
 起点课堂会员权益
起点课堂会员权益如何让天猫精灵对话更自然?我提出了6个优化方法

为了更实际的感受语音交互,前段时间下单了天猫精灵,用了一段时间,除去技术上的限制,觉得它在主要功能上设计还是比较完整的,但是用起来还是不是那么流畅自然,所以试着从PM的角度写下自己一些优化想法。
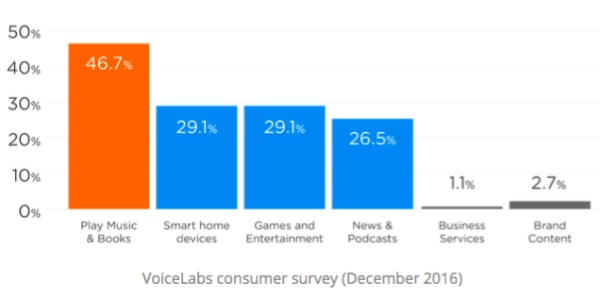
根据VoiceLab 2016年的调研结果,近46.7%的用户喜欢用Amazon Echo 和 Google Home的原因是可以用来播放音乐和听书。所以我主要试用了音乐播放这个功能,并结合之前看的 谷歌语音交互设计规范写了这篇文章。(10分钟看懂谷歌语音交互设计规范都讲了些什么)
对话式交互设计分三个阶段:
- 解决基础交互问题,让用户能开始对话(1-10轮)
- 解决数据和中级交互问题,让用户能持续对话(10+轮)
- 解决需求问题,让用户能长期对话(超过一周)
目前天猫精灵已经可以支持用户开始对话了,但是在对话过程中还是不是那么流畅,但其实为什么会觉得对话不流畅呢?我觉得主要原因是对话是双向的,一方的停止都会让对话被终止,
- 用户停止:由于缺乏恰当的指引和自然的对话方式,有时候用户可能试了几次同样的功能就失去了对话的兴趣(特别是其中还有几次出错情况)。所以天猫精灵需要给到用户指导,和优化自己对话方式,给到用户信心,以便对话继续下去。也就是后面讲的如何让对话更自然流畅。
- 天猫精灵停止:因为技术的限制,天猫精灵不可能听懂用户说的所有话,目前当识别出错时,天猫精灵会直接的报错,从而结束对话。比如“ 对不起,我没有搜到这首歌“。 但是我们其实可以通过一些对话设计技巧来让对话继续下去,也就是后面讲的的错误情况处理机制。
如何让对话更自然流畅(避免用户停止对话)
1、多样化回答及应答词
使用多样应答词:应答词是指 “好的” “ 没问题“, “ Okay“,等等词语,应答能让用户知道系统已经接收识别了来自他们的信息,并让对话流畅自然。看看我们平时和同事朋友的对话中,当别人提出一个请求时,是不是也会很经常用这类词?而缺乏应答词时对话通常会显得比较冷冰冰。
同样的,在我们日常的对话里,一般也不会永远用同一个应答词,我们可能会说“好的“ “嗯嗯” 甚至表情 来表达确认。 在语音交互里也是这样,所以我们可以在系统内配置多歌应答词表,在回答时随机的提供某个应答词,以提高我们对话的多样性。
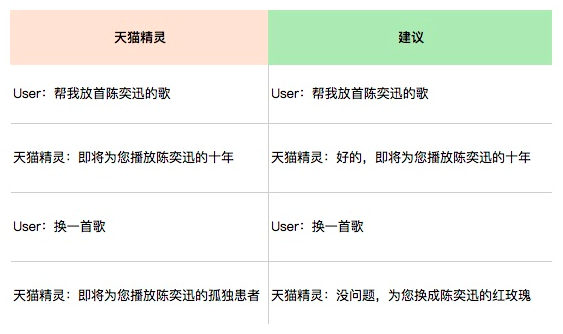
高频率对话的多样化: 我们不需要每个回答都准备N种方式,只需要对高频率出现的对话提供多种回答方式就能很大程度提高对话的自然性。 比如在音乐播放的功能里面,最常使用是播放功能,天猫精灵的回复是“ 即将为您播放#歌曲名词#“, 如果这句话能用不同的方式表达,那么用户会更觉得自己是在跟人对话。
2、主动给出功能引导
在GUI下,用户可以直观的看到可操作的功能,但是对话式交互下,用户不知道产品支持哪些功能,有时候用户可能试了几次同样的功能就失去了对话的兴趣。所以天猫精灵需要让用户知道自己可以做哪些操作。
我在首次使用的时候,因为在网易云使用时是“加到我喜欢的歌曲“,所以一直和天猫精灵说的是” 我喜欢这首歌“ 来让它标记,但是天猫精灵不能识别这句话,我很久后看到文字介绍才知道是用 “收藏“ 这个词。
所以,由于表达的多样性,我们需要提前引导,给出具体的例子,来介绍功能和教会用户该如何表达。比如在用户首次使用音乐播放的时候,放完几首歌后,我们可以主动引导用户“ 如果您喜欢这首歌,可以跟我说“ 收藏这首歌曲””
3、准备用户表达的多种可能性
亚马逊的语言设计规范说 “为了确保功能表现的不错,一个基准是每个意图都需要30或更多的对话单元,即使是很简单的意图”
To make sure your skill performs well, a good benchmark is 30 or more utterances per intent, even for simpler intents. You don’t need 100% coverage, but more examples are better. Also, plan to continue adding utterances over time to improve skill performance.
