
 起点课堂会员权益
起点课堂会员权益数据分析的准备工作:从问题分析到数据清洗
本文给大家介绍一下数据分析前的准备工作,一共分为四部分:首先是对问题的分析,其次是数据的收集,然后是数据的预处理,最后是数据的预分析。

先复习一下前几天,我们学习了数据分析的框架:
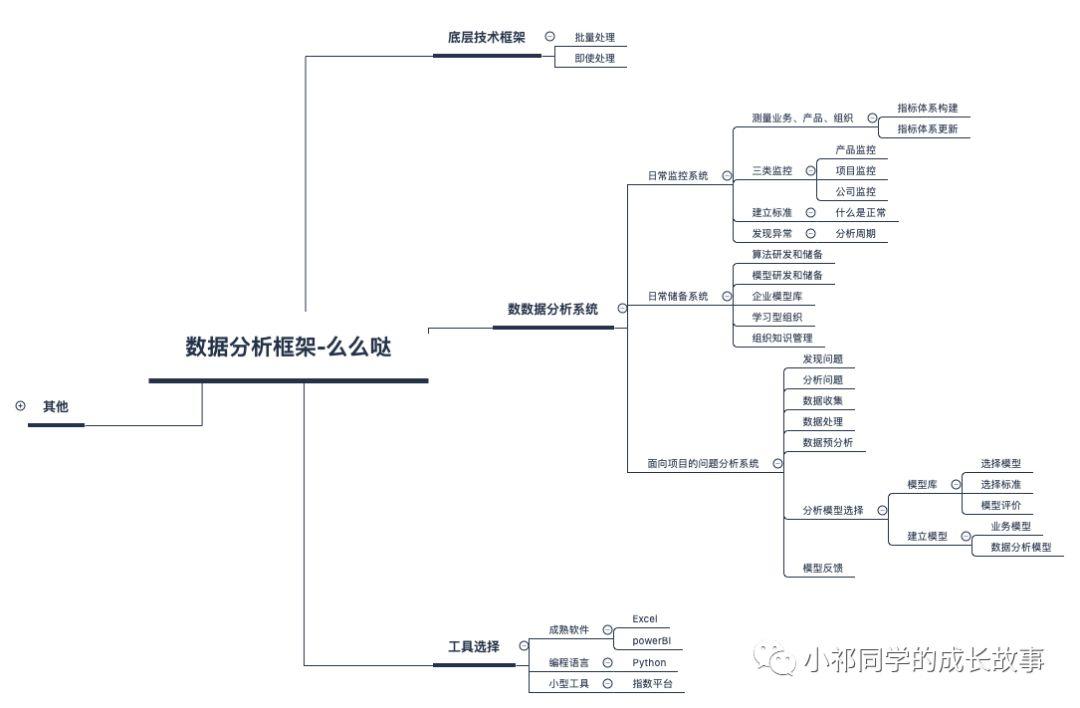
今天我们开始对框架进行详细的拆解:
今天首先给大家介绍一下数据分析前的准备工作,一共分为四部分:首先是对问题的分析,其次是数据的收集,然后是数据的预处理,最后是数据的预分析。
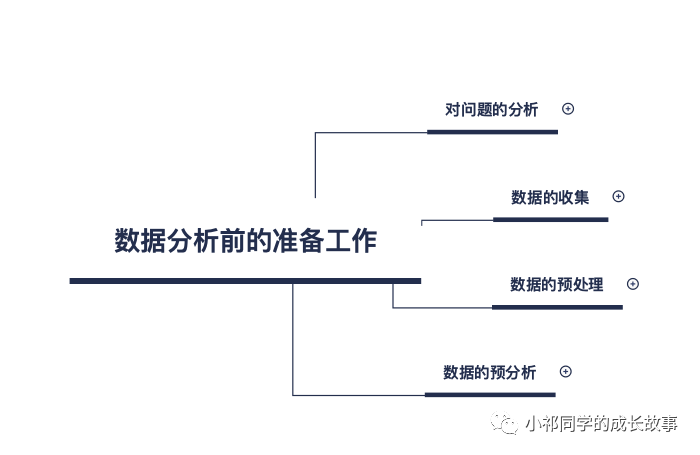
首先是对问题的分析:
对问题的分析不是今天想要说的重点,但是为了框架的完整性,今天做一些简单的介绍。关于对问题本身的分析,人类的知识体系在这方面沉淀了大量的智慧和经验。
其中尤其是以维特根斯坦的语言哲学分析,还有诺贝尔奖得主西蒙的满意决策论,还有大量关于宗教哲学政治关于标准和价值观方面探讨的积累。任何一个纬度的叙述,都有可能会穷尽一个人一生的经历。所以今天只能点到为止,简单给大家做一个介绍。
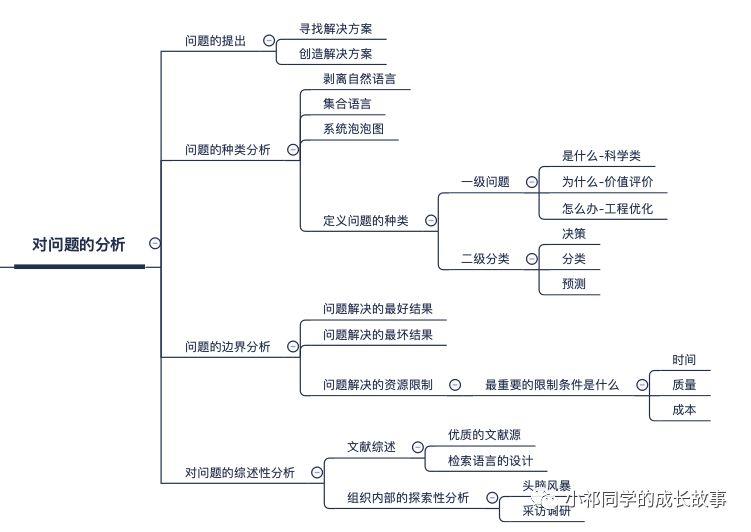
关于问题的提出
首先是关于问题的提出。
问题的提出可能来自老板,也可能来自同事。关于公司人际关系的分析,不是我们探讨的重点。当然这一点在实际工作中尤其重要,因为每个人的精力都是有限的,然而每个人面对的任务其实是无限的,我们必须有选择的去完成一些对我们同时对公司重要的项目。
我们首先来看一下,当我们面对一个提出的问题的时候,我们是在提问什么?
在大多数时候都觉得当我们需要去解决一个问题的时候,我们需要创造性的提供一种解决方案,实际情况可能和我们的常识不是很一样。
我们可以想象这样一种情景:
通常认为,在回答一个问题之前,你必须提出那个问题。或者,换个比喻的说法,要找的东西必须是已经丢失的东西。
但这是不是真的呢?当一个人发现了一个金矿脉时,是不是大自然丢失了这个金矿脉呢?
