
 起点课堂会员权益
起点课堂会员权益如何通过用数据挖掘技术来分析Web网站日志?

收集web日志的目的
Web日志挖掘是指采用数据挖掘技术,对站点用户访问Web服务器过程中产生的日志数据进行分析处理,从而发现Web用户的访问模式和兴趣爱好等,这些信息对站点建设潜在有用的可理解的未知信息和知识,用于分析站点的被访问情况,辅助站点管理和决策支持等。
1、以改进web站点设计为目标,通过挖掘用户聚类和用户的频繁访问路径,修改站点的页面之间的链接关系,以适应用户的访问习惯,并且同时为用户提供有针对性的电子商务活动和个性化的信息服务,应用信息推拉技术构建智能化Web站点。
2、以分析Web站点性能为目标,主要从统计学的角度,对日志数据项进行粗略的统计分析,得到用户频繁访问页、单位时间的访问数、访问数量随时间分布图等。现有的绝大多数的Web日志分析工具都属于此类。
3、以理解用户意图为目标,主要是通过与用户交互的过程收集用户的信息,Web服务器根据这些信息对用户请求的页面进行裁剪,为用户返回定制的页面,其目的就是提高用户的满意度和提供个性化的服务。
收集方式
网站分析数据主要有三种收集方式:Web日志、Javascript标记和包嗅探器。
Web日志
web日志处理流程:
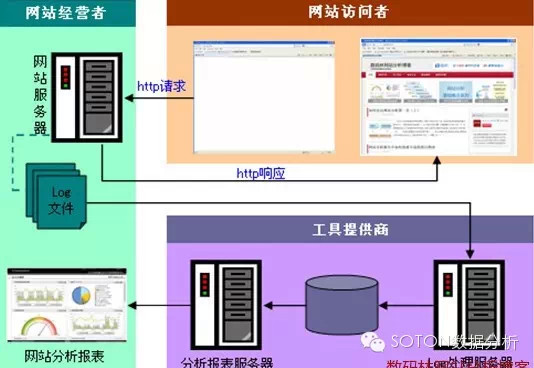
从上图可以看出网站分析数据的收集从网站访问者输入URL向网站服务器发出http请求就开始了。网站服务器接收到请求后会在自己的Log文件中追加一条记录,记录内容包括:远程主机名(或者是IP地址)、登录名、登录全名、发请求的日期、发请求的时间、请求的详细(包括请求的方法、地址、协议)、请求返回的状态、请求文档的大小。随后网站服务器将页面返回到访问者的浏览器内得以展现。
Javascript标记
Javascript标记处理流程:
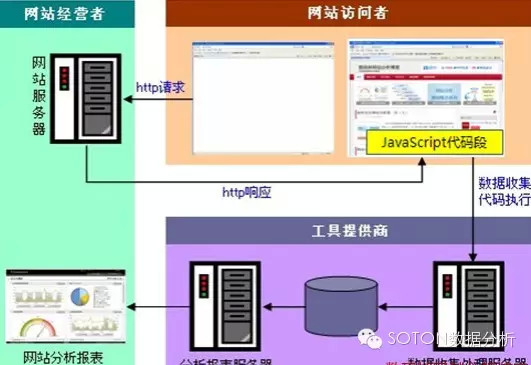
上图所示Javascript标记同Web日志收集数据一样,从网站访问者发出http请求开始。不同的是,Javascript标记返回给访问者的网页代码中会包含一段特殊的Javascript代码,当页面展示的同时这段代码也得以执行。这段代码会从访问者的Cookie中取得详细信息(访问时间、浏览器信息、工具厂商赋予当前访问者的userID等)并发送到工具商的数据收集服务器。数据收集服务器对收集到的数据处理后存入数据库中。网站经营人员通过访问分析报表系统查看这些数据。
包嗅探器
通过包嗅探器收集分析的流程:
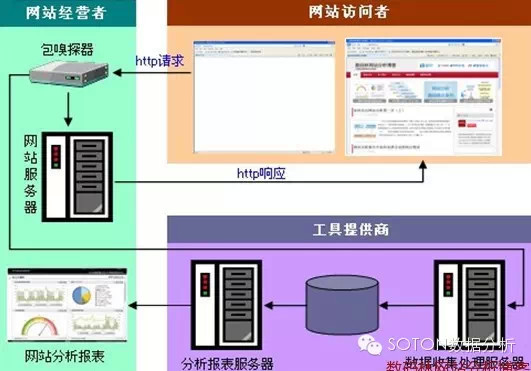
上图可以看出网站访问者发出的请求到达网站服务器之前,会先经过包嗅探器,然后包嗅探器才会将请求发送到网站服务器。包嗅探器收集到的数据经过工具厂商的处理服务器后存入数据库。随后网站经营人员就可以通过分析报表系统看到这些数据。
web日志挖掘过程
整体流程参考下图:
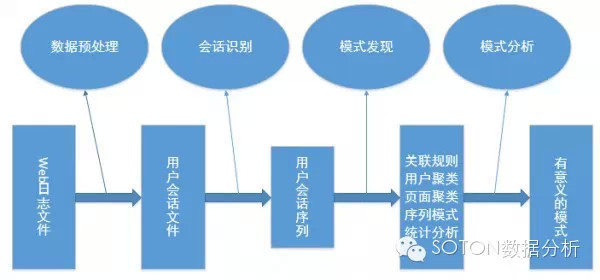
