
 起点课堂会员权益
起点课堂会员权益银行和大厂的一次数据交易
编辑导语:随着信息化和互联网的快速发展,数据交易已经成为社会热点。与信息技术紧密融合的金融行业,伴随着信息化程度的提高,与互联网大厂的和合作越来越频繁。那么当大厂和银行联合建模之后会发生什么呢?一起来看看吧!

之前写过一篇:银行和大厂的一次联合建模慢银行在联合建模之后,借由快大厂的数据和流量,短暂地解决了获客问题。
但好景不长,该模型效果衰减地非常厉害,通过率也掉了一个水平,当初建模未料到行业将如此下行,采用的样本过于优质。现在不得不面对更下沉的客群。
不管是那次联合建模过程中,还是之后,慢银行和快大厂涉事双方都对那次合作不置好词。他们唯一达成了的共识是,联合建模太麻烦了。但合作是上层战略,总是要维持和推进的。
于是,快大厂提议,可以输出我们内部的数据标签作为标准产品给你们,这些数据不仅风险区分效果好还很稳定。慢银行虽然明知其套路,但迫于形势恶劣,还是觉得可以一试。
毕竟,标准产品省去了联合建模的麻烦,同时也避免了建模样本过少导致过早失效的问题。于是,原班人马把上个项目成立的微信群,“快与慢联合建模群”,改成了,“快与慢数据产品合作群”。
只是联合建模时快大厂的负责人,已经离职了。据说是因为当时合作太费劲,受不了了,也据说是在快大厂已经待了两年多了,该走了。(不知道我为什么特意想黑一下)曾经发生的故事,或多或少,或变或没变,地再次发生了。
一、立项会议
有了之前的经验,这次两方都没怎么寒暄,就直奔主题了。慢银行因为对上次合作不满意,这次主动提了很多要求。你们那什么什么交易数据要加工这些字段,提供给我们。
此处可以代入,天猫淘宝京东拼多多等电商交易数据,也可以代入花呗借呗白条金条等支付借贷数据,等等。你们那会员等级数据要提供给我们。
此处可以代入支付宝会员等级、芝麻信用分,京东京享值、小白守约分,微信支付分等。另外,你们的账龄数据要给我们。还有,你们提供什么模型评分给我们?是你们的A卡、B卡还是什么模型的评分?你们怎么建的模型?内部怎么用的?……快大厂,没有话说。
项目是VP层级的,老板发了死命令,要服务好对方。慢银行指定了一个同学,当然还是那个慢A,快大厂也指定了个同学,也还是那个快B。此外,双方增加了策略同学的参与,分别是慢C、快D。慢A和快B仇人见面分外眼红,但工资让他们学会了安分和合作。
二、数据准备
关于标准产品,慢银行体现了其专业性,提出的数据维度非常丰富,把快大厂的数据资产挖的是干干净净,多一个不能多,少一个不能少。
那是因为慢C同学参考了芝麻信用变量的维度,依葫芦画瓢,再排除了快大厂相对比较缺失的信息,提出了这么一个变量清单。芝麻信用的65个变量列表如下,其中标红的是8个核心变量。
覆盖信用历史、行为偏好、履约能力、身份特质、人脉关系五个维度,正所谓“五大护法齐上阵,信用风险忙下场”。关于芝麻信用,我写过揭秘:芝麻信用是怎么做的。
明显可以看到,阿里系在人脉关系上是多么的弱势,该部分信息主要都在腾讯和运营商手上。
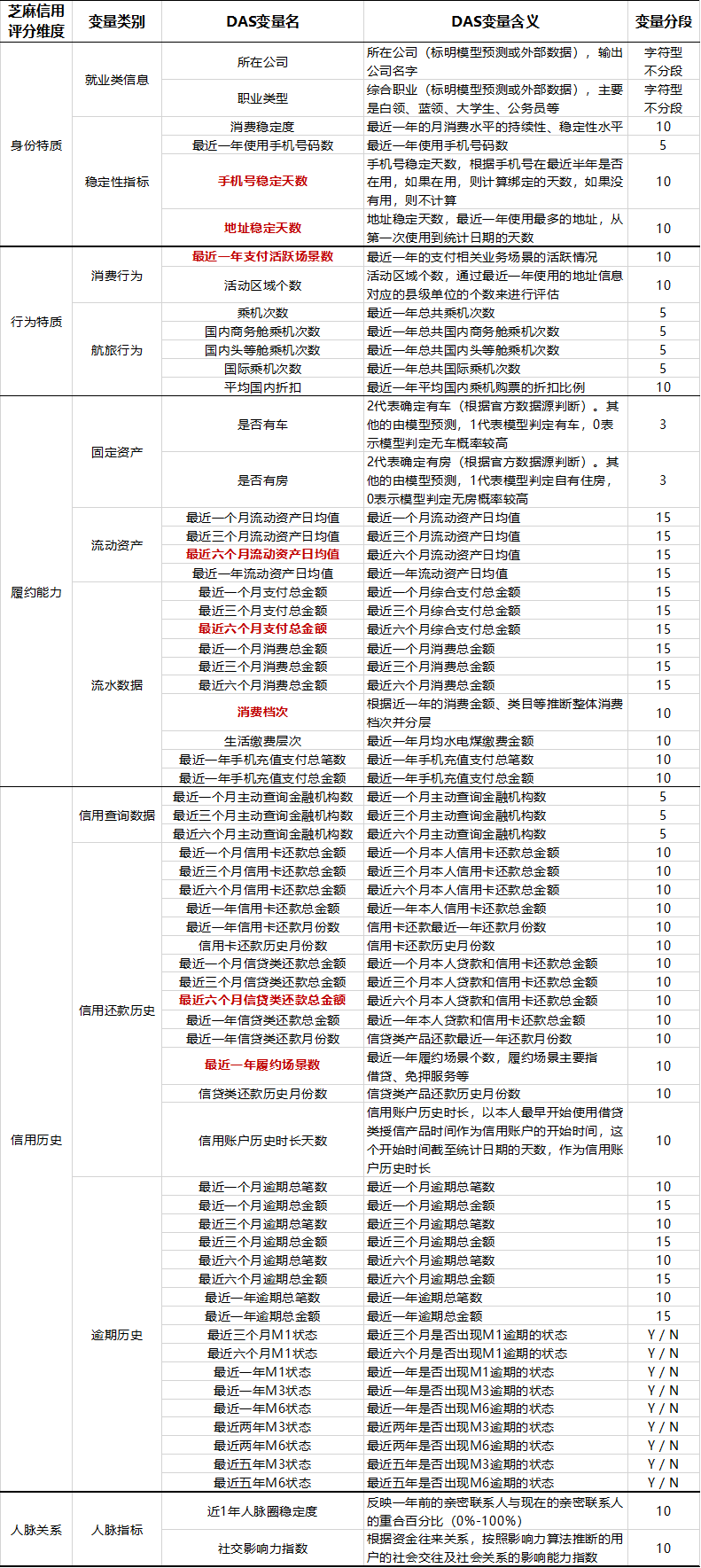
不仅如此,慢C还提出了这些变量分段的要求,例如天数类的、金额类的、次数类的分段区间怎么设等等。只是最终分段还是要结合快大厂大盘数据分布情况再做定夺。
快大厂的策略同学快D秉着“最大化达成合作目的,最小化合作效果”的宗旨,剔除了其中一些过于敏感的数据,并进一步限制了变量分段数量。需求最终提给了模型同学快B去加工,这处加工费了快B半条老命。
