
 起点课堂会员权益
起点课堂会员权益自建运营分析系统:埋点&运营分析产品设计
本文以公司自建的运营分析系统为讨论对象,对系统的产品架构设计及技术方案选型进行了分析以及要点说明。

目前市面上关于流量分析的产品已经做到非常标准化了,如GrowingIO、诸葛IO、神策数据等,通用的用户分析、转化分析、留存分析等功能已经非常完善了,但是在公司实际应用过程中,运营人员总会有各种个性化的需求是市面上通用功能无法满足的。也是基于这个原因,不少公司会自建运营分析系统,本文会详细描述下之前我所在的公司运营分析系统的产品架构设计及技术方案选型,希望能够给到各位一些参考。
一、现状和问题
1.1 埋点方案重构
我们公司埋点方案做得早,最早的时候只有代码埋点,而且PC/M和APP的埋点上报方式不同:APP端是使用appsflyer实现的【事件级】上报机制,PC/M端是基于页面【元素级】上报机制。
这两者有什么区别?
简单来说,事件是有业务含义的,比如【首页广告位点击事件】,指的是用户在网站首页点击“XX广告位”图片的行为,这样上报上来的数据是可以直接指导分析的;
页面元素的上报是冷冰冰的元素采集,同样是广告位点击,页面元素上报会通过在广告栏位的代码埋点对每个广告图的点击、曝光等行为进行上报,在分析【首页广告位点击事件】时,分析师需要找到首页–广告位–广告图、取其中的点击行为数据进行分析。
也就是说【事件级】是组装好的业务数据,【元素级】是未组装的数据,【元素级】虽然很灵活,但在数据应用的效率、存储成本、业务接受度上,【事件级】都要更优。
目前GrowingIO、神策数据等厂商都使用【事件级】的埋点方案作为分析系统的基础,要打造运营分析系统,首先第一步就要改造埋点方案。
1.2 产品架构规划
此前由于运营部门已经购买了GrowingIO,因此提到IT的需求都是一些零散的个性化需求,简单来说就是个性化报表,主要特点是:业务逻辑复杂+开发周期长,业务体验特别差。
因为都是零散的个性化需求,缺少了对【逻辑层】的规划,所以报表都是直接从【数据层】开发落地到【应用层】。
系统产品架构规划如下图所示:
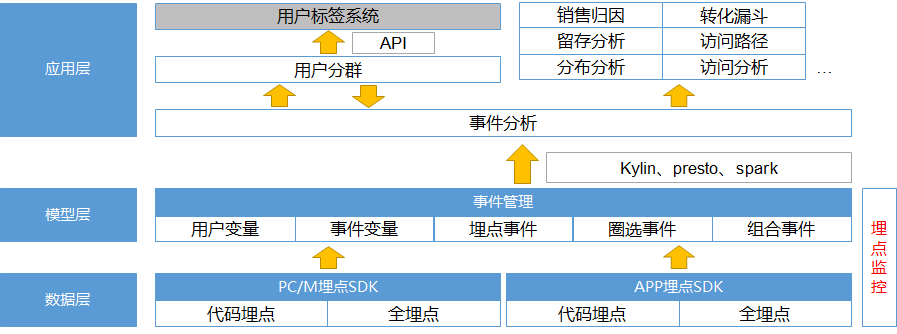
因此,我们认为运营分析系统的功能建设有两个重点:
- 逻辑层:事件管理要与业务数据解耦,支持多租户(满足不同站点或业务模块的事件逻辑隔离)
- 应用层:事件分析是GrowingIO中使用率超过80%的功能,是用户分群及其他分析功能的基础
二、建设方案及计划
2.1 埋点方案的选择
目前常用的埋点方案有三种,代码埋点、可视化埋点以及全埋点(也叫无埋点)。
关于这三者之间的区别在不少的文章中都有过阐述,这里用一个商超的例子做说明。
假如网站就是一个大型商超,那么有三种方式可以获取用户数据:
第一种,在需要监控的店铺内、货柜上安置摄像头,可以完整监控用户在店铺停留了多久、浏览哪些品类、试用哪些产品等等详细的用户行为;
