
 起点课堂会员权益
起点课堂会员权益推荐系统“体检”:如何评估推荐系统的“健康”状况?
为了自己的健康去体检,推荐系统也有自己的健康指标,不同的业务、不同的场景、不同的阶段都有不同的指标,所以选择好的评估指标以及合适的评估方式,才能让推荐系统更加“健康”。那么,如何评估推荐系统的“健康”状况?

推荐系统从海量数据中挖掘用户喜欢的内容,满足用户的需求。要想做到“千人千面”的同时,又能做到“精准推荐”,一个健康的推荐系统是必不可少的。
就像为了自己的健康去体检,推荐系统也有自己的健康指标,不同的业务、不同的场景、不同的阶段都有不同的指标,所以选择好的评估指标以及合适的评估方式,才能让推荐系统更加“健康”。
推荐系统的常见指标
推荐系统的评价指标,要从解决实际问题的角度来思考,好的推荐系统,不仅要保证自身的“健康”,还要满足服务平台、用户等多方面的需求。
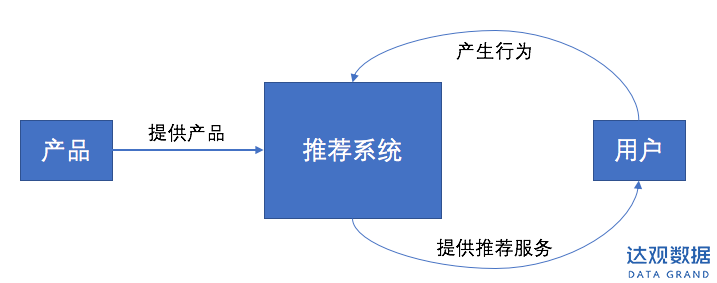
图1:推荐系统基础流程
1. 用户角度
用户最重要的需求是更方便、更快速的发现自己喜欢的产品,为了满足用户的需求,推荐系统可以从以下几个方面评估。
- 准确度:准确度更多的是用户主观感受,评估的是推荐的物品是不是用户喜欢的,比如推荐的视频,用户观看了,推荐的商品,用户加入购物车或者购买了,都可以用来衡量用户的喜好程度。
- 惊喜度:推荐的物品让用户有耳目一下的感觉,可以给用户带来惊喜。比如推荐用户想不起来名字的音乐、电影,或者用户知道功能不知道名字的商品等等,这种推荐和用户的历史兴趣不一定相似,但是用户很满意,超出了用户的预期。
- 新颖性:给用户推荐没有接触过的东西,推荐出的商品不一定是用户喜欢的,但是可以提升用户的探索欲望,从而获取更完整的用户兴趣。
- 多样性:人的兴趣往往是多种多样的,给用户推荐多种类目的物品,可以挖掘用户新的兴趣点,拓宽用户的兴趣范围来提升用户的推荐体验。
2. 平台角度
平台方给用户提供物品或者信息,不同平台获取利润的方式不同,有的通过会员盈利,有的通过商品盈利,大部分的平台都会通过广告赚钱。
所以对于平台方来说商业目标是最重要的目标之一,通常来说有两类值得关注,一个是内容满意度,一个是场景转化率。
1)内容满意度
业务场景不同,内容满意度的指标也随之变化,主要是通过用户对产品的不同行为了来衡量,下图的例子分别说明了不同领域的内容满意度的一些衡量指标。
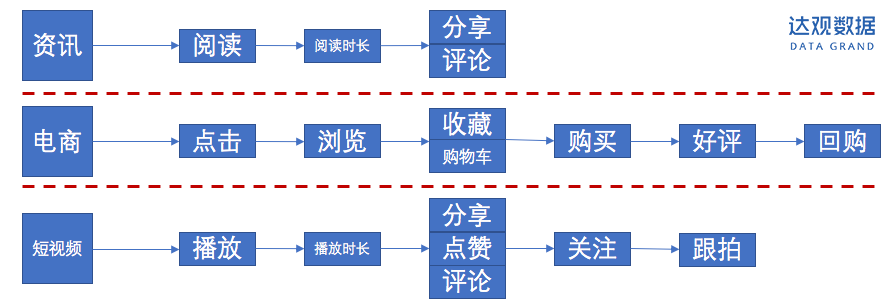
图2:内容满意度评价指标
2)场景转化率
转化率是比较直观的指标,给用户进行推荐,是希望用户对推荐的内容有所行动,比如常见的点击行为、点赞行为等。
- pv点击率(点击量/pv):比较经典的指标,能粗略的衡量转化效果,但是少数用户贡献大量的点击会掩盖这个指标的真实性。
- uv点击率(点击率/uv):与pv点击率相比,该指标不会因为重复浏览某个产品而受影响,能记录用户在一个完整周期的点击效果。
- 曝光点击率(点击量/曝光次数):比较适合信息流这种支持上拉/下拉翻页的产品,曝光次数随着用户刷屏次数增加而变大,能更真实的记录每一屏的转化情况。
