
 起点课堂会员权益
起点课堂会员权益数据分析的坑,都在统计学里埋过
为什么要了解统计学?对于普罗大众来说,统计学应该会成为每人必备的常识,才能避免被越来越精致的数字陷阱欺骗。起码当你看到各种百分比和收益率,能多出一份警觉,多思考些他们的来源和计算途径。
对于互联网工作者来说,统计知识投射在互联网上,就是数据相关的方法论。举例来讲,现在盛行的 A/B Test 本质上就是控制变量法实验中的一种。不同的是,互联网获取数据更简单,进行对比实验更方便。这将是一个统计学/数据分析的大事件。想象一下 Facebook 内部几千个 A/B Gate,简直称得上一场史无前例的大规模人口社会实验。
这也是为什么近些年来 Growth Hacker ,Data Scientist 越来越火的原因。数据量的极易获取,计算存储成本的降低和分析效率的提升,使得统计分析的成本更低,规模更大,从而输出价值更高。
统计和分析的差别
个人理解上,统计分析应该是整个数据流程的不同部分。统计在于工具或手段,分析更偏重理念。比如回归分析为什么叫分析不叫统计,就是因为其中已经包含了部分归因的思想。再举个栗子,决定对一批数据取平均数还是中位数,这是统计,该怎么利用,是分析。
如《赤裸裸的统计学》中指出来的一样,统计分析是:
- 总结大量的数据
- 做出正确的决定
- 回答重要的社会问题
- 认识并改善我们日常的行为模型
坑一:统计指标各有利弊通过选择合适的统计指标,来精准表达数据集的内容。同时也需要防止有人利用这些指标的优缺点来误导舆论,影响你的决策。
平均数,中位数,四分位数: 平均数对极值敏感而中位数不会。所以北京的同学们经常会感觉自己的薪资收入拖慢了集体的后腿….但如果看中位数和四分位数,可能情况就会大不相同。
绝对值,比率值:注册数是绝对值,注册率是比率值。比率值出现异常时,需要首先关注分子和分母的情况。比如说,某天发现网站 UV 周同比上涨了 500%,有可能是上周基数太低导致的。如果一上来就从维度进行细分,很容易跑偏。
百分比,百分差,百分率:百分比是个常见的数据表达形式,其中猫腻也比较多。此类数字往往需要注意分母和分子的差别。以下是两个常见例子:1,一件货品先降价15%再涨15%价格是否一样?2,对于百分差和百分率,税率从3%涨到5%,可以说上涨了2个百分点,也可以说上涨了67%,给人感觉效果大不一样。
指数型数据:即通过各项数据计算得出来的指数,优点在于将所有信息浓缩成一个数字,简单易懂,但容易忽略其中成分数据的影响。美团外卖当初有个很复杂的考核城市用户体验的指标,就是个很好的例子。通过多项数据的整合,我们很好地把用户体验这种比较虚的东西落到了实处。不过需要注意的是,对它的过分依赖容易带来误导性的结论。
坑二:统计背景不够明确首先要了解:精确和准确是有本质差别的。如在你内急的时候我告诉你公厕在你右边直走134.12m处,这很精确。不过实际上,厕所在左边。准确的要义是要能让指标贴近所描述事物。
这需要在衡量事物的指标上达成统一。如在之前 20011 年时有争论:美国制造业是否正在衰退?从总体产出上看,从 2000 年来看一直在增长,而制造业的就业数却在下降。因此需要统一指标来表述制造业的繁荣情况。
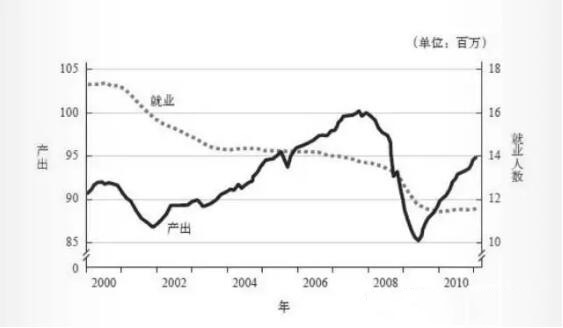
就像电商一样,需要明确自己当前关注的唯一核心指标,如订单数,交易额等。不同的关注会导致公司战略上的不同。
第三确定指标后,需要确定描述主体。同样是房价,政府说我们今年有60%的城市,房均价比去年低!你们买房有希望了!但实际上,40%的房子都涨价了,且都集中在核心城市。P 民们照样买不起房子..
