
 起点课堂会员权益
起点课堂会员权益建模困难,缺乏行为数据?了解一下联系人倒排表特征吧
编辑导语:建模,是为了理解事物而对事物做出的一种抽象,是对事物的一种无歧义的书面描述。建模是研究系统的重要手段和前提,凡是用模型描述系统的因果关系或相互关系的过程都属于建模。如果在建模的过程中发现缺乏行为数据,你该怎么办?针对这个问题,本文作者为我们分析了联系人倒排表。

一、联系人倒排表特征简介
1. 使用背景
在构建用户风控评分卡时,工程师们经常为特征数量和数据维度所困。特别是实时评分卡,因为实时申请用户往往缺乏行为数据而使得模型构建困难。
在大集群数据计算时,使用图数据效率又不是很高。因此,倒排表成了一个可以高效率挖掘用户关系特征的重要方向,倒排表特征是新申请用户关联到老平台用户的特征。
2. 倒排表特征简介
倒排表区别于正向表,和传统的倒排索引区别于正向索引有类似之处。
例如:关系人电话倒排表也是通过在正向关系表的用户-联系人电话维度表(图一),导出逆向的倒排的联系人电话-用户的维度(图二)。但倒排表和倒排索引不同的地方在于,电话与电话之间和用户与用户之间不存在先后关系。
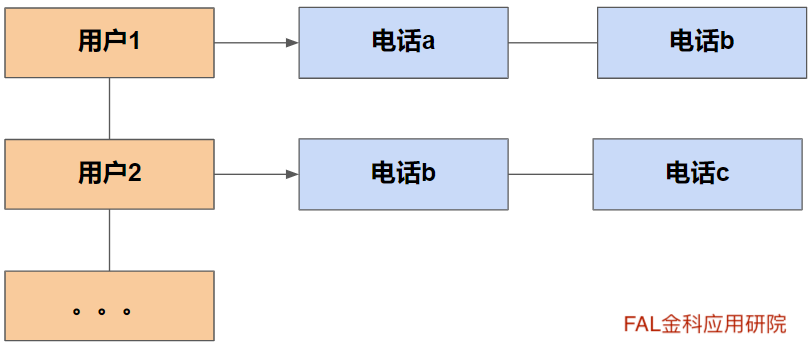
图一:用户-联系人电话的正向表
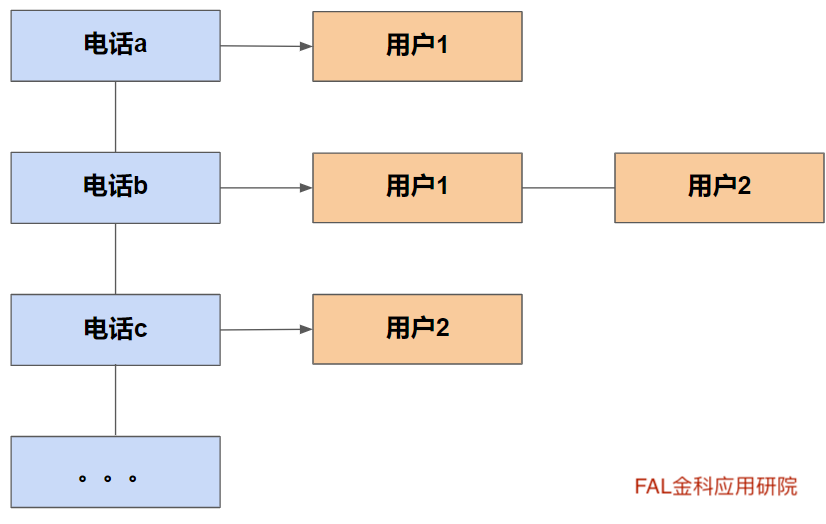
图二:联系人电话-用户的倒排表
倒排表特征区别于常规特征,倒排表特征的主键往往不是用户身。
例如:常规特征如表1所示,主键是用户本身,常规特征也是属于用户本身的。但是,倒排表特征的主键却不是用户本身。从根本上说,这个倒排表特征是属于对应的主键的,联系人倒排表特征的主键则是联系人电话,如表2所示。

