
 起点课堂会员权益
起点课堂会员权益如何确定你的用研样本量和数据

在这篇文章中,本文作者将推荐一个公式来确定用户研究中的定性样本量,且探讨如何收集和分析数据,以实现“数据饱和”,最终将提供一个侧重本文观点的案例研究。
Jen正在向一个运营电商网站的客户展示她的调研报告。她在12个潜在用户中进行了访谈,目标是了解用户会在什么样的条件下选择线上购物或线下购物。客户询问Jen,她只与12个人进行了交谈,为什么他们应该相信她的调研结果。Jen向她的客户解释了她的工作流程,分享了她是如何决定样本量的,以及如何通过数据饱和的角度来收集分析她的数据。客户觉得Jen的解释言之凿凿,让她继续了她的展示。
序言
用户研究员必须能确定他们的研究的样本量。客户、同事和投资人想要了解他们是否能相信研究结果的推荐方案。样本人口组成和数量是他们建立信任的基础。你是否访谈了对的人?你是否访谈了足够多的人?研究员还必须知道如何处理他们收集到的数据。如果你没有提出好的问题和进行深思熟虑的分析,你的样本量将不起作用。
定量研究手段(如问卷调查)为决定样本量带来了有效的统计技术。它是建立在你调研的人口量和调研期望结果的可信度之上的。许多利益相关者对定量研究方法和诸如“统计学意义”的术语相当熟悉。这些利益相关者倾向于将这个认知搬运到所有调研项目中,而且因此希望在不同的研究项目中也听到类似熟悉的术语和熟悉的样本量。
而定性研究人员需要为利益相关者设置一个背景。定性研究手段(如访谈)目前没有普适的技术。尽管如此,这里你可以采取几个步骤来保证你采集到和分析了正确数量的数据。
在这篇文章中,我将推荐一个公式来确定用户研究中的定性样本量。我也将探讨如何收集和分析数据,以实现“数据饱和”。最终,我将提供一个侧重本文观点的案例研究。

(Image credit: Brandon Sax) (View large version)
定性研究的样本量
作为调研人员,或与调研人员一起工作的同组成员,我们需要了解和向他人传达为什么我们选择了某个特定的样本量。
我先告诉你一个坏消息。在为定性研究决定一个确切的样本量的问题上,我们并没有一个被广泛认同的公式。任何人都说其他人是错的。但我们拥有的是—— 以学术研究先例为基础的一些建议方针。我曾参与过仅仅访谈了少于10人的项目,也曾参与过访谈了许多人的项目。Jakob Nielson建议可用性测试的样本量为5个。然而,他增加了一些限定词,这个建议仅仅适用于可用性测试研究,不包括探索访谈、情境调查或其他在调研初始阶段广泛使用的定性研究方法。
那么,我们应该如何决定一个定性研究的样本量?我们需要了解我们的调研目的。我们实施定性研究来获取某个事物(一个活动、问题、难题或解决方案)的深度理解。这与定量研究是不同的,定量研究的目的是量化或测量某个事物的存在。定量研究通常提供的是对某个事件的浅层且宽泛的视野。
你可以在滚动的基础上去决定你的定性研究的样本量。也可以在调研前就先阐明样本量。
如果你是一个长达数年项目的学术研究员,或者你拥有大量的预算和很长的时间线,建议你采用滚动样本。你将从预先设定好数量的受访者中收集数据,在此同时,分析这些数据然后决定是否需要继续收集更多的数据。这个方法能为你的发现带来了大量的数据和更真实的证据。你将对你想要去定位的问题拥有更深层和更广阔的视野。到你已经不再需要继续收集数据时,数据收集终止。这样一来,你可能会最终得到一个更大的样本量。