如果我们能找到我们不曾丢失的金子,我们就有可能回答我们未曾问过的问题。
现实工作中,我们很多时候当面对一个问题的时候,我们往往需要自己寻找一个解决方案,而不是去创造一个解决方法,所以我们工作的重点应该是怎么去和我们已有的积累形成联系,或者用更加数学化的语言描述说。怎么将现实问题映射到我们的模型空间中去,这应该是我们的工作重点。
关于问题种类的分析
有问题种类的分析,我们先来看一下我们为什么要分析一个问题的种类。现实中我们面临的实际问题,它的表达形式可能是千变万化的。然而我们资源是有限的,又不能为每一种问题都去积累经验,都去建立模型。我们只能为一些包含重要特征的问题,去建立模型空间。
所以当我们面临一个问题的时候,首先应该去看一下这个问题,它本质上在说什么,它的标准形式是什么样的。
这个过程中,我们首先要做的第一步需要剥离自然语言。这一点比较容易理解,我们平时在说话的过程中,语言中有很多冗余的成分。我们首先要做的就是把这些冗余的成分删除掉,其次是把我们一些似是而非的名词替换成我们的标准名词。经过对自然语言的整理之后,我们更容易发现一个问题的本质。
举个例子:可能大家会更加明白,比如:甲方爸爸给了这样一个需求:俺们公司最近遇到了一件特别闹心的事情,一举办活动,活跃用户就少很多,我们很着急,你们快来帮我们看看巴拉巴拉。
以上这段话转化一下就是: 举办活动 和 活跃用户的相关性分析。
用集合的语言和系统泡泡图,去重新描述问题。去把一个在复杂现实情景中的问题,转化为若干研究对象和这些研究对象之间的关系的问题。
当工作进行到这一步的时候,我们就已经已经可以清晰的看出一个问题说出的类别了。 一般在世界上所有的问题都大概可以分为三类:
- 首先是一类探索是什么的问题,也就是关于一些科学性的问题。这一类问题的核心特征是科学研究中对准确率要求非常高,一般要达到99.7%以上。在工作中,要求可能并不需要这么高。
- 还有一类问题是关于为什么的问题,也就是关于一些价值评价标准的问题。日常所说的宗教哲学政治探讨的问题,都属于这个范畴。这个问题的特征是特别讲究多远,从本质上来看,各个价值观之间它们是没有可比性的。然而这只是理论上的,实际生活中还是会看到很多大家因为不同价值观真的面红耳赤的情况,这一类问题在研究过程中非常体现的是组织的价值观,还有上级的价值观。