表一:常规特征表

表二:联系人倒排特征表
倒排表特征的使用是通过用户的某项用户数据,关联成用户本身的特征。
例如:本文要介绍的联系人倒排表特征是,先拿到这个用户拥有的电话号,然后再去联系人倒排表中查找这个电话号的倒排表统计特征。除了联系人电话这个主键外,还可以使用地址或设备信息作为主键。在本文中主要介绍以联系人电话为主键的倒排表特征。
3. 倒排表特征的结构
要制作倒排表特征总共需要准备与制作4张表。分别是:倒排关系表,用户特征表,倒排用户特征表和倒排特征最终表。
它们的关系如图三所示:
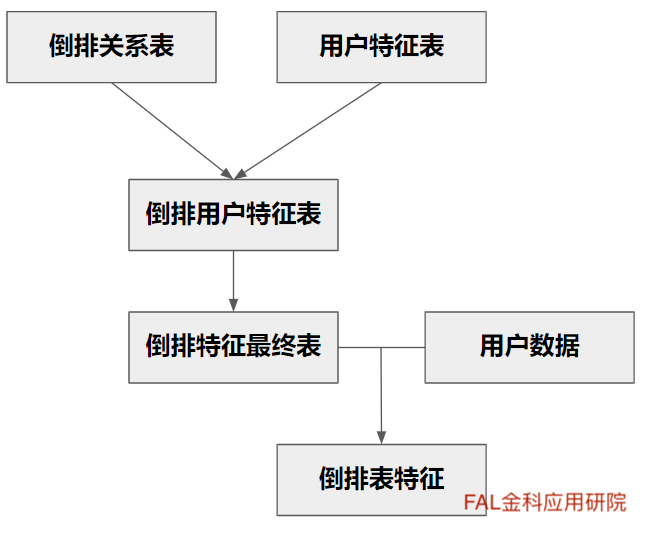
图三:倒排表特征制作结构
首先,倒排关系表和用户特征表合成成倒排用户特征表;然后,使用倒排用户特征表计算出倒排特征最终表;最后,用过倒排特征最终表关联用户数据得出倒排表特征。
我会在下文中分别介绍这4张表的作用和制作方法。
二、联系人倒排表特征的制作
1. 联系人倒排关系表
倒排关系表是由原始关系数据生成的一张关系表。
例如:联系人倒排关系表是一张联系人电话和现有用户的关系表,表中的联系人电话和用户关系是通过通讯录数据或者电商下单购买数据等提取出的;例如:在电商下单数据中,每一条数据都有收货人电话和下单用户的用户id。
如果,用户1给电话a和电话b下过单,记:
- 电话a与用户1有关系
- 电话b与用户1有关系
共两条数据。
如果,用户2给电话b和电话c下过单,则记下:
- 电话b与用户2有关系
- 电话c与用户2有关系
共两条数据。
因此,关系人倒排表会如表3中记录所示,共4条数据。表中,主键是电话,每行数据对应一个电话和下单用户的关系。

表三:联系人倒排关系表
2. 用户特征表
用户特征表是一张用户对应的常规特征表,和我们构建风控评分卡时使用的常规特征表一样。主键是用户本身,包含一些用户的重要常规特征,甚至可以包含该用户行为评分卡的分数,如表四所示。

表四:用户特征表
3. 联系人倒排用户特征表
倒排用户特征表是由倒排关系表和用户特征表,以用户为key,合成的表,如表五所示。联系人倒排用户特征表中的主键依然是联系人电话,每行数据对应了这个电话关联到的用户和该用户的特征。

表五:联系人倒排用户特征表
4. 联系人倒排特征最终表
倒排特征最终表是使用倒排用户特征表计算。在联系人倒排特征最终表中计算方法是通过group by主键,求电话关联到所有用户的特征的mean值,max值或者比例。
如表六所示,联系人倒排特征最终表的主键依然是联系人电话,每行数据代表了该电话关联到的用户的统计特征。

