
 起点课堂会员权益
起点课堂会员权益分析:基于文本内容推荐和协同过滤推荐
当用户看完某个感兴趣的事物时,推荐系统会给你推荐类似你喜欢的东西,而本文主要分析一下关于协同过滤推荐和基于文本内容推荐的这两种推荐方式。

(1)需求背景
- 当用户表示出对一些内容感兴趣的时候,满足用户的一个拓展的兴趣;比如:feed流产品,让你对新的内容既有熟悉感并且有新颖感,这样的话就能够促进用户进一步内容消费。
- 一般是在内容消费完结时推荐,比如:看完一部小说,会给你推荐通类型的小说,看完一部钢铁侠的电影,会给你推荐钢铁侠系列电影。
相似内容推荐的核心逻辑——即推荐用户在当前当刻下最感兴趣的或者与这个内容最相似的一个内容。
(2)业务目标
业务目标:推荐内容用户消费行为的最大化
(3)衡量标准
- 简单的方式就是CTR的方式,用户点击的数量/推荐的数量。
- 用户行为消费的深浅,比如:一个网页的用户停留事件,网页的浏览完成时间。
基于文本内容推荐Content-base
1. 基本原理
使用内容的元数据,或者针对内容的自身的分析,对于任意内容A、B,计算AB之间两两相似度Sab,推荐给用户相似度最高的N个内容。
2. 关键路径
(1)定义度量标准
标准类似于坐标轴,例如:人有很多属性,性别、年龄、身高、体重、文化程度、专业技能等。
这些共同构成的一个多维空间,每一个特定的人,在每一个维度上面都会有一个具体的值,这样就实现对一个特定人的量化表示。实现从一个人的个体到一个N维度的向量的一个映射,并且由于面对的需求不一样,我们构建的一个特征空间可能是不一样的。
继续上面的例子,如果我们要挑选好的战士,那么特征空间可能就包括性别、年龄、身高、体重,等维度基本就够了。那如果要挑选好的产品经理,这些维度肯定不不够全面。
(2)对内容进行量化
对各个内容,如:文章、商品,通过上面定义的维度进行量化。
(3)计算相似度
- 算距离度量,及文本在立体在空间上存在的距离,距离越远说明个体间的差异越大。
- 算相似度度量,相似度度量的值越小,说明个体间相似度越小,差异越大。
距离度量和相似度量是负相关的——距离小、“离得近”、相似度高;距离大、“离得远”、相似度低。
3. 举例
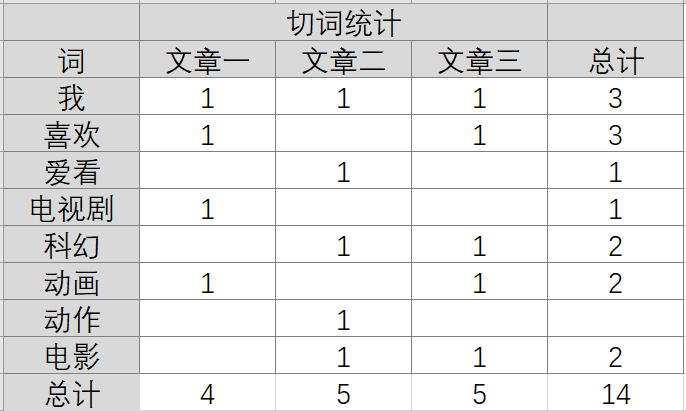
(1)定义度量标准:全体有益的词,如果两篇文章中相同的词汇越多,则认为两篇文章越相似。
首先我们需要对文章进行处理,通过切词,去掉没有意义的形容词,得到关键词的一个集合,这样完成了一篇文章到一个集合的映射。
(2)对内容进行量化
如果直接对关键词量化,首先想到的是统计一下文档中每个词出现的频率(TF),词频越高,这个词就越重要。但是统计完你可能会发现你得到的关键词基本都是“的”、“是”、“为”这样没有实际意义的词(停用词)。因此,我们需要通过TF-IDF的方法进行预处理。
TF-IDF指在上出现得越频繁的一些词,也就是说越是大众货色的词。那我们认为,对于区分不同内容的贡献度就越低。他们的权重应该降低,这个权重就是(IDF)。
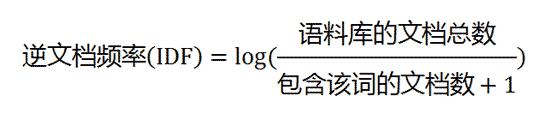