- 还有一个问题是关于怎么办的问题,这一类问题本质上是属于一类工程问题。在这类问题中我们要注意的是,我们并不是像求解第一类是什么问题,要追求极高的准确率,我们追求的是在资源有限的情况下,我们如何把一件事情做到流畅,也就是60分到80分的样子。也就是说在大多数的时候,我们求解的不是最优解,我们求解的仅仅是一个满意解而已。 现实生活中我遇到遇到的本质性的三类问题,其他任何问题都可以转化为这三类问题,或者转化为这三类问题的组合。
这三类问题在模型空间里也有标准的对应形式,价值观的探索问题,本质是一类标记或者分类问题。关于是什么的探索问题,往往是一类预测相关性的问题。 关于怎么办一类的工程问题,本质上是一类关于过程描述模型和概率描述模型的问题。
对问题边界的边界分析
对问题的边界分析就是我们这个问题解决之后,最好可以达到什么样的效果,如果问题没有能够解决,最坏的结果是什么样的。
为什么我们要对问题进行边界分析?因为我们工作中,面临的大多数问题,都是在给定限制条件下寻求满意解,因为给定了资源限制,也给定了我们能力的边界。
从更深层次上来看,一个工程问题优化的空间永远都是有限的。
为什么呢?
因为从本质上来看首先对问题的测量就有很大误差,然后图灵机限制/哥德尔不完备定理/摩尔定律这些底层规律都对工程问题的优化做了边界上的限定。所以,千万不能以科学的态度和方法对待工程问题.。
那么我们如何对问题进行边界分析呢?这里给出一个参考思路,我们工作中往往面临来自三方面的限制:时间/质量/成本;我么可以选择一个必须达到要求的,然后去调节另外俩者的关系。
比如:我们现在要在放假之前,完成集中周作业/考试/谈恋爱等等若干项目,我们先抓住主要因素:时间,必须在放假之前完成,然后就是质量和成本的关系,成本方面可以削减项目,比如相比交作业和考试,恋爱就可以先不谈了,质量方面,追求中等质量,作业不返图,考试不挂科就可以.