大多数客户或项目需要你阐明一个预先决定好的样本量。事实上,预算和时间通常决定了样本的大小。如果你的项目期望在8-10周的时间里完成调研-设计-开发工作,你将不会有足够的时间来访问50个人并且对数据做严谨的分析。一个10到12的样本量可能对于这样的项目来说更加现实。从调研开始到分析完毕,你只拥有2周的时间。当你耗尽了你的调研资源时,调研将终止。但我们的客户和同行想要我们根据这个数据给出一个有影响力的推荐方案。
你对滚动或先决样本量的使用将决定你如何解释为什么你终止了数据收集。对于滚动样本,你可以说:“我们在分析之后,发现收集更多的数据将不再出现有价值的样本,因此终止了数据收集。” 如果你使用了先决样本量,你可以说:“在访谈了我们预先决定的数量的受访者之后,我们停止了数据收集,并对收集来的数据进行了充分的分析。”
我们使用先决样本量的时候依然能维持一个严谨的流程,它的发现依然是有效的。数据饱和帮助我们确保了这个结果。在使用先决样本时,为了阐明你已经尽职地完成了确定样本量的调查和达到数据饱和,你需要完成这3个步骤:
- 在有意义的基础上去决定样本量;
- 达到数据收集的饱和;
- 达到数据分析的饱和。
在接下来的篇幅将涵盖每一个步骤的细节。
决定样本量:从方针到公式
市场调研公司Research by Design的Donna Bonde提供了调研基础方针(市场定性调研:When enough is enough)来帮助人们提前决定定性研究的样本量。Bonde回顾了无数的市场调查研究来确定不同研究中样本量的一致关键因素。Bonde认为这个方针不应该是一条公式,它应是影响定性样本量的各个因素。这个方针是针对于市场调查的,所以我对它们加以修改来适应用户研究员的需求。我也将相关的因素组织成了一条公式。这将帮助你确定和辨证一个样本量,且增加达到饱和的可能性。
定性样本量公式
基于我对Research by Design的方针的翻译,决定样本量的公式如下:
样本量[N] =(范围[S] × 特征[C] )÷ 专业程度[E] + / – 资源[R]
关于这个决定你定性样本量的公式,这里有其四个要点的描述和例子。
1. 调查的范围
你需要考虑你在试图完成什么东西。在考虑样本量时,这是最重要的因素。你是否打算从头开始设计一个解决方案?或者你是否打算定义一个提升现有产品可用性的小节点?如果你打算创造一个全新的体验,你应该最大化你的调研对象。如果你试图定义你应用中的付款流程有什么潜在的困难,那么你只需要更少的调研对象。
数字上,这个范围可以是1到无限中的任一个数字。0指的是没有调研,这是违反用户体验设计的原则的。下一步你需要将范围乘以每个用户类型再×3(译者注:下文会解释为什么还要乘以3)。因此,这个范围只要比1还大,将大大地增加你的样本量。范围可以理解成你想如何应用你的结果。我推荐使用下面的值来填入范围(scope)中:
- 针对现有产品的调研(比如,可用性测试,定义新功能,或研究现有的状况);
- 创造新产品(比如,一个收纳了所有你的员工所使用软件的新门户网站);
- 超越产品之外范畴(比如,在一个研究刊物刊登你的研究成果或宣布一个新的设计流程)。

