
 起点课堂会员权益
起点课堂会员权益经验分享:资深架构师教你什么是网络应用架构?
导读:本文作者基于其公司 (StoryBlock) 的实际业务架构向我们分享了一节生动详细的网络架构入门课,虽然作者的预期阅读对象是前端开发人员,但是也非常适合产品经理阅读和学习,尤其是已经有一定工作经验的产品经理,希望对大家有用。

01 从一个场景开始
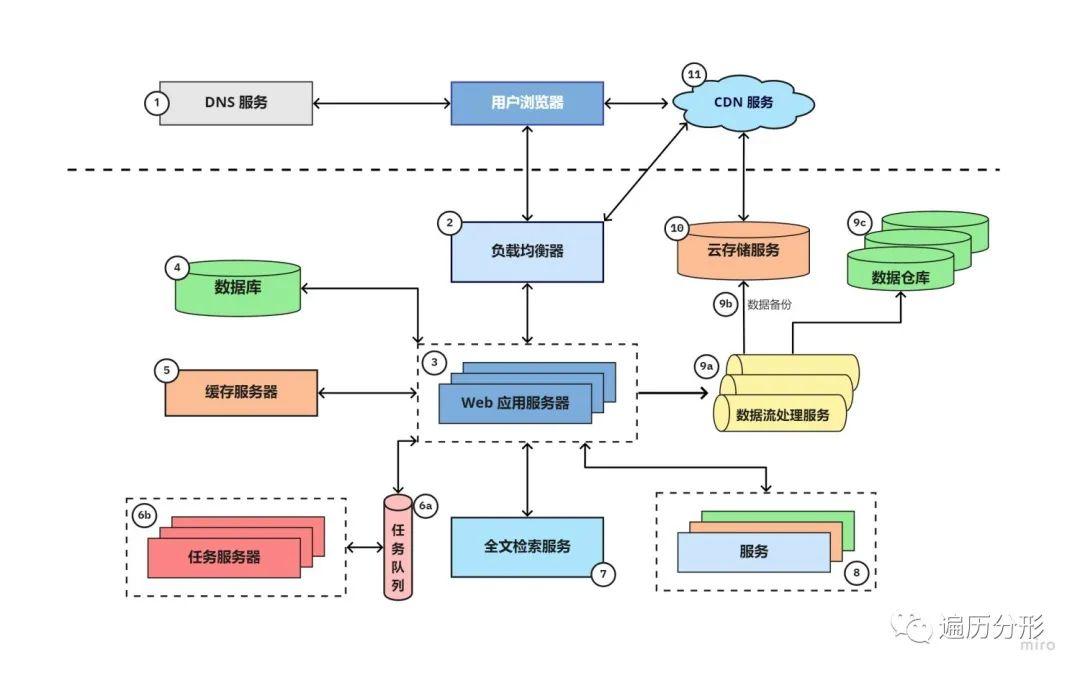
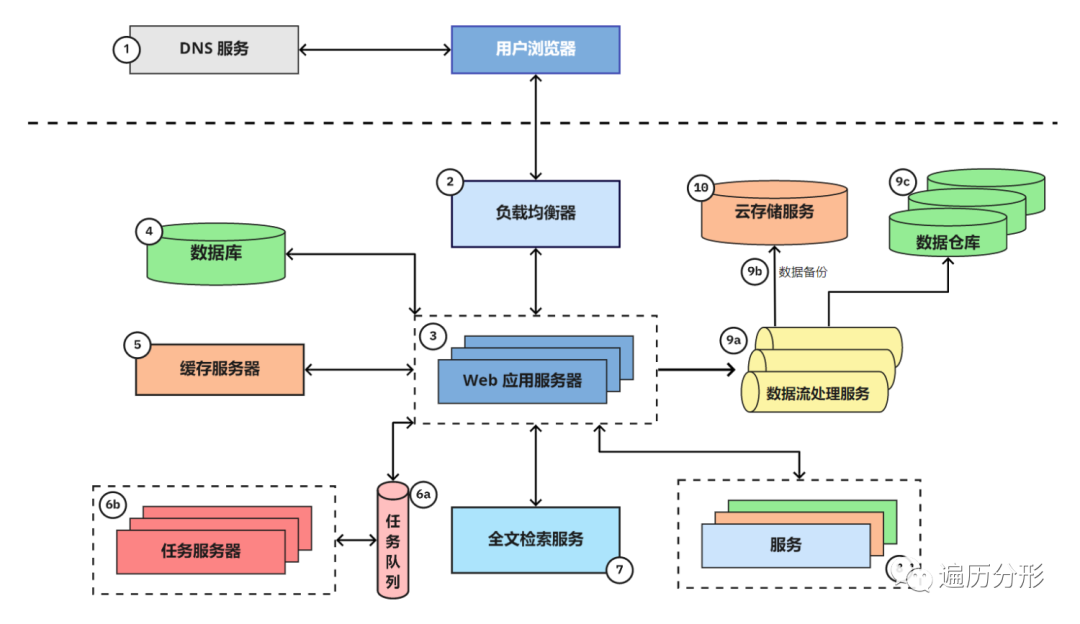
以上的架构图是对 Storyblocks 业务架构的一个很好的概括。对于那些相对缺乏经验的 web 开发者,或许你会觉得这个架构有些复杂。没关系,在讲解相关组件的具体业务细节之前,我们先举个例子,帮你更容易地理解 Storyblocks 的业务架构。
先从一个场景开始:用户用谷歌搜索 「美丽的浓雾和林间的阳光」 。首个结果正好出自 Storyblocks:一个知名的图片和矢量图资源网站,用户点击该条结果,浏览器重定向到该图片的所在的详情页面。
这个场景背后,用户浏览器向 DNS 服务器发送请求,查询 Storyblocks 的域名信息,然后发送访问请求。访问请求首先经过负载均衡器,负载均衡器会从十多台运行网站服务的网络服务器选择任意一台,将请求发送到这台服务器进行处理,网络服务器先从缓存服务器查询图片的详情信息,然后从数据库获取图片的其他相关信息。
我们注意到这张图片的色彩配置信息还没被计算出来,于是服务器将一个新的色彩配置任务推送到任务队列,我们的任务队列服务器将异步地处理图片的色彩配置信息计算,一旦计算完成,便将配置信息更新到数据库中。
下一步,服务器将图片标题作为关键词,向全文检索服务发送查询请求以寻找相似图片。此时用户登入他的 Storyblocks 账户,相应地,服务器从账户服务中获取用户账户信息。
接下来,我们将这个页面浏览事件加载到 data firehose(AWS 推出的流数据装载服务) 以记录到云存储系统,并最终存储到数据仓库,便于分析师分析使用并帮助解答业务问题。