数据的收集:
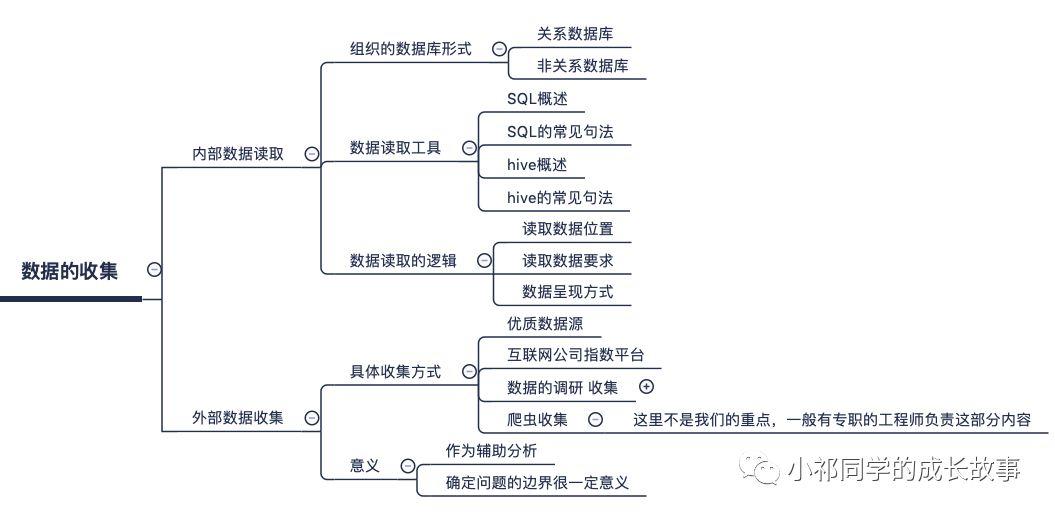
数据收集分为内部数据读取和外部数据收集俩部分,今天主要谈内部数据读取的问题。
内部数据收集
1. 数据库种类
关系型数据库,是指采用了关系模型来组织数据的数据库。关系模型是在1970年由IBM的研究员E.F.Codd博士首先提出的,在之后的几十年中,关系模型的概念得到了充分的发展并逐渐成为主流数据库结构的主流模型。
简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。
但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,用户A看到的内容和用户B看到同一用户C内容更新不一致是可以容忍的。或者说,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的。因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。
相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极高,关系型数据库已经无法应付(在读方面,传统上为了克服关系型数据库缺陷,提高性能,都是增加一级memcache来静态化网页。
而在SNS中,变化太快,memchache已经无能为力了),因此,必须用新的一种数据结构存储来代替关系数据库。
关系数据库的另一个特点就是其具有固定的表结构,因此,其扩展性极差,而在SNS中,系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库也难以应付,需要新的结构化数据存储。
于是,非关系型数据库应运而生,由于不可能用一种数据结构化存储应付所有的新的需求。因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。必须强调的是,数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库这员老将。
2. 数据库读取工具
SQL概述
结构化查询语言(Structured Query Language)简称SQL(发音:/ˈes kjuː ˈel/ “S-Q-L”),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统,同时也是数据库脚本文件的扩展名。
结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。
SQL语法总结:
- (选择全部)SELECT * from celebs;
- (创建表格)CREATE TABLE celebs (id INTEGER, name TEXT, age INTEGER); (插入行数据)INSERT INTO celebs (id, name, age) VALUES (1, ‘Justin Bieber’, 21);
- (选择某列)SELECT name FROM celebs;
- (更新信息)UPDATE celebs SET age = 22 WHERE id =1;
- (添加表列)ALTER TABLE celebs ADD COLUMN twitterhandle TEXT;
- (处理缺失值)DELETE FROM celebs WHERE twitterhandle IS NULL;
- (多变量筛选)SELECT name ,imdbrating FROM movies;
- (唯一筛选)SELECT DISTINCT genre FROM movies;
- (条件匹配)SELECT * FROM movies WHERE imdbrating > 8;
- (文本部分匹配单)SELECT * FROM movies WHERE name LIKE ‘Seen’;
- (文本部分匹配多)SELECT * FROM movies WHERE name LIKE ‘a%’ ;
- (范围内的数据)SELECT * FROM movies WHERE name BETWEEN ‘A’ AND ‘J’;
