
 起点课堂会员权益
起点课堂会员权益基于深度主动学习的命名实体识别 | 分享总结

众所周知,深度学习在多种实际应用中取得了突破,其背后的主要推动力来自于大数据、大模型及算法。在很多问题中,获取标注准确的大量数据需要很高的成本,这也往往限制了深度学习的应用。而主动学习通过对未标注的数据进行筛选,可以利用少量的标注数据取得较高的学习准确度。因此,深度学习中的主动学习方法也成为了研究的热点。
以下是来自德州大学奥斯汀分校的在读博士沈彦尧,基于亚马逊实习项目延伸探讨了主动学习在深度学习中的应用与思考,并分享了多篇深度主动学习的 ICLR,ICML 文章。
沈彦尧,德州大学奥斯汀分校博士生,第三年在读。清华大学电子工程系本科毕业,主要研究方向为机器学习理论及其应用,曾在亚马逊、微软亚研院实习。
分享主题:主动学习在深度学习中的应用与思考。
分享提纲
- 主动学习的背景介绍及研究意义;
- 主动学习相关理论;
- 主动学习在深度学习中的前沿研究及方法;
- 主动学习在深度学习中的挑战。
分享内容:
本次分享基于本人去年在亚马逊的实习项目「基于深度主动学习的命名实体识别 Deep Active Learning for Named Entity Recognition」而展开,关于该项目的论文「Deep Active Learning for Named Entity Recognition. ICLR, 2018.Shen et al.」已被深度学习领域顶会 ICLR 2018 接收。
本文基于该项目,并延伸探讨了深度主动学习在各类人工智能或者机器学习问题中扮演的角色。
主动学习的背景介绍及研究意义
主动学习和强化学习、半监督学习、在线学习类似,它们都介于监督学习和无监督学习之间,但主动学习又和该三项概念有所不同,可以借助下方图例来具体理解主动学习。
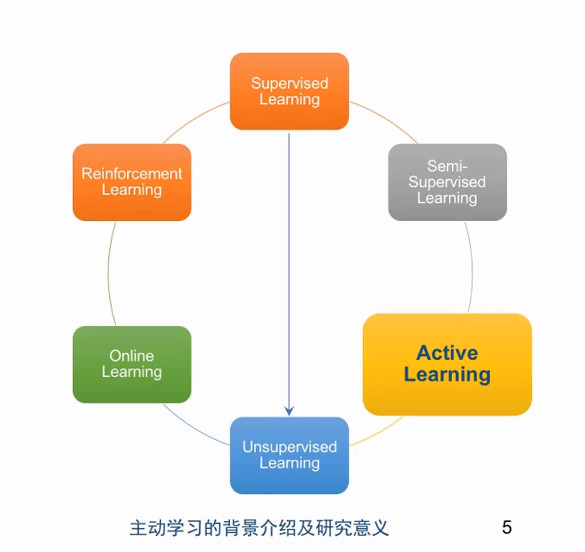
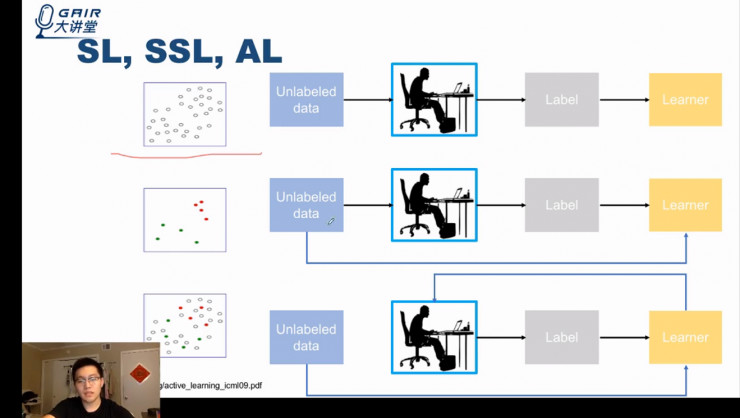
对比监督学习、半监督学习和主动学习的概念图例,可以看到:在主动学习中,模型 (learner) 会主动向 worker 提供想标记的数据,而非由 worker 提供。
下图最后一栏中从模型 (learner) 到 worker 的蓝线即为主动学习的主动部分,在该阶段模型会主动甄别需要标记的数据,判断哪些样本值得学习,哪些不值得学习。
主动学习具有 membership query synthesis、stream-based selective sampling 和 pool-based sampling 三种情景(方法)。
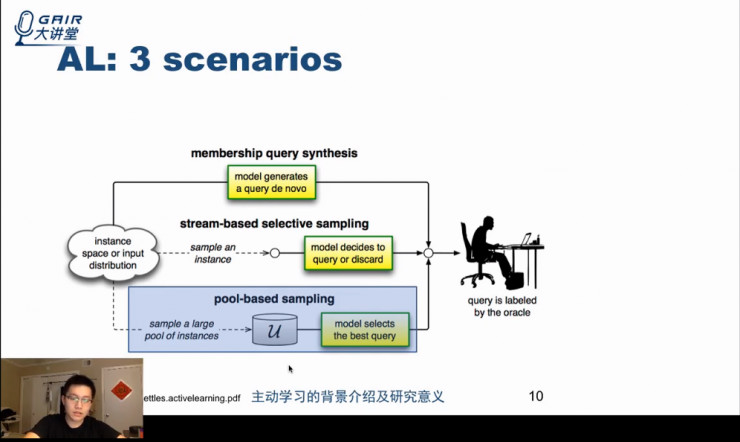
pool-based sampling,顾名思义,即所有的数据均存在于一个池子中,我们的工作就是在该池子中选出一些样本进行标记。
在这样的设定下,所有样本都提供给模型,模型来选择一部分样本进行标记。在实际中,pool-based sampling 在三种方法中所使用的最多。
