
 起点课堂会员权益
起点课堂会员权益关于文本舆情数据的6个分析方法

用户舆情信息包括文本、音频、图片等各种各样的形式,在实际工作中,我们应用较多的还是文本类的用户舆情。综合考虑数量、丰富性、易获得性、信息匹配度等方面因素,文本之于音视频、图片而言的信息价值、性价比都是相对比较高的。
一、文本用户舆情的价值
当我们从电商、论坛、应用市场、新闻媒介等渠道平台取到大量和调研目标相匹配的用户舆情文本后,具体应该如何应用?其中可能包含哪些对用研有价值的内容?可以通过什么方法提炼分析?能实现什么预期效果?根据以往项目经验,文本舆情分析的价值和具体应用如下图所示:
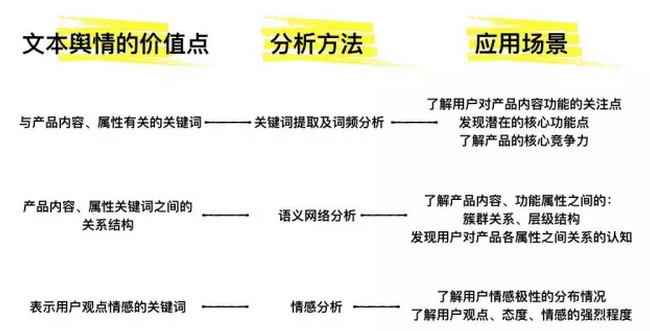
这些信息既描述说明了“是什么”的问题,也可以表明属性、关系、喜好,说明是“怎么样”的,还能在一定程度上分析表象背后的原因,分析“为什么”,可以挖掘出包含其中的焦点、趋势、关联,帮助我们了解产品的市场反馈和用户需求,为方向聚焦、策略引导、价值判断提供依据。
二、文本舆情数据的分析方法
分析文本舆情数据,主要用到的是文本分析的方法。因为文本数据是非结构化的,拿到文本舆情之后的一个关键问题是要把数据转化为能被计算机理解和处理的结构化数据,然后才可能进一步对用户舆情数据进行完整系统的处理分析,从无关冗余的数据中提炼出有意义的部分。
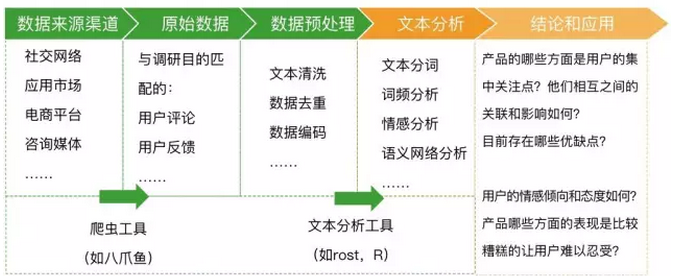
过程中需要用到的工具有:
- 数据爬虫工具:可以根据我们的需要免费从网站上爬取数据(在设有反爬虫机制的渠道,获取舆情数据的难度会增加)。
- 文本分析工具:通过分词处理、词频分析、语义网络分析等,挖掘潜藏其中的关键信息,把握深层的关系和结构。根据笔者的实际使用经验,文本分析工具ROST的功能完善,在文本数据量不太大的情况下基本能满足中文舆情分析的需要。如果对于文本分析结果有更高的要求,可使用Python、R等编程语言进行处理。
- 文本数据可视化工具:使用工具将文本分析结果以可视化的形式(如词云图、语义网络图)呈现出来,便于从中直观的发现价值点。
1、数据爬虫
明确舆情分析的目的和需求后,筛选数据来源渠道获取用户舆情数据。
网络上例如论坛发帖、微博评论、淘宝京东的买家评价等文本舆情信息都是可以用爬虫工具直接爬取的。以八爪鱼为例,可以很方便的从网站上把我们需要的内容按二维结构表的形式(比如excel)免费下载保存。如下图所示,八爪鱼就从电商网站商品详情页上爬取到了信息。同理,爬取用户舆情数据也可以采用相同的方法实现。
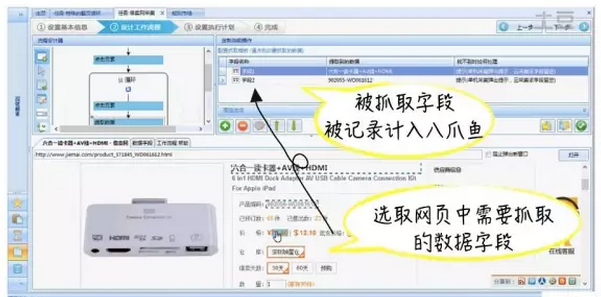
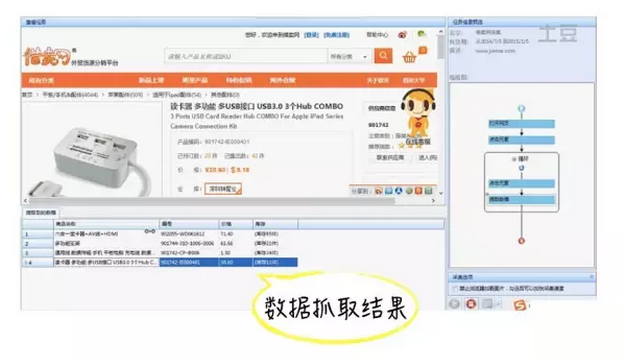
