
 起点课堂会员权益
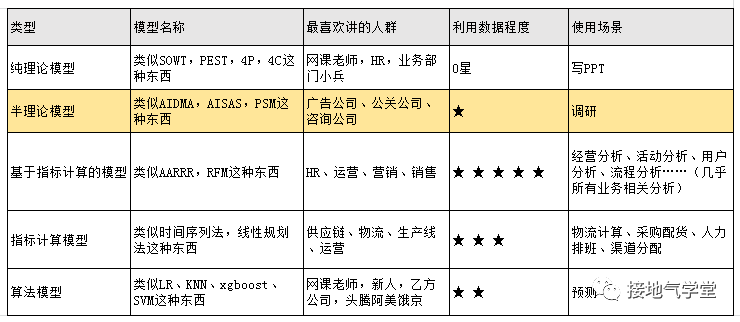
起点课堂会员权益数据分析师,要懂多少算法模型?
编辑导读:作为一名数据分析师,你是否也会感到迷惑,为什么需要这么多算法模型,工作中真的能用到吗?最重要的是,我到底应该懂多少算法模型?本文作者对此发表了自己的看法,与你分享。

随着数据分析岗位招聘越来越内卷,问“你用过/建过什么模型”的也越来越多。这个问题很容易给人“面试造航母,工作拧螺丝”的感觉。实际工作中,真的要搞那么多模型???
搞得很多同学在疑惑:
- 到底数据分析师要懂多少算法模型?
- 工作中真的要用到那么多模型?
- 我干的到底算不算模型?
今天系统讲解一下。
一、盘点各路人马口中的“模型”
这个问题的本质来自于不同人口中的“模型”含义不一样。广义上讲,只要是对现实问题的抽象,都可以叫“模型”。但一旦要结合数据、计算过程、使用场景,就会发现这些千奇百怪的模型完全不一样。因此了解清楚,我们得先对各路人马口中的“模型”全盘梳理一下。
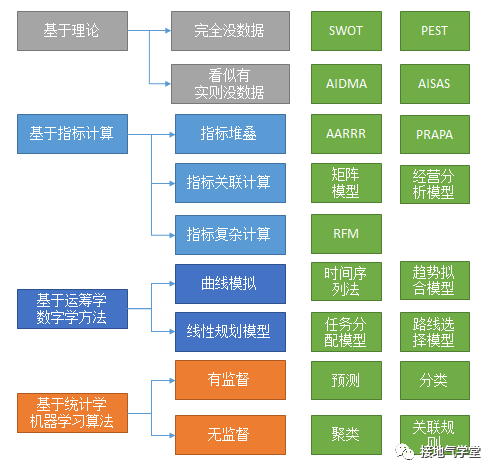
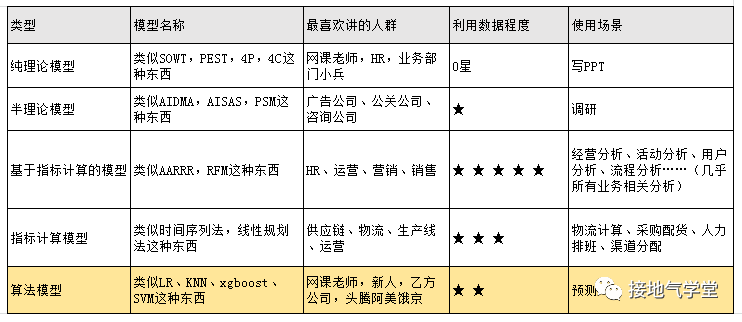
类型一:纯理论模型

这些模型往往来自《管理学》《营销学》课程,和数据的结合度几乎为0。就比如PEST,就问一款APP的DAU在8月份涨了10万,有多少来自国家出的文件?又有多少来自2017年新生人口1723万?又有多少来自华为——没有一个能算得清楚的。
所以这些东西严格来说不能算数据分析模型,它们只是一个思考方式。除非是政策敏感性特别强的行业+政策风向猛烈波动(比如互联网金融),才能直观的从PEST看到数据变化;或者处于垄断竞争行业(比如三大电信运营商)业务才会直接受到对手挑战。其他场景下,这些玩意就是美化PPT用的。
类型二:半理论模型
这些模型是经典的营销分析模型,但正因为经典,所以它们大部分基于调研数据,诸如用户态度,感觉,评价,是基于传统调研的手段获取数据。在当下,能获取用户数据方法很多,直接ABtest,比通过问卷问态度再反推更直观。因此这些模型适用范围已大大缩水。理论可以看,但是直接搬运就省省了。