相较于 pool-based sampling,其他的两种设定更类似人来学习事物的方式。
- membership query synthesis,是指模型可以生成新的样本,即模型可以操控样本的生成。这类似于人在学习的过程中进行举一反三,自己生成一些新的问题,然后通过更深入的研究新问题来提高自己的认知。
- stream-based selective sampling,是指样本不在池子中,而是按一定次序被模型看到,而模型需要决定是否对每个新看到的样本进行标记。这一过程类似于人每天都在接受新的概念和定义并从中选择出需要的内容进行专门学习,不需要的则抛弃或忘记。
概括来讲,最近十多年或者二十多年来的研究中,主动学习领域大部分文章和方法主要基于 pool-based sampling,但实际上要真正进行主动学习,我们更需要模型能够适应 membership query synthesis 和 stream-based selective sampling 这两种和人类学习模式更为相似的情景。
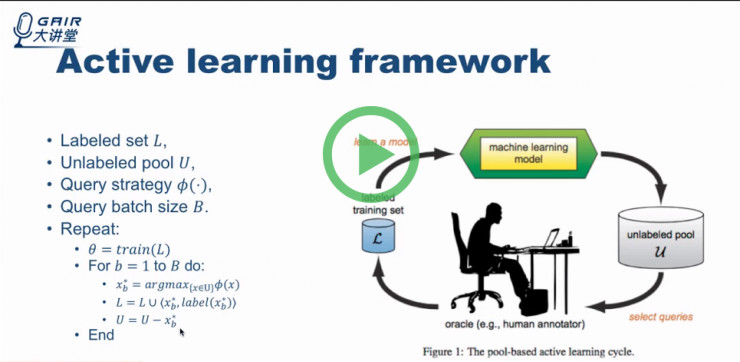
注:关于名词和公式的详细解读,大家可以看的 Active Learning Framework 部分
在主动学习框架中,模型具有 query strategy(即判断哪些样本需要进行标记的方法)。在主动学习过程中,模型会持续进行上图的循环操作,模型的准确率也会随之不断提高,并且通过 query strategy 的设定模型准确率,可能好于随机选取数据进行标记。当在准确率达到一定程度之后,即可停止标记。
接下来讲解主动学习的一种广泛使用的 query strategy,即基于不确定性的采样方法(Uncertainly Sampling Methods)。
它基于一个简单概念,即当有一个分类器或者模型时,选取那些在概率上最不确定的样本进行标注。「概率上最不确定」存在多种定义方式,最常用的几种定义方式列在下图中。

常用的几种定义方式包括 Least confidence、Margin(主要存在于多分类问题)、Token entropy、Sequence entropy 以及 N-best SE 等。
需要注意的是:上面提及的基于不确定性方法来采样(Uncertainly Sampling Methods)仅是诸多主动学习经验方法中的一种。
接下来的内容中还会提及另一种(即 Query-by-Committee),另外还有基于所有点之间距离关系的一种采样方法(选择最具表现性的点,而非只针对每一个点来判断它的不确定性多高)。
总体而言,大家可以提出很多种类似的经验方法。另一方面,也有很多人在进行主动学习的理论研究。
下面我们就简单了解一下这些相关理论的基本原理。
主动学习相关理论
下面来简单介绍主动学习的相关理论。
Query-by-Committee 是一种很重要的算法,它在 1992 年被提出(前面提到的 Uncertainly Sampling Methods 也在同时期被提出)。

