
 起点课堂会员权益
起点课堂会员权益那些年,我们在A/B测试中踩过这5个坑

如果这些坑真实反映了你当前的状况,就请尽快修正测试方案,跳出陷阱才能得到更为科学可信的结果。
随着Growth Hacking在中国的传播和兴起,作为增长黑客必杀技之一的A/B测试,也被越来越多的国内企业所接受和重视。然而,A/B测试看似简单,实则隐藏着许多沟沟坎坎,稍不注意就会导致试验结果偏离科学轨道。那么今天,我们就为大家一一细数那些年我们在A/B测试中踩过的坑。
PS,文中包含大量真实案例,若能对号入座,请尽快修正试验方案。
1. 轮流展现不同版本
对于广告主而言,找到最有价值的广告投放渠道,提升着陆页(landing page)的转化率,从而对整个广告投放流程进行优化,无疑是最核心的优化目标。采用A/B测试对不同版本的广告和着陆页进行测试,是一种很有效的优化手段。也就是将不同版本的广告和着陆页同时投放,根据它们各自的数据表现,就可以判定哪一版更好。
而目前最常见的做法是,将不同版本的广告进行轮流展示,比如谷歌Adwords系统中的测试功能,就是采用的这种方法。这种所谓的A/B测试(请注意,这种测试方法其实并不能被称为真正意义上的A/B测试),就让企业掉入了第一个陷阱。
举个不太恰当的例子,如此的测试方法就好比在电视上投放广告,分别选取了工作日的下午三点中和晚间黄金时段进行测试收集。由于轮流展示时的测试环境不尽相同,所面向的受众群体更是千差万别,因此最终试验结束后的数据结果必然会存在一定偏差,也就更不具有说服性了。
正确的做法是:不同版本需要并行(同时)上线,并且尽可能的降低所有版本的测试环境差别,才能得到精准的数据结果,从而做出可信的决策。
2. 选择不同应用市场投放
在介绍这个误区之前,必须先解释一下什么是辛普森悖论。辛普森悖论是英国统计学家 E.H. 辛普森(E.H. Simpson)于1951年提出的悖论,即在某个条件下的两组数据,在分别讨论时都会满足某种性质,可是一旦合并起来进行考虑,却可能导致相反的结论。
什么样的情况会造成辛普森悖论呢?一个很典型的应用场景:为了验证新版本对于用户使用真实影响,很多企业会选择将不同版本打包,分别投放到不同的应用市场。当发现其中某版本的数据表现的最好,就决定将该版本全量上线。殊不知,当将全部应用市场整合起来进行统计,却发现这个版本的表现差强人意,对核心数据产生了不利影响。
这里有一个真实的案例,某产品计划在安卓客户端上线一个新功能,于是先将不同版本以小流量投放在多个应用市场(例如豌豆荚、91助手等)。一段时间之后,测试结果都指向了其中一个版本。但其实,这些不同应用市场的用户并不具有全用户代表性,所以如果盲目将试验选出的版本直接推送给全部用户,就很容易因为辛普森悖论而出现完全相反的结果。
因此,避免这一大陷阱的正确做法是:将流量进行科学地分割,保证试验组和对照组的用户特征一致,且都具有全局代表性。
3. 试验结果不好就一竿子打死
上一个误区讲的是「以偏概全」,那么接下来我们要介绍的这个误区则是「以全概偏」,也叫做区群谬误。
在这个概念中,认为群体中的所有个体都有群体的性质。但如果仅基于群体的统计数据,就对其下属的个体性质作出推论,那么得出的结论往往是不准确的。换句话说,当我们做了一次A/B测试后,发现试验版本的数据结果并不理想,于是就认定所有的地区或渠道的效果都是负面的,那么我们就陷入了区群谬误的陷阱。
作为国际短租平台,搜索是Airbnb生态系统中很基础的一个组成部分。Airbnb曾经做过一个关于搜索页优化的A/B测试,新的版本更加强调了列出的图片,以及房屋所在位置(如下图所示)。