![]()
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
举一个例子说明一下:
- 文章1:我喜欢动漫电视剧;
- 文章2:我爱科幻动作电影;
- 文章3:我喜欢动画科幻电影。
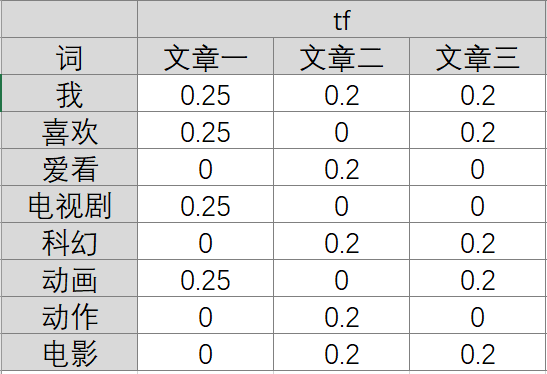
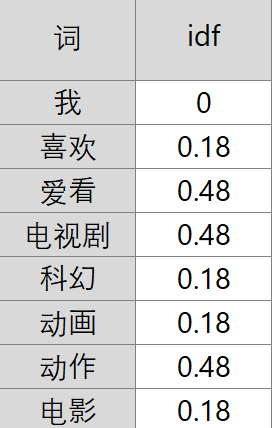
在计算IDF时,如果该词语不在语料库中,就会导致被除数为零,因此一般情况下会加1为了简便计算,分母只包含改词的文档数,公式如下:
![]()
计算结果如下:
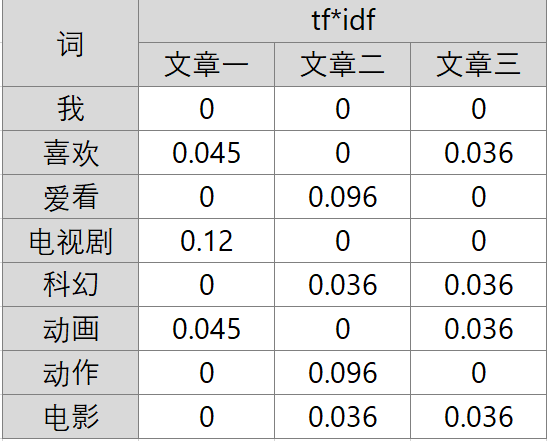
- 文章1:(0.045,0,0.12,0,0.045,0,0,0)
- 文章2:(0,0.096,0,0.036,0,0.096,0.096,0.036)
- 文章3:(0.036,0,0,0.036,0.036,0,0.036,0)
在此过程中完成了文章向向量的转化。
(3)计算相似度
算距离度量常用的算法:
欧式距离
欧式距离是最常见的距离度量,衡量的是多维空间中各点之间的绝对距离,公式如下:

根据距离度量越大差异越大,相似度如下:文章1,文章3> 文章2,文章3> 文章1,文章2。
闵可夫斯基距离
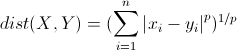
P是一个变参数,当 P=1 时,就是曼哈顿距离当 P=2 时,就是欧氏距离。
曼哈顿距离
和欧氏距离非常相似(把平方换成了绝对值,拿掉了根号),公式如下:
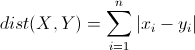
- Dist(文章1,文章2=|0.045|+|0.096|+|0.12|+|0.036|+|0.045|+|0.096|+|0.036|=0.47
- Dist(文章1,文章3)=0.21
- Dist(文章2,文章3)=0.264
与欧式距离结果类似。
算相似度度量, 常用的算法:
余弦相似度
余弦相似度用向量空间中两个向量夹角的余弦值,作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
公式如下:
![]()

根据相似度量越小,相似度如下:文章1,文章3> 文章2,文章3> 文章1,文章2。
皮尔逊相似系数
即相关分析中的相关系数r,分别对X和Y基于自身总体标准化后计算空间向量的余弦夹角。
公式如下:
![]()
Jaccard相似度
卡德相似度,指的是文本A与文本B中交集的字数除以并集的字数,杰卡德相似度与文本的位置、顺序均无关,并且公式非常简单:
![]()
- Jaccard(文章1,文章2) =0
- Jaccard(文章1,文章3)=3/8
- Jaccard(文章2,文章3)=3/8
相似度结果如下:文章2,文章3=文章1,文章3>文章1,文章2。
使用哪种方法计算相似度都可以,没有一个明确的答案谁好谁坏,相反,我们怎么定义这种度量标准,如何实现精细化的量化?这相对来说更加重要些。