服务端将视图呈现为为 HTML 页面并经由负载均衡器,返回用户的浏览器客户端。这个页面同时包含存储在云存储系统的 Javascript 和 CSS 代码文件,云服务器直接连接到 CDN 集群,内容也经由 CDN 分发,用户浏览器访问 CDN 集群并获取内容。
最终,浏览器渲染页面使用户可以浏览阅读。
接下来,我将带你遍历每个组件,并做简要说明和介绍,帮助你形成一个相对准确的概念模型,以便于理解网络架构和组件间的交互。我仍将遵循已经分享的文章中给出的一些实践建议,这些建议基于我在 Stroyblocks 的业务经验,具有一定参考价值。
02 网络架构诸组件
1. DNS 服务

DNS (Domain Name System)代表 「域名系统」,这是实现互联网相互连接的核心技术。DNS提供从域名 (例如 google.com) 到 IP 地址 (85.129.83.120) 的最底层的键值对查询服务,事实上,计算机基于网站的 IP 地址路由到合适的服务器。用电话号码比喻的话:域名和 IP 地址的关系,类似于联系人姓名和号码的关系。
正如你需要通过电话簿来查询特定联系人的电话号码,你同样需要通过 DNS 来查询指定域名的 IP 地址,所以你完全可以把 DNS 理解为互联网的电话号码簿。
我们以后会深入介绍关于 DNS 的详细原理,现在进入下一个话题。
2. 负载均衡

在深入介绍负载均衡之前,我们需要先行解释应用架构的水平拓展和垂直拓展。
你肯定会好奇这两个概念的含义和区别:简单来说,水平拓展是指你向资源池增加更多机器设备,而垂直拓展则意味着增加更多算力资源(CPU,内存)到现有机器设备。对于 Web 开发,水平拓展常常是最好的选择。
毕竟,所有事物都可能中断,服务器有时崩溃,网络会降速,甚至整个数据中心也会偶尔断线。如果要防止出错,除了保持简单,我们别无选择。使用服务器集群可以帮你有效应对突发情况,增强业务的健壮性和容错性,确保应用持续稳定地运行。
其次,水平拓展允许你将后端服务 (网络服务器,数据库,应用服务) 的不同组件分配在不同服务器,借此你可以高效地调用后端服务的不同组件。