关于 Query-by-Committee 最初想法和基本理论,我们借助下面这个图例进行解释。

线性分类的问题中,绿点和红点为已标记的点,列出的几条线代表可能的分类方法(这几条线是假设空间的采样,假设空间可由斜率连续变动的一组线表示,其中每一条线都正确的区分开了绿点和红点)。
根据 QBC 算法:当有一个新的样本进来(图示标记),我们随机挑选两条线,并通过这两个假设来判断该点属于哪一类(红或绿)。
当两条线得出的分类表现一致时(都分类为红点时),就不选择标记该点,随后再选择下一个样本。
这时再次随机挑选两条线,如果一条线预测为红点,另一条线预测为绿点的情况出现时(即结果不一致),模型就会尝试标记这个点(标记为红色)并通过删除错误的假设缩小假设空间(去掉那些预测为绿点的线)。
假设空间会根据这个点来淘汰很多线性分类器,该过程持续循环,即当样本落在该区域内再选择进行标记。假设空间的大小会逐渐变小,并最终生成一个十分准确的模型。

这里,我们来总结主动学习理论中常用的几种假设:
- 假设分类器是 linear separable,即存在一条可以完美分类所有样本的线性分类器;
- 假设二分类任务而非多分类任务;
- 假设样本没有噪声;
- 维持一个假设空间是可行的。
![]()
部分文献中会对这四点中的一点进行松弛并研究,但是我们实际中遇到的问题属于以上四个假设均不满足的情况,这就导致大家,更倾向于在实际中使用不确定性的采样方法之类的经验方法。
因此,主动学习理论对于实际应用中的算法设计缺乏指导性的原因可以总结为以下三个原因:
- 维持一个假设空间十分难以承受;
- 相较于假设理论常用的 stream-based selective sampling,实际中更偏向使用 pool-based sampling;
- 实际任务分类复杂程度远超二分类任务。
主动学习在深度学习中的前沿研究及方法
以上所提及的这些问题因深度学习的到来而愈加关键。
我们可以看到:深度学习取得明显效果的几个应用均具有复杂的模型和巨大的数据量,同时因模型的非线性导致维持一个假设空间十分难以承受。
这些应用包括了下图中我们最熟悉的、已经广泛运用深度学习模型的两类应用:CV 和 NLP。
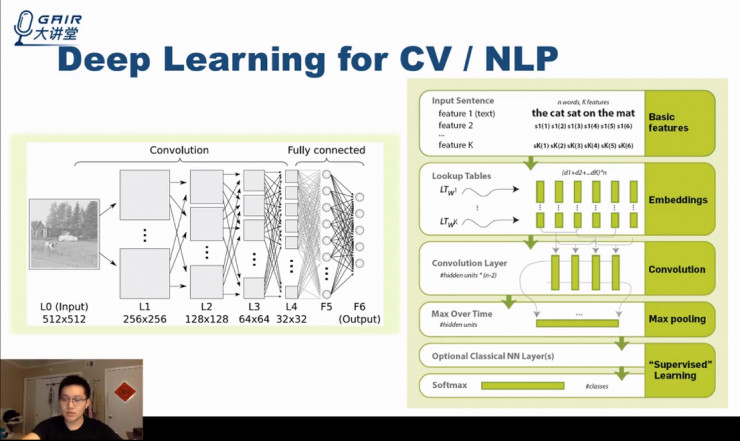
基于以上两种模型,近期有两篇文章研究了在以上两种深度学习模型中的主动学习。它们主要探讨如何利用 Convolution 中学习出来的中间层来更好的选择样本(比如该中间层是否会提供更丰富的 embedding 信息来判断样本与样本之间是否相似等)。
深度主动学习并不只包含解决以上这两个任务,它们只是图像和语言中最容易建模的两种问题:它们都被建模成了简单的分类问题。
而我们在实际应用中遇到的深度学习应用任务更加复杂,例如:序列问题(sequential problems)。
在复杂任务中,有两点问题显得尤为突出:
- 深度模型训练速度很慢(预测的速度同样慢或更慢)。
- 此前的经验方法,是否还能在复杂的问题中继续发挥作用?
