
 起点课堂会员权益
起点课堂会员权益模型在风控策略中用到什么细节?
编辑导语:风控一般包含很多类型的规则,每个规则都是结合产品、业务基于经验和数据分析产生出来的,模型在风控中也有很大的作用;本文作者分析了模型在风控策略里有什么使用细节,我们一起来看一下。

模型:通过历史样本数据,运用数学算法,预测未来;我们通用的信用模型a卡就是根据客户的申请数据字段,然后在权重上通过算法计算出来的系数的组合,得到相应的预测概率(0-1之间),这就是最初的模型——它代表的是预测客户发生逾期的概率,模型评分卡只是方便管理而转化来的。
策略:即为了目标的实现,通过一系列的规则组合,而成为策略。
所以风控会出现有很多的名词:因子、规则、规则集、策略、策略集、事件等等。
风控最基本的因素是因子,因子构成规则,多个功能相似的属性规则组成规则集,多个规则集再成为策略;例如反欺诈策略,准入策略、额度策略、模型策略,这些组合成策略集,而整个策略集构成了风控的一个贷前审核事件。
大概介绍了风控相关的一些概念,那模型在风控属于什么位置呢?
其实可以理解模型就是一个因子,他可以单作为一条规则,成为只有一个规则的规则集,一个策略集,一个事件;有伙伴们问规则、模型、策略,都是具体怎么使用的,怎么组合的,规则和模型的区别等等,熟悉上面的逻辑就大概清晰了。
另一个模型之所以在风控中的有着重要地位,是由于模型通过多个规则因子(也就是蕴含了更多的规则)组合而来,它代表一系列规则因子的风险预测能力;所以它比任何一条规则都具有很好的区分度,所以模型这个单一的因子,生成单一的规则,比起其他简单规则在风控中的地位高了很多。
话说回来,模型概率或分数在风控里回归到一个因子,如何具体应用呢?
一、选择cutoff,即决策点
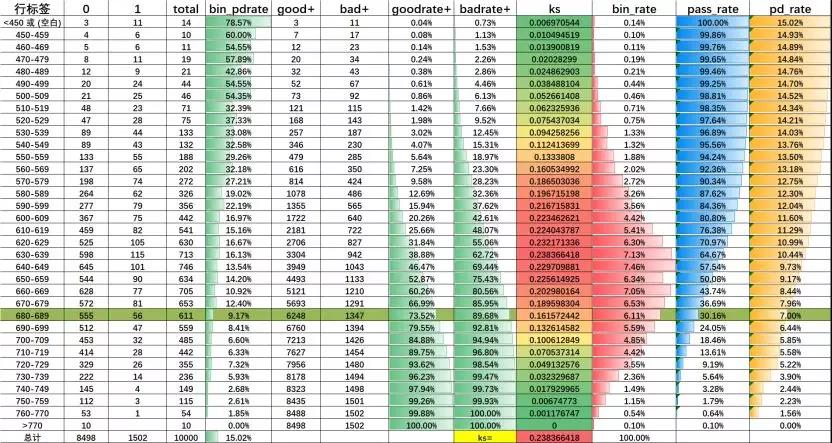
(模型决策表)
这个图是根据模型衍生出的风控策略决策表,当我们的模型做出来了,我们是怎么选择cutoff呢?
假如这个模型是做了拒绝演绎的模型,代表全部样本的分布评分;我们先看bin_pdrate 从逾期78.57%单调下降到1.85%,模型的单调性很完美,ks为23,bin_rate是箱占比,整体上还是很正态分布的。
重要的我们看后两列,这两列是通过前几列计算的在每个阈值点下的通过率和对应的坏账率,随着通过率的降低,坏账也随着降低。
风控往往有几个KPI考核指标,如坏账率;如果KPI不能大于7,我们选择了大于680分,30.16%的通过率,这是一个简单的选择。
有的公司会复杂的计算每一行的盈利情况,然后根据盈利来决定cutoff选择哪一个。
方法多种,有的可能30%的通过率达不到KPI,会选择630-680之间的一部分客户进行人工审核、信审,或者再利用其它的数据模型进行捞回,下面讲下捞回的策略是如何使用模型的。
二、模型捞回之提高通过率,精细化风险评估
捞回就是被模型拒绝的一些相对不差的客户用其它有区分度的模型进行再次评估,达到提高通过率的效果。
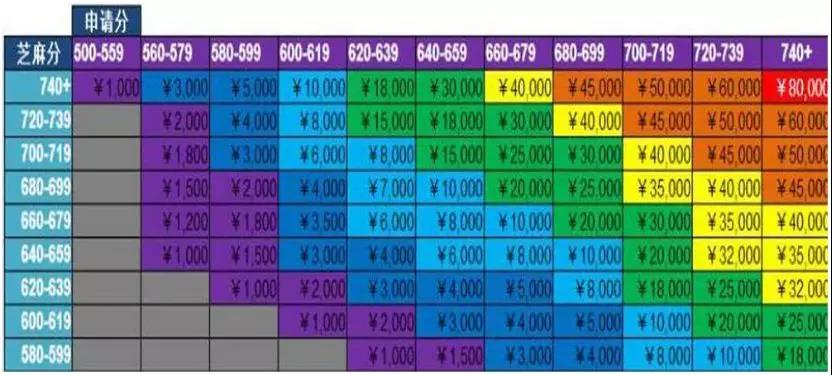
(模型矩阵表)