(图片来源:八爪鱼官网免费教程视频截图,笔者标注)
2、文本清洗和预处理
用户在网络上的书写表达非常随意多样,汉字中夹杂数字、字母、符号;语句段落的表达间断不完整,还会出现大量重复的短语短句,比如有的人会评论“棒棒棒棒”“太太太太差了“。文本清洗首要是把这些噪音数据清洗掉。ROST的“文本处理”功能可以用来进行文本清洗。
我们还应根据需要对数据进行重新编码。例如在网易云课堂的某次舆情分析中,用户大量提及了中国大学MOOC,但表达方式有多种(如中M、中国大学慕课、慕课)。为了便于分析,统一编码是非常必要的。
3、分词
分词就是把一段中文文本切割成一个个单独的词。中文分词的难点在于书写中文时字词之间并没有明显的间隔或划分,不像英文那样可以根据自然书写的间隔实现基本的分词(如“we are family”可以直接拆分出“we” “are” “family”)。
汉字书写表达时没有明显的分隔符,再加上汉语博(那)大(么)精(复)深(杂),大大增加了中文分词的难度。这里举一个经典的例子:短语“南京市长江大桥”中由于有些词语存在歧义,计算机的分词结果可能是“南京市/长江/大桥”,也可能是“南京/市长/江大桥”。我们显然知道第一种情况是正确的,但如果算法还不够完善计算机就可能出错,毕竟两种结果基于汉语构词和语法规则都是说得通的。可见具体在实际进行分词的时候,结果可能存在一些不合理的情况。基于算法和中文词库建成分词系统后,还需要通过不断的训练来提高分词的效果,如果不能考虑到各种复杂的汉语语法情况,算法中存在的缺陷很容易影响分词的准确性。
4、词频和关键词
词频就是某个词在文本中出现的频次。简单来说,如果一个词在文本中出现的频次越多,这个词在文本中就越重要,就越有可能是该文本的关键词。这个逻辑本身没有问题,但其中有一些特殊情况需要留意。
最关键的一点就是在关于自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比。根据经典“齐夫定律”的定义,假设我对文本进行分词处理并统计了词频,发现词频排名TOP3的三个词分别为“的”、“是”、“它”,那么“的”出现频率应该约为“是”的2倍,约为“它”的3倍。结果就可能会是词频排名靠前的高频词占去了整个语料的大半,其余多数词的的出现频率却很少。
所以不能完全直接的基于词频来判断舆情文本中哪些是重要的关键词,词频最高的其实是中文中的常用字,而非对当前文本最有代表性的关键词。如下图的词频曲线所示,只有出现在曲线中间区域的词才是真正在当前文本中出现频率高,并且在其他文本中很少出现的,这些词语就是当前文本的关键词,对当前文本具有重要性和代表性。前端的高频词和靠后的长尾低频词都可排除在考虑范围之外。