最后,垂直拓展很容易遇到规模瓶颈,谷歌的搜索服务平台是一个相当典型的案例,这个场景也同时适用于 Storyblocks 这样的中小型公司,举例来说,我们在任意时刻都运行着 150 到 400 个 AWS EC2 实例,如果要通过垂直拓展模式提供同等算力,很难想象我们需要使用何种级别和规模的计算机设备(估计得使用超算了)。
现在我们回到负载均衡器,它们是实现业务水平拓展的重要部分,它们将接收的访问请求路由到互为备份的应用服务器集群中的任意一个,并将应用服务器的响应返回到客户端。任何一个应用服务器的处理方式都完全相同,通过这种方式,负载均衡器将访问请求均匀地分派到不同的服务器以防止服务器过载。
负载均衡器的业务原理相当简单,但是要深入理解,就涉及到很多复杂的概念,这些更加复杂的概念,我们将在以后进行讲解。
3. Web 应用服务器
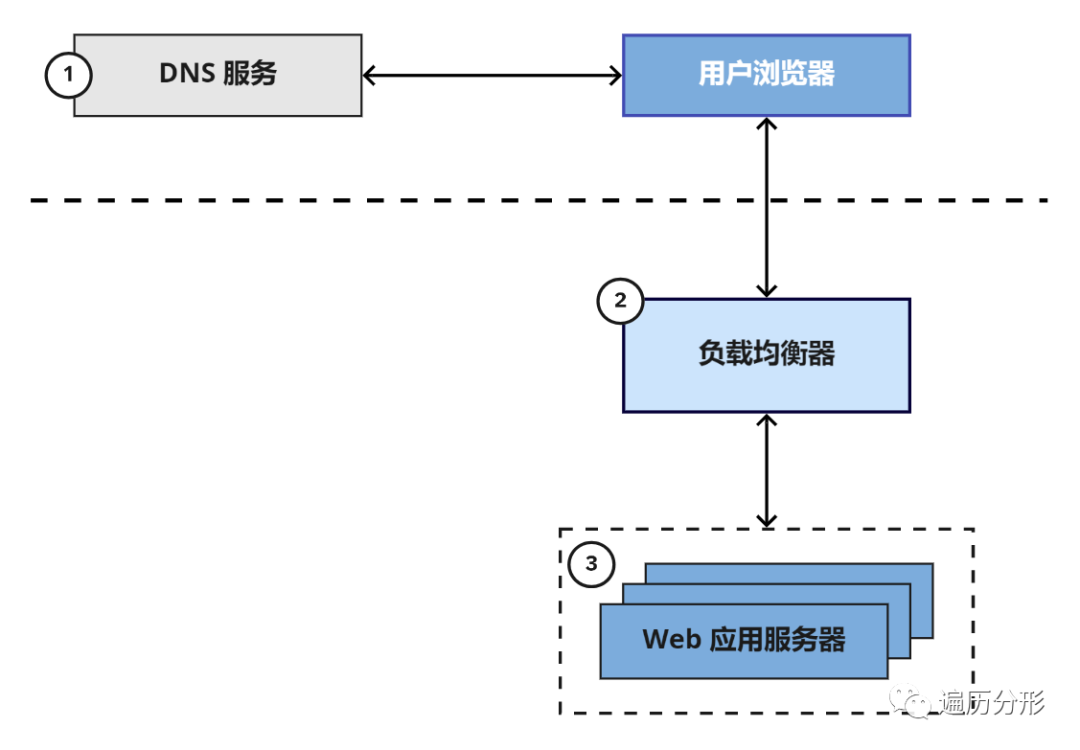
从抽象角度来说,Web 应用服务器的作用是这样的:它们被用来执行诸如处理用户请求和将 HTML 返回用户浏览器等核心业务逻辑。为了确保任务完成,应用服务器通常会和数据库,缓存层,任务队列,搜索服务,其他微服务组件,数据/日志队列等一系列后端基础设施交互。
正如上文所提及,很多时候,由于负载均衡器的存在,应用服务器需要成倍地连接更多服务,以便于处理大规模的用户访问请求。
应用服务的技术实现首先基于特定后端语言,如 Node.js, Ruby, Scala, Java, C#, .NET 等等,同时需要选择基于该后端语言的 Web MVC 框架,如 Express 之于 Node.js, Ruby on Rails, Play 之于 Scala, Laravel 之于 PHP 等等。本文仅做基本介绍,不会过于深入介绍这些语言和框架的具体实现细节。
4. 数据库服务器
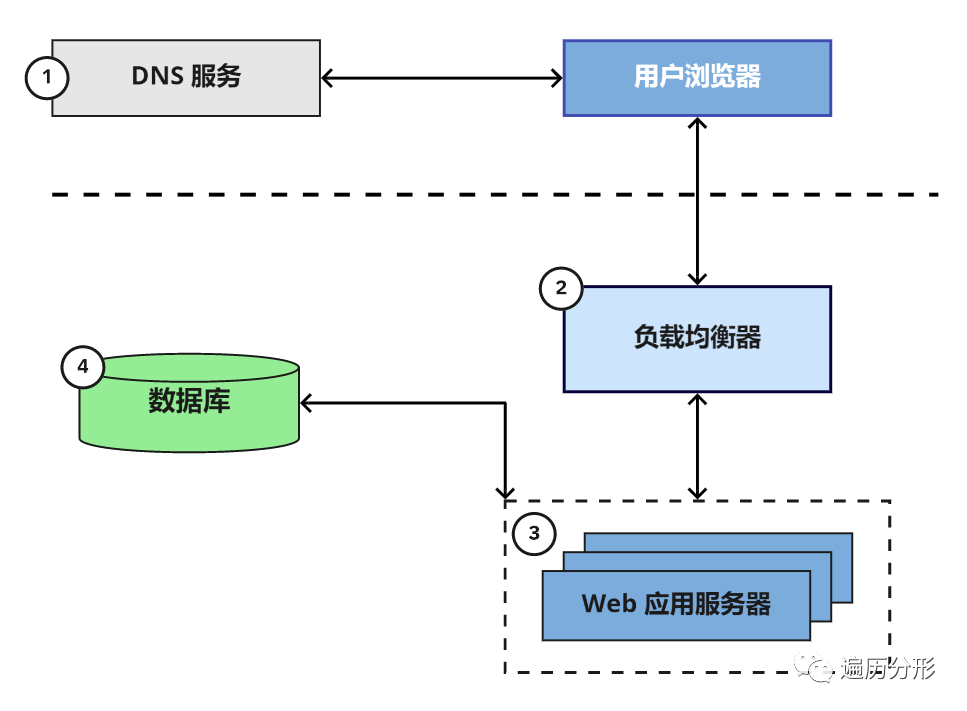
任何一个现代的 Web 应用都使用一个或以上的数据库存储信息。数据库帮助我们完成诸如定义数据结构,插入数据,查找数据,更新和删除数据,以及执行数据计算等各种数据库操作。