总结
优点:
- 用户之间具有独立性:每个用户的推荐都是根据用户自身的行为所获得的,与其他人无关;
- 好的可解释性:你可以向用户解释为什么会给他推荐这些内容;
- 冷启动快捷:对于新加入的物品可以直接在推荐结果中曝光。
缺点:
- 度量标准难定义:上面的例子为文章,我们可以通过 tf-idf 抽取文章的特征,但是我们在大多数的情况下很难从项目中抽取特征,比如:视频等多媒体内容中,信息的都蕴含在高纬度中,很难进行抽取。
- 无法挖掘用户的潜在兴趣:我们推荐的内容只是根据用户过去的喜好,因此推荐的内容也跟用户过去喜好的相似。
- 新用户无法推荐:由于新用户没有浏览历史,因此无法获得用户的喜好。
协同过滤推荐 Collaborative Filtering
1. 基本原理
对于每个用户,采集对每个内容的消费行为,量化构建用户-内容行为矩阵,通过该矩阵的分析处理计算内容-内容的两两相似度。
2. 主要步骤
(1)用户行为的采集
用户的反馈通常分为两种:一种是正反馈行为,一种是负反馈行为。
在正反馈行为中还分为显性和隐形两种,,比如说:评价、分享、点赞、收藏、下载等等。用户主动参与的,认为是一个正反馈显性的行为,比如:用户页面的停留时间,播放视频等自然操作行为,认为是一个正反馈的隐形行为。
但是由于我们在实际收集数据中,采集到用户正反馈的显性行为比较少,往往需要隐形的数据帮助我们推荐更精准的量化。负反馈行为就是负向评价,或者投反对票,不喜欢等。
(2)用户-内容行为矩阵构建
划定采集行为的窗口期:从现在开始我要回溯多久的一个数据,确定窗口期的原因在于我们的内容会发生变化,并且用户的兴趣也可能发生变化,因此,具体的窗口期需要根据各个业务领域而定,比如新闻类,窗口期不宜设置过长。
定义正负反馈行为的权重:一般来说,显性的正反馈的权重大于隐形的正反馈,比如正向的评价,肯定会比页面停留时间的权重要高,而负反馈的权重需要根据用户行为的深浅进行判断,比如:用户如果明确点击了不喜欢,或者一个负向的评价,则可以认为是一个权重比较高的行为。
数据的预处理(降噪和归一化):
- 降噪:数据是用户使用过程中产生的,因此会存在大量的噪音和误操作,需要将这些数据进行过滤,比如:在用户的生命周期中,只产生了一到两次的正反馈行为,这种用户的参考价值比较低。
- 归一化:目的是让大的输入,大的信号映射到小范围内。
假设一个产品用户查看次数为X1、分享次数X2,权重分别为Y1、Y2,加权求和 X1 Y1+ X2 Y2 。
假设’ X1属于[10~1000],X2属于[0~1],由于X1远远大于X2,那么X2 Y2就可以忽略不计了,整个加权求和就只由X1 Y1决定,小的信号被淹没了。
常用的函数:
- y=(x-MinValue)/(MaxValue-MinValue) (归一到0 1 之间)
- y=0.1+(x-min)/(max-min)*(0.9-0.1)(归一到0.1-0.9之间)
(3)矩阵分析计算相似度
此过程中依旧是基于向量,计算两个向量之间的距离或者计算相似度,算法与上面CB中基本一致。