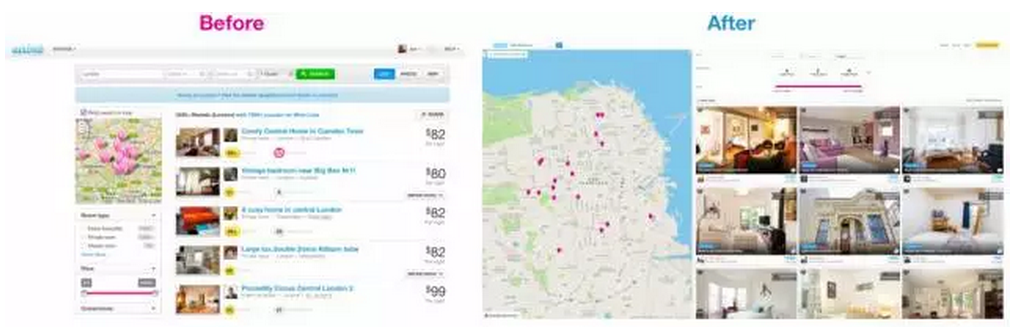
在等待了足够长的时间之后,试验结果显示新老版本的整体数据相差无几,似乎这次优化没有很好的效果。如果此时,Airbnb直接根据整体的数据表现放弃了这次优化,那么这个花费了很多精力设计的项目就会前功尽弃。
然而,Airbnb并没有借此放弃。相反,经过仔细研究,他们发现除了IE浏览器之外,新版在其他不同浏览器中的表现都很不错。当意识到新的设计制约了使用老版本IE的操作点击后(而这个明显为全局的结果造成了很消极的影响),Airbnb当即对其进行了修补。至此以后,IE恢复了和其他浏览器一样的展示结果,试验的整体数据增长了2%以上。
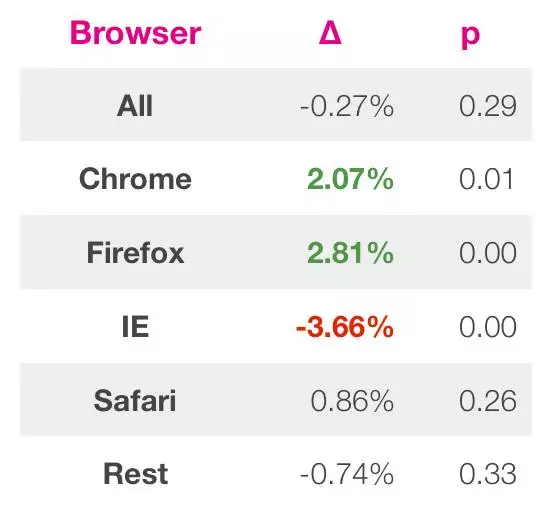
通过Airbnb的例子,我们能学到正确的做法是:在整体效果不太好的时候,不要一竿子打死,而需要从多个维度细分观察个体的情况,以避免区群谬误带来的决策偏差。
4. “好奇害死猫”
一个好的产品必须要能够激发用户的好奇心,并在用户的持续使用中对产品逐渐产生粘性,而不至于流失。但与此同时,我们需要时刻警惕好奇心理所带来的数据偏差。
从心理学的角度来说,好奇心是个体遇到新奇事物或处在新的外界条件下所产生的注意、操作、提问的心理倾向。应用到A/B测试的场景中,当一个产品推出了新的功能或主页,用户在早期出于好奇心理,发生了过多的试探性点击,从而推动了相关数据的增长。如果这时就以为用户更青睐于优化后的版本,直接全量上线,就很有可能忽视了用户的真实喜好。
所以,正确的做法是:适当延长试验的运行时间,观察试验数据的走势是否持久稳定,消除用户的好奇心给结果带来的偏差。
5. 反复检验,区间一收敛就喊停
在反复检验中,我们提到了p-value的概念,它可以作为区间收敛结果显著的一个参考。通常情况下,p=0.05是常用的显著值。于是,我们会自然而然的认为当p达到这个值时,就可以得到显著的结果。不过事实真是这样吗?可以看看下面这个案例。
Airbnb还做过另一个试验,他们将搜索页上的价格过滤器的上限从300调大到了1000,想知道预订数是否会增加。他们监测了价格过滤器试验随时间变化的结果,发现p-value曲线在7天之后就达到了0.05,并且这时候的结论是试验版本在预订方面起到了很显著的效果,然而当他们继续运行试验的时候,却发现这个试验开始趋向于中立,最后得到的结果是两个版本差别不大。
为什么不应该在p-value达到0.05时就停止试验呢?Airbnb团队认为,用户预订需要花很长的时间,所以早期的转化在试验最开始时会有不太恰当的影响。他们给出的建议是,为了避免统计学上的错误,最好的实践方法就是基于样本的总量计算所需最小效果,并在开始试验之前就想好你要运行多久。
试验给出的p-value值是基于认为你设计的试验是已知样本和效应大小的,所以单纯使用p-value作为停止试验的准则是不太正确的。以及,如果你持续的监控试验的发展和p-value,就比较容易看到真实的效果。
以上,就是在做A/B测试时比较容易遇到的坑。还是文章开头说过的那句话,如果刚才说到的那些坑真实反映了你当前的状况,就请尽快修正测试方案,跳出陷阱才能得到更为科学可信的结果。
作者:吆喝科技,微信公众号(appadhoc)。
本文由 @吆喝科技 原创发布于人人都是产品经理。未经许可,禁止转载。









“以及,如果你持续的监控试验的发展和p-value,就比较容易看到真实的效果。”
请问这个持续周期又该如何确定呢?
请问p-value曲线利用什么工具查看?