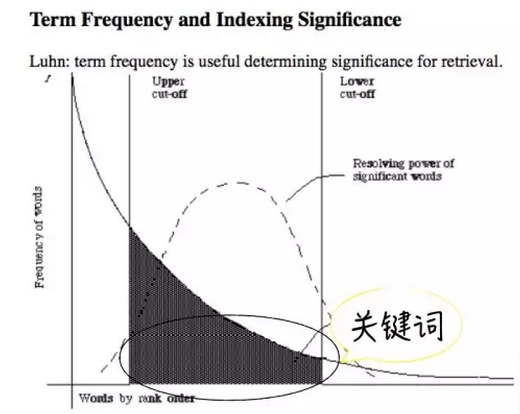
(图片来源:Google,笔者标注)
基于这个原理,在词频统计之前需要过滤掉文本中的停用词(stop word)。出现在词频曲线头部的那些高频词,就多数是停用词。停用词还包括实际意义不大但使用频率高的功能性词汇,比如“啊”、“的”、“在”、“而且”这样的语气词、介词、连词等等。过滤停用词还是为了减少信息冗余,提高分析的效率和准确性。过滤停用词需要的停用词表,词库都可以在网上下载。实际应用的过程中我们还可以在停用词表中添加或删减特定的词汇,使之更加完善或具有针对性,符合当前研究的实际需要。
包括分词、过滤停用词、统计高频词在内的这些操作,都可以通过ROST的分词工具完成。我们可以在ROST中导入经过完善或自定义的词库词表,替换掉ROST自带的默认词库。
这些被提取出的关键词浓缩了用户舆情中的精华信息,能反映出用户的关注点、情绪和认知,产品的潜在竞争力等信息。例如,在网易100分的智能笔用户需求调研项目中,我们针对2C市场的智能笔消费者进行了舆情分析。首先我们通过ROST的分词工具获取了分词文档,关键词及其词频列表。然后我们将分词后的文档导入在线词云编辑器Tagxedo,就能直接生成词云图。

根据分词结果和词云图,我们基本能做出如下判定:
- 用户的整体使用体验:方便
- 产品的核心功能点:同步,识别,效率
- 产品的主要使用场景:笔记,绘画
- 用户的消费体验:价格,概念创意,外观
- 可推测潜在用户的身份:商务人士?老师?学生?艺术设计从业者?
但如果想要进一步知道具体内容之间的关系,就还得要继续挖掘分析这些关键词之间的结构关系。
5、语义网络分析
语义网络分析是指筛选统计出高频词以后,以高频词两两之间的共现关系为基础,将词与词之间的关系数值化处理,再以图形化的方式揭示词与词之间的结构关系。基于这样一个语义网络结构图,可以直观的对高频词的层级关系、亲疏程度进行分析。
其基本原理是统计出文本中词汇、短语两两之间共同出现的次数,再经聚类分析,梳理出这些词之间关系的紧密程度。一个词对出现的次数越多,就表示这两个词之间的关系越密切。每个词都有可能和多个词构成词对,也会有些词两两之间不会存在任何共线关系。关键词共现矩阵就是统计出共现单词对出现的频率,将结果构建而成的二维共现词矩阵表。
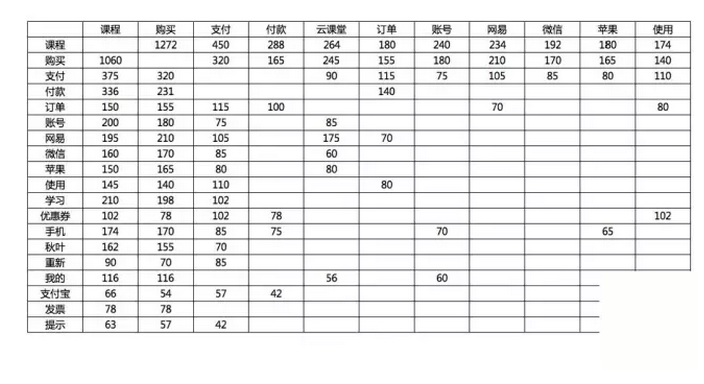
再经聚类分析处理,将关键词共现矩阵转化为语义关系网络,揭示出各节点之间的层级关系、远近关系。需要特别强调的是,语义网络分析只是根据节点的分布情况来揭示他们之间关系的紧密程度,并不能表示节点之间存在因果关联。基于共现矩阵的关键词语义网络分析,同样也可以通过ROST中的语义分析工具来完成,生成语义网络结构图供我们进行分析。
