
 起点课堂会员权益
起点课堂会员权益数据产品设计:利用基尼系数实现数据波动的自动归因分析
编辑导语:当你在进行一项产品设计时,数据突然产生波动了,你会怎么做?作者分享了自己是如何利用基尼系数进行数据波动自动归因分析的方法,我们一起来看下吧。

日常工作中,数据同学经常会被老板或业务问到“昨日XX指标波动50%,帮忙看下什么原因?”,也有上来直接来一句“今天数据是不是有问题啊?”,数据同学心里一惊,“我X,是不是集群延迟了?难道昨天修改逻辑,改出Bug了吗?”
于是先去找到指标对应的数据任务,排查数据加工流程有无异常,检查了一遍任务运行正常,各个环节数据无误,松了一口气。
开始分析波动原因,经过多个维度的拆解分析后,发现南京下降影响最大,结合最新公布的疫情信息,回复老板/业务说,“昨日数据波动的主要原因是XXX,指标总体下降XX,其中南京下降XX,影响率XX”。一轮操作后,一上午过去了,既定的排期任务又要晚上加班搬砖了。
一、数据波动产生的原因
业务数据不可能一成不变,尤其是互联网业务发展迅速,业务指标也会不断变化。数据的波动主要体现和对比日期(同比、环比等)出现上升或下降。
DAU、订单数、营收等经营业绩性指标重点关注下降,而退订率、投诉率等服务性指标重点关注上升。当用户反馈数据波动问题时,可以从以下几个方面排查分析:
- 首先确认数据质量问题,数据在加工过程,由于源头数据异常、任务依赖延迟(集群资源不足)、开发Bug等原因,导致的数据重复、延迟、异常值脏数据等,影响数据结果。
- 周期性波动,对于有周期属性的业务,OTA旅游产品,景区门票周末、暑期、节假日是出行旺季,这些时段各项业务指标会较其他时段有明细的增幅。外卖业务,在母亲节、情人节等节日,鲜花品类会暴涨。
- 市场环境影响,如突发政治政策,用户信息安全监控政策出台后,一些赴美上市的出行、招聘等企业新用户停止注册,业务会出现大幅波动。
- 自然环境,如天气,外卖业务白领区域来说,工作日遇到雨雪天气,出门吃饭的人会大大减少,外卖订单激增。
- 业务动作,如新版本发布、新的营销活动上线等,五一期间,各家OTA公司上线机票盲盒活动,一时成为后疫情时代的爆款产品,带来增量流量的提升。
- 竞对出现,互联网业务新入局者往往会在营销、补贴等方面投入更多的资源,以跑马圈地获取用户,对于忠诚度不高的趋利型用户,会被直接转移,百度、美团、饿了么外卖市场三足鼎立时,很多人同时装三个App,哪个补贴多用哪个。
- 业务变化,产品调整带来的统计逻辑的变更,例如App新版本上线后,流量入口的统计埋点方式发生的变化,业务产品未及时通知数据团队,统计逻辑变更不及时,导致数据波动。
二、什么样的数据波动才是异常?
异常的判断需要结合业务的属性、发展阶段、指标特征、对比的周期综合确定评价标准。首先是指标评价的依据,即凭什么说指标波动了,和历史同期比通常的方式是对比分析(上一篇文章有详细的同比、环比计算逻辑和常用场景)。
对于波动范围,同是DAU指标,百万级公司可能下降30%定为异常,而对于千万级、亿级的企业可能下降5%就需要分析下原因了。
因此,在数据产品设计时,需要对业务需求进行调研分析,确定指标异常的判断标准。
三、数据产品异常归因分析设计思路
1. 数据质量保证
数据波动时,很多业务第一反应是“数据准不准”,尤其是当数据质量问题比较频繁时,会降低业务对数据产品的信任度。
数据质量可以说是数据产品的生命线,没数据时,业务可以基于经验等多方考虑去决策,但如果数据质量有问题给业务带来错误的决策引导,那就是好心办坏事了。
因此,数据产品设计要考虑数据质量的把控,可以通过数据质量监控报警日报每日巡检指标涉及的任务运行情况、数据生产链路的表的质量情况(一致性、及时性、准确性、完整性监控),当监控体系覆盖健全后,业务来质问数据问题时,就可以有底气问业务上是否有什么动作。
当监控发现数据质量异常时,数据人员第一时间进行问题排查和恢复处理,并且产品端通过调用质量监控结果的接口数据,进行异常提醒,降低错误数据对业务决策的负面影响。
