
 起点课堂会员权益
起点课堂会员权益唇语识别,真会是语言交互的终极战场?

自出现唇语识别技术出现起,就有声音说唇语识别是语言交互的高阶战,甚至可能带来一场革命。不过,从本文来看,唇语识别还不能快速地普及。
在今年的乌镇世界互联网大会上,搜狗展出了一项黑科技——唇语识别,12月14号搜狗在北京又公开演示了这项技术。作为行业领先的唇语识别系统,搜狗在非特定开放口语测试中,通用识别的准确率在60%以上,而在车载、智能家居等垂直场景下,已达到90%的准确率。
虽说搜狗是国内第一家公开演示这项技术的公司,但早在2017年3月,海云数据创始人兼CEO冯一村在亚洲大数据可视分析峰会上,就发布了重庆市公安科研所与海云数据共同研发的唇语识别技术,它的中文识别模型准确率已达到70%。
而谷歌DeepMind团队,在2016年利用BBC视频对他们的AI系统进行了5000个小时的训练,测试时唇语识别正确率达到了46.8%。
这并不是场独角戏,那唇语识别到底是何物?未来又有着怎样的想象空间?
唇语识别只是语言识别的进化
虽说唇语识别近期才进入公众视野,但唇语识别技术的发展可以追溯到上世纪80年代。
当时,语音识别技术迅速发展,出现了许多实用的语音识别系统,然而这些系统抗干扰能力不强,在有背景噪音与交叉谈话的情况下,它们的性能会大幅降低。而在自然应用环境中,噪音现象十分常见,研究者们为了解决上述缺陷,一方面采用降噪技术降低干扰,另一方面开始寻求其它解决方法。
那唇语识别技术是怎么发展来的呢?语音识别的研究者们突然发现,其实人类的语言识别系统是由两个感知过程构成的,声音虽然是人类语言认知过程中最重要的方式,但在日常交流中,我们还会用眼睛看着对方的口型、对方的表情等,来更加准确的理解对方所讲的内容。受此启发,研究者们开始研究唇语识别。因为唇语识别完全不会受到噪声干扰,在多人对话中也能有效进行区分,这就有望解决语音识别的缺陷。事实上也是,将唇语识别与语音识别结合起来能够大大提高系统的正确率和抗干扰能力,于是唇语识别便有了更多的发挥空间。
换汤没换药,近30年的发展,核心步骤还是三步
经过研究各类资料发现,唇语识别技术从摄像头输入到理解输出,中间最重要的是这三个单元——视觉前段、视觉特征提取、以及唇动识别。
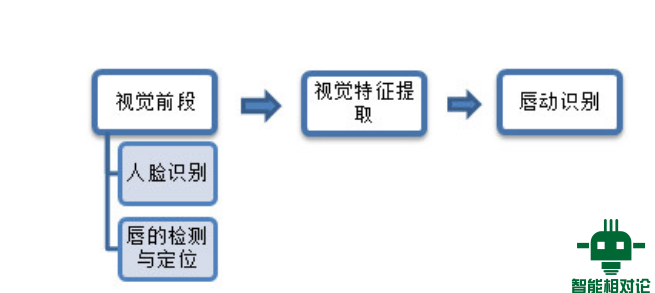
(图为:唇语识别的步骤)
其中,视觉前段包括人脸检测与唇的检测和定位,早期检测方法比较笨拙,不允许人脸自由移动,有些还会手动添加特定标志来跟踪唇动。目前的检测方法主要是基于算法,先用人脸检测算法得到人脸然后有针对性的定位唇动;或者利用最佳闽值二值化算法,以唇的边缘是平滑的,和左右形状对称为条件,作为二值化闽值选定的约束条件,得到平滑而对称的唇图像。
视觉特征提取是对获取的唇图像进行处理得到对应特征,特征提取方法主要分为两大类:基于像素的方法和基于模型的方法。所谓基于像素的方法,就是利用包含嘴的灰度级图像或利用经过预处理后得到的特征向量的一类方法。这种方法的缺陷在于对二维或三维的缩放、旋转、平移、光照变化以及说话人的变化都很敏感,会造成提取过程中特征丢失的情况,不能得到完整的特征信息。而搜狗所用的基于模型的方法就是,对唇的轮廓建立一个模型,将特征信息包含在这个模型之中,并对模型中特征信息的变化用一个小的参数来描述。这类方法的优点是重要特征被表示成二维参数,不会因光照、缩放、旋转、平移而改变,缺点是忽略了细微的三维信息,可能会对后面的识别过程造成影响。
目前唇动识别采用的技术大多是隐马尔可夫模型,该技术基本思想是,认为唇动信号在极短时间内是线性的,可以用线性参数模型来表示,然后将许多线性模型在时间上串接起来,组成一条马尔可夫链。马尔可夫链可以用来描述统计特征信息的变化,并且这种变化过程与人的唇动过程是相吻合的,所以隐马尔可夫模型能够识别唇动并与相应语句匹配转化成文字。
看似应用方向很多,最重要的还是辅助语音识别
