
 起点课堂会员权益
起点课堂会员权益从算法原理,看推荐策略

在信息量爆炸的今天,由于范式的转移,传统的内容和渠道已经不再是稀缺资源;在今天,将信息和内容更好更精准得呈现在用户面前,才是全方面提高效率的方式,真正的稀缺资源变成了「推」和「拉」。而在这一切的背后,推荐算法的作用都功不可没。
推荐算法简介
目前的推荐算法一般分为四大类:
- 协同过滤推荐算法
- 基于内容的推荐算法
- 混合推荐算法
- 流行度推荐算法
协同过滤的推荐算法
协同过滤推荐算法应该算是一种用的最多的推荐算法,它是通过用户的历史数据来构建“用户相似矩阵”和“产品相似矩阵”来对用户进行相关item的推荐,以达到精准满足用户喜好的目的。比如亚马逊等电商网站上的“买过XXX的人也买了XXX”就是一种协同过滤算法的应用。
基于内容的推荐算法
基于内容的推荐算法,是将item的名称、简介等进行分词处理后,提取出TF-IDF值较大的词作为特征词,在此基础上构建item相关的特征向量,再根据余弦相似度来计算相关性,构建相似度矩阵。
混合推荐算法
混合推荐算法很好理解,就是将其他算法推荐的结果赋予不同的权重,然后将最后的综合结果进行推荐的方法。
举例来说,比如上述已经提到了三种方式,协同过滤算法中的基于用户和基于item的协同过滤推荐,和基于内容的推荐算法;而混合推荐算法中是将这三种推荐结果赋予不同的权重,如:基于用户的协同过滤的权重为40%,基于item的协同过滤的权重为30%,基于内容的过滤技术的权重为30%,然后综合计算得到最终的推荐结果。
流行度推荐算法
这个很基础,看名字就知道了。这种方法是对item使用某种形式的流行度度量,例如最多的下载次数或购买量,然后向新用户推荐这些受欢迎的item。就和我们平时经常看到的热门商品、热门推荐类似。
浅析推荐算法在实际中的应用
了解了大概原理后,就可以来看看在实际场景中,推荐算法都是怎么使用的吧。(事先声明,这只是我看了相关东西再结合自己理解进去推测的,如果有说错的地方请各位千万放下手中的刀……)
好,下面开始,先说说协同过滤算法在实际中的应用。
协同过滤算法
协同过滤算法一般是怎么做的呢?我们先来看看在图书推荐中的做法:
协同过滤(CF)大致可分为两类:一类是基于邻域的推荐、一类是基于模型的推荐;邻域方法是使用用户对已有item的喜爱程度来推测用户对新item的喜爱程度。与之相反,基于模型的方法是使用历史行为数据,基于学习出的预测模型,预测对新项的喜爱程度。通常的方式是使用机器学习算法,找出用户与项的相互作用模型,从而找出数据中的特定模式。(由于基于模型的方法我也不太理解,暂时不展开说明,感兴趣的可以查阅相关资料)
【基于邻域的推荐】–即是构建用户相似矩阵和产品相似矩阵
假设用户表现出了对一些图片的喜欢情况并进行了相应的评分,情况如下:
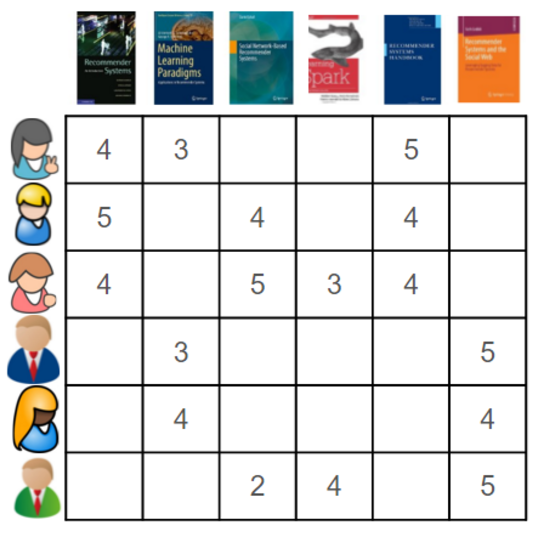
不同图书代表不同维度,评分则代表了特征向量在该维度上的投影长度,根据用户对不同图书的喜爱程度建立用户的特征向量,然后根据余弦相似度可以判断用户之间的相似性。根据相似性可以建立用户相似矩阵:

很显然,通过根据用户对历史图书的评分情况,可以得到用户对其的喜爱情况,在此基础上构建出用户特征向量,可以一定程度上判断两个用户在图书品味上的相似程度,进而我们可以认为,若A和B比较相似,可以认为A喜欢的书B也喜欢。
在给A用户进行图书推荐时,找到与其相似度较高的其他用户,然后除去A用户已看过的图书,结合相似用户对某本图书的喜爱程度与该用户与A用户的相似度进行加权,得到的推荐指数越高的图书优先进行推荐。
这应该也是豆瓣等图书社区上使用的推荐算法之一,利用用户之间的相似度来进行推荐。当然,电影推荐也同理。
同理,反过来我们可以按照相似的方位,以用户为维度来构建item的特征向量。 当我们需要判断两本书是否相似时,就去看对这两本书进行过评价的用户构成是否相似,即是使用评价过一本书的用户向量(或数组)表示这本图书;也就是说,如果有两本书的评价中,用户重合度较高,即可认为该两本书相似度较高。其实借用的还是用户相似的基础。(《白话大数据与机器学习》中也提到过相似的推荐算法,感兴趣的同学可以找来看一下)。
在音乐的推荐中同样用到了协同过滤算法,我们众所周知的使用个性化推荐的音乐app应该属「网易云音乐」比较典型了。
那么我们就来yy一下网易云音乐的推荐算法,首先用户过去都会有听歌的历史,由于音乐中没有相关的评分机制,那么可以根据用户对音乐的行为来建立一个喜爱程度模型,例如:收藏-5分,加入歌单-4分,单曲循环-3分,分享-5分,听一遍就删-0分(本来想说负分走开的)。这样就大概有了一个喜欢程度列表,于是接下来就可以根据用户的听歌情况,建立用户的特征向量,接下来的推荐就顺利成章了。
当然,基于协同过滤算法的用户相似度矩阵算法应该只是网易云采取的一种推荐方式,接下来还会说到另外的方式。
值得注意的是,协同过滤的推荐算法虽然使用得很广且推荐效果也较好,但还是存在一些不足之处:
- 协同过滤算法(CF)推荐中存在流行性偏差,因为协同过滤算法是基于惯性数据来进行推荐的,流行的物品由于关注的用户多,产生的数据也多,因此可以建立较为有效的推荐机制;而对于小众或长尾的产品(没人用过也没人评分过),则无法有效推荐;
- 冷启动问题(又叫做新用户问题,或推荐新项问题),同样是由于惯性数据的缺失,导致一开始的推荐算法无法建立;这样的问题可以通过流行性算法进行一定程度的解决,当然也可以利用基于内容的推荐算法来进行解决(后面会提到)。
基于内容的过滤算法
简介部分已经提到了基于内容的过滤算法的基本原理,这里就不再重复了,直接说一下具体大概是怎么用的吧。
基于内容的过滤方式与协同过滤中建立用户相似矩阵的方式类似,都是利用特征向量来进行余弦相似度计算,从而判断物品的相似性。
首先, 利用分词技术对书籍的标题和内容进行处理,去掉权重为0的词(如的、得、地等);
然后,取 TF-IDF值较大的词作为特征词,并将其提取出来作为标签;

接着, 根据特征词建立书籍的特征向量;
最后, 计算不同书籍之间的余弦相似度,并凭次建立书籍之间的相似度矩阵;

基于内容的协同过滤算法,最主要的初级步骤是通过分词技术对标题和简介等进行处理,形成特征标签。例如,对于图书和电影而言,可以对名称和简介进行特征词提取,从而构建特征向量;当然,在豆瓣上发现可以用一种更省事的方法,就是让用户进行对作品评价时需要勾选相关的标签,这样只要为不同种类提供足够多的标签供用户选择即可(当然这是我猜的);
而如果对于音乐的推荐呢?没有相关简介,歌名也不具备足够的指向性,这种情况下则可以通过音乐本身的类别来作为标签进行特征向量的构建,例如:民谣、摇滚、怀旧等;我猜这也是网易云音乐采用的一种推荐方式吧。
而对于36氪之类的资讯网站,采用什么样的推荐算法也能够有一定程度的理解了吧,原理都是类似的。
基于内容的推荐由于不需要太多的惯性数据,因此可以部分解决冷启动问题和流行性偏差,也就是弥补了协同过滤算法中的部分不足,因此也可以将两者混合起来使用,例如混合推荐算法就是采用了这样的方式;其次,需要注意的是,如果单纯使用基于内容的过滤算法,会出现过度专业化问题,导致推荐列表里面出现的大多都是同一类东西,有的小伙伴可能也观察到了类似的现象,比如在亚马逊上购买哪本书(比如java相关的),会发现推荐的书籍里全是java相关的,就是因为出现了过度专业化的现象。
结语
推荐算法的原理其实基于数学的原理得到解决(向量、余弦相似度等),其实其他各类也同理,都是可在数学的基础上得到思路和衍生,如用来进行情感判断的朴素贝叶斯算法,就是将人才能理解的情感问题转化成了基本的概率问题而得到解决,包括自然语言处理(NLP)和语音识别等,由此真是可以体会到数学的博大精深啊。
作为一名初级产品汪而言,从算法原理角度理解一些实际问题还是很有帮助的,当然具体上手层面还需要开发同学的大力协助。
关于文中对推荐算法的理解和猜测,若有不足之处欢迎指教~
本文由 @Mr_yang 原创发布于人人都是产品经理。未经许可,禁止转载。









非常有帮助,感谢作者
很有帮助
最近想做个智能推荐的功能,原先也是有做过内容推荐的,但是总觉得不够完善,看完以后,觉得对这次做智能推荐很有帮助,非常感谢。
总结的很好,至少作为份外行是理解了,想请教下,产品经理在日常工作中如何决定用哪种算法,根据经验还是也有非常专业的一套评价流程再最终决定?
关于这方面的内容,产品经理有什么相关书籍可以推荐下吗
只能推荐我看过的吧,作为非技术的原理了解可以看《数学之美》和《白话大数据与机器学习》,其他的我也不太懂了…
好的,谢啦