
 起点课堂会员权益
起点课堂会员权益传统客服知识库,如何进行图谱化改制以及具体的应用?

基于结构化数据的知识图谱问答系统已经非常成熟,并被广泛应用于搜索引擎及智能客服中。本文对这里面的内容不在进行赘述,主要为大家介绍传统客服知识库,如何进行图谱化改制及具体的应用。
知识图谱简述
知识图谱,其实是知识工程这门学科的延伸,它将知识通过三元组的形式相互勾连起来。通过实体之间的相连的边,定义出实体之间的关系。机器人通过实体识别解析出用户问句中的实体,以识别到的实体作为父节点,通过遍历逻辑找出图谱中对应的实体和关系,进而推理出用户所需的答案。
接下来我们通过构建一个简单的知识图谱,来简单表示图谱的知识推理流程。
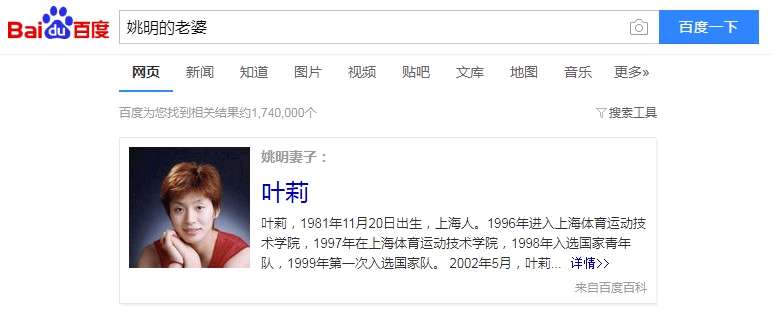
如图,我们构建了“姚明”和“叶莉”两个person entity,他们之间有一对相互的边,这对边的关系为“夫妻”。那么我们就可以能够根据知识图谱的结构化数据,进行一个简单的知识推理。
Q:“姚明的老婆是谁”
A:“叶莉”
当然,这样基础的问答已经被搜索引擎广泛应用
如果说深度学习让机器人有了更好的理解能力,那么知识图谱就是给了机器人推理的能力。人们可以通过定义实体与实体之间的关系,从而让机器进行知识的推理。
但是图谱在应用中也存在着一定的劣势:
- 首先就是对结构化数据的依赖性,由于构建图谱是一件成本很高的工作,因此目前更多的是依赖现有的结构化数据进行机器自动构建,自动构建对于非结构化数据的处理,目前应用仍然存在准确率的问题。
- 其次便是实体识别的准确性,只有实体识别准确,图谱的推理才能是有效且有用的,而当实体的粒度及图谱构建的广度到了一定时,如何在大量的实体中精确命中就成了问题。
- 还有就是遍历的逻辑,知识图谱的推理依赖的就是遍历逻辑,合适的遍历逻辑才能使得图谱的推理合理准确。
- 最后一点就是实体歧义性问题,在客服会话场景中,用户描述会隐含部分信息,例如:绑卡,这个“卡”可以是电话卡,也可以是银行卡。
非结构化知识库图谱化的好处
很多人会有一只疑问,既然目前智能客服准确率已经能够达到了八九十的水平(目前各大公司宣传),那么为什么还要花功夫去构建知识图谱呢?
用户意图不清、上下文
相似度模型计算的是用户问句与知识库中问句的相似度,这是一种单轮的问答对匹配,然而实际的场景中用户,经常会表述不清或者的表述会带有上下文的关系。
例如:
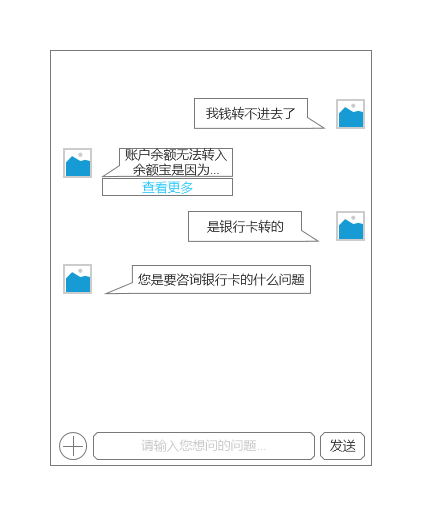
很多人认为这可以通过上下文的技术去解决,然后目前的上下文技术更多的是通过配置的词类与句式实现的。
这就导致了:
- 难以完全覆盖线上用户的问法;
- 句式之间的冲突问题。
因此我们可以通过将知识库进行图谱化,解决用户意图表述不清的问题。当用户表述不清无法获取答案时,我们将识别到的实体组合成交互话术,向用户进行反问。
知识库补全过滤
除了解决用户表述不清、上下文问题,图谱还能通过实体的组合,遍历出所有可能的知识点,补全库中缺的知识点,还可以通过实体组合找出知识库中重复问句。
一般客服知识库积累,是来源于坐席客服日常工作的积累,是一个多人参与维护的知识库,不同人对同样问句的表达会有偏差,这就导致了库中存在一定比例的重复标准句。例如:有的标准句叫:XXX是什么,YYY是什么意思?