唇语识别技术的应用方向有很多,比如手语和听力障碍患者的辅助教育、国防反恐方面的情报获取、个人的身份识别以及公共安全领域等都拥有巨大的应用潜力。但在目前来看最大的应用还是辅助语音识别,毕竟它自诞生之初就是为了解决语音识别的噪音问题而研发的,这也会使得语音交互更加完善。
说到这里就不得不提到智能音箱,其实除搜狗之外,很多大公司也在布局语音交互,国内有阿里巴巴、百度、科大讯飞,国外有苹果、谷歌、微软、亚马逊。在今年7月阿里巴巴就发布了一款智能音响天猫精灵,可以接受各种语音指令,搭载中文人机交流系统AliGenie,有望成为家庭智能小助手。在11月16日百度也推出了首款智能音响raven H,其采用19×19的点阵触摸屏,内置DuerOS 2.0语音交互系统,拥有语音和控制器两种交互方式。其余还有京东的叮咚智能音响,小米的小爱同学,喜马拉雅的小雅音响等智能音响产品。对于这些公司而言,似乎不出一个智能音响都不好意思说自己在人工智能领域混。
那智能音响到底与唇语识别有啥关系?大厂们纷纷推出智能音响的原因是看到了新型交互方式的大趋势,但是智能音响能够满足需求的场景较少,且智能音响还有两大顽疾——抗噪音能力与远场交互能力较低。
根据声学在线的测试,即便是市面上最主流的智能音响,在抗噪音能力与远场交互能力上的表现也不尽如人意,5米的中短距离上有很多失误。
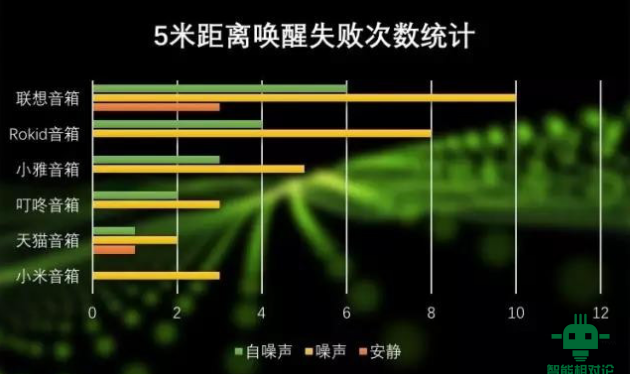
(图为:5m 距离智能音响唤醒失败次数统计)
而且,传统语音交互对输入音频要求高,在背景噪音大时很容易失效,若人与机器再隔得远一点,失效的情况就更加严重了。但唇语识别就可以解决这两个问题。
若要快速普及,还有两个问题待解
自出现唇语识别技术出现起,就有声音说唇语识别是语言交互的高阶战,甚至可能带来一场革命。不过,根据观察,目前来说,唇语识别还不能快速普及。这主要的问题在:
1、摄像头录入存在很大的限制,不能完全满足日常交互需求
在目前的唇语识别系统中,获得的嘴唇视觉特征信息都是正向的,这就意味着你与它交互时,必须时刻正对着它,第一视角被其牢牢占据,这在真实应用场景下难以达到。要能够应用更多的场景,应该使人在侧着身子说话时也能被检测识别,这要求在人脸识别、唇的检测与定位方面研究出更强的定位、跟踪算法,提高算法的普适性,使之适用于非特定姿势和位置的识别定位,并且唇动识别技术也要提高,使之能处理非正向的、较不完整的视觉特征信息。
2、识别的准确度也是一个关键的问题,在有关安全的场景下,准确度是不容有差的
但我们知道其实口型与拼音序列是一对的多关系,如 zhi、chi、shi对应的口型序列是一样的,单纯利用视觉特征难以区分,会造成信息识别错误,处理这个问题,传统的技术方法是文法型语言模型,它基于人工编制的语言学文法,这种语言模型一般用于分析特定领域内的语句,无法处理大规模的真实文本。目前很多识别系统是人工限定的框架,在某一场景中对可能会出现的语句进行了很多设置,这是搜狗唇语识别系统在垂直场景(如车载)中表现得很好的原因,这同样也是它还不能大规模应用到其他场景的原因,因为要对所有场景进行设定,几乎是不可能的。
不过,我们依然要满怀信心,随着人类社会的发展,真实信息越来越多,处理数据的手段也越来越丰富,基于语料库的统计语言模型发展迅速,借助于统计语言模型的概率参数,可以估算出自然语言中每个句子出现的可能性,并通过对语料库进行深层加工、统计和学习,获取自然语言中的语言知识,从而可以处理大规模真实文本,并能识别出语言中细微的差别。目前在通用识别场景的准确率只有60%到70%,虽然稍显不足,但可以预见,随着大数据与人工智能的发展,未来的识别准确率会达到更高。
这看起来,一个新的时代正向我们迎面走来。
作者:夏汀,微信工众号: 智能相对论(aixdlun)
本文由 @潇湘 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 unsplash,基于 CC0 协议









唇语识别,说实话,在实际生活场景中,一无是处。试想一下,一个人走在大马路上对着一个摄像头,夸张的摆弄着自己的嘴巴,这不是神经病是什么?