损失函数,基于模型预测的值与标签的实际值之差的绝对值。与 L2 损失函数相比,L1 损失函数对离群值的敏感性弱一些。
2.L1 正则化 (L₁ regularization)
一种正则化,根据权重的绝对值的总和来惩罚权重。在依赖稀疏特征的模型中,L1 正则化有助于使不相关或几乎不相关的特征的权重正好为 0,从而将这些特征从模型中移除,与 L2 正则化相对。
3.L2 损失函数 (L₂ loss)
请参阅平方损失函数。
4.L2 正则化 (L₂ regularization)
一种正则化,根据权重的平方和来惩罚权重。L2 正则化有助于使离群值(具有较大正值或较小负值)权重接近于 0,但又不正好为 0(与 L1 正则化相对)。在线性模型中,L2 正则化始终可以改进泛化。
5.标签 (label)
在监督式学习中,标签指样本的“答案”或“结果”部分。有标签数据集中的每个样本都包含一个或多个特征以及一个标签。
例如:在房屋数据集中,特征可以包括:卧室数、卫生间数以及房龄,而标签则可以是房价。在垃圾邮件检测数据集中,特征可以包括:主题行、发件人以及电子邮件本身;而标签则可以是“垃圾邮件”或“非垃圾邮件”。
6.有标签样本 (labeled example)
包含特征和标签的样本,在监督式训练中,模型从有标签样本中进行学习。
7.lambda
(多含义术语,我们在此关注的是该术语在正则化中的定义。)
8.层 (layer)
神经网络中的一组神经元,处理一组输入特征,或一组神经元的输出。此外还指 TensorFlow 中的抽象层。
层是 Python 函数,以张量和配置选项作为输入,然后生成其他张量作为输出。当必要的张量组合起来,用户便可以通过模型函数将结果转换为 Estimator。
9.Layers API (tf.layers)
一种 TensorFlow API,用于以层组合的方式构建深度神经网络。通过 Layers API,您可以构建不同类型的层,例如:
- 通过 tf.layers.Dense 构建全连接层。
- 通过 tf.layers.Conv2D 构建卷积层。
在编写自定义 Estimator 时,您可以编写“层”对象来定义所有隐藏层的特征。
Layers API 遵循 [Keras](#Keras) layers API 规范。也就是说——除了前缀不同以外,Layers API 中的所有函数均与 Keras layers API 中的对应函数具有相同的名称和签名。
10.学习速率 (learning rate)
在训练模型时用于梯度下降的一个变量。在每次迭代期间,梯度下降法都会将学习速率与梯度相乘,得出的乘积称为梯度步长。
学习速率是一个重要的超参数。
11.最小二乘回归 (least squares regression)
一种通过最小化 L2 损失训练出的线性回归模型。
12.线性回归 (linear regression)
一种回归模型,通过将输入特征进行线性组合,以连续值作为输出。
13.逻辑回归 (logistic regression)
一种模型,通过将 S 型函数应用于线性预测,生成分类问题中每个可能的离散标签值的概率。
虽然逻辑回归经常用于二元分类问题,但也可用于多类别分类问题(其叫法变为多类别逻辑回归或多项回归)。
14.对数损失函数 (Log Loss)
二元逻辑回归中使用的损失函数。
15.损失 (Loss)
一种衡量指标,用于衡量模型的预测偏离其标签的程度。或者更悲观地说是衡量模型有多差。要确定此值,模型必须定义损失函数。
例如:线性回归模型通常将均方误差用于损失函数,而逻辑回归模型则使用对数损失函数。
作者:思颖
来源:https://www.leiphone.com/news/201803/01zalRgbQYSnTWMI.html
本文来源于人人都是产品经理合作媒体@雷锋网,作者@思颖
题图来自 Unsplash ,基于 CC0 协议






- 目前还没评论,等你发挥!