有意思的是,为了体现自己的价值,调研公司、咨询公司、广告公司还是很喜欢讲这一类的模型,毕竟用户脑袋没有开接口,行为数据记录再多,还是不能直接推导出用户想法。因此在产品经理运营研发很迷惑的时候,还是会求助于市场调研。
类型三:基于指标计算模型
这些模型才是业务提及率最高,讲得最多的模型。这些模型,往往直接使用业务部门的KPI指标,以有逻辑的方式呈现,因此业务部门在讨论问题的时候可以直接往里边套,非常好用。同时,这些模型都是可以基于指标继续拆解的,因此业务讨论完了,可以直接按小组分配任务,并且监督任务完成情况。这两项优势,使得业务非常喜欢用这一类模型,时不时还自己创造两个。
但是,这一类模型有个致命缺点,就是:关键参数来自经验,未来预测全凭拍脑袋。你问业务为啥估计转化率是20%,得到的回答不是:“最近几个月都是20%”,就是“我觉得它会是20%”——建算法模型的时候还有各种检验值呢,这里就纯拍脑袋了。
类型四:指标计算模型
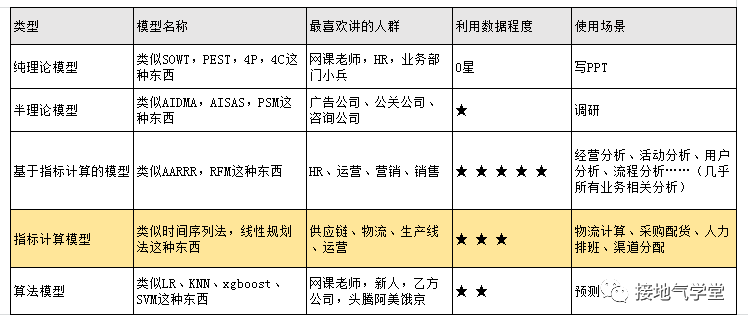
曲线拟合一般用来预测整体指标走势,比如整体销量、整体商品数量、用户流失数量等等。这种做法简单粗暴:不看原因,只看结果,拿结果数据的过往走势,拟合未来走势。
虽然看起来粗暴,但是却非常好用。因为需要的数据量少!只有一个结果数据即可(很多情况下,简单省事就是王道)。因此适用范围非常广。
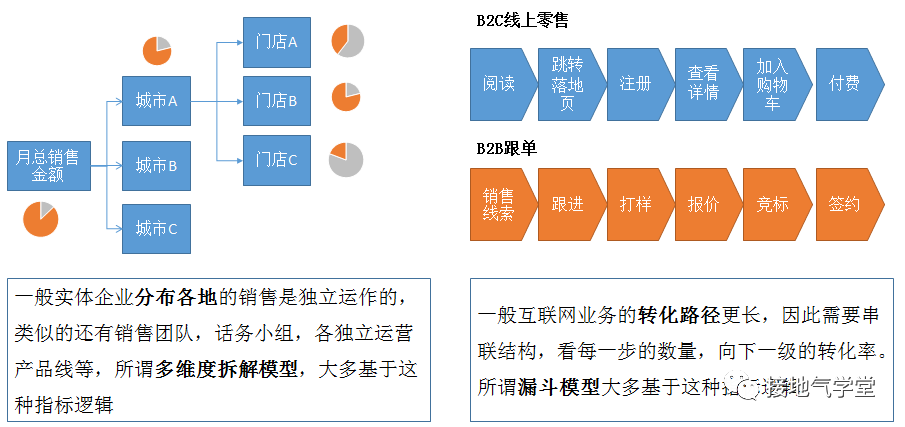
线性规划模型是经典的科学管理模型,往往用在已定目标,分配任务的场景(如下图)。