- uv转化率(转化次数/点击量):衡量用户的转化情况,能把多大比例的用户从一个场景转化到另一个场景去。比如视频App首页,一般用户在点击某个视频后,会进入详情页继续操作,而不是返回首页,用uv转化率更加合理。
- 人均点击次数(点击量/点击uv数):每个用户点击的次数,与uv转换率相辅相承,可以评价用户的深度,uv转化率评价用户的宽度。
*注:pv:访问页面的次数;uv:访问页面的人数。
推荐系统的离线评估
推荐系统的评价指标除了上面提到的用户角度和平台角度之外,还有推荐系统自身的评估。
推荐系统从接收数据到产生推荐结果,再根绝推荐结果的影响重新修正自身。所以本质上是一个闭环系统,在这个闭环中,离线部分的工作主要是通过学习训练以及其他策略规则进行召回,主要的以下的评估指标。

图3:推荐系统评价阶段
1. 准确度
准确度的评估主要是评估推荐算法模型的好坏,为选择合适的模型提供决策支持。
推荐系统也像其他机器学习一样,把数据划分为训练集和测试集,使用训练集学习训练模型,通过测试集来衡量误差以及评估准确度。根据推荐系统的目的不同,准确度的衡量也有不同的指标。
分类问题:比如点击、不点击或者喜欢、不喜欢就可以看成分类问题,分类问题的指标主要是精确度(Precision)和召回率(Recall),精确度描述的是推荐结果有多少是用户喜欢的。
而召回率描述的是用户喜欢的产品,有多少是推荐系统推荐的。当然,我们希望这两个指标都越大越好。但是实际情况,都需要平衡这两个指标的关系,所以常用的F-指标就是一种常用的平衡二者关系的计算方式。
评分预测:对产品进行评分,比如电影评分,常用的准确度指标主要有均方根误差(RMSE)、MAE(平均绝对误差),二者之间主要是计算方式的差别,都是描述算法的预测评分和产品真实评分之间的差距。
排序问题:分类和评分预测问题,只是把可以推荐的产品筛选出来,但是并不包含展示给用户的顺序,我们当然希望把用户最可能“消费”的产品放在前面,这就需要排序指标。
其中最常见的离线指标是AUC,简单的说,AUC代表的是随机挑选一个正样本和一个负样本,正样本排在负样本前边的概率。所以当算法能更好的把正样本排在前边的时候,就是一个好的算法模型。
其他常见的算法指标,比如MAP,描述的是推荐列表中,和用户相关的产品在推荐列表中的位置得分,越靠前得分越大,MRR是按照相关产品的排名的倒数作为准确度,NDGG描述的是推荐列表中每一个产品的评分值的累加。同时考虑每个产品的位置,最后进行归一化,在同一标准上评价不同的推荐列表。
2. 覆盖率
覆盖率描述的是推荐出的产品占总产品的比例,除了产品之外,类目、标签也可以用覆盖率来评价。
3. 多样性
用户的兴趣不是一成不变的,而且有些产品的用户不止一个,同一用户的兴趣也会受到时间段、心情、节日等多种音速的影响。所以推荐时要尽量推荐多样的产品。在具体的多样性评价上,可以通过对产品聚类,在推荐列表中插入不同类别的产品来提高多样性。
4. 时效性
不同产品的时效性是不同的,比如电商类需要的时效性不是很高,但是新闻、资讯、短视频这类产品,就需要很高的时效性。所以针对不同产品甚至产品下不同的类目,设置不同的时效性,也是提高推荐质量的途径之一。
推荐系统的在线评估
在线评估大致可以分为两个阶段:一个是用户触发推荐服务;另一个是用户产生行为这两个阶段。