你的样本量应该随着你的范围的增加而增加。(Image: Brandon Sax) (View large version)
我给出的调研范围的方针保证了你的样本量跟一些学术研究员建议的量是有可比性的。学者John Creswell建议的方针是,调研范围可以少到如案例研究(如你的现有产品)中的5个人,也可以多到如推出一个新理论(比如,超越产品之外范畴)的20人以上。我们不反对Creswell的建议,因为当你表明你使用了一个公式来决定样本量时,你将造成一个更强烈的争议,同时也表现出了对之更好的理解。另外,学者们在具体样本量的使用上也很难达成一致,Creswell说道。
2. 研究的人口特征
随着你调研人口的多元增加,你的样本量也应随之增加。你将需要每个不同人物画像的多种代表或用户类型。我推荐每种用户类型至少有3个受访者。这允许我们对每个用户类型的用户体验有一个更深层次的探索。
我们假设你现在正在设计一个应用,这个应用能让制造业公司输入和追踪供货从仓库到工厂的订单、运输信息。你应该采访这个流程中的许多人:仓库基层员工、办公室职员、从仓库到工厂的采购员、经理等等。如果你仅仅只是对这个APP的货运追踪功能的界面进行重新设计,那么你应该采访那些关注这个应用的追踪页面的人:仓库和工厂的办公室职员。
数字上,特征(C)=P × 3,在这里,P等于你已经确定的用户类型。3个用户类型决定了C=9。
3. 研究人员的专业程度
有经验的研究员比经验不足的研究员更能从小的样本量中挖掘更多的信息。定性研究员用与定量研究员不同的方式,将他们自身投入到数据收集的工序中。在问卷调查中,你无法根据无法预知的相关话题来改变你的问题大纲。但在定性研究中,你能根据受访者的实时反馈来调整你的访问大纲。有经验的研究员将根据受访者的回应生成更多更高质量的数据。一个有经验的研究员知道如何、何时根据受访者的回应进行深度挖掘。有经验的研究员带来的历史经验能为数据分析增加洞察力。
数字上,专业程度(E)能从1到无限。现实中,这个范围应该在1到2 。例如,一个没有经验的研究员应该值1,因为他们将需要完整的样本量,且随着项目的推进,他们也随之获得经验。采用数值2时你的样本量将减半(在公式中),这也是最极端的。我推荐每增加5年工作经验,这个值就增加0.1,例如5年经验的研究员应该让你的公式中的专业程度(E)=1.10。
专业能力能加快调研的进度以及减少用研所需的样本量。 (Image: Brandon Sax) (View large version)
4. 资源
一个不幸的事实是,在决定样本量时,你不得不将预算和时间约束考虑在内。随着你的样本量的增加,你要么需要增加时间,要么增加这个项目的研究员数量。大多数的客户和项目要求你确定好预期的调研对象数。时间和资金也将受这个数字的影响。你需要预算时间来招募调研对象和分析数据。同时,为了完成你的职责,设计和开发的需求你也得考虑在内。如果你的研究结果跟他人提出来的结论没什么两样,同行也会觉得你的调研发现没有什么价值。在团队急需用研结果的时候,相较于一个需要拖很长时间才能出结果的样本量,我推荐缩小样本量来及时获取信息。