- (与条件选择)SELECT * FROM movies WHERE year BETWEEN 1990 AND 2000 AND genre = ‘comedy’;
- (或条件选择)SELECT * FROM movies WHERE genre = ‘comedy’ OR year < 1980;
- (排序)SELECT * FROM movies ORDER BY imdbrating DESC;
- (选取前几个)SELECT * FROM movies ORDER BY imdbrating ASC LIMIT 3;
- (计数)SELECT COUNT(* ) FROM fakeapps;
- (条件计数) SELECT COUNT(* ) FROM fakeapps WHERE price = 0;
- (分组计数)SELECT price ,COUNT(*) FROM fakeapps GROUP BY price;
- 等等等。
hive概述
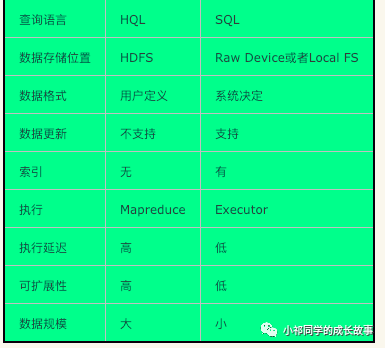
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hvie是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
Hive定义了简单的类SQL查询语句,称为HQL,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
由于Hive采用了SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。
本文将从多个方面来阐述Hive和数据库的差异,数据库可以用在Online的应用中,但是Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。传统数据库都使用的SQL语句,而Hive使用的是HQL语句,在大部分情况下其增删改查的语句都是类似的。因此广义上而言,学会了SQL语句的语法也就学会了HQL语句。
外部数据收集
外部数据的收集往往作为我们数据收集的补充,对于我们对问题获得一个外部性的概括认知有一定帮助。
优秀数据源:
- 国家数据 - http://data.stats.gov.cn/index.htm
- CEIC - http://www.ceicdata.com/zh-hans
- wind(万得)- http://www.wind.com.cn/
- 搜数网 - http://www.soshoo.com/
- 中国统计信息网 - http://www.tjcn.org/
- 亚马逊aws - http://aws.amazon.com/cn/datasets/?nc1=h_ls 来自亚马逊的跨科学云数据平台,包含化学、生物、经济等多个领域的数据集。
- figshare - https://figshare.com/ 研究成果共享平台,在这里你会发现来自世界的大牛们的研究成果分享,同时get其中的研究数据,内容很有启发性,网站颇具设计感。
- github - https://github.com/caesar0301/awesome-public-datasets 如果觉得前面的数据源还不够,github上的大神已经为大家整理好了一个非常全面的数据获取渠道,包含各个细分领域的数据库资源,自然科学和社会科学的覆盖都很全面,简直是做研究和数据分析的利器。
数据的预处理(数据清洗):
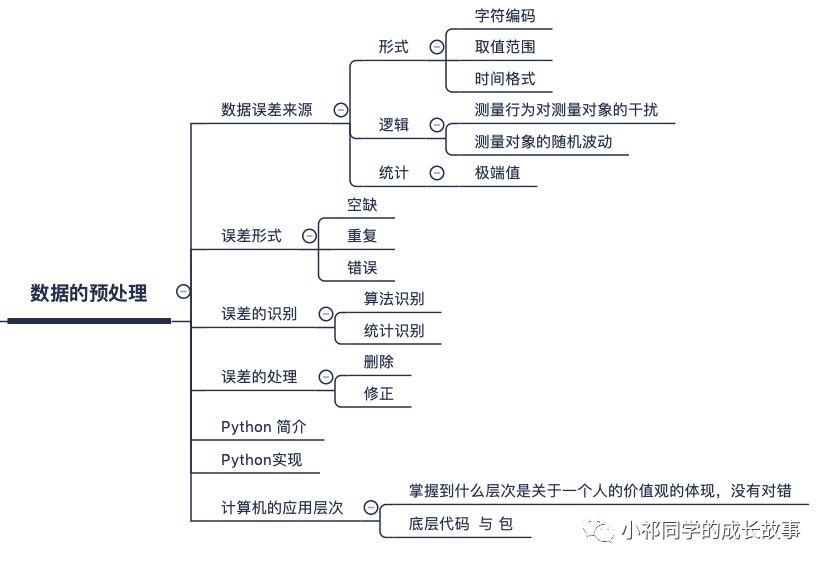
数据清洗(Data cleaning)– 对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
主要有三种类型:
(1)残缺数据
这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
(2)错误数据
这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如:数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。