1、数据预处理阶段根据挖掘的目的,对原始Web日志文件中的数据进行提取、分解、合并、最后转换为用户会话文件。该阶段是Web访问信息挖掘最关键的阶段,数据预处理包括:关于用户访问信息的预处理、关于内容和结构的预处理。
2、会话识别阶段该阶段本是属于数据预处理阶段中的一部分,这里将其划分成单独的一个阶段,是因为把用户会话文件划分成的一组组用户会话序列将直接用于挖掘算法,它的精准度直接决定了挖掘结果的好坏,是挖掘过程中最重要的阶段。
3、模式发现阶段模式发现是运用各种方法和技术从Web日志数据中挖掘和发现用户使用Web的各种潜在的规律和模式。模式发现使用的算法和方法不仅仅来自数据挖掘领域,还包括机器学习、统计学和模式识别等其他专业领域。
模式发现的主要技术有:统计分析(statistical analysis)、关联规则(association rules)、聚类(clustering)、归类(classification)、序列模式(sequential patterns)、依赖关系(dependency)。
(1)统计分析(statistical analysis):常用的统计技术有:贝叶斯定理、预测回归、对数回归、对数-线性回归等。可用来分析网页的访问频率,网页的访问时间、访问路径。可用于系统性能分析、发现安全漏洞、为网站修改、市场决策提供支持。
(2)关联规则(association rules):关联规则是最基本的挖掘技术,同时也是WUM最常用的方法。在WUM中常常用在被访问的网页中,这有利于优化网站组织、网站设计者、网站内容管理者和市场分析,通过市场分析可以知道哪些商品被频繁购买,哪些顾客是潜在顾客。
(3)聚类(clustering):聚类技术是在海量数据中寻找彼此相似对象组,这些数据基于距离函数求出对象组之间的相似度。在WUM中可以把具有相似模式的用户分成组,可以用于电子商务中市场分片和为用户提供个性化服务。
(4)归类(classification):归类技术主要用途是将用户资料归入某一特定类中,它与机器学习关系很紧密。可以用的技术有:决策树(decision tree)、K-最近邻居、Naïve Bayesian classifiers、支持向量机(support vector machines)。
(5)序列模式(sequential patterns):给定一个由不同序列组成的集合,其中,每个序列由不同的元素按顺序有序排列,每个元素由不同项目组成,同时给定一个用户指定的最小支持度阈值,序列模式挖掘就是找出所有的频繁子序列,即子序列在序列集中的出现频率不低于用户指定的最小支持度阈值。
(6)依赖关系(dependency):一个依赖关系存在于两个元素之间,如果一个元素A的值可以推出另一个元素B的值,则B依赖于A。
4、模式分析阶段模式分析是Web使用挖掘最后一步,主要目的是过滤模式发现阶段产生的规则和模式,去除那些无用的模式,并把发现的模式通过一定的方法直观的表现出来。由于Web使用挖掘在大多数情况下属于无偏向学习,有可能挖掘出所有的模式和规则,所以不能排除其中有些模式是常识性的,普通的或最终用户不感兴趣的,故必须采用模式分析的方法使得挖掘出来的规则和知识具有可读性和最终可理解性。常见的模式分析方法有图形和可视化技术、数据库查询机制、数理统计和可用性分析等。