提高解析正确率
熟悉短文本相似度模型的人都知道,用于训练的样本量是会影响特征在问句中的权重的。例如:“无法转账”这个问句的训练预料可能有上千句,但是“无法转账提示银行卡余额不足”这个问句的训练预料可能就只有20多句。
那么模型训练后,就会存在用户说:“转不了钱,说是银行卡里没钱”,由于“无法转账”的特征权重过高,而预测出“无法转账”。然后知识图谱的实体识别,就能够通过识别用户问句中的实体,遍历出正确的结果。
知识图谱在非结构化知识库中的应用难点
功能很美好,但是如何将传统的客服知识库进行图谱化改造确实一个难题。智能客服一般都是在原有的客服知识库基础上,通过深度学习的方式,训练短文本相似度模型,实现准确问答的。
客服知识库一般是一个被维护到稳定状态的知识库,虽然有的知识库会有知识点分类,将标准问句根据知识点的层级关系进行分类,但是这也是一种非结构化数据。
客服知识库的图谱化与常见的知识图谱,还是会有一定的区分:
- 知识库图谱化更多是的基于语义的抽取,而非答案的抽取;
- 知识库图谱化是一个有边际的图谱,层级会限制在一定范围内;
- 知识库图谱化的实体不一定只是一个词,也可能是一个短语,例如:提示绑卡失败。
在我们图谱化的工作中以下几个具体的问题就是我们要解决的:
- schema构建问题:在开始做之前,我们先要明确我们需要构建的schema框架、边的类型及定义,schema的构建直接决定了图谱的交互逻辑及遍历逻辑。
- 实体抽取问题:如何定义实体、实体?如何从大量的标准句中抽取出来?
- 遍历逻辑:当我们命中到了实体后,如何进行遍历——即遍历后的交互如何设计?也是需要考虑的。
- 实体不同阶段名称不同:同样的事、物在整个业务的不同阶段的称呼会存在差别,而用户不会进行这么细致的区分,例如:银行卡在绑定后进行理财时叫理财卡,进行支付操作是叫支付卡。
- 业务复杂导致的实体歧义性:当app业务交叉较多时,会出现这种情况,例如:卡可能对应的话费卡,也可能是银行卡。
- schema的时效性问题:由于客服知识库是持续维护更新的,维护包括了新增、删除、合并、挑战,那么图谱也需要同步更新。如果图谱未进行对应的更新,那么就会存在新知识无法图谱不认识,删除了的识别出来无法获取答案。
图谱化流程
schema构建
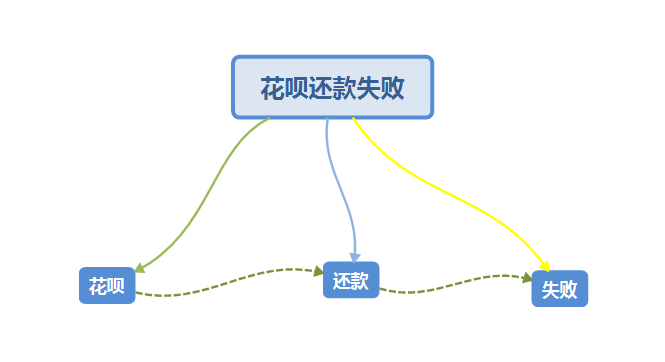