数字上,资源的值可以是N-1或N+1或更多(N为预期的样本量)。你将基于成本和招募受访者、实施调研和数据分析所需的时间来决定你的资源。在之前的尝试中,你可能有了一个具体的数字。打个比方,你可能知道采用一个招募服务需要花费大概15,000美元,其中包括租用2天的设施以及15个受访者1个小时的访谈费用。你也知道招募服务需要至多3周的时间帮你找到你需要的样本,这取决于你的研究的复杂程度。在另一方面,你可能可以通过你的客户找到他们的现有用户,这样招募来的研究对象不需要花费额外的费用。但是,如果你不能快速找到他们或者潜在受访者短期内没空,这会让整个调研流程拖更多的时间。
你需要将获取样本所需要的时间和资源做一个预算,或者相应地减少你的样本量。因为这就是生活中的现实,我建议你事先把这些事情考虑好。跟你的老板或客户说,“我们在这个项目中想要跟15个用户进行交谈。但是我们的预算和时间只允许10个人。请在拿到调研结果的时候考虑到这一点。”
公式使用的例子
让我们假设你现在正在研究评估一个需求:为一个中等大小的客户的客服中心职员创建一个门户网站,职员们可以通过它访问他们平时用来工作的应用。你想要算出这个调研需要多少个受访者参与。你的客户阐述说,这里有3个基本的用户类型:基层员工,经理,管理者。从调研到门户网站的设计概念展示再到运作原型和流程图,你有一个健康的预算和总共10周的时间。你是一个有11年经验的研究员。
你决定用研样本量的公式如下:
范围(S):创建一个新的门户网站,范围(S)= 2 ;
特征(C):3个用户类型,特征(C)= 3 × 3 =9;
专业程度(E):11年经验,专业程度(E)=1.20;
资源(R):充裕,资源(R)=0;
我们的公式是 ( ( S × C ) / E ) +R
故,( ( 2 × 9 ) / 1.2 ) + 0 = 15,这个调研需要15受访者。
数据饱和
数据饱和是来源于学术调研的一个概念。学者们对饱和的定义也是各执己见。最基础的理念是获取足够的数据来支持你所做的决定,然后穷尽你所需要分析的数据。为了创造一个有意义的问题和推荐你已经详尽无疑的数据分析,你需要获取足够多的数据。达到数据饱和取决于你具体的数据收集手段。访谈通常被用来做为最能保证达到数据饱和的研究手段。
研究人员通常不单独使用样本量作为评估饱和的标准。我支持其中一个双管齐下的定义:数据收集的饱和与数据分析的饱和。在研究当中,你需要满足两者的饱和。你也需要在进行数据收集和分析的同时,了解你在调研结束前是否已经达到饱和。
数据收集的饱和
你会收集足够多的有意义数据来确定关键的问题及作出相应推荐方案。一旦你提炼了你的数据并确定了主要的问题,你是否拥有了可行的解决方案?如果有,那么你应该对你发现的东西感到满意。如果你无法确定主要的问题或受访者几乎都有不同的用户体验,那么你需要收集更多的数据。或者如果在某个访谈中出现了一些独有的事件,你可能会增加一些访谈来探索这个概念。
你可以通过收集丰富的数据来达到数据饱和。丰富的数据为你正在调查的问题提供了深度的洞察力。丰富的数据是良好的访谈问题、随访提示和经验老道的研究员的产出物。基于数据收集的质量而非样本量,可以让你收集到丰富的数据。访谈一个3人样本,人均1小时,与访谈一个6人的样本,人均30分钟,前者更可能获取到更好的数据。你需要打磨你的问题来收集丰富的数据。当你创建了一个问题大纲时,让他人帮你优化和提供反馈,并且事先演练一下数据收集,这样可以帮助你收集到丰富的数据。
你或许会将调研对象限制在特定类型的受访者当中。这样能减少扩大样本来达到数据收集饱和的需要。