这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
(3)重复数据
对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。 数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。
对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。
数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
数据清洗方法
一般来说,数据清理是将数据库精简以除去重复记录,并使剩余部分转换成标准可接收格式的过程。数据清理标准模型是将数据输入到数据清理处理器,通过一系列步骤“ 清理”数据,然后以期望的格式输出清理过的数据(如上图所示)。
数据清理从数据的准确性、完整性、一致性、惟一性、适时性、有效性几个方面来处理数据的丢失值、越界值、不一致代码、重复数据等问题。
数据清理一般针对具体应用,因而难以归纳统一的方法和步骤,但是根据数据不同可以给出相应的数据清理方法。
- 解决不完整数据( 即值缺失)的方法 大多数情况下,缺失的值必须手工填入( 即手工清理)。当然,某些缺失值可以从本数据源或其它数据源推导出来,这就可以用平均值、最大值、最小值或更为复杂的概率估计代替缺失的值,从而达到清理的目的。
- 错误值的检测及解决方法 用统计分析的方法识别可能的错误值或异常值,如偏差分析、识别不遵守分布或回归方程的值,也可以用简单规则库( 常识性规则、业务特定规则等)检查数据值,或使用不同属性间的约束、外部的数据来检测和清理数据。
- 重复记录的检测及消除方法 数据库中属性值相同的记录被认为是重复记录,通过判断记录间的属性值是否相等来检测记录是否相等,相等的记录合并为一条记录(即合并/清除)。合并/清除是消重的基本方法。
- 不一致性( 数据源内部及数据源之间)的检测及解决方法 从多数据源集成的数据可能有语义冲突,可定义完整性约束用于检测不一致性,也可通过分析数据发现联系,从而使得数据保持一致。
目前开发的数据清理工具大致可分为三类。
- 数据迁移工具允许指定简单的转换规则,如:将字符串gender替换成sex。sex公司的PrismWarehouse是一个流行的工具,就属于这类。
- 数据清洗工具使用领域特有的知识( 如:邮政地址)对数据作清洗。它们通常采用语法分析和模糊匹配技术完成对多数据源数据的清理。某些工具可以指明源的“ 相对清洁程度”,工具Integrity和Trillum属于这一类。
- 数据审计工具可以通过扫描数据发现规律和联系。因此,这类工具可以看作是数据挖掘工具的变形。
数据清洗工具:Python简介
Python是一种计算机程序设计语言,是一种动态的、面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
设计者开发时总的指导思想是,对于一个特定的问题,只要有一种最好的方法来解决就好了。这在由Tim Peters写的Python格言(称为The Zen of Python)里面表述为:There should be one– and preferably only one –obvious way to do it. 这正好和Perl语言(另一种功能类似的高级动态语言)的中心思想TMTOWTDI(There’s More Than One Way To Do It)完全相反。
Python的数据清洗实现示:
Python学习的一点心理体会
Python的学习又是一个大的模块,本质我们其实只是在学习如何使用Python的包而已,新人最容易有畏惧心理:我从来没学过任何语言,会不会很难?
其实,我们只是把以前用在记忆软件操作上的时间用在了记忆代码上,并没有什么非常难的问题要解决,我们前期只需要明白输入/输出是什么就可以,至于中间的原理可以后期去学,甚至可以跳过。
我简单提两点注意事项:
- 输入法配置:搜狗输入法的英文状态,记得设置标点为英文.
- 找有源码的教程:一边看,一边打。有源码很关键,因为有一个完全正确的对照,比较容易发现自己错误的地方。否则一处代码错误,可能是环境错误,可能是语法错误,可能是标点错误,可能是…..