在用户-行为矩阵中,有两种维度计算方式:
- 将用户对所有的物品的偏好,作为一个向量计算用户之间的相似度。
- 将所有用户对某个物品的偏好,作为向量来计算物品之间的相似度。
3. 例子
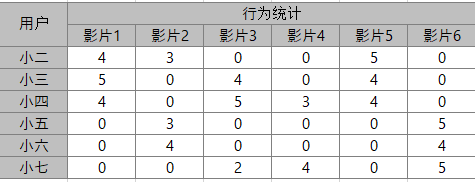
(1)用户行为-矩阵的构建
收集到如下正反馈行为及赋权规则:查看=1、收藏=4、分享=1。
用户-行为矩阵:每个单元格代表了用户在该影片的行为量化后的结果。
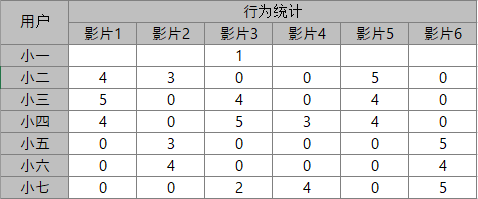
数据预处理
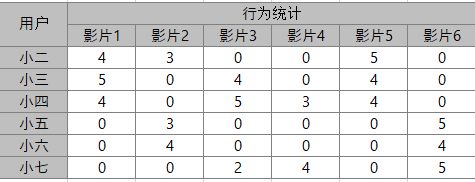
(2)计算相似度
基于用户维度
首先计算用户与其他用户在商品维度上的相似性,每一个用户都可以用一个向量表示,首先计算第一个用户与其他用户的余弦相似度。
小二的向量可以表示为(4,3,0,0,5,0),其他类似:
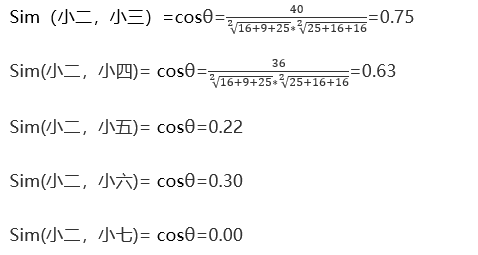
Sim(小二,小三)>Sim(小二,小四)> Sim(小二,小五)> Sim(小二,小六) >Sim(小七)。
由结果可以看出,小二,小三的相似度高,和小七完全不相似,根据此计算每个用户之间的相似度。
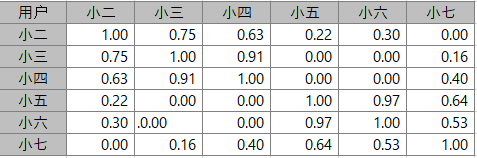
首先找到与小二最相似的N个用户,这个n=2,最相近的用户为小三、小四,且除去小二的看过的影片还有影片3、影片4。
- 影片3=(0.7*4+0.6*5)/(0.7+0.6)=4.5
- 影片4=(0.6*3)/0.6=3.0
因此向用户推荐影片3和影片4。
基于商品维度
每一个影片都可以通过向量表示,影片1的向量可以表示为(4,5,4,0,0,0)。
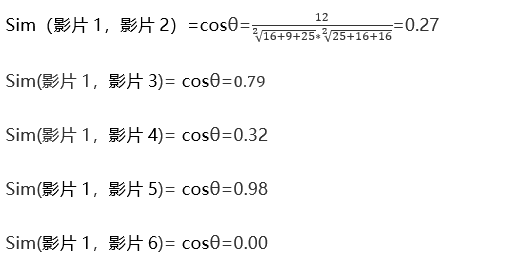
根据此计算每影片之间的相似度。
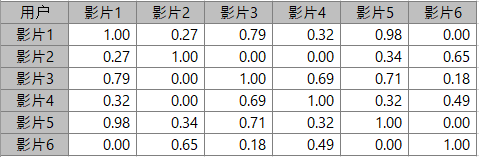
小二,看了影片1、影片2、影片5。
- 与影片1相似的有:影片3、影片5
- 与影片2相似的有:影片6、影片5
- 与影片5相似的有:影片3、影片1、
应该先用户推荐:影片3和影片6。
总结
优点:不依赖对于内容的理解,甚至可夸异构内容实现推荐。
缺点:
- 头部内容的问题:非常热门的内容容易覆盖用户行为更多,比如最近比较火的《延禧攻略》,如果仅仅基于行为来说的话,会有很多用户都会产生正向的行为,这样计算出来了,就会更很多内容有相似性,因此还需要进行降权处理。
- 业务关联导致的相关性:在内容的生命周期内,由于业务关联导致用户既看了这个,又看了那个。
- 其他:容易受脏数据污染,新内容冷启动慢,结果解释性差。
本文由 @SincerityY 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议








写的非常棒
非常优秀了
学习了,本科论文就是用的jaccard相似度,现在都忘了
腻害