在大多数情况下,Web 应用服务器和专有的数据库服务器直接通信,对于任务服务器也是如此。另外,任何一个后端服务都可能拥有一个独立于其他应用的专有服务器。
尽管我在试图避免在每个组件上过于深入细节,但是如果我不详细解释数据库的一些基础概念,(SQL 和 NoSQL),必将会影响你理解接下来的其他概念。
SQL(Structured Query Language, SQL),代表 「结构化查询语言」。被发明于上世纪七十年代,作为标准的关系数据库数据查询方式,最终被广泛接受和使用。SQL 数据库将数据存储在数据表中,通过 ID 等字段进行表关联。
举一个简单的存储用户历史地址信息的的例子简要说明:现有两个表:【用户表: users】和【用户地址表: user_addresses】,这两张表通过用户编号相关互联,如下图所示。这些表相互关联,是因为【用户地址表】的 {用户编号: id} 信息是用户表中 {用户编号: id} 在用户地址表的外键 (Foreign Key, FK)。
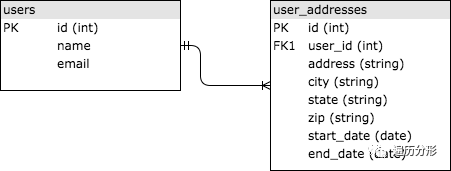
如果你对 SQL 不太了解,我强烈建议你学习这个基础教程,可汗学院的 SQL 入门课:数据查询与数据管理 ,SQL 在 Web 开发领域应用相当广泛,你至少需要了解基础知识,这样才能恰当地设计应用架构。
NoSQL 代表 Non-SQL 或 Not-Only-SQL,是指新一代的数据库技术,用于处理大型网络应用所产生的巨量数据(大多数关系型数据库无法很好地水平拓展,只能垂直拓展,直到性能瓶颈)。如果你对 NoSQL 一无所知,我建议你从以下介绍入手:
- https://www.w3resource.com/mongodb/nosql.php
- http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
- https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-nosql