表六:联系人倒排特征最终表
下文会介绍在离线训练和线上预测时如何使用倒排特征最终表生成倒排表特征。
三、联系人倒排表特征的使用
1. 离线计算与训练的使用
在训练模型之前,需要先离线计算好倒排特征最终表。
在训练时,按用户数据关联倒排特征最终表中的主键,如图四所示。最后,在训练模型时把关联到的倒排表特征按照普通特征放入模型中即可。这里有很多坑点,请参考下文的总结与坑点。
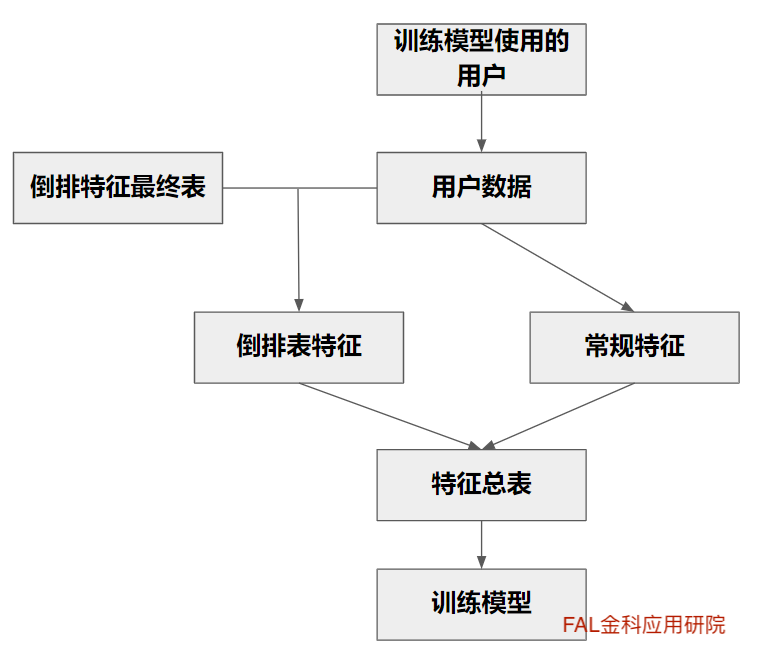
图四:线上倒排表特征使用流程
2. 线上实时使用
线上实时使用倒排表特征也需要提前生成好倒排特征最终表。
如图五所示,线上新用户申请时,用线上用户数据去查倒排特征最终表。从而生成该用户的倒排表特征,再放入线上评分卡模型中预测分数。
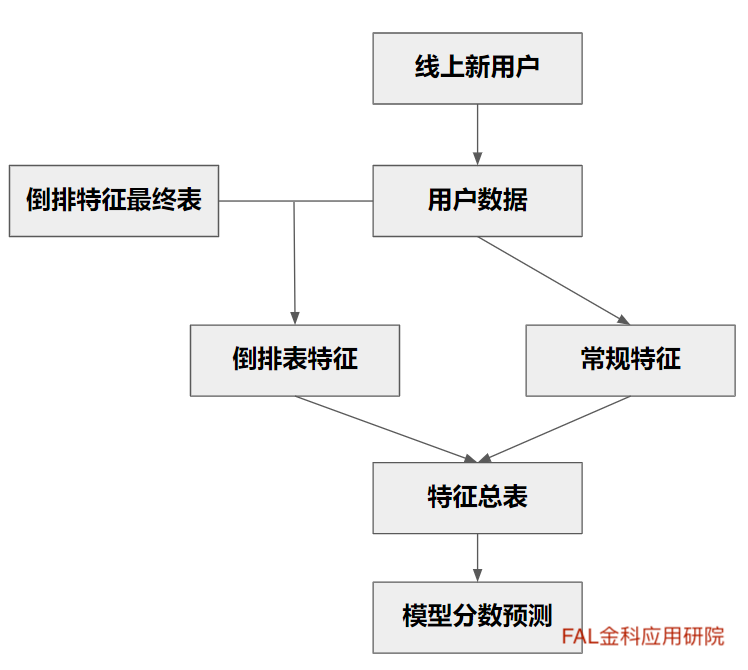
图五:线上倒排表特征使用流程
四、总结与坑点
1. 总结
本文中介绍了,为了解决在构建申请评分卡时申请用户因为缺乏行为数据而使得模型构建困难的问题,使用了倒排表特征。倒排表是一个可以挖掘用户关系的特征构建方向,通常在构建模型中占据着重要地位。
2. 坑点
构建倒排表特征时有非常多坑点,这里总结了几个供大家参考:
1)坑点1:线上和线下电话存输格式不一
在构建联系人倒排关系表时,原始数据来源于通讯录数据或者电商产品购买数据。
在这些数据里面的电话可能是没有加国家和地区号的,但线上传输数据是有可能是加了国家和地区号的电话,这里一定要注意先统一规划好电话号格式。
2)坑点2:使用未来数据
构建离线训练模型的倒排特征最终表时,要注意构建的倒排关系表和用户特征表这两张表都应该有观察截止时间,并且关系和数据都应该只使用在观察截止时间前的数据。
3)坑点3:训练数据中,放入自己关联自己的数据
使用倒排表特征的目的是让新用户在申请时多一点关联特征,所以,我们在训练的时候也要尽量模拟新用户申请的场景。
如果我们使用的是老用户去模拟新用户构建模型的情况,请一定记得在离线特征生成时去掉自己关联自己的数据,防止模型过拟合。
例如:电商下单数据中用户给自己下的单,不应该出现在离线训练的倒排关系表里面。
本文由 @FAL金科应用研院 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 unsplash,基于 CC0 协议









不错 内容👍