例如,我们曾针对网易云课堂的用户支付问题进行了舆情分析。所有舆情数据是以若干支付相关的词汇为关键词,进行抓取的。通过ROST的分析生成了如下图所示的语义网络结构图。
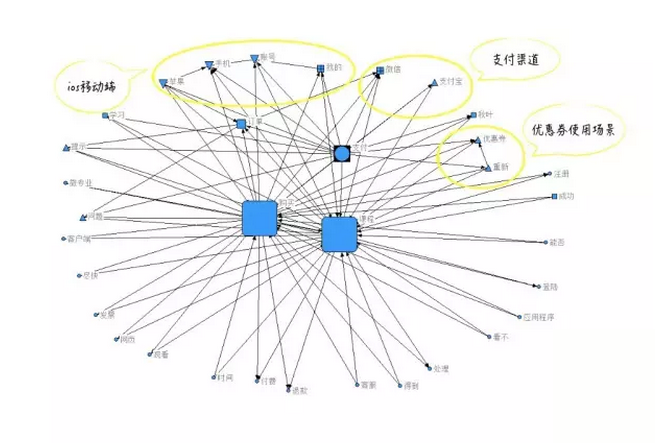
在这个语义网络图中,次级节点基本以核心节点为中心向周围辐射分布,但其中也存在局部的簇群关系,揭示出主要问题之间的潜在关联:
- 优惠券:优惠券使用问题和重新支付场景关系密切,可挖掘分析导致了重新支付场景下的优惠券使用问题的具体原因。
- 移动端:移动端支付问题突出的表现在IOS端
- 支付渠道:微信和支付宝的支付情况存在差异。微信和订单的创建搜索关系密切,支付宝和购买流程关系密切。
6、情感分析
对用户舆情进行情感分析,主要是分析具有情感成分的词汇的情感极性(即情感的正性、中性、负性)和情感强烈程度,然后计算出每个语句的总值,判定其情感类别。还可以综合全文本中所有语句,判定总舆情数据样本的整体态度和情感倾向。
ROST同样也可以完成对文本情感的分析。但目前不少文献、研究认为中文情感分析的准确性不够高,因为中文除了有直接表达各种极性情感的形容词(高兴、生气),还有用于修饰情感程度的副词(很好,非常、太),有时候其中还会夹杂表示否定的词(非常不好用,很不方便)。分词处理文本时,要对形容词、副词、否定词都有正确的分词;分词后,要基于情感词库、否定词库、程度副词库对这些情感词汇进行正确的赋值;最后进行情感值加权计算,才能最终分析出总的情感类别。
另外需要注意的是,我们的舆情数据可能来自电商、应用市场、社区论坛等,这些来源渠道本身就对整体数据的情感倾向有筛选,具有某些属性的情感表达直接就被该渠道过滤掉了。
三、总结
总的来看,用户舆情具备有优势特点:
- 来源渠道丰富:不限于社交网络、新闻资讯媒体、电商平台、应用市场等。
- 覆盖面广,信息量大:覆盖到不同人口学特征的人群,覆盖到目标用户、竞品用户等不同人群。
- 真实客观:整体而言是用户最直接的表达,能在一定程度上保证数据的真实客观。
- 获取成本低:基本上都能快速、免费的获取,省时高效。
在用研工作中,用户舆情分析能让我们在特定的研究背景下,以更小的代价了解到产品的市场反馈,用户的态度认知和需求痛点,有效的达到研究目的。
作者:曾玫媚,网易产品发展部用盐一枚。目前对接网易中小学教育产品网易100分的用户研究工作,正在努力为浇(zhé)灌(mó)祖国的花朵添砖加瓦。
来源:微信公众号【用盐有点咸】










文皮皮,文本分析高频词很好用,http://www.wenpipi.com/
有料
赞