数据的预分析:
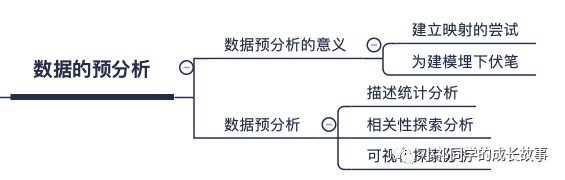
数据的描述统计分析:
描述性统计,是指运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动。描述性统计分析要对调查总体所有变量的有关数据进行统计性描述,主要包括数据的频数分析、集中趋势分析、离散程度分析、分布以及一些基本的统计图形。
- 数据的频数分析:在数据的预处理部分,利用频数分析和交叉频数分析可以检验异常值。
- 数据的集中趋势分析:用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。
- 数据的离散程度分析:主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。
- 数据的分布:在统计分析中,通常要假设样本所属总体的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本数据是否符合正态分布。
- 绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。
在SPSS软件里,可以很容易地绘制各个变量的统计图形,包括条形图、饼图和折线图等。
数据的相关性探索分析
数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的的原始素材。数据可以是连续的值,比如声音、图像,称为模拟数据。也可以是离散的,如:符号、文字,称为数字数据。
数据相关性是指数据之间存在某种关系,如正相关,负相关。 数据相关性是指数据之间存在某种关系。大数据时代,数据相关分析因其具有可以快捷、高效地发现事物间内在关联的优势而受到广泛关注,并有效地应用于推荐系统、商业分析、公共管理、医疗诊断等领域。
数据相关性可以时序分析、空间分析等方法进行分析。数据相关性分析也面对着高维数据、多变量数据、大规模数据、增长性数据及其可计算方面等挑战。
对于不同测量尺度的变数,有不同的相关系数可用:
- Pearson相关系数(Pearson’s r):衡量两个等距尺度或等比尺度变数之相关性。是最常见的,也是学习统计学时第一个接触的相关系数。
- 净相关(partial correlation):在模型中有多个自变数(或解释变数)时,去除掉其他自变数的影响,只衡量特定一个自变数与因变数之间的相关性。自变数和因变数皆为连续变数。
- 相关比(correlation ratio):衡量两个连续变数之相关性。
- Gamma相关系数:衡量两个次序尺度变数之相关性。
- Spearman等级相关系数:衡量两个次序尺度变数之相关性。
- Kendall等级相关系数(Kendall tau rank correlation coefficient):衡量两个人为次序尺度变数(原始资料为等距尺度)之相关性。
- Kendall和谐系数:衡量两个次序尺度变数之相关性。
- Phi相关系数(Phi coefficient):衡量两个真正名目尺度的二分变数之相关性。
- 列联相关系数(contingency coefficient):衡量两个真正名目尺度变数之相关性。
- 四分相关(tetrachoric correlation):衡量两个人为名目尺度(原始资料为等距尺度)的二分变数之相关性。
- Kappa一致性系数(K coefficient of agreement):衡量两个名目尺度变数之相关性。
- 点二系列相关系数(point-biserial correlation):X变数是真正名目尺度二分变数。Y变数是连续变数。
- 二系列相关系数(biserial correlation):X变数是人为名目尺度二分变数。Y变数是连续变数。
可视化探索分析
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。但是,这并不就意味着数据可视化就一定因为要实现其功能用途而令人感到枯燥乏味,或者是为了看上去绚丽多彩而显得极端复杂。
为了有效地传达思想概念,美学形式与功能需要齐头并进,通过直观地传达关键的方面与特征,从而实现对于相当稀疏而又复杂的数据集的深入洞察。然而,设计人员往往并不能很好地把握设计与功能之间的平衡,从而创造出华而不实的数据可视化形式,无法达到其主要目的,也就是传达与沟通信息。
推荐学习网站:博客园/知乎/网易云课堂/人人都是产品经理社区/GitHub
最后讲个小故事:
七十六岁这一年,爱因斯坦因为腹主动脉瘤破裂引起内出血,被送到医院。这不是什么疑难杂症,医生建议马上手术,但是爱因斯坦拒绝了。
爱因斯坦说:“当我想要离去的时候请让我离去,一味地延长生命是毫无意义的。我已经完成了我该做的,现在是该离去的时候了,我要优雅地离去。”
希望我们离开这个世界的时候也可以这样说一句:我要优雅的离去
作者:小祁爱数据,公众号:小祁同学的成长故事
本文由 @小祁爱数据 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









差点以为看了一遍哲学文,这怕不是被数据分析耽误了的修仙哲学家吧hhhhh