1. 触发推荐服务
- 稳定性:系统的稳定性对于用户的体验至关重要,怎样能针对不同的场景持续稳定的提供推荐服务,是推荐系统最重要的指标之一,提高推荐效果,也要在保证系统稳定性的前提下去进行优化。
- 高并发:当某个时间点有大量用户访问,或者用户规模很大时,推荐系统能否扛住高并发的压力也是一个很大的挑战。所以设计一个高并发的系统,了解不同接口的高并发能力,做好充分的压力测试,也是推荐系统能否稳定提供服务的重要内容。
- 响应时间:响应时间衡量用户是否能够及时得到推荐反馈,响应时间会受到多种因素的影响,比如网络情况、服务器、数据库等,可以通过监控请求的时长,做好超时报警。同时在生产推荐结果时优化计算方式、简化生产过程,尽可能的规避响应时间带来的影响。
2. 产生行为
这一阶段主要是用过用户产生行为,通过收据分析用户的行为日志进行相关指标的评价。这一阶段更多的是考虑平台角度,从商业化指标以及用户行为指标等方面进行评价。
比如转化率、购买率、点击率等都是常见的行为指标,一般用户行为符合漏斗模型(例如,推荐曝光-点击-阅读-分享),通过漏斗模型可以直观的描述不同阶段之间的转化,提升用户在不同阶段之间的转化。
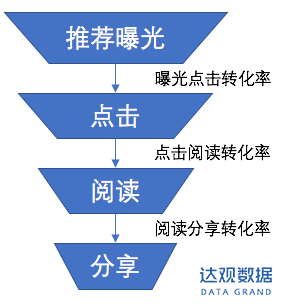
图4:用户行为漏斗模型
AB测试
在线评估通常会结合AB测试,当有新的算法或者策略上线时,通过AB测试,在同一指标下,对比新旧算法的差异,只有当新算法有明显优势时,才会取代旧的算法。
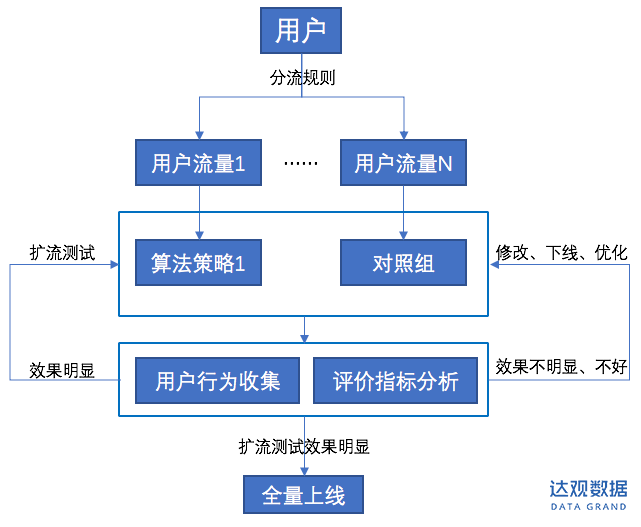
图5:AB测试流程
1. 什么是AB测试
AB测试的本质是对照试验,其来源于生物医学的双盲测试,通过给两组病人不同的药物,来确定药物是否有效。
在推荐系统中,AB测试也采用了类似的概念:将不同的算或者策略,在同一时间维度,分别在两组或者多组组成成分相同的用户群体内进行线上测试,分析各组的用户行为指标,得到可以真正全流量上线的算法或者策略。
2. AB测试的常见做法
AB测试应该怎样进行呢?其中最重要的是“控制变量”、“分流测试”和“规则统一”。
控制变量:AB测试必须是单变量的,变量太多,变量之间会产生干扰,很难找出各个变量对结果的影响程度。在推荐系统中,AB测试的唯一变量就是推荐算法或者策略。
分流测试:AB测试作为对照试验,自然有实验组和对照组。通常状况下会对用户进行分流,很多用户都会访问同一个app或者web多次。所以根据用户进行分流是一个很好的方案,在对用户进行分流时,可以通过用户ID,设备号或者浏览器cookie。
对于未登录用户来说,跨设备访问app或者web,就会产生不同的标识。所以对于未登录用户,最好能保持实验组和对照组有相同的比例。
不同的用户在一次浏览过程中,体验的应该是一个方案,同时需要注意不同流量之间的人数,大多数情况希望所有用户平均分配。
规则统一:在控制变量和分流测试的前提下,针对不同的流量,应该制定相同的评价指标,才能得到准确的对比效果。
本文由 @达观数据 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









发现个错别字…
审核编辑的鸡腿没了