构建图谱的第一步就是先确定图谱的结构,定义结构我们可以先根据知识库中现有的标准句,确定图谱构建的层级。一般我们会将图谱构建成三层的主框架,分别为业务、框架、类型。
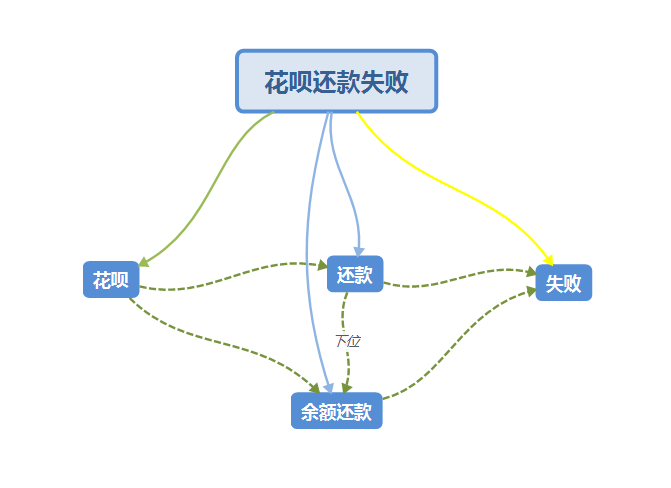
例如:花呗还款失败,我们会拆解为:花呗-还款-失败。
当我们有了基本的基本的主框架结构后,基本上就能够覆盖线上大部分常见问题,但是这并不是我们解决问题的主要方式,因为还有很多句子并不是这样的简单句。
例如:账户余额还花呗失败怎么办,这时我们相对于上面的标准句,增加了一个条件,即:账户余额。那么我们可以在主框架的基础上增加一层的子实体,这个子实体可以是业务,也可以是框架的下位。
实体抽取与定义
当我们定义好了schema的框架和边之后,那么我们剩下的工作就是把标准问进行拆拆拆了。当我们拆分时,我们需要做好拆分的定义文档,避免实体的重复。例如:当我们定义好了一个动词,为开通,通过如下的文档备注,就可以避免其他抽取实体的将开展也作为一个实体进行标注。

这里给大家介绍两个实体抽取工具(应用前应先明确实体的定义,避免抽取时混乱)
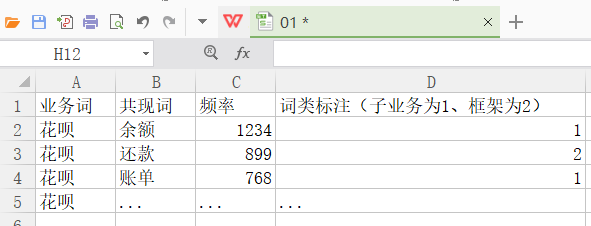
(1)词共现
我们可以通过词共现算法对所有的问句进行处理,这样我们就可以很快得筛选出业务下面的框架、子业务实体,框架下的类型及子框架。
(2)句式结构拆分
句式结构拆分,即我们通过句式的结构将标准问进行拆分,当标准句句式比较规范时,我们可以采用,适合有知识库维护标准的业务方。

实体识别
知识图谱的实体识别目前业界已经有成熟的方案,这里不再作赘述。但是在智能客服的场景中的应用,考虑到上下文的情况,上一轮识别的实体结果也是下一路实体识别的输入之一。
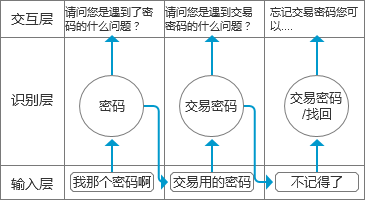
遍历、交互逻辑
遍历的逻辑设计,是根据实体识别的结果进行设计的,由于采用的是三层的结构,因此一共会有三类识别结果:只解析到一层实体;解析到两层实体;三层实体都解析到。
这里我们进行分开讲述:
(1)一层实体
解析到一层实体时,我们不用考虑解析到的具体情况,我们可以直接将识别到的结果解析反问,例如:您是遇到了花呗的什么问题。
(2)两层实体
当解析到两层实体时就会存在两种情况:
- 一种是两个实体之间存在边连接;
- 另一种是两个实体之间不存在边进行连接。
当它们之间存在边连接时,那么我们可以将同样具有着两个实体的路径实体拿出来进行交互。