值得注意的是,基于 SQL 查询已经成为数据库的通行接口标准,即使对于 NoSQL 数据库也是如此。所以如果你对 SQL 缺乏了解,很有必要认真学习一番,在互联网行业,SQL 是无可避免的。
5. 缓存服务

缓存服务为相关信息提供简单的键值数据存储,可在接近 O(1) 时间内保存和查找信息。
O(1) 是指算法的时间复杂度为常数阶,换言之,此场景下,任何单次查询的时间都是相对稳定的,和该条查询指令复杂度基本无关。
应用服务同样会利用缓存服务预先存储一些计算量较大的计算结果,以便于下次需要时直接从缓存中获取结果而重新计算。应用服务也可能从其他服务获取缓存,如数据库查询结果,外部服务调用结果,指定URL 的 HTML 文件,以及其他服务。下面是真实世界的一些案例:
- 谷歌直接缓存常见的搜索关键词如「狗」或者「泰勒·斯威夫特」的搜索结果,而非搜索时重新计算。
- Facebook 缓存你登入账户时所看到的信息,如你的发帖记录信息和朋友列表信息等数据。这篇文章详细介绍了 Facebook 的缓存技术应用。
- Storyblocks 缓存服务端的 React 渲染生成的HTML 文件,搜索结果和提前输入结果等信息
使用最广泛的两种缓存服务器技术是 Redis 和 Memcache,后续也会针对这两种技术进行介绍。
6. 任务队列和服务器
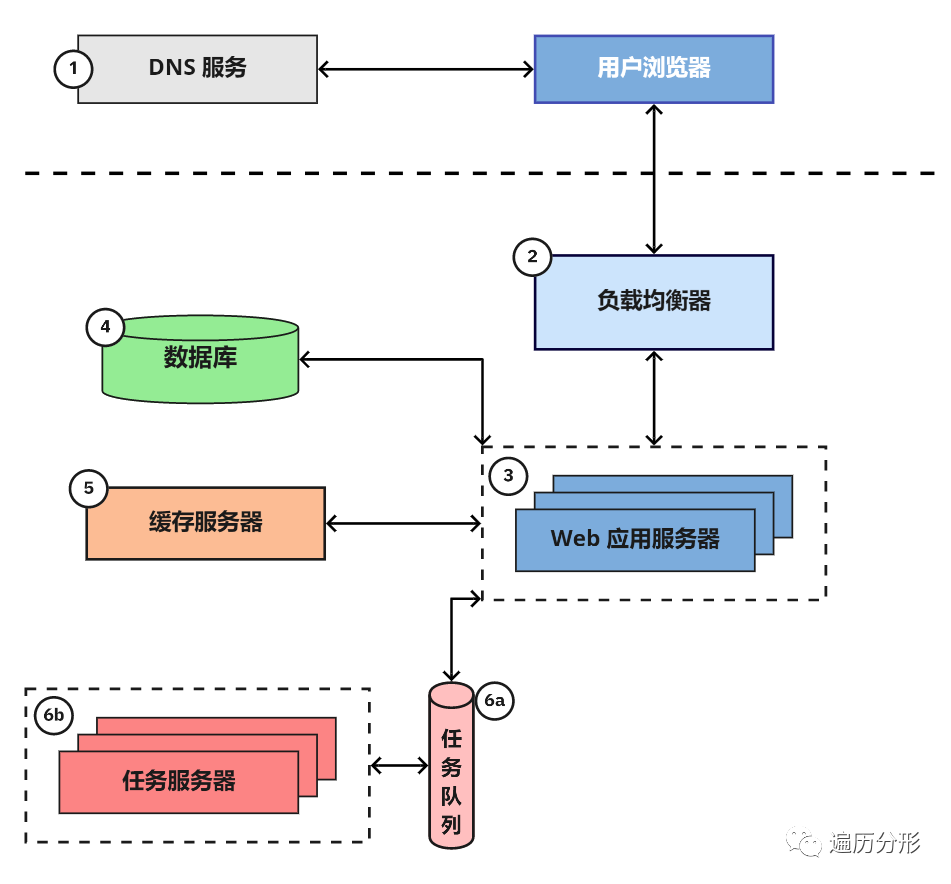
在不涉及于用户交互的场景中,网络应用需要异步地完成很多工作。例如,为了搜索查询结果,谷歌需要用爬虫遍历全网的内容并编制索引,谷歌不是在用户搜索时才进行上述操作,相反,它异步地爬取网络内容,并预先更新查询索引。
尽管有很多应用架构可用于完成异步任务,但最通用的是「任务队列架构 (Job Quene)」。它包括两个组件:一系列等待被执行的「任务」和数个用于执行任务的任务服务器(通常被称为 Workers )
任务队列存储一系列需要被异步执行的任务。先进先出(First In First Out, FIFO)队列是最简单的任务队列,尽管多数应用最终需要可以按照优先级排序的队列系统。不管是由日常任务调度安排或是由用户操作触发,一旦应用服务需要执行任务,它都会将合适的任务添加到队列中。