这就引出了去年在亚马逊的实习项目——「利用深度主动学习进行命名实体识别(Named Enity Recognition, NER)」。在这个项目中,我们需要在一个序列标记任务中来验证深度主动学习的好处。
NER 问题的一个应用场景是:给出亚马逊用户的一段评论,利用深度学习模型自动识别出代表人、组织、地点、时间等等多类具有实体名词意义的词汇。研究该问题有助于机器理解网站用户留言的含义,这也是很多 NLP 上层任务的一个基础。
我们可以想象:在收集有标注的数据集的时候,需要依靠大量的人工标注,准确的标注出正确的命名实体类别是非常耗时耗力的,这也是我们寄希望于深度主动学习能够减少标注量的主要原因和动机。

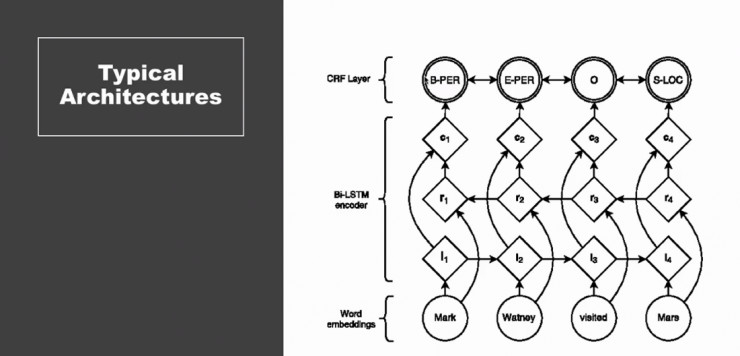
首先,我们先了解一下在普通 NER 任务下,能够取得最好预测结果的模型是怎样设计的。
下图为训练 NER 模型的一个十分流行的深度模型,该模型以 Bi-LSTM 为基础,最后通过 CRF 来生成概率最高的预测序列。
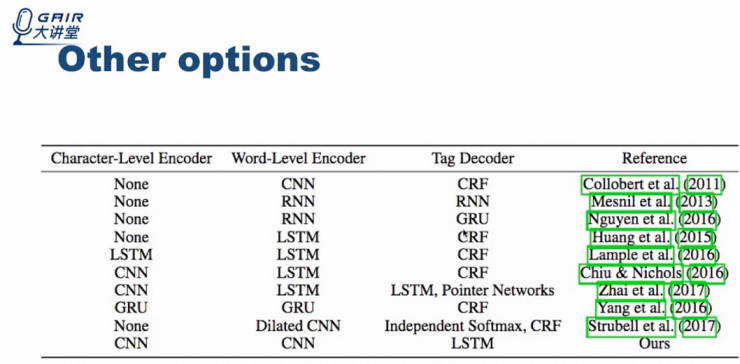
除该典型模型之外,近几年也出现了各种不同的模型,包括使用 Character-Level Encoder(字母级词向量)、Word-Level Encoder(词向量),随后使用 RNN 或者 CRF 来做最终的预测。
各种不同的模型列在下图中的表格内。
具体到本任务中,除去进行监督学习,我们的模型需要能够迅速的对样本进行预测和评估不确定度。
为了能够进一步加快主动学习中利用模型判断不确定性的过程,我们进一步对深度模型进行加速,提出了一个基于 CNN-CNN-LSTM 结构的模型——即 Character-Level Encoder 和 Word-Level Encoder 我们都是用 CNN 进行学习,而最终利用 LSTM 而非 CRF 层进行预测。
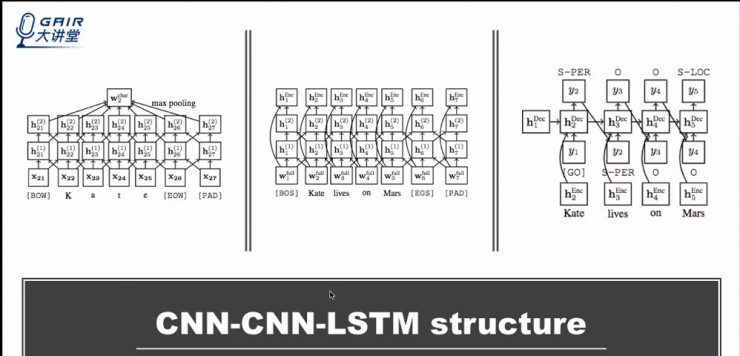
如上图所示:左边是一个 Character-Level Embedding 模型;中间是 world-level embedding 模型;右边是 LSTM 序列生成模型。
通过实验,我们可以比较模型利用 CNN 作为 encoder 的效果,以及 LSTM 作为 decoder 的效果。
可以看出:使用我们的 CNN-CNN-LSTM 结构显著的提升了训练以及预测时的速度,这对于我们使用和验证深度主动学习算法是非常重要的。
