
 起点课堂会员权益
起点课堂会员权益舆情热词分析的四点思路

近段时间,腾讯和阿里在技术公开这件事情上隐隐有较劲的趋势,这边公开一个Tinker热补丁技术,那边就公开一个双11背后的技术,似乎都在通过秀技术来争夺开发者的眼球,当然,这也是广大开发者非常乐意看到的。下面这篇关于阿里舆情热词分析的文章,稍作删减,难度很合适,值得一读。
背景
阿里云公众趋势分析产品通过云服务的方式,将阿里巴巴成熟的舆情分析技术共享给广大开发者。热词分析是公众趋势分析最近刚刚上线的功能,这个功能听起来很简单,不就是对数据源进行分词,然后再统计一下热度么?No!它可没那么简单。
分词和实体识别
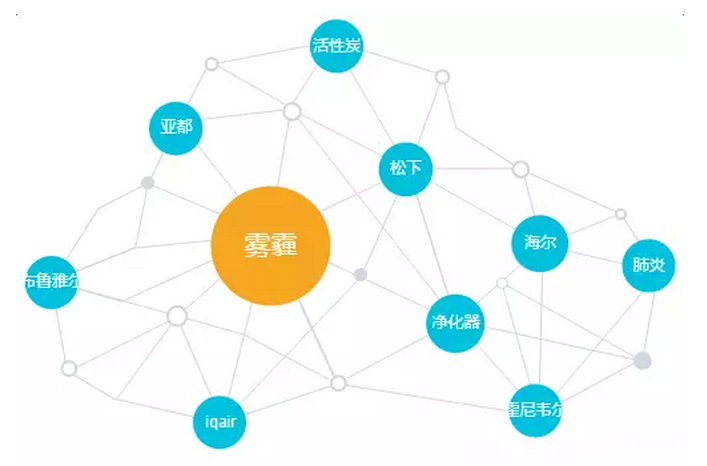
良好的分词是热词分析的基础。对于绝大部分分词工具来说,最大的挑战在于识别从未见过的网络热门词、各种奇葩的品牌、产品词等。举个例子,“安利的空气净化器跟霍尼韦尔还有米家比怎么样”这个句子,我们随意在网上找到了某款开源的分词工具,分词的结果如下:
安利/的/空气/净化器/跟/霍尼/韦尔/还有/米/家/比/怎么样
分词工具能识别一般的词语,但是对于品牌词、产品词等专有的实体词,在没有知识库的辅助下很难识别。而阿里在互联网尤其是电商领域耕耘多年,积累了丰富的词库,并始终在不断更新,譬如上述句子,我们可以将其断成如下形式:
安利:brd/的/空气净化器:prd/跟/霍尼韦尔:brd/还有/米家:brd/比/怎么样
不仅能正确地分词,而且还能识别出其中的实体,如霍尼韦尔和米家是品牌词(brd),空气净化器是产品词(prd)。目前,公众趋势分析背后有百万级的人名、品牌、地址、组织机构名、商品、品牌词库等做支撑。
关键词提取
海量的文章带来了巨大数量的词,对于每篇文章,真正需要被关注的只是少数关键词,那么如何在一篇长文本中挑出关键词呢?热词分析使用TextRank算法为文本生成关键词。
TextRank的算法思想来源于PageRank,旨在通过文本中句子、词之间的相互投票,为句子、词进行权重的排序。PageRank假设一个网页的入链越多,则其权重越高。随机地为每个网页分配一个初始权重,在每一轮投票中,每个网页将其权重均匀地分配给其出链,收敛后(平稳马尔科夫过程)每个网页得到的权重值反映了其重要性。
PageRank通过页面之间的链接关系建立投票机制,TextRank以此为启发,通过词之间的邻近关系建立词权重投票机制,即假如两个词出现在同一个窗口中,则它们之间产生一次权重投票,这样可以通过PageRank的求解方法,计算每个词在文本中的权重。得到权重的排序之后,就可以挑选topN词作为关键词了。
词关联计算
对于每个热词,我们提供了与其强关联的词,那么,这些关联关系如何计算呢?
词关联使用点互信息PMI(pointwise mutual information)来表示,用信息论的语言来表述,点互信息衡量的是“给定一个随机变量后,另一个随机变量不确定性的减少程度”。假设有两个词x和y,则x和y之间的点互信息由下述公式表示:
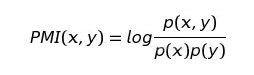
其中p(x,y)表示x和y同时出现的概率,p(x)和p(y)分别表示x和y单独出现的概率。简单粗暴地理解,就是说相对于单独出现,某两个词更喜欢一起出现,则它们之间的关联程度越高。
热度计算
好了,现在我们已经能得到每篇文章的关键词,而且也能计算跟这些关键词有关联关系的词了,那么词的热度如何衡量呢?词的热度计算不能仅仅统计这个词在所有文章中的出现次数,因为每篇文章的热门程度不一样,汪峰上了头条时的报道,对于热度的计算不能跟一般的小道消息同日而语。热词分析在计算热度时,会用文章的热度对词进行加权,而文章的热度会综合考虑以下因素:
- 文章的转发量
- 浏览量
- 评论量
- 文章发布的时间,如果发布时间越长,则热度衰减地越高
这里作者只是对热词分析提供了一些分析思路,真正实践起来还是需要算法的支持和反复调整各种影响因子。
最后,感谢原作者。
#专栏作家#
给产品经理讲技术,微信公众号(pm_teacher),人人都是产品经理专栏作家。资深程序猿,专注客户端开发若干年,对前端、后台技术略懂,热衷于对新的科技领域的探索。
本文原创发布于人人都是产品经理。未经许可,禁止转载。






- 目前还没评论,等你发挥!