例如,Storyblocks,将任务队列用于强化那些用于支持市场的幕后工作:例如视频和图片的编码,包含元数据标签的 CSV 的处理,用户统计数据的聚合,密码重置邮件的发送等任务。起初我们使用简单的 FIFO 队列,但最终我们还是升级为优先级列队以确保那些时间敏感的任务可以迅速完成(如密码重置邮件的发送)
任务服务器的任务处理流程为:任务服务器轮询任务队列以确定是否有任务需要执行,如有则推出(pop)该任务并加以执行。相关的编程语言和服务框架数不胜数,这里就不作过多展开。
7. 全文检索服务
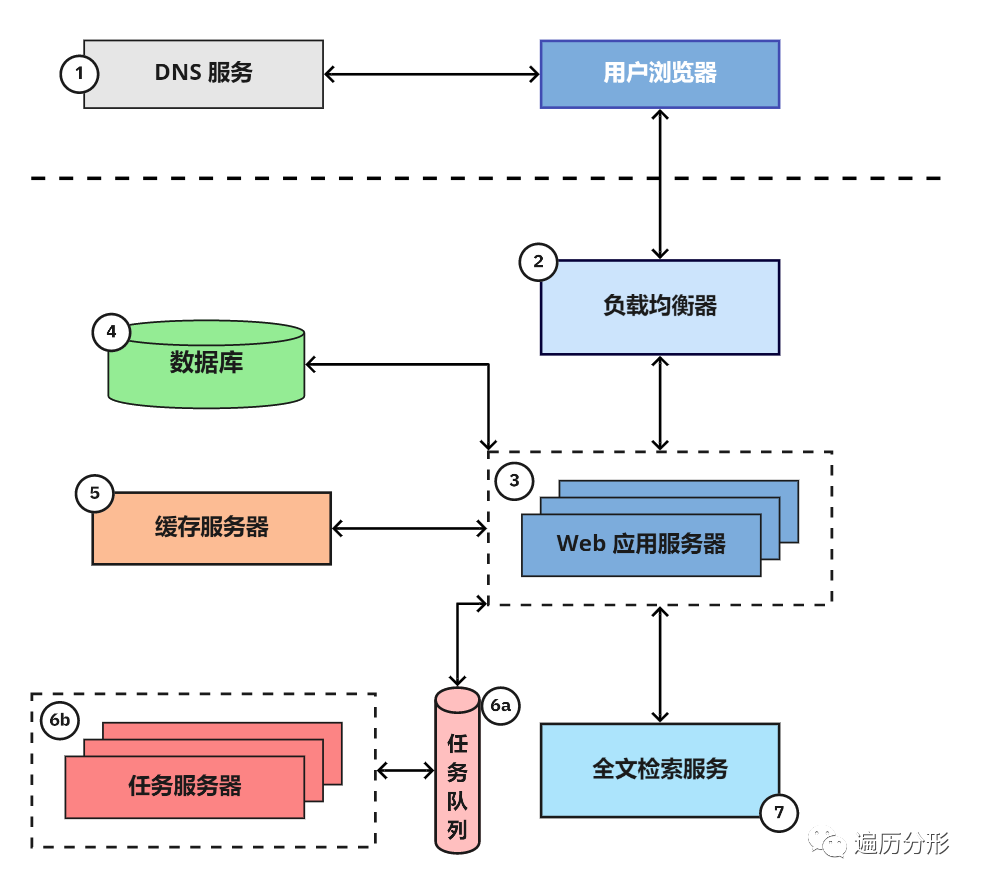
当用户输入文字进行查询时,多数网络应用都或多或少地提供检索功能,应用服务返回最相关的查询结果。这种用于支持文本查询的功能,通常被称为「全文检索」,全文检索使用反向索引以便快速查询包含关键词的文件信息。

上图说明如何将这三个文档标题转换为反向索引,以便于从特定关键字快速查找到标题中具有该关键字的文档。请注意,如 “in”,”with” 等常见单词,通常不包括在倒置索引中的常见单词(被称为停止词: stop words)
尽管有些数据库直接提供全文检索特性(例如,MySQL 支持全文搜索)但将一般将计算生成并存储反向索引的「检索服务」作为独立服务并提供查询接口。现在最流行的全文检索平台是 Elasticsearch,同时 Sphinx 和 Apache Solr 也是常见的备用选择。
8. 服务
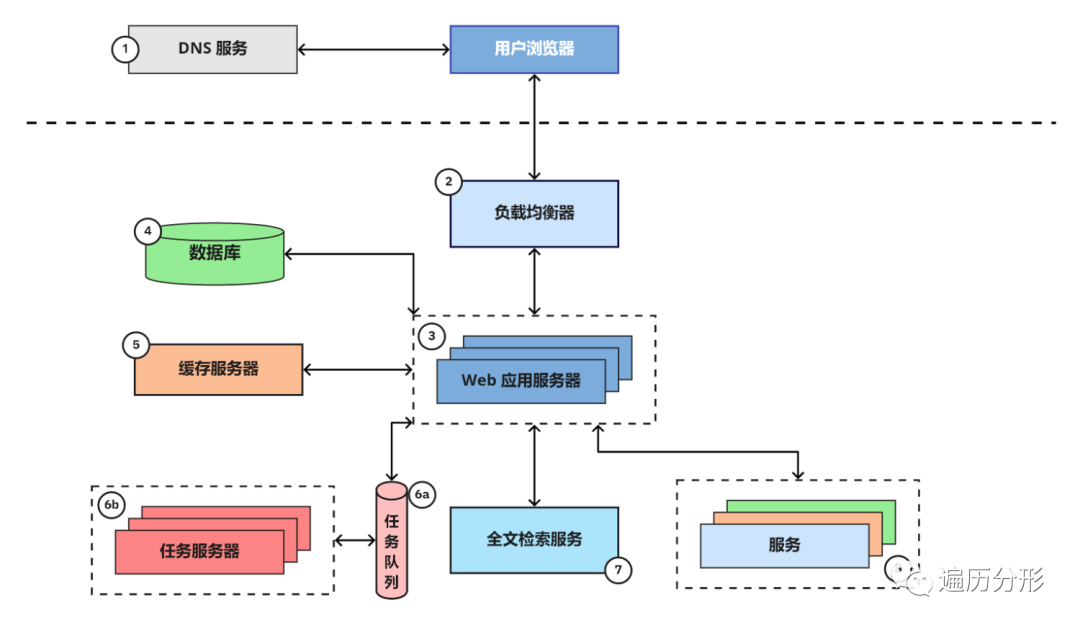
当应用达到一定规模,其中有些服务需要拆分出来成为单独的应用。这些新应用不一定用于开放给外部系统,但是一定会用于和原应用以及其他服务交互。举例来说,Storyblocks 有以下几种操作和计划服务:
- 账户服务:存储用户在我们所有站点的相关数据,这将有助于我们提供交叉销售的机会并创造统一的用户体验