第二种,在商超中各个主道、楼道位置预留摄像头监控位,当需要监控特定主道或楼道时打开摄像头开关就可以记录商超用户行为轨迹,虽然无法记录用户在店铺内都具体浏览了什么买了什么东西,但可以知道用户沿着哪个方向进行购物、进入了哪些店铺、每个店铺的人流量等;
第三种,还是预留摄像头监控位,但是每个摄像头都是开启状态,全年无休地监控每个主干道和楼道的人流情况;
以上三种,分别对应的就是代码埋点、可视化埋点及全埋点。
如果说商超是网站,那商超里的店铺就是实际产生的业务交易行为。
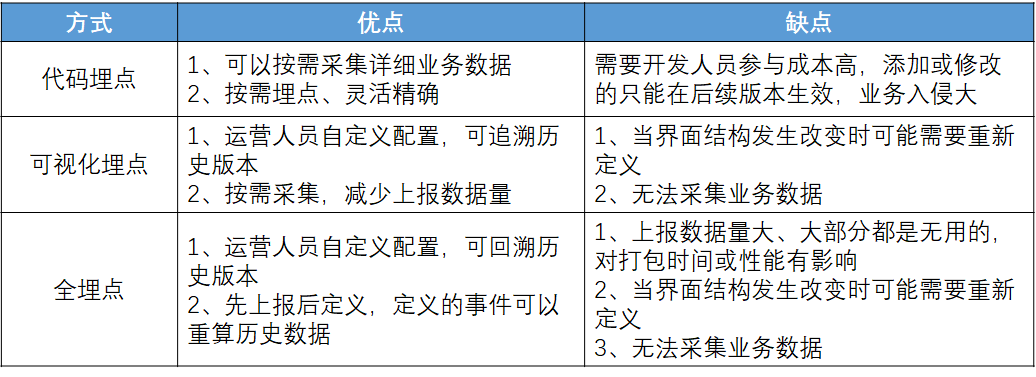
- 代码埋点的优势明显,它能够获取到店铺内的业务交易行为以及行为双方的交易媒介、交易细节等,缺点是店铺数量多、埋点成本高;
- 可视化埋点的优点在于灵活、低成本,根据需要分析的具体问题再打开“摄像头”,缺点是无法获取交易的细节;
- 全埋点对比可视化埋点,优势是全量获取了商超用户的购物行为,事后根据用途再调取监控视频,缺点是无法获取交易细节,并且冗余了很多用不上的“监控视频”。
三种埋点方式的优劣势总结如下:
根据以上的例子说明,可以想见最高效合理的方案应该是“代码埋点”+“全埋点”/“可视化埋点”,通过全埋点或可视化埋点进行网站整体的流量分析、再通过代码埋点重点分析个别页面的业务细节。
在评估了数据量以及成本等因素之后,我们选择的是在现有代码埋点的基础上再开发一套全埋点,用以支撑运营高频且非固化的埋点需求(例如活动、社区等页面)。
2.2 技术方案选型
技术选型的内容比较细也比较乏味,这里只是简单阐述一下。
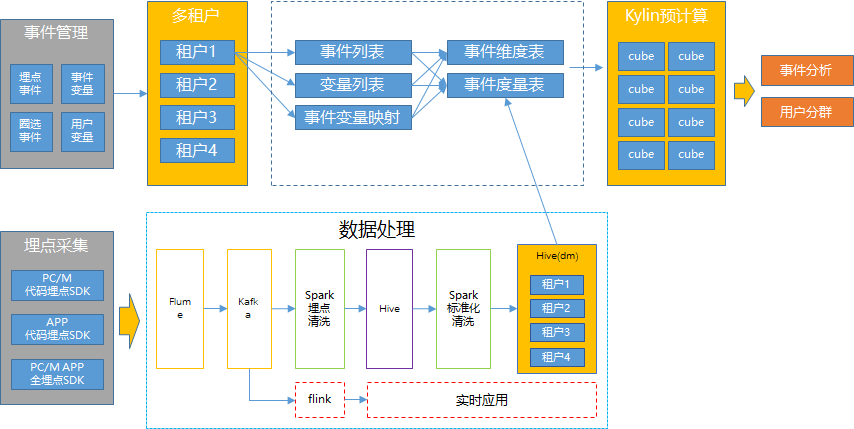
事件分析的方案在我们立项之初讨论了两套,一种是基于全量基础数据的内存计算(选型为presto),这个方案简单粗暴,瓶颈在于服务器内存,同时一旦数据量过大、并发过多,都会造成前端用户体验很差;
另一种是基于kylin的预计算,优点是固化查询维度数量后基于构建后的数据cube查询效率非常快,缺点是存储了大量冗余数据、不支持维度太多的场景。
基于GrowingIO的使用情况调研,我们认为用户的分析维度不会太多,最终选择更加稳定kylin预计算方案,整体技术架构如下:
结语
关于代码埋点、全埋点、数据分析的方案还有很多细节可以展开进行分享,由于篇幅原因这次就先总体介绍一下,下次有机会再将里面的细节展开跟大家做分享,希望大家对于文章内容中存在疑问、错误的地方也予以指正,对看到这里的各位表示由衷感谢。
本文由 @LinKiD 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









Hi LinKiD,我是GIO的产品经理,有兴趣聊一下吗? WeChatID:tanrunyang