注意时代背景:《赤裸裸的统计学》中举了个很有趣的例子:如何评价历史上票房最高的电影。好莱坞在截止2011年时,给出的票房前 5 名是:阿凡达,泰坦尼克号,蝙蝠侠前传二,星球大战四和怪物史莱克二。但历史阶段上,通胀情况是不一样的。把通胀因素考虑进来后,这个榜单应该更新为:乱世佳人,星球大战四,音乐之声,外星人 ET 和十诫。
利用统计学手段可以影响人们的解读:截取有利时间段,混淆单位等。
坑三:统计指标也有偏见在选择样本和进行统计分析时,会存在各种各样的偏见,导致结果失之毫厘,谬以千里。
选择性偏见:选择了错误的样本,得到的分析结论自然是错的。如在第三季硅谷里,Richard 对自己的开发者朋友们发布了 Beta 版,好评如潮。但因为其上手难度太高,普通用户根本用不了,最后注册用户虽有百万之巨,但活跃用户却寥寥无几。同样的,在对电商用户习惯做分析时,一二线城市和三四线城市的消费水平和习惯肯定有所差异,选择单独一种都会有失偏颇。
发表性偏见:学术研究或新闻更乐于发表肯定性结论而非否定性。一个打游戏不会引发癌症的研究,肯定不如证明当 PM 会导致寿命更短的实验更受关注。
记忆性偏见:人们会因为结果修改自己的记忆,如很多成功人士会在失败后将原因归咎于某个因素,并将其放大成关键原因。但事实上可能并非如此。
幸存者偏见:通过挑选样本来操控数据。简而言之,对于那些下单成功的用户数来讲,他们的注册成功率是 100%。在日常分析中,需要时刻警惕这种偏见的变异版本。
坑四:慎重选择统计实验在研究事物的相关性时,控制变量实验是个比较科学的做法。在现实生活中,一些变量很难甚至无法控制,此时便需通过各种统计实验来逼近这种效果。
随机控制实验:随机抽取样本,随机分配实验组和对照组。这便是最理想的 A/B Test,核心在分桶策略。
自然实验:利用已有数据营造近似的随机实验,如在 O2O 城市运营中,很难长期控制城市去做实验要求的推广活动来对比哪种更有效。合适的方法是从已有的数据中,挑选情况类似活动不同的城市来进行对比分析。
差分类差分实验:利用时间和空间上的对比来控制变量,如美国曾经在研究受教育年龄对寿命的影响实验中,分析了田纳西州在教育改革时间前后数据的变化,以及和相邻州对比情况。
非连续分析实验:选择条件类似但结果不同的样本,进行对比分析。如选择一批犯罪情况类似的青少年,一组需要送去监狱而另一组刚好免除牢狱之灾,通过对这两组人的分析来研究坐牢对青少年后续犯罪率的影响。
《赤裸裸的统计学》中,还有部分关于概率,期望值和回归分析的部分,限于篇幅所限,在这里就不多阐述了。感兴趣的同学推荐详细阅读此书。更老的一本还有《统计数字会撒谎》。希望这篇分享能给大家带来一点收获。
作者:陈新涛 美团外卖首任数据产品经理,如今在大数据公司 GrowingIO 任职。
本文来源于人人都是产品经理合作媒体@36大数据,作者@陈新涛









Good