- 内容服务:存储所有视频、音频和图形内容的元数据,同时为内容下载和查看下载历史记录提供接口
- 支付服务:为处理客户信用卡结算信息提供接口
- HTML → PDF 服务: 提供简单的处理接口,以支持根据 HTML 页面返回相应 PDF 文件
9. 数据处理
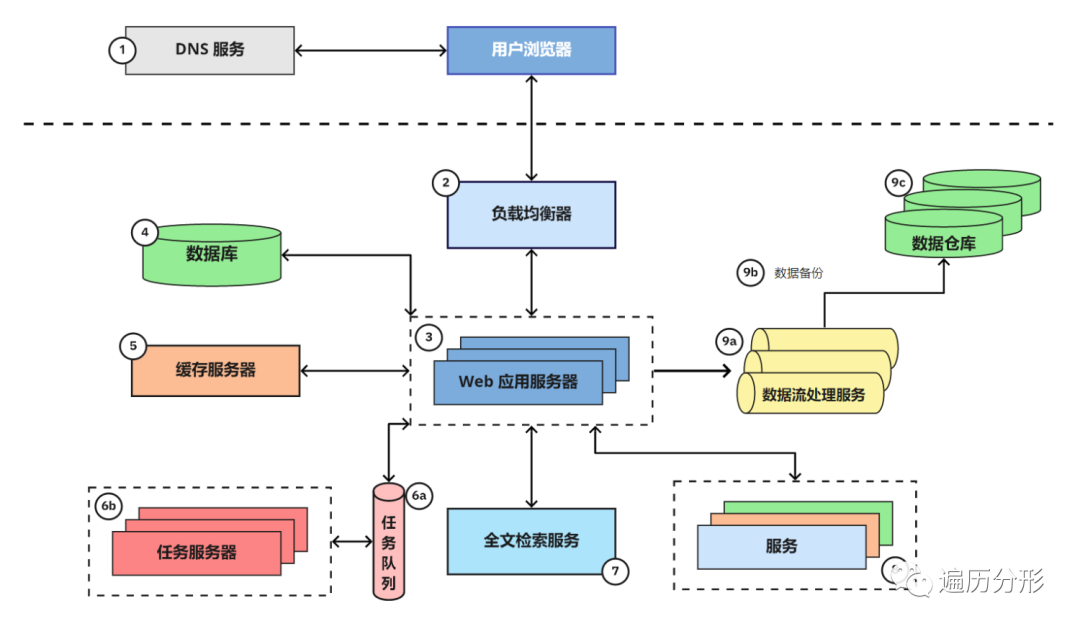
大数据时代,公司的生死存亡系于对数据的完善利用程度。现在的网络应用,只要达到一定业务规模,就一定会建立数据管道以确保数据的收集、存储和分析。典型的数据管道包括以下三个主要过程:
- 数据流处理:应用发送数据,特别是关于用户行为的事件信息,到 data firehose,后者提供了流处理接口以摄取和处理数据。通常来说,源数据会经过转换或处理并发送到另外的 firehose。AWS Kinesis 和 Kafka 是用于此目的的两种最常见的技术
- 数据云存储:源数据以及经过转换或处理的新数据将被存储到云存储系统。AWS Kinesis 提供了一种名为 “firehose” 的设置,它帮助我们轻松地配置将源数据存储到云存储 (AWS S3) 的整个过程
- 同步到数据仓库:经过转换或处理的新数据常常被装载到数据仓库以便于分析。我们也使用 AWS Redshift,它在创业公司中相当普遍且份额正逐渐扩大。尽管大公司通常使用 Oracle 或其他专有的数据仓库技术。如果数据集足够庞大,对于分析而言,类 Hadoop 的 NoSQL MapReduce 技术将是必要的。
应用架构图中未提及的一个环节是:将数据从网络应用和服务的生产数据库装载到数据仓库。比如在 Storyblocks 我们每天装载视频块,音频块,故事块(VideoBlocks, AudioBlocks, Storyblocks)和账户服务以及参与者门户数据库到 RedShift。由此通过整合核心业务数据和用户行为事件数据,为数据分析师提供完整的数据集。
10. 云存储
按照 AWS 的说法,「云存储是一种存储、访问和分享数据的方便且可拓展的方式」
