
 起点课堂会员权益
起点课堂会员权益【干货】AI机器学习-Apriori算法
在数据科学的世界中,Apriori算法以其在挖掘关联规则方面的强大能力而闻名。这篇文章将带你深入探索Apriori算法的精髓,从其基本原理到关键术语,再到算法的具体计算过程。

一、什么是Apriori算法
Apriori算法是关联规则挖掘算法,也是最经典的算法。它的进阶算法有FpGrowth算法。
Apriori算法是为了发现事物之间的关联关系,比如我们熟知的“猜你喜欢”,当你浏览一件商品之后,会推荐你一些相关的商品,从而促进商品销量。
这么一说,这个算法的原理想必你也能马上get到了,没错,它就是认为物品之间是存在关联关系的,当这些物品组合出现越多,那么它的关联越强。
比如一个超市在一段时间里一共来了100个客户,其中有90个客户都同时买了鸡蛋和面条,那么超市销售就可以认为鸡蛋和面条是有强关联的,以后就可以把鸡蛋和面条放在一处售卖。
二、几个重点名词
在深入学习Apriori算法之前,我们先来学习几个名词。
以下面的菜市场销售清单为例:
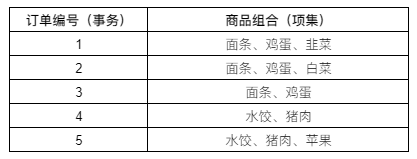
订单编号代表交易流水号,商品组合代表一个顾客一次购买的全部商品。根据这个清单,我们引入以下名词:
- 事务:每一条订单称为一个事务。例如,在这个例子中包含了5个事务。
- 项:订单的每一个物品称为一个项,例如面条、鸡蛋等。
- 项集:包含零个或者多个项的集合叫做项集,例如 {水饺,猪肉}。
- k-项集:包含k个项的项集叫做k-项集。例如 {面条} 叫做1-项集,{面条,鸡蛋,韭菜} 叫做3-项集。
- 前件和后件:对于规则{面条}→{鸡蛋},{面条} 叫做前件,{鸡蛋} 叫做后件。
三、Apriori的原理
接下来开始敲黑板了,我们要深入学习Apriori算法了。
刚刚我们有说到,我们认为经常一起出现的物品越多,它们之间的关系越强。这种经常一起出现地物品组合被称为频繁项集。那么问题就来了:
第一,当数据量非常大的时候,我们无法凭肉眼找出经常出现在一起的物品,这就催生了关联规则挖掘算法,比如 Apriori、PrefixSpan、CBA 等。
第二,我们缺乏一个频繁项集的标准。比如10条记录,里面A和B同时出现了三次,那么我们能不能说A和B一起构成频繁项集呢?因此我们需要一个评估频繁项集的标准。常用的频繁项集的评估标准有支持度、置信度和提升度三个。
1. 支持度
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。如果我们有两个想分析关联性的数据X和Y,则对应的支持度为:
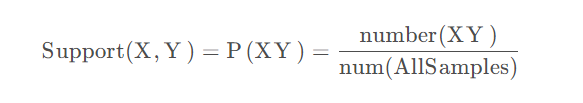
比如上面例子中,在5条交易记录中{面条, 鸡蛋}总共出现了3次,所以:

以此类推,如果我们有三个想分析关联性的数据X,Y和Z,则对应的支持度为:
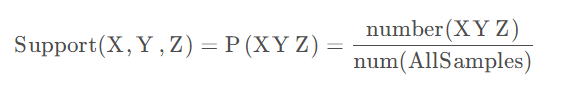
一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。另外,支持度是针对项集来说的,因此,可以定义一个最小支持度,而只保留满足最小支持度的项集,起到一个项集过滤的作用。
2. 置信度
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。如果我们有两个想分析关联性的数 据X和Y,X对Y的置信度为:
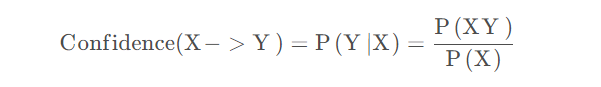
比如上面例子中,面条对鸡蛋的置信度=鸡蛋和面条同时出现的概率/面条出现的概率,则有:

也可以以此类推到多个数据的关联置信度,比如对于三个数据X,Y,Z,则Y和Z对于X的置信度为:
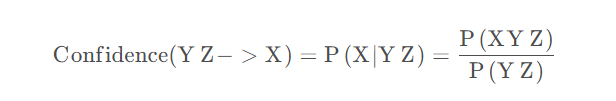
3. 提升度
通过对支持度和置信度的解释,我们应该知道支持度越高的组合出现地肯定越频繁。置信度更能从条件概率上去确保这种频繁程度的可信性。
然而,这两个指标还有一些缺陷:
⽀持度的缺点在于许多潜在的有意义的模式由于包含⽀持度小的项而被删去,置信度的缺点更加微妙,用下面的例子最适于说明:
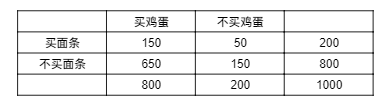
可以使⽤表中给出的信息来评估关联规则{面条}→{鸡蛋}。猛⼀看,似乎买面条的⼈也喜欢买鸡蛋,因为该规则的支持度(15%)和置信度(75%)都相当的高。
这个推论也许是可以接受的,但是所有的⼈中,不管他是否买面条,买鸡蛋的⼈的比例为80%,⽽买了面条又买鸡蛋的人却只占75%。也就是说,⼀个人如果买了面条,则他买鸡蛋的可能性由80%减到了75%。因此,尽管规则{面条}→{鸡蛋}有很高的置信度,但是它却是⼀个误导。所以说,置信度的缺陷在于该度量忽略了规则后件中项集的⽀持度。
为解决这个问题,我们引入另一个度量指标:提升度(lift)
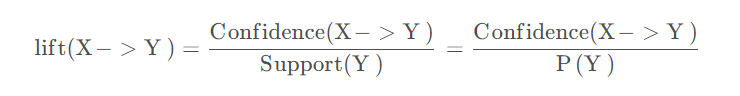
提升度大于1则是有效的强关联规则, 提升度小于等于1则是无效的强关联规则 。
明确了上面三个指标之后,我们还需要引入一个原理:
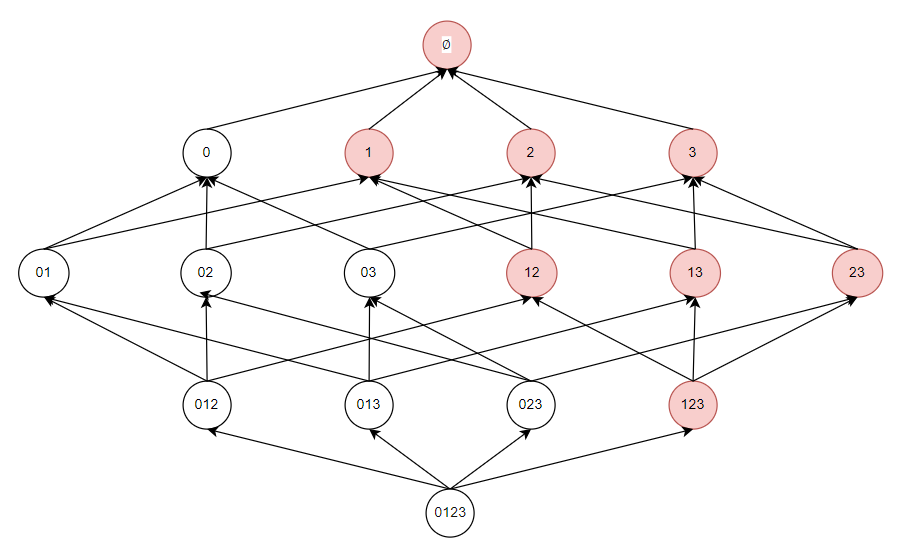
如果一个项集是频繁的,则它的所有子集一定也是频繁的。
这很容易理解,例如对于我们设定一个组合出现了3次以上,那么它的子集出现地次数肯定更多:
然后我们对上面的原理求反可得:
当一个子集不是频繁项集,则它的超集也不是频繁项集。
这两条原理的用处是什么呢?
它可以减少我们去检索的范围,比如我知道了0和1的组合不频繁,那么我就不需要再去找含0和1更多项的组合了。
四、Apriori的计算过程
关联分析的目的包括两项:发现频繁项集和发现关联规则。
首先需要找到频繁项集,然后才能获得关联规则。
Apriori 算法过程
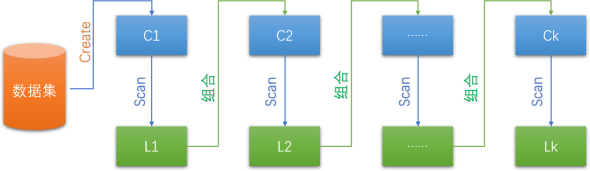
- C1,C2,…,Ck分别表示1-项集,2-项集,…,k-项集;
- L1,L2,…,Lk分别表示有k个数据项的频繁项集。
- Scan表示数据集扫描函数。该函数起到的作用是支持度过滤,满足最小支持度的项集才留下,不满足最小支持度的项集直接舍掉。
那么我们可以将上图所描述的计算过程总结为:
(1)扫描全部数据,产生候选1-项集的集合C1;
(2)根据最小支持度,由候选1-项集的集合C1产生频繁1-项集的集合L;
(3)对k>1,重复执行步骤(4)、(5)、(6);
(4)由Lk执行连接和剪枝操作,产生候选(k+1)-项集的集合C(k+1)。
(5)根据最小支持度,由候选(k+1)-项集的集合C(k+1),产生频繁(k+1)-项集的集合L(k+1);
(6)若L≠Ф,则k=k+1,跳往步骤(4);否则往下执行;
(7)根据最小置信度,由频繁项集产生强关联规则,程序结束。
上述就是对于Apriori算法的全部解析。当然了,对于产品经理来说,我们只需要了解算法原理和它的应用即可。
另外,这套算法的实现是开源的,下次遇到开发说实现不了就拿这篇文章狠狠锤他哦。
作者:阿宅的产品笔记;公众号:产品宅
本文由 @阿宅的产品笔记 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


