
 起点课堂会员权益
起点课堂会员权益数据ETL:反作弊的应用与基础模型
文章对数据ETL中的反作弊应用进行了简单的梳理分析,希望通过此文能够加深你对数据ETL的认识。

一、反作弊作用于哪个阶段?
在做反作弊之前,我们要明确整个数据从底层到数据中台过程中流向是什么样的。这里,我梳理了一个模型,它可以反映这一过程。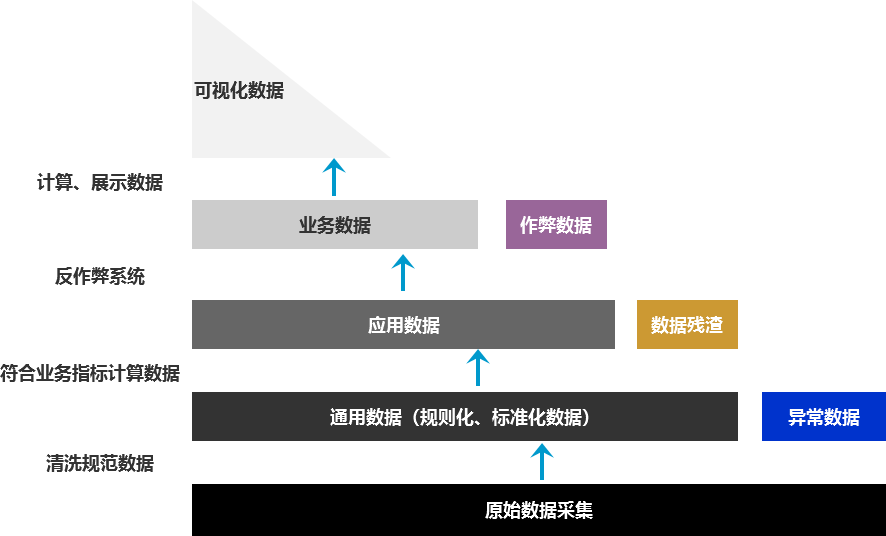
数据从原始采集经过“清洗规范”,会形成“通用数据”,这里会过滤掉异常数据供上层使用。
通用数据会根据业务场景,聚合成符合业务指标计算的数据,即“应用数据”,比如说是“主题场景”的数据。“主题场景”的数据可以是基于大背景的场景(横向),如:推荐业务场景、搜索业务场景。也可以是垂直到业务线的场景(纵向),如:某项购物时的推荐场景、短视频搜索的业务场景。这一过程会产生“数据残渣”,这部分数据是暂时没有应用场景的数据。
比如,在推荐商品时,你只取了用户的年龄、性别等作为特征,剩下的用户姓名这个特征数据在这个场景应用不到,它就成了暂时的“数据残渣”。不过,你可能在信贷业务场景中使用到这个特征数据(用户姓名),那种应用场景下它就不是“数据残渣”。
应用数据只是一个基础可用的数据集市,还需要经过反作弊系统来过滤掉具体应用场景下的作弊用户或者设备,形成“业务数据”。
最终,跟进业务需求等制定数据指标、维度等计算逻辑,并在数据中台形成可视化数据。
综上,我们可以发现,反作弊是在“应用数据”与“业务数据”之间work的。
二、反作弊基础模型
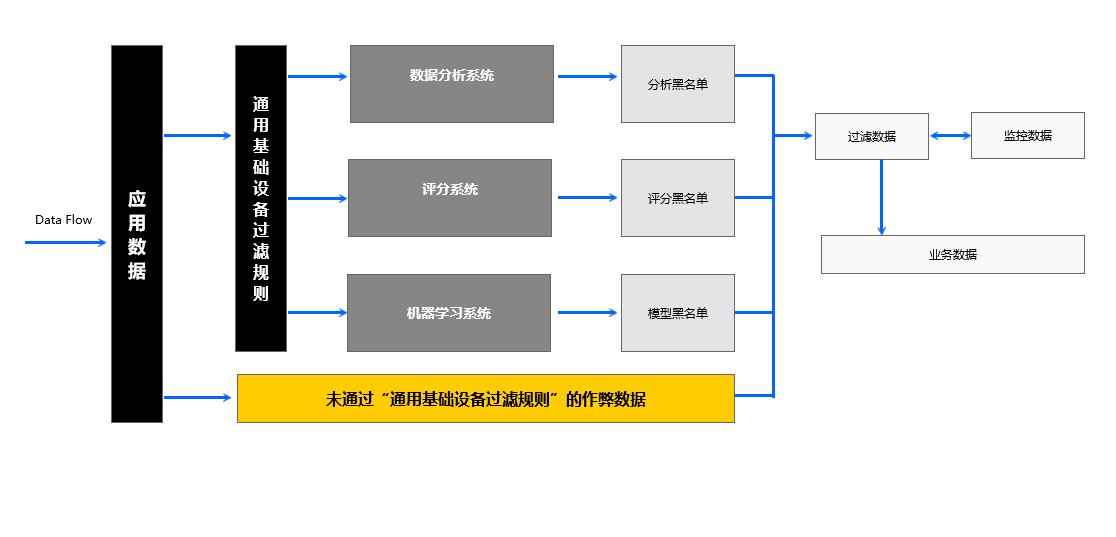
1. 通用基础设备过滤规则
这里面可以是人为设定的一些规则(比如:设备中安装有淘宝APP版本号大于线上最新版本的用户都是作弊用户),也可以是基于经验总结的设备属性。举个例子:

2. 数据分析系统
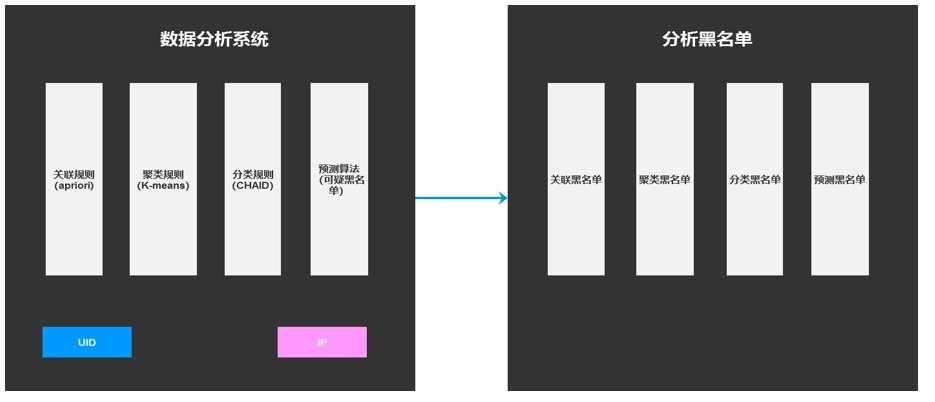
这里面主要是根据业务场景,分析业务属性与用户属性在结合的过程中产生的作弊用户。当然,可以通过业务规则或者算法来找出这部分用户。举例,在投放广告时,可以根据用户的uid、ip等找出这些属性与某些广告是否存在强关联关系,试图找出用户有恶意刷广告的行为。下图给大家介绍几个算法以及其应用场景。
3. 评分系统
评分系统也是基于业务场景来制定的规则或算法,从而产生对应的黑名单。比如,在短视频领域中,可以根据用户行为画像和视频画像来给视频或者用户打分。其主要流程可以参考下图:
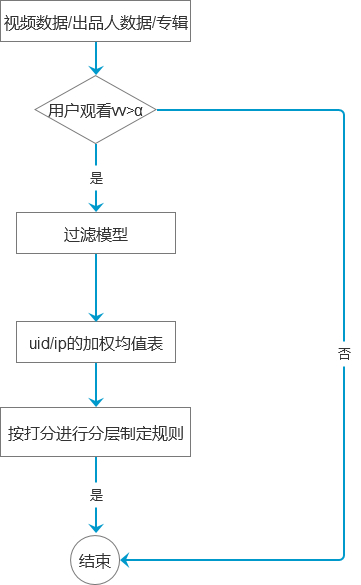
这里面关键是如何建立“过滤模型”,由于保密问题,这块需要大家根据业务场景自行建模。
4. 机器学习系统
这部分没有什么太多可以分享的,因为市面上机器学习的算法有很多,也很成熟,需要根据业务场景来选模、建模,甚至优化模型等等。
作者:软院猛哥 人人都是产品经理网“萌新一枚”
本文由 @软院猛哥 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议









能加个微信吗,我想跟您交流一下