举个例子,假设你想要了解近期人们在什么情形下会切换使用银行。你是否找到了区分这个人群的关键特征?或许是有些用户之前使用的银行收费太多,让他们觉得恼火,因而更换了一个体验有巨大区别的银行。
你是否跟许多满足各个用户类型的人交谈过?不同用户类型之间的体验是否有共同点?或者你是否需要对某一个用户类型或不同用户类型之间进行更深层次的研究。
如果你仅仅访谈了一个满足换用银行这样一个类型描述的用户,那么你需要扩大你的样本,跟更多该用户类型的人进行交谈。或许你会对仅有一个用户类型与当前项目相关提出异议。但这样其实可以让你把注意力集中在一个用户类型上,进而减少达到数据收集饱和所需要的受访者数量。
数据收集饱和的案例
假设你已经决定好你的银行调研项目需要一个15人的样本。
你创建好了访问提纲,然后将焦点放在过去的五年内你的受访者跟银行之间有怎样的体验上,不管是亲身体验还是在线体验。在每个受访者身上你花了1小时进行访问,细致入微地问尽了你的问题线索和随访提示。
你同时收集和分析了数据。在12个访谈过后,你发现在你的数据里呈现出了下面几个关键问题:
- 用户觉得银行缺乏透明度;
- 用户拥有一个糟糕的初次使用体验;
- 用户更迫切地想要去一个能感受到个人联系的银行。
你的团队聚在一起讨论主要问题以及探讨如何将之应用到你们的工作当中。团队最终决定创造一个基于Web的初次使用体验,促使银行账户收费方式透明化,这个概念旨在向用户说明你的客户是如何允许用户分享个人银行体验及邀请他人的。这些都是你的受访者所说,在开户体验上缺失的主要方面。
你已经达到了两个所需的饱和之一:收集了足够有意义的信息来定义主要问题和做出推荐方案。你从调研结果中有了一个可行的解决方案:建立一个强调透明化和个人联系的初次使用体验。而且它仅仅在你访谈了12个受访者后就得到了。你完成了剩下的3个访谈来验证你已经了解到的东西,并为下一部分的“饱和”储存了更多数据。
数据分析的饱和
你细致入微地分析了收集到的数据来达到数据分析的饱和。不管样本量是1还是100,这意味着你已经用功地完成了你分析数据的职责。你能通过许多方式分析定性数据。有些取决于你采用的具体数据收集手段。
你需要对你的数据进行提炼(【译注】data coding:定性研究中将收集到的信息整理、归纳、分类、概括的数据分析方法。)。你可以归纳性地提炼(基于数据显示的信息),或者演绎性地提炼(预先决定好的提炼方式),试图确定数据中有意义的问题和要点。当你完成了所有数据的提炼和根据提炼的数据确定了问题时,你就让数据分析饱和了。这也是研究员的经验发挥作用的地方了。经验会帮助你更快地确定和提炼有意义的问题,然后将他们转化成可行的推荐方案。
你无法在缺少缜密数据分析的前提下达到数据饱和。(Image: Brandon Sax) (View large version)
回到我们的银行案例,你向你的客户展示了你的发现,并且提出了一个初次使用的体验方案。客户很喜欢这个想法,但是也提出关于缺乏透明度这个问题可能还有很多信息没有揭露出来。他们建议你找多几个人对这个具体的问题进行访谈。