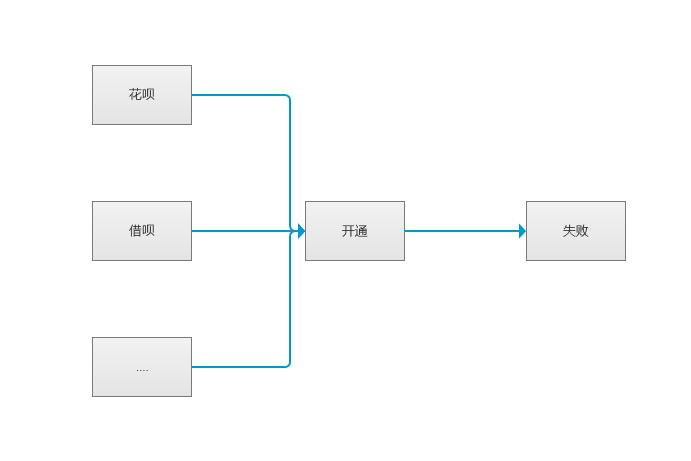
如果两个实体之间没有边连接,那么我们就只能拿置信度高的实体作为遍历的起始节点,交互逻辑和只解析到一层实体一致。
(3)三层实体
当解析到三层实体时,那么存在的情况就会有三种:
- 一种是三个可以组成一个标准问;
- 一种是其中两个有变进行联系;
- 还有一种则是三层实体均无边进行连接。
第一种情况时,那么我们可以直接给用户一个答案作为回应;第二种情况则交互逻辑同解析到两层实体一致;第三种情况则交互逻辑与解析到一层实体一致。
解析方案设计
图谱的解析和短文本相似度解析是并发的结构,这就类似于融合模型一样,通过多套解析方案的融合,使得解析的效果达到一个理想的状态。
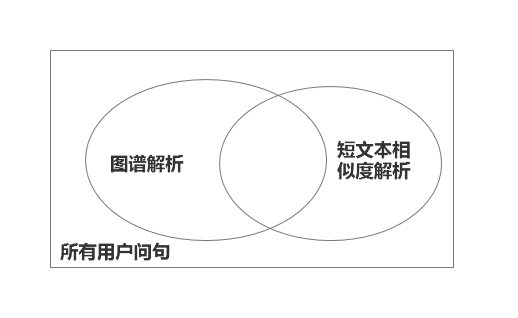
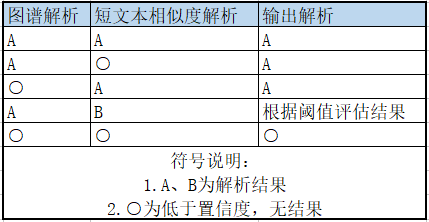
图谱和相似度模型的解析效果是一个交叉的,所以我们通过对两个解析结果的组合,就可以实现正确率的提升。
- 当两个解析结果一致时,我们给出一个结果;
- 当其中一个有结果,一个无结果时,我们给出一个预测结果;
- 当他们给出了不一样的结果时,我们通过评估得出的阈值,给出预测的结果;
- 如果两个模型都没有结果时,我们认为解析失败,机器人进行兜底。
本文由 @祝楠 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议









你好,想要咨询一下有关知识图谱构建的问题,可以加微信交流一下吗
求微信交流
感谢分享,可以交流吗?我的微信是NDLZYZ
大佬,想请教问题
您好,可以加个微信 咨询一下吗
你微信是多少啊,我加你
楼主你好,方便加个微信,咨询下相关的问题么 😳
AI产品经理,需要如此透彻的了解技术相关语言吗?
如果是,那研发转AI产品经理的优势就极大体现了
你好,看了你的文章很有启发,能详细沟通一下吗?(ebele_)
我们正在做这块,在简书上也看到你的文章,苦于联系不到你,能加微信交流下吗,laoqi-hengqiu
可以加微信交流一下吗
可以啊,你微信号多少
可以加微信吗?
可以加个微信吗?
请教一个问题,解析之后得到置信度高的结果之后,如何吐出答案呢?还是会像传统的结构化客服知识库那样,匹配qid返回答案吗
知识图谱中的标准问句是实体的组合,识别到实体后就可以映射到标准句上
感谢科普
感谢支持~
赞
谢谢支持~
很好
不错