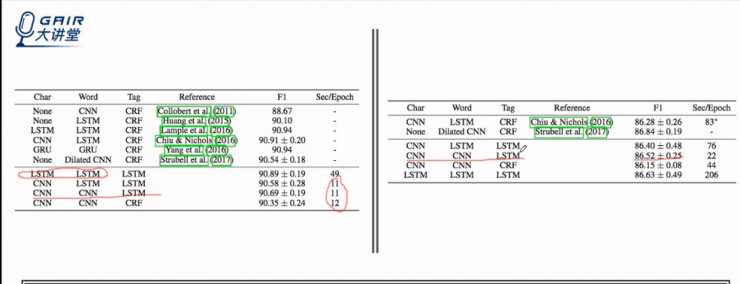
上图左侧是在一个较小的数据集上的测试结果(句子数量较少,且预测标签仅为 4 类);右侧是在一个较大数据集上的测试结果(几十万句子,预测标签 18 种)。
可以看到在两个数据集下,encoder 使用 CNN 相比 LSTM 能得到较好的速度提升。右侧提升速度更为明显,达到了将近十倍的提升速度,并且不损失精度和准确度。
这里利用 LSTM 做 decoder 的速度要优于 CRF,因为 CRF 算法的计算复杂度和标签数量的平方呈正比,而 LSTM 只是正比于标签数量 x 时间长度,当标签数量多时,利用 LSTM 要优于 CRF。这也就是我们不用 CRF 来做机器翻译的原因,其输出可能性太多(光词就有上万种选择)。
结构设计完毕之后,我们可以开始尝试深度主动学习的方法。
我们主要考虑了以下四种算法,并通过实验验证各自的表现:

- 第一种即 Least Confidence(简称 LC),计算预测中最大概率序列的对应概率值。
- 第二种,Maximum Normalized Log-Probality(MNLP),基于 LC 并且考虑到生成中的序列长度对于不确定性的影响,我们做一个 normalization(即除以每个句子的长度),概率则是用每一个点概率输出的 log 值求和来代替。
- 第三种是一个基于 Disagreement 的主动学习方法,主要利用 dropout 在深度学习中的另一个作用(dropout 本来的作用是在训练中为了让模型 generalize 得更好)。去年 Gal et al. 的一篇文章就告诉我们:如果在做 inference 的时候也用 dropout 实际上是等价于来计算模型的不确定性的。这里我们也就需要在做 inference 的过程中也要同时做 dropout,在得到的 M 种结果中计算有多少是不一致的。
- 第四种方法是基于每一个点是否具有代表性的采样方法,除去考虑每一个点的不确定性外,通过计算样本与样本之间的相似度,来进一步判断该选择那些样本更具有代表性。这样的方法在大量数据的情况下需要更加有效的计算方法。我们重新把它处理成一个 submodular maximization 的问题,并利用 streaming algorithm 得到近似最优解。
- 第五种方法是随机生成样本并且标记,作为 baseline。
为了检测刚才提及的五种算法的有效性,先做一个较简单的检验。
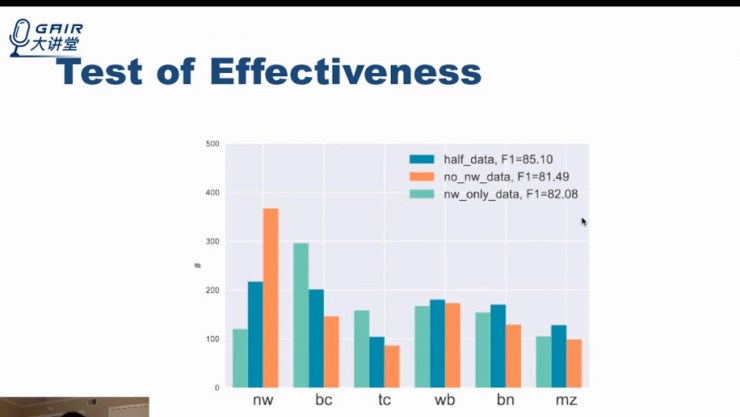