和本地文件系统的现有方式一样,你可以使用云存储来存储和访问任何文件,其好处是能够调用 RESTful API 通HTTP 交互。到目前为止,亚马逊 S3 是市场上最受欢迎的云存储服务(国内则是阿里云),也被 Storyblocks 用于存储视频、图片和音频资源,还有 CSS 和 Javascript 代码,以及用户事件数据等信息。
11.CDN

CDN(Content Delivery Network)代表「内容分发网络」,该技术提供了一种快速加载 HTML、CSS、JavaScript 文件和图片等网页资源的方式,这比从原服务器直接请求要要快得多。
CDN 基于遍布世界各地的「边缘服务器 (Edge Server)」分发内容,这样用户可以从边缘服务器加载网页资源,而不用访问原服务器加载。如下图所示:身在西班牙的用户请求原站点位于美国纽约的网页,但是静态网络资源却经由CDN 网络中位于英国的边缘服务器获取,而非通过缓慢且不安全的跨洋 HTTP 请求。
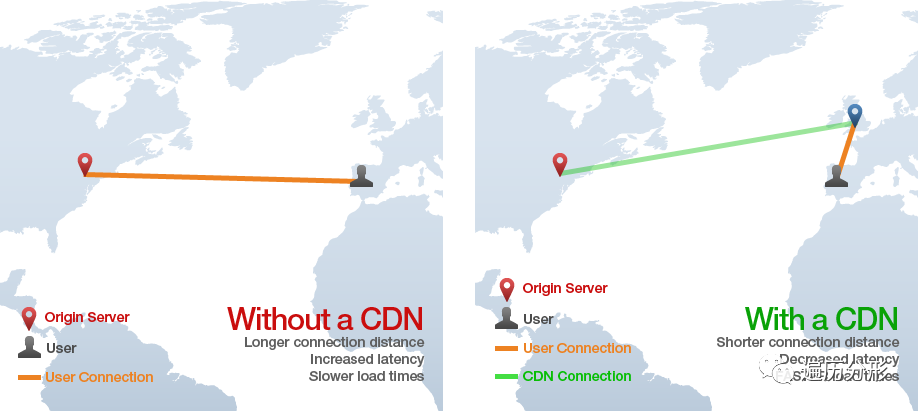
想要了解更详尽的介绍,可以查看本文。通常来说,Web 应用应始终使用 CDN 为 CSS、Javascript、图像、视频和任何其他网络资源提供服务。某些应用还会使用 CDN 来分发静态 HTML 页面。
写在最后
文章作者基于其公司 (StoryBlock) 的实际业务架构向我们分享了一节生动详细的网络架构入门课,虽然作者的预期阅读对象是前端开发人员,但是也非常适合产品经理阅读和学习,尤其是已经有一定工作经验的产品经理。
毕竟,我们所设计的产品最终通过互联网分发给全国和世界各地的用户,我们对于互联网通信过程了解越深入,就越有可能发现产品所可能存在的缺陷和问题,也就越有可能做出真正优秀的产品。
希望各位读者能够有所收获,我也将陆续创作和翻译其他相关产品和技术的内容和分享。
原文地址: web-architecture-101
本文由 @遍历分形 翻译发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。






- 目前还没评论,等你发挥!