收集数据
收集的数据主要包括:
全局UUID、访问日期、访问时间、生成日志项的服务器的IP地址、客户端试图执行的操作、客户端访问的服务器资源、客户端尝试执行的查询、客户端连接到的端口号、访问服务器的已验证用户名称、发送服务器资源请求的客户端IP地址、客户端使用的操作系统、浏览器等信息、操作的状态码(200等)、子状态、用Windows@使用的术语表示的操作的状态、点击次数。
用户识别
对于网站的运营者来说,如何能够高效精确的识别用户非常关键,这会对网站运营带来极大的帮助,如定向推荐等。
用户识别方法如下:
使用HDFS存储
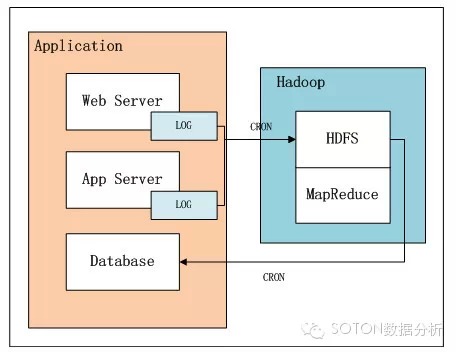
数据收集到服务器之后,根据数据量可以考虑将数据存储在hadoop的HDFS中。
在现在的企业中,一般情况下都是多台服务器生成日志,日志包括nginx生成的,也包括在程序中使用log4j生成的自定义格式的。
通常的架构如下图:
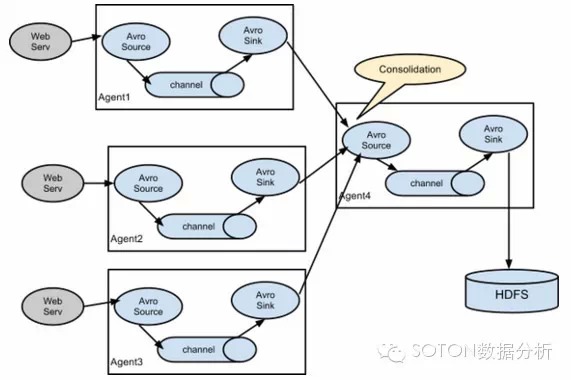
使用mapreduce分析nginx日志
nginx默认的日志格式如下:
222.68.172.190 – – [18/Sep/2013:06:49:57 +0000] “GET /images/my.jpg HTTP/1.1” 200 19939 “http://www.angularjs.cn/A00n” “Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36(KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36”
remote_addr: 记录客户端的ip地址, 222.68.172.190
remote_user: 记录客户端用户名称,
time_local: 记录访问时间与时区, [18/Sep/2013:06:49:57 +0000]
request: 记录请求的url与http协议, “GET /images/my.jpg HTTP/1.1″
status: 记录请求状态,成功是200, 200
body_bytes_sent: 记录发送给客户端文件主体内容大小, 19939
http_referer: 用来记录从那个页面链接访问过来的, “http://www.angularjs.cn/A00n”
http_user_agent: 记录客户浏览器的相关信息, “Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36″可以直接使用mapreduce来进行日志分析:
在hadoop中计算后定时导入到关系型数据库中进行展现。
也可以使用hive来代替mapreduce进行分析。
总结
web日志收集是每个互联网企业必须要处理的过程,当收集上来数据,并且通过适当的数据挖掘之后,会对整体网站的运营能力及网站的优化带来质的提升,真正的做到数据化分析和数据化运营。
本文转载自:SOTON数据分析






- 目前还没评论,等你发挥!