拿我们常用的模型矩阵来说,这个与分群建模的思路是一样的,上图(图中数据非真实模拟)中是通过矩阵坏账的比例高低然后给与不同的额度。
在申请分660-679之中,我们通过芝麻分可以更好的再区分这个区间的人群风险,做到精细化管理,在申请分660-679中我可以选择芝麻分在大于680,额度为大于10000的的客户进行放款;因为这部分客户的模型风险跟申请分大于680的同颜色的相同,这样就可以根据模型矩阵来提高通过率。
三、多模型补漏之更合理地选择客户

(模型补漏策略)
在实际场景中,我们还会遇到另一种情况,就是我们模型的数据不是完全覆盖的,有一定的缺失,一定的查得率,这时候往往不是一个模型可以解决问题的;因为你不能因为没有数据而拒绝,这时候往往需要过多个模型进行互相补漏。
也就是说,如果有5个备用模型,在很大概率是可以决策任何一个用户的借贷情况,模型的数据源越多,就可以覆盖越多的客群,更大化的对客户进行合理的风险评估。
例如第一个模型A没有数据,则运行模型B,按顺序依次调取;一般模型运用策略是最好的,覆盖最高的放在前面。
四、多模型组合使用之整体风险稳定
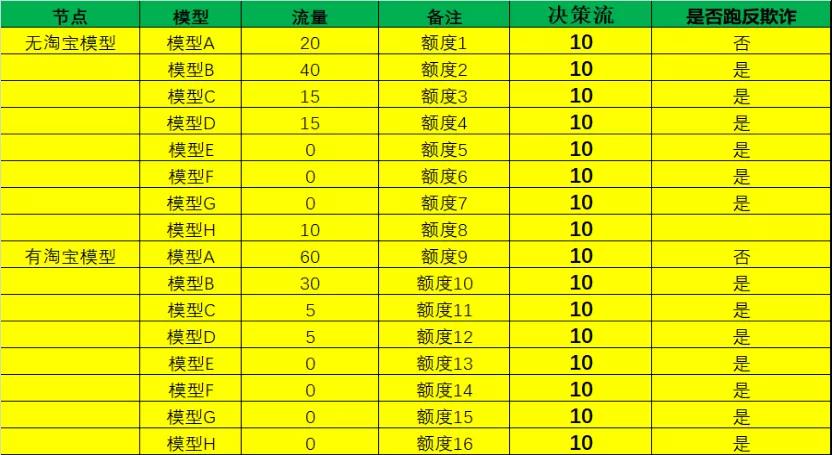
(模型组合表)图表模型名称敏感用字母替换
这个风控模型不仅可以作为模型A-B Test使用,来测试新模型的效果(此表同时跑了8模型,每个模型分配不同的流量),然后对测试模型进行效果评估。
另外,通过长时间的工作经验积累,还可以将几个有区分度的模型分流组合使用,整体效果会更好;原因主要是数据的稳定性、数据的衰减性、市场等,往往多模型组合较单个模型使用,具有更稳定的数据表现和更好的理想效果。
并不是我们认为模型A是最好的,然后就全部流量给A,因为都给A会存在很大的不确定性;例如数据源停供、数据源出现失真、数据源预测质量明显下降;这些现象,在实际工作中是经常遇到的,事后发现就有些晚了。
反过来,通过几个较好模型的组合,会发现有更稳定、更理想的数据表现,图中无淘宝模型用了5个模型进行组合。
五、模型日志的的重要性
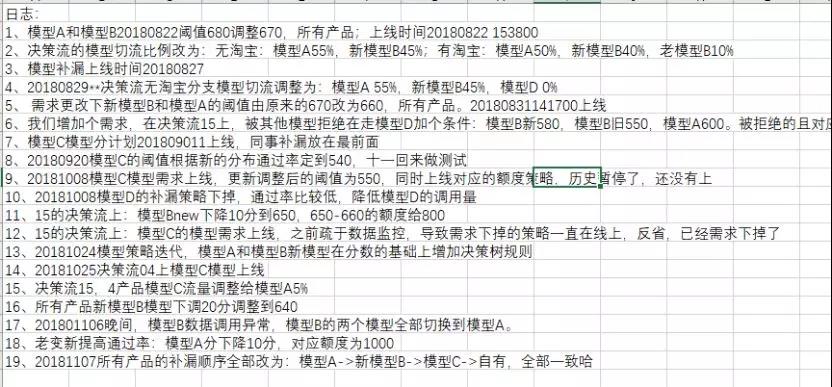
(模型日志)
上文是简要的一个模型使用变动的所有记录日志,这个一定要重视起来;我们工作中有很多需要回溯的时间,或者风控表现滞后,往往再排查原因不能准确的定位,就比较浪费时间了,最后还可能找不到原因。
假如今天客群表现很差,我提前知道某天前改动了模型的阈值,正好今天有表现,这时候往往会很快的定位。
数据风险的变动无外乎两种,外部的客群和内部的风控,风控日志的每个变动都会带来风险的变动。
所以找任何原因从日志上下手是最方便的,他就像我们写代码的log日志,很好很方便,也很需要,直接告诉你病点在哪。
以上是模型具体使用的一些细节,在如何选择决策点、模型捞回、模型补漏、模型组合、模型日志上进行具体的风控实施。
希望可以给读者在思路的一些帮助与完善,谢谢!
本文由 @FAL金科应用研院 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