不仅四处问人这些字段的取数逻辑,好不容易加工好还总有变量分布不符合预期。过程中,快D找出了无数个问题点,以至于快B天天吐槽快D事儿多。百年之后,快B终于改好了这些变量加工的代码,对着大盘跑批了近两年的数据,并校验了分布稳定合理。
同步慢银行时,还被慢C同学质疑了-1和0取值上的不合理。
三、策略制定
慢银行要了快大厂的大盘数据分布情况后,从行内提取了10w样本,让快大厂的模型同学快B回溯。随后,慢银行的模型同学慢A,对这些字段进行了IV和KS的计算,效果差强人意。没有人惊喜,也没有人发怒。
于是,慢A做了非常详细的数据分析,回匹了行内的客群标签,计算了变量每组下的风险水平。然后,交给了慢C制定策略。慢C操起了所谓的经验之锤,写了一堆case when,得到了最终的风险评级,继而测算了各类人群结构上的占比、通过率、风险、额度水平等等。
写了一些结论,做了一个文档,获得了行内认可。快D苦求了半天,以方便更好的监控服务效果为由,要到了这个毫无营养的文档。如获至宝地同步了快B和厂里的老板。
四、数据部署
标准产品的部署显然跟慢银行都没关系,但即便如此,谁说又能小瞧呢?快B和快D首先讨论了,客群要包括哪些。大盘用户数量巨大,全都算人数太多了,很多人也没有有效数据。
于是按活跃度选定了一个客群。然后讨论了接口服务的困难。要输出的字段有大几十个,这些字段都是要推送线上的,跟模型分的一两个字段部署完全不一样。导致这个部署作业既吃资源,又耗时长。
于是一致决定月更。但日后随着大盘活跃用户增加,该作业的执行和推数效率仍可能存在风险点。最后再制定了数据监控的方案。
快B同学每月跑数完成后要校验所有字段的分布,并邮件正式通知相关方。再第一时间推送线上接口,同时确保推送服务的有效性。对待这些需求,快B只是觉得他们吵闹。
四、我说
这次合作,慢A和快B两位模型同学都沦为了工具,非常弱势,“人为刀俎,我为鱼肉”。没办法,他们是“牛逼哄哄”的算法工程师,数据产品又不是模型,跟他们有什么关系。
算法工程师往往不等于风控同学。在数据产品合作这个项目过程中,他们被策略同学教做人了。我相信这对他们来说是一件好事。算法工程师不应该只会算法。
如果你只会对确定的样本、确定的特征、确定的标签,建一个所谓的大数据模型,不管这个模型是LR,还是XGB,还是神经网络,还是图算法,其实都是不够的。但,这在国内往往是吃得香的。
有一类很难的面试考点叫system design,国外大厂很喜欢考,国内也有很多考的了。风控模型本应该也是一样,如何对遇到的问题设计合理的解决方案,比模型本身重要的多得多。
但,还是有很多算法层面的面试仍然是XGB参数、AUC、KS等。考察的永远都是候选人有没有在认真准备面试。“存在即合理”,我理解不了这句话的解析意,我就是想用其表面意。
#专栏作家#
雷帅,微信公众号:雷帅快与慢,人人都是产品经理专栏作家。风控算法工程师,懂点风控、懂点业务、懂点人生。始终相信经验让工作更简单,继而发现风控让人生更自由。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议









原来是我太肤浅了,以为两者 关系只有钱,没想到还有那么多的联系,学到了
总感觉银行和大厂之间唯一的关联就是贷款,看完之后才明白想的太简单了
我能不能说,看见的第一眼我想到的竟然只有钱,看完之后才恍然大悟。原来是这个样子。