在你同意访谈更多的人之前,你叫来了其他研究员来回顾你的数据。这个研究员发现在透明度问题中存在一些异常现象,他指出,目前根据数据的提炼结果并没有涵盖:“有些用户认为银行在费用和服务上缺乏透明度。而另外有用户提及说银行在客户信息的储存和使用上缺乏透明度。” 最初,你仅仅归纳出了费用方面的透明度缺失。增加“一双眼睛”来回顾你的数据能让你达到分析的饱和。你的设计师开始在初次使用体验和整体体验上处理这个异常情况。他们强调了银行的隐私和数据安全政策。
你跟你的客户探讨并建议不再继续更多的访谈了。当你回顾了数据然后采取了额外的数据提炼,你就能达到数据分析的饱和了。不需要额外的访谈。
样本量公式和数据饱和案例研究
让我们来看看一个涉及到本文概念的案例研究。
假设我们跟客户一起进行他们的临床数据管理应用的概念化重设计。研究人员用临床数据管理应用来收集和储存临床试验的数据。临床试验是关于新药物疗程的效用测试的研究。客户想要我们确定产品设计上有什么提升的空间,以及提高产品的使用和可靠性。我们将在提出设计概念前先实施访谈。
样本量的饱和
基于本文中的公式,我们要了12个访谈的受访者。下面展示的是我们是如何决定公式中每个变量的值的。
范围:我们被指派了提供一个现有产品的设计概念的调查报告的任务。这个项目没有太大的范围。我们不会发明一个新的方式来收集临床数据,相反,我们仅仅只是在优化现有的工具。更小的范围确定了更小的样本量。
范围(S)= 1
特征(C):我们的客户确定了3个具体的用户类型:
- 研究设计员:掌管系统中研究项目建设的用户;
- 数据收集员:从患者收集数据和将数据录入系统的用户;
- 研究管理员:掌管项目中的数据收集和报告的用户。
特征(C)= 3×3用户类型 = 9
专业程度:让我们假设我们的主调研员拥有10年的调研经验。我们的队伍拥有类似项目的经验。我们清楚地知道我们需要多少数据,也知我们道想从12个受访者中了解到什么。
专业程度(E)= 1.20
在这个点上,考虑到资源因素前,我们的公式是( ( 1 × 9 ) ÷ 1.2 ) = 7.5位受访者。
资源:我们知道可用的预算和时间。从过去的项目中我们也知道实施15个受访者的访谈这些资源是足够的。如果我们能访谈少于15位的受访者,我们能够分出更多资源在设计上。增加4个受访者对我们现在的数目(8位受访者)来说并不会让我们的资源缩水太多,而且这能让我们跟每个用户类型的4个不同受访者进行交谈。
资源(R)= 4
基于决定样本量的公式,我们向我们的客户建议需要12位调研对象:
- 范围(S):小范围,升级一个现有产品;S = 1
- 特征(C):3个用户类型;C = 9
- 专业程度(E):10年;E =1.20
- 资源(R):足够总计15人的调研对象;R = +4
- 我们的公式是( ( S × C ) ÷ E ) + R ;
- 故,( ( 1 × 9 ) ÷ 1.2 ) + 4 =12,这个研究需要12位调研对象。
数据分析的饱和
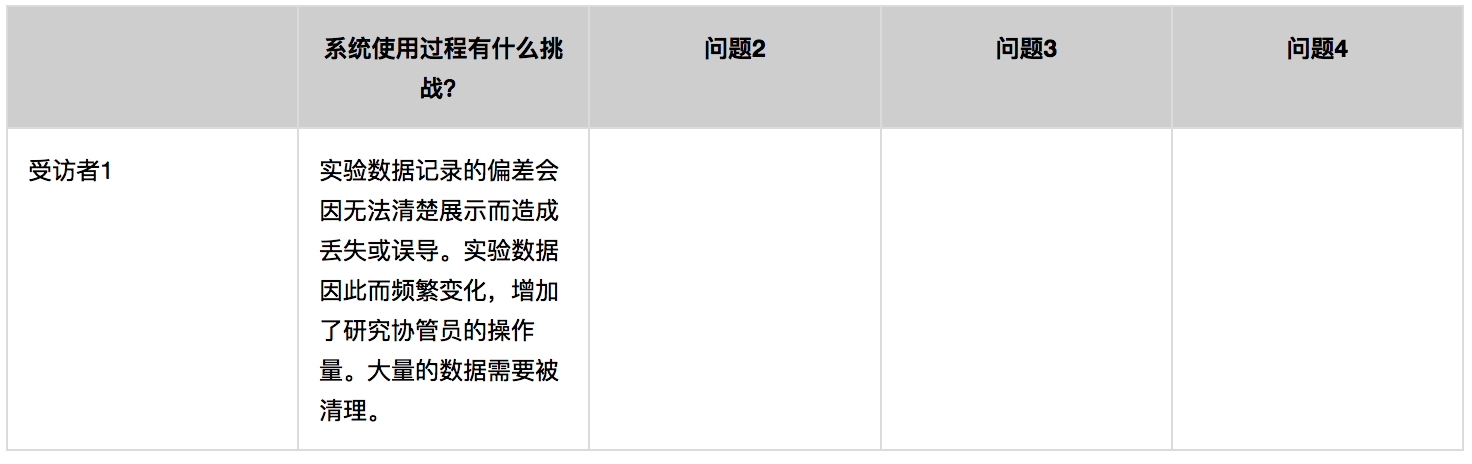
我们将建立一个电子表格来管理我们收集的数据。横向为问题,纵向为受访对象。
例表1:数据分析电子表格
接下来,我们增加了电子表格的第二个标签页,然后基于数据呈现进行提炼(例表2:数据提炼电子表格):

下一步,我们回顾了数据来确定相关的问题(例表3:问题和引言的电子表格):
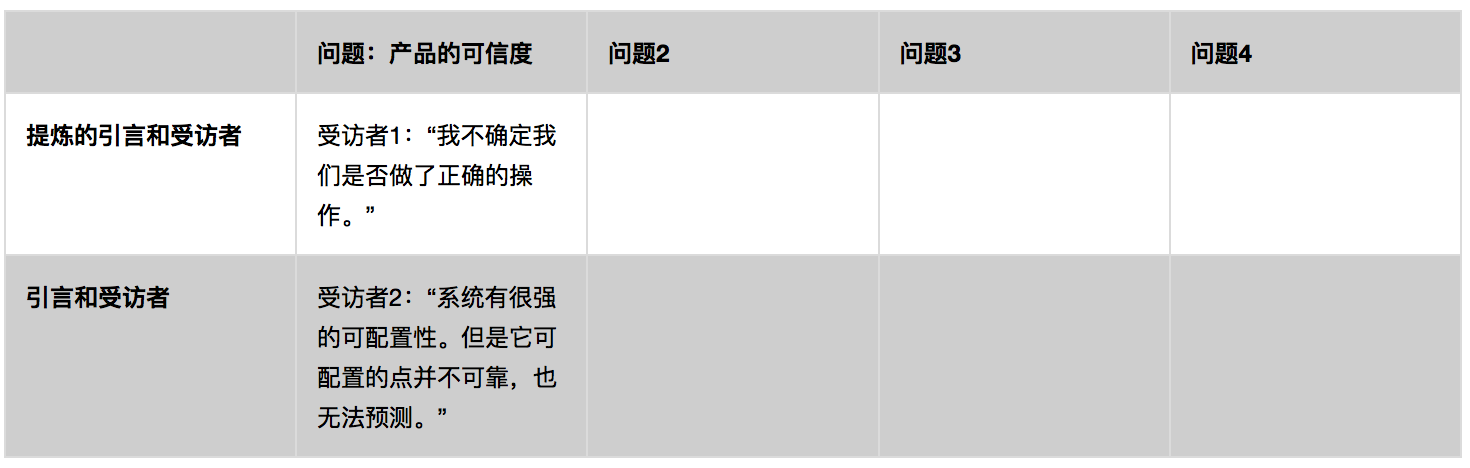