同样是上面的收藏歌曲的案例,可能只收录了“ 收藏“ 这个词槽(slot),而没有“喜欢”,但是日常的对话中我们可能更经常的说“ 我喜欢这首歌“,所以我们需要用更口语场景的词汇,而不要单纯的把GUI的词汇移植过来。同时为了保证功能的覆盖面,我们需要去想到更多的可能的词汇, 比如“加星这首歌“ “ 这首歌很好听“ “
4、处理有歧异的对话
这个我们之前也说过,自然语言处理里面最基础的问题就是歧义消解(disambiguation)问题,比如我让天猫精灵放一首 安静(周杰伦的),它会播放 安静的音乐合集 (即歌单)。或者我说 “报警”,它会播放某歌手的《报警》,这些都是对于比较明显会出现歧异的地方没有进行处理。 所以在对话设计的时候,除了正常的对话,也要对那些容易产生误解的对话进行预设。比如在机器无法判断的时候 ,主动提问“ 你是要听安静这首歌吗?”
错误情况处理(避免天猫精灵停止对话)
在对话的时候,我们可能因为技术限制或者用户的原因出现各种错误情况,但是记住“ In Conversation, There Are No Errors“,把出错当成机会,就像和朋友讲话时我们也常常不理解对方的意思呀,所以我们要做的是在出错后给到良好的反馈,而不是主动停止对话。
在谷歌语音交互设计规范里我们讲到两种错误情况
- 输入缺失:用户没回应,或系统未获取到用户输入,比如用户突然走远了没回复。
- 无法识别:虽然获取到了信息,但是却不能识别解析,比如背景噪音或多个用户一起说话
- 输入有误:用户回答了但技术识别有误, 比如用户说的是“陈奕迅” 识别成“ 陈奕慢“
- 无法匹配:用户回答了,识别也准确,但是没有对应的功能,比如用户说帮我叫个顺风车
- 错误的识别:我们以为识别成功,但是其实误解了用户,用户可能会在下一次对话纠正。
针对这些错误有如下优化方式:
(1)智能联想
我不知道是我没发现还是怎样,目前天猫精灵还不支持缺失联想和错误联想的功能,所以暂时先写上来了。
- 识别缺失联想: 当系统没有完全采集到用户说的话时,可以使用缺失联想,比如只识别到 “莫文蔚的如果没有“,可以通过缺失联想,问” 您是不是想听莫文蔚的 如果没有你“
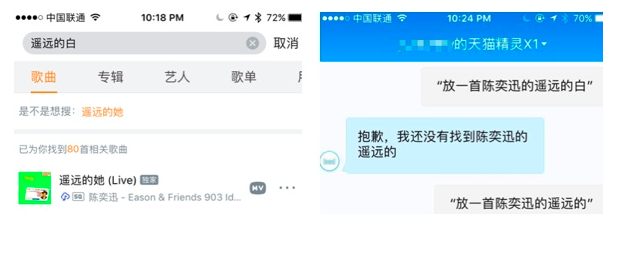
- 错误识别联想: 我在虾米里试了下 搜索“ 遥远的白“,是可以联想成功的,而且再天猫精灵里也识别出是音乐这个功能,所以当识别出错时,可以通过识别联想,询问说 “您是不是要听陈奕迅的遥远的她“,给予用户使用的信心,也让操作继续下去。
(2)主动提问
试想如果我们日常没听清时,是不是会说,“你刚说陈奕迅的那首歌?”,在设计VUI时也是一样,在无法应对的时候,不用过多的感到抱歉,试着像和朋友说话一样 让天猫精灵说 “ 对不起,我没听清,你要听陈奕迅的哪首歌?” “ 能再说下你要听哪首歌吗” 。
- 无内容的快捷重复提示: “ 您能再说一遍吗”
- 有内容的快捷重复提示: “ 我没听清,你刚说的哪首歌?”
- 重复询问: 当问了个问题用户10秒无回应时,可以重复再问一次“您想听什么歌呢”
- 更改问题:当问了个问题用户无回应时,也可以试着换个说法“ 想听谁的歌?”
- 回答一个没有明说的请求: “您可以试试让我放个热闹的歌”
- 积极主动询问:有时用户无回应,可能是不知道怎么回复,可以试着主动给出用户建议,比如在我问是这是谁的歌时,主动询问“你想要收藏这首歌吗吗”。
最后放一个JIBO的 开箱视频,我们可以看到用户和JIBO的对话就是相对比较流畅的,甚至某些额外的情况也能处理,比如JIBO问”你喜不喜欢我的舞蹈“ 女生说“ A little” 的时候,JIBO会说“ 喜欢还是不喜欢呀“,非常可爱。
本文由 @少女璐 原创发布于人人都是产品经理。未经许可,禁止转载。




![面试离职原因 : 为何离开前公司?该诚实回答吗[离职原因范例]](https://image.woshipm.com/2023/05/06/7f26556e-ec01-11ed-bbb6-00163e0b5ff3.jpg!/both/120x80)




作者的优化方案,让我想到了一句话:当技术不完善的时候,通过产品方案来进行弥补。
双十一之后我再回复你上述所说的赞同点和不赞同点
双十一99元抢天猫精灵?