三种颜色代表利用不同数据训练出来的模型,随后在所有未标记和未训练的样本中,利用不确定性的采样方法(Uncertainly Sampling Methods)来计算出最不确定的 1000 个样本和他们的分布。
例如: nw 代表新闻,如果我们此前的训练模型都未使用任何的 nw 样本作为训练信息(橙色模型),那么通过不确定性的采样方法,我们就可以发现: nw 在前 1000 个不确定样本中比例最高,这也间接证明了该算法最有效。
最终结果可以参考下图:
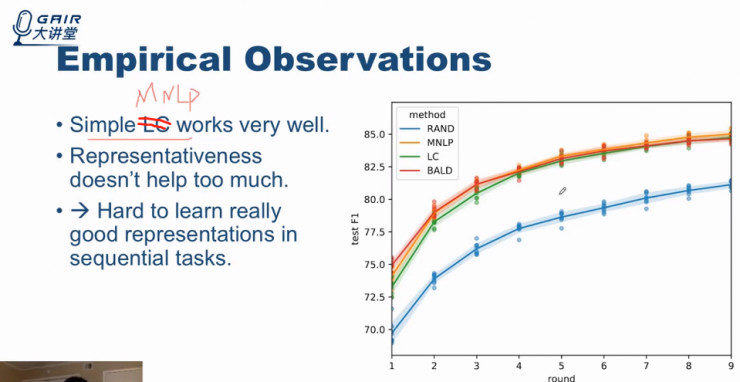
注:PPT 内容错误,LC 应为 MNLP
首先,baseline 方法远低于其他分类方法。在各种方法上,我们跑了多次实验来证明 NER 上的结果准确性,每一种方法跑 10 组,图中也将标准差画了出来,可以看到:LC 稍微差一点,MNLP 和 BALD 最优。
尽管 BALD 与 MNLP 同样很好,但是由于在计算 BALD 的实验中,需要对每一个样本进行 100 次的 inference,计算代价要高于简单的不确定性的采样方法,因此 MNLP 是更值得采取的方法。
另外,我们发现在深度主动学习的问题中,基于代表性的选择方法并没有取得相较 LC 而言任何的提高,我们认为其中的原因主要在于在序列问题任务中,很难学习到一个非常好的表示向量。
也就是说 embedding 并没有很好的表示真正的样本之间的相似度,所以只需要预测每一个样本的概率的不确定性,就已经能达到很好的效果了。
我们简单介绍一下其他的几篇关于深度主动学习的工作,在上述讨论中提到的在 Inference 阶段利用 dropout 可以估计模型的不确定性是 ICML 2017 的一篇文章,主要侧重于深度模型本身的特点。
另一篇 NIPS 2017 的文章其研究重点在于主动学习上,通过利用两个 deep network 来模仿从假设空间中采样这一过程,不断更新这两个 deep network,将更新后的 deep network 认定为两个采样假设,依次判断样本需不需要被标记。
这相当于 QBC 算法的一个变种,并利用了深度模型的强标示性,这些相关文章的具体题目和作者信息可参考 ppt
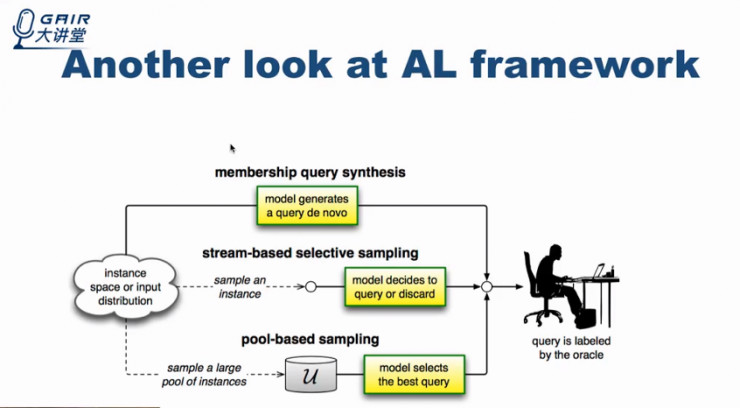
下面,我们再简单回顾主动学习的基本框架。可以看出:我们现在针对的主要是第三种的 pool-based sampling。
那么有没有针对另外两种的研究呢?