可信度很快作为主要问题呈现了出来。几乎每一个受访者都提到了系统缺乏可信度。研究设计员跟我们说,他们不信任创建研究的架构。临床数据收集员跟我们说,他们不信任新手研究设计员。而管理员跟我们说,他们不信任研究方案的设计,不信任数据收集员的精准度和系统能100%准确地存储和上传数据。
我们的推荐方案把概念设计的焦点放在交互和功能上,以增加产品的可信度。
结论
定性用户研究人员必须为选择样本量提供支撑依据。我们可能不是学术型研究员,但是我们应该为如何决定样本量而做出努力。我已提供了一个帮助确定样本量的公式,这个标准增加了我们调研的严谨性和可信度。
我们也应该确保数据饱和的达成。为了完成这个目标,我们应使用一个有意义的样本量、使用健全的问题和良好的访谈技术收集数据,以及进行缜密的数据分析。当我们决定我们的样本量和分析我们的数据时,客户和同事将对我们提供的透明度而感到欣赏。
我们必须将决定定性样本量的讨论继续推进下去。请分享你在决定样本量时遇到的问题或使用的方法。当被问到你如何决定样本量时,你给了你的客户和同事一个怎样的标准?
参考资源
- “Are We There Yet? Data Saturation in Qualitative Research” (PDF), Patricia I. Fusch and Lawrence R. Ness, The Qualitative Report
- “Justifying the Adequacy of Samples in Qualitative Interview-Based Studies” (PDF), Julie Barnett et al, University of Bath
- “How Many Interviews?” (PDF), Sarah Elsie Baker and Rosalind Edwards, National Centre for Research Methods
- “What Is an Adequate Sample Size? Operationalizing Data Saturation For Theory-Based Interview Studies” (PDF), Health Services Research Unit, University of Aberdeen
- “How Many Test Users in a Usability Study,” Jakob Nielsen, Nielsen Norman Group
原文作者:Victor Yocco
原文地址:《 Filling Up Your Tank, Or How To Justify User Research Sample Size And Data 》
译者:门卫阿伯
本文由 @门卫阿伯 翻译发布于人人都是产品经理。未经许可,禁止转载。









{kind=link}
{kind=link}
{kind=link}
{kind=link}
非常专业
我在做党建调研的时候参考了您的文章,虽然用了问卷调查,但是还是决定采用定性样本量的计算。不知道能否和你探讨。
不明觉厉
给支付宝的作用可能远不止于此,仅我自己的行为:普通的刷码消费,都会有意识的从之前的微信换为支付宝,有了更全面的支付数据,对征信金融等业务作用巨大
表示看不懂