有意思的是,线性规划模型常常是用在供应链的,营销端理论上可用,但是用的少。其中最大的制约,来自基础数据的积累:供应链往往对生产力、运力、人力有比较多的评估和积累,因此有大量数据可用于建模。营销端一天100个花样,业务方又太执着于玩法创新,懒得打业务标签和积累数据,自然没有多少数据可参考。
类型五:算法模型
这里才是近几年大火的机器学习算法。但是,这些算法大部分不是用来解决企业经营问题的,而是工业应用,比如安防,辅助驾驶,语音识别,语音控制,内容推荐,商品推荐,反欺诈,风控等等。这些都是生产系统,非数据分析/BI系统。在架构上一般都是专门的算法组/风控模型组负责,不会和数据分析组重叠。
在企业经营方面,算法有一些经典应用场景,比响应率预测,消费能力预测等等,但始终不是数据分析工作重点。因为大部分企业经营场景,面对的问题是:没数据!采集数据,整理数据,分析数据才是数据分析组主要任务。且大部分算法解释性差,业务既无法参与,无法理解,因此能输出的成果非常有效,从而限制了算法在分析上使用。
至于为啥面试的时候喜欢问算法的越来越多,其实是数据分析岗位内卷得明显标志:只是单纯报这个岗位的人太多了,咱问点难的东西淘汰一批吧。没有独立算法组,指望招一个孤零零的数据分析师把模型搞出来,就是做梦。
二、模型到底需要懂多少
比如预测12月销量,那么可以做:
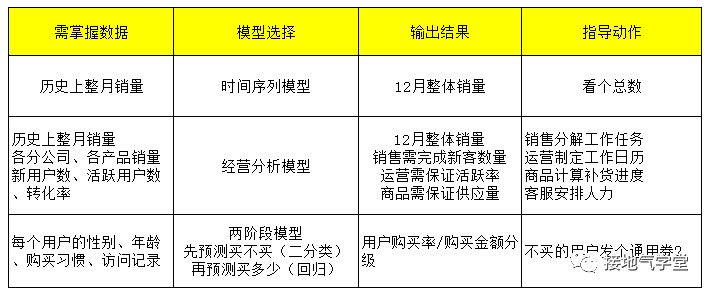
这样直观对比,就能看出来,为啥统计学/机器学习算法模型,在实际场景中运用很少。这些模型需要的数据多,需要的数据颗粒度细,建模过程复杂,输出的结果反而更简单,业务看了能干的事也少。
相比之下,套用经营分析的模型进行拆解,虽然主要参数都是拍脑袋,但也变相的给各个部门下了军令状:你必须做到这么多!这样更容易驱动业务部门行动。用时间序列法虽然算出来的也不能落地,但是它需要的数据少,只有一串数照样用。因此省事。
注意:上边的对比,并不能说明机器学习方法不适合经营分析,只是场景不合适而已。换个场景照样好用。比如用二分类模型预测用户购买。就有两种典型好用用法:
- 在响应率低的时候,压缩业务工作量,提高产出率。最典型的就是外呼,用户如果不接电话,任凭外呼员巧舌如簧也没用。并且外呼成功率特别低,自然成功率1.5%-2%,因此哪怕模型只提高一个点的接听率,也能让外呼员的效率提高一大截。
- 在响应率高的时候,识别自然响应群体,减少投入。最典型的就是营销成本控制。如果想压缩优惠券投放,最好的办法就是预测:是否购买,之后把购买概率高的群体的券砍掉。对于释放费用,非常好使。
所以在工作中,根据以下几点来看菜吃饭,才是能发挥作用,争取认可的好做法。
- 数据丰富程度
- 数据质量高低
- 结果使用场景
- 期望上线时间
毕竟企业工作,追求的是低成本高效率地解决问题,如果一味追求复杂尖端,还是回去学校读个博士认真做科研的好。
可问题是,如果工作中真的受各种制约,没法做复杂的算法模型,面试又被问道,咋办呢?有兴趣的话,关注接地气学堂公众号,我们下一篇分享,如何应对越来越内卷的数据招聘要求,敬请期待哦。
#专栏作家#
接地气的陈老师,微信公众号:接地气学堂,人人都是产品经理专栏作家。资深咨询顾问,在互联网,金融,快消,零售,耐用,美容等15个行业有丰富数据相关经验。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议。









陈老师,图片水印能不能换个地方,右下方的字都被遮住了。