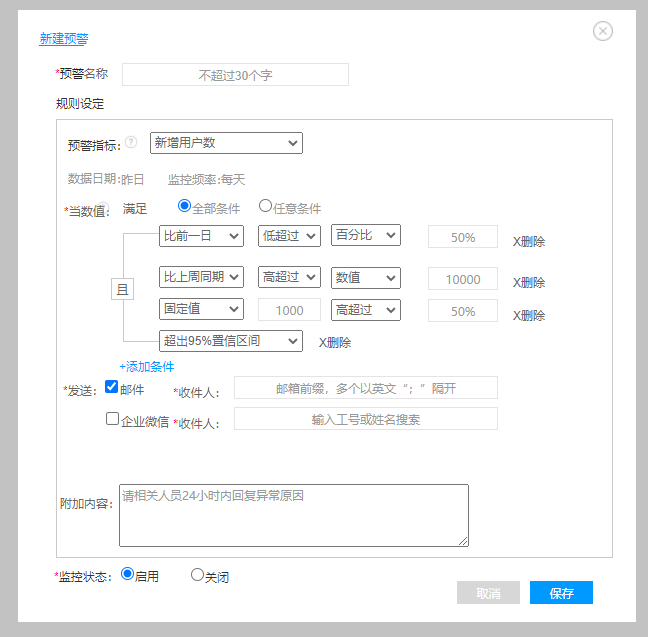
2. 指标异常规则的配置
数据质量保证没问题后,第二步就是界定指标波动异常的标准了,一般有两种方式,一是充分了解业务需求,将指标预警的规则,内嵌到产品实现逻辑中,好处是开发成本低,可以快速变现。
适合于规则变化不频繁的场景,缺点是后期业务变化需要调整规则时,需要开发支持,且难以复用。第二种方式是建立统一的指标预警的配置化工具,业务可以按照自己需求场景设定预警的规则。
3. 利用基尼系数的思想实现异常归因报告自动生成
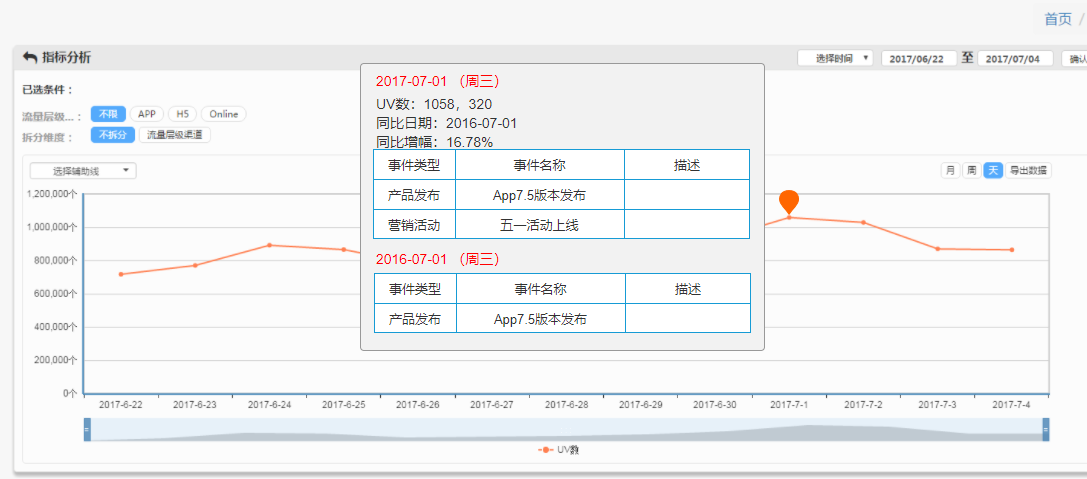
确定数据质量准确无误后,指标波动异常分析的一般流程是,先结合常见的几种异常原因(业务动作、市场环境等)提出初步假设。然后是将指标按照支持的维度进行逐层拆解分析。
例如昨日大盘单量环比下降40%,先分平台看,Android、ios、微信小程序各段环比是否有明显的差异,即是各端均差不多幅度下降,还是某一端明显下降。
分业务类型看,环比下降幅度Top的业务分别是团购、丽人、到店,单量下降对大盘整体的影响分别是10%,8%,5%等。最后确定指标拆解过程定位关键影响维度验证假设,得出分析结论。
这个分析流程的核心思想是基于某一标准(指标)分析哪个维度、以及哪一维度枚举值对总体的影响最大,这和经济学中用基尼系数(英文:Giniindex、GiniCoefficient)比较相似,基尼系数来作为衡量一个国家或地区居民收入差距的常用指标。
基尼系数取值区间为[0,1]。越接近0表明收入分配越是趋向平等,一般认为小于0.2时,居民收入过于平均,0.2-0.3之间时较为平均,0.3-0.4之间时比较合理,0.4-0.5时差距过大,大于0.5时差距悬殊。
因此,可以先通过计算各个维度下,每个维度枚举值波动情况对大盘的影响,得到单一维度下,各个值的基尼系数(基尼系数的算法公式参考百度百科),得到哪些维度波动“不公平”,即差异比较大,由此可得影响总体波动的关键维度排名,然后再针对具体维度下的各个枚举值,计算波动影响Top的值。
例如昨日订单环比下降10%,降低数值为A,通过基尼系数得到城市维度下,基尼系数最高,0.7,可以确定城市维度存在明显差异,每个城市环比下降值从高到低依次为,B1,B2……Bn,由此可自动生产归因报告,即到订单下降主要受到地区影响,分城市看大盘贡献度Top3的城市为:上海B1/A,北京B2/A,南京B3/A。
4. 数据填报,实现信息共享
数据部门经常遇到的痛点是很难第一时间获得业务的信息,比如产品改版、活动上线等,往往是先看到数据波动,再去沟通确认业务动作。
因此,可以考虑基于数据填报的能力,当业务调整、或者外部经济、政治、竞争环境信息时,可以及时更新备注,作为日期维度表的补充,在产品端进行展示提醒。
四、小结
指标波动是数据工作中最常见的问题,高效的异常波动的归因分析流程主要从以下几个方面逐步完善:
- 建立完善的数据质量监控体系,才有足够的自信,确认不是数据问题
- 利用基尼系数分析或其他分析方法,产品化影响波动的关键维度以及影响率,可应用与定制化的可视化报表或自主分析BI工具中
- 了解波动的常见原因,将定量的数据分析结果与业务内外部的因素结合起来
- 建立便捷的信息共享通道,降低沟通成本
#专栏作家#
数据干饭人,微信号公众号:数据干饭人,人人都是产品经理专栏作家。专注数据中台产品领域,覆盖开发套件,数据资产与数据治理,BI与数据可视化,精准营销平台等数据产品。擅长大数据解决方案规划与产品方案设计。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议









老师您好,请问您这里的归因分析报告,就您提到的大盘单量环比下降40%这个例子来说,假设有少量城市单量上升,那这个基尼系数怎么计算,也能正常算出来吗?还望老师指点。