近期有研究人员提出,利用增强学习来模拟主动学习选择样本的过程,把选择样本进行标记看作是增强学习中的行为:标记或者不标记。
ICML2017 的这篇文章就是用增强学习的 agent ,来模拟主动学习选择样本的过程。ICLR2018 的这篇文章中,作者考虑在一个更为复杂的任务中,利用增强学习生成更有价值的问题的方法。
这两篇文章均属于主动学习基本框架中的另外两种情景。

主动学习在深度学习中的挑战
最后一部分来介绍主动学习在深度学习中的挑战。
在一些传统,定义得比较好的任务中,我们需要更快的训练过程和更快的 Inference,而其中 inference 速度更为重要。
因为在实际的序列任务中,训练其实是相对较快的。而我们在没有标记的句子中去判断哪些句子更加重要这就比较困难。
例如:在机器翻译中每翻译一个句子是远低于训练一个句子,因为进行 inference 的过程是非并行的,这是深度主动学习需要研究的一个方面。
第二种就是主动学习和生成模型的结合,也就是刚才看到的三种模型框架,第一种是模型可以主动生成样本,目前这一方面点研究很少且挑战巨大。
第三种是优化,Optimization 是任何任务中都十分重要的一个环节,但还尚不清楚设计 network 和优化来让深度模型更有效的来学习任务,深度主动学习其实是在 Optimization 之上的,所以 Optimization 也是主动学习需要关注的一个问题。

在研究深度主动学习的过程中,我们可以借与人进行对比来思考深度主动学习的过程。
拿公认较难的机器翻译任务来举例:目前机器学习在做机器翻译任务的时候,需要几百万句子对的数据集来训练模型,但该种过程与人为翻译不同——主动学习在人翻译的过程中扮演了一个十分重要的角色。
思考机器和人在翻译过程中的学习方式,我们可以发现主动学习(包括主动深度学习)尚有较大提升空间。
再举个例子:之前的 NER 任务中,模型通过计算生成出来的概率值来表示不确定性,但人无需计算概率性的精确值,人在看到一个句子时,是通过简单的模糊判读来决定该样本是否需要学习,即无需进入 decoder 那一层,在之前的 encoder 阶段就可做出判断。而这一点是目前的深度主动学习,还无法解决的一项巨大挑战。
以上就是全部分享内容。
作者:刘鹏
来源:https://www.leiphone.com/news/201805/EguyIsqF4aecx2iA.html
本文来源于人人都是产品经理合作媒体@雷锋网,作者@刘鹏
题图来自PEXELS,基于CC协议






- 目前还没评论,等你发挥!


