
 起点课堂会员权益
起点课堂会员权益成为搜索产品经理(2):认识网络爬虫
在上文中,笔者介绍了互联网的发展、搜索引擎的发展,从目录搜索引擎讲到搜索引擎。本章节,我们来继续聊一聊搜索产品背后的技术。

因为我本身并不从事技术岗位,本篇文章的读者,我也默认是与我一样,不从事技术岗位,但对技术有一定感知的同学,我将尽力将文章写得简单、易懂。
索引引擎系统由多个子模块组成,先来了解第一个模块,网络爬虫。
一、网络爬虫是什么?
用一个程序自动地将所有的网页下载到本地,在本地形成互联网的镜像备份。
二、通用爬虫框架
了解通用爬虫框架之前,让我们再次回顾上个章节讲过的超链接(hyperlinks)。
浏览网页时,点击超链接,浏览器就可跳转到相应的网页。有了超链接,我们可以从任何一个网页出发,用图的遍历算法,自动地访问每一个网页并把他们存起来。
(图的遍历算法,在这里不做解释,有兴趣的同学,可以自己查询)
上述说法较为抽象,让我们通过一个实例来了解。
网络爬虫如何下载整个互联网呢?

参考上图,从一家门户网站的首页开始。我们任意选择一家门户网站的首页,将其内容下载下来,并对内容进行分析,于是,我们能获取门户网站首页的所有超链接。接着,我们分别进入不同的超链接,比如,进入超链接一,重复对该网站进行内容下载。
当然,也需要记载哪个网页被下载过了,避免重复。
三、网络爬虫的特性
实用的爬虫系统应该具备如下几种特性:
3.1 高性能
互联网网页浩如烟海,因此爬虫的性能至关重要。性能定义为爬虫下载网页的速度,具体评价指标为爬虫每秒能下载的网页数量。单位时间能够下载网页数量越多,性能越高。
3.2 可扩展性
因为互联网网页数量巨大,即使单个爬虫性能很高,要完成爬虫任务,所耗费的时间也是极长。为了尽可能缩短抓取周期,爬虫系统应该有很好的可扩展性,可以通过增加爬虫数量来达到此目的。
3.3 健壮性
爬虫要访问各种类型的网站服务器,可能会遇到很多种非正常情况,比如网页HTML编码不规范,被抓取服务器突然死机。爬虫对各种异常情况能够正确处理非常重要,否则可能会不定期停止工作。
3.4 友好性
爬虫的友好性包含两方面的含义:
1. 保护网站的部分私密性
2. 减少被抓取网站的网络负载
四、爬虫质量的评价标准
从用户体验角度,我们需要对爬虫质量进行衡量,有以下3个指标:
1. 抓取网页覆盖率
2. 抓取网页时新性
3. 抓取网页重要性
4.1 覆盖率
覆盖率 = 爬虫抓取的网页数量 / 互联网所有网页数量的比例
覆盖率高,等价于搜索引擎的召回率越高。
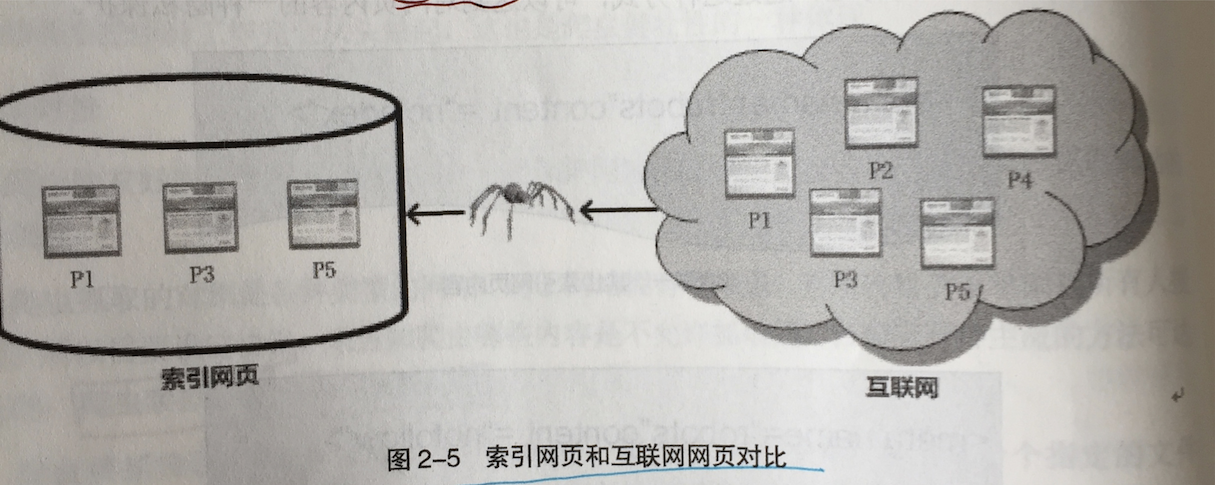
上图中,互联网有5个网页,爬虫系统抓取了其中3个,因此召回率 = 3 / 5 = 60%
4.2 时效性
对很多抓到本地的网页来说,很多网页可能已经发生变化,或者被删除,爬虫完整抓取一轮需要较长的时间周期,所以抓取到的网页中必有一部分是过期的数据,即不能在网页变化后第一时间反映到网页库中,所以网页库中过期的数据越少,则网页的时效性越好,这对用户体验的作用非常重要。
4.3 重要性
互联网网页众多,但是每个网页重要性差异很大,比如来自雅虎新闻的网页和某个作弊网页相比,重要性有很大差异。如果搜索引擎爬虫抓回来的网页大都是比较重要的网页,则其在抓取网页重要性方面做得很好。
本章介绍了,搜索引擎的第一步,网络爬虫,分别从网络爬虫系统,网络爬虫的性能,以及网络爬虫的评价指标三大模块,对网络爬虫进行了讲解。
下一章,我们讲搜索引擎索引。
参考
- 数学之美
- 智能时代
- 这就是搜索引擎核心技术详解
本文由 @一颗西兰花 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议










求更新啊
您有搜索相关的群之类的吗?想多学习一下呢
继续啊,老板!小迷哥等你更新呢!
这完全是seo的部分知识
SEO(Search Engine Optimization):汉译为搜索引擎优化。是一种方式:利用搜索引擎的规则提高网站在有关搜索引擎内的自然排名。目的是让其在行业内占据领先地位,获得品牌收益。——百度百科 >> SEO的目标是提高网站的自然排名,当然是需要了解搜索引擎的规则
个人觉得稍微浅了些,如果深入讲下就好了😂
好的呀!会深入分析的
菜鸟一枚,感谢通俗地分享,学习了
不客气