
 起点课堂会员权益
起点课堂会员权益提高产品假设及决策质量的方法——因果推断
产品经理的核心价值在于决策,正确的决策能够引导产品在正确的方向上。那么如何借助于“因果推断”的一些方法,在已有数据的基础上构建准实验,并依据相应的数据分析结论去提升事前决策的质量呢?本文进行了总结,希望对你有所启发。

产品经理的核心价值在于决策力,科学合理的决策将指引业务前行在正确的方向上,而一旦有所偏离或不断低质量重复性尝试则会让业务停留在原地转圈。因此,在整个工作流中, 最为关键的其实是第一步,即如何在事前提高决策的质量和正确概率,后面的步骤按照既有流程执行也能保证较高质量的交付。
那么如何借助于“因果推断”的一些方法,在已有数据的基础上构建准实验,并依据相应的数据分析结论去提升事前决策的质量呢?
一、因果关系与归因偏误
首先,我们需要了解因果关系。因果关系是当其他控制变量不变,因某个特定解释变量的变化而引起被解释变量变化的关系。倘若我们要对去探究我们所关注的变量的因果关系,其实可以拆解为两个子问题:其一,界定因果关系:X和Y谁是因、谁是果?;其二,衡量因果效应大小:这种影响有多大?
在正式论述如何去界定因果并估计因果效应之前,我们现来看一个例子认识归因过程中的常见偏误并基于此去理解该如何去做因果推断。假设我们为了研究某服务对GMV的贡献,数据里活跃用户和非活跃用户,各组里都有使用过该服务或没有使用过该服务的用户,详细数据如下所示:

由上表可知,活跃用户使用过该服务的用户累计GMV平均比未使用过该服务的用户高1000元,非活跃用户使用过该服务的用户累计GMV平均比未使用过该服务的用户高500元,但从整体来看,使用过该服务的用户累计GMV反而比未使用过该服务的用户低123元。
细分人群构成来看,在现有数据中未使用过该服务的用户主要是活跃用户,而使用过该服务的用户主要是非活跃用户,两组间人群构成存在差异。也就是说总体数据的比较结果并未对个体活跃程度进行控制,因而造成服务使用效果的评价中混入了活跃程度的影响。
从上例中,我们不能根据直观数据简单通过正负相关去推导因果关系:因为会存在可观测或不可观测的混淆变量对因果解释造成偏差。因此,因果推断最主要的思路就是需要控制混淆变量。
控制混淆变量的最理想的方式即采用随机对照实验,因为随机分配使得干扰项条件均值独立于解释变量,即解释变量与任何其他可能的混淆变量都不相关,这种情况下解释变量与被解释变量之间不会存在混淆路径,二者的相关性能直接反映因果关系。但出于种种原因,如时效性、费用成本、操作性困难等原因,我们可能不会有理想实验条件,只能通过既有的观察性数据去推断,这时候就需要使用计量方法去帮助我们做出因果推断。
二、因果推断的计量方法
以下将简要介绍4种常用的因果推断计量方法
2.1 匹配法
基本原理:对于接受处置的个体,找到可观测特征相同的未被处置的个体,通过比较他们的观测结果的差异,达到估计处置效应的目标。
成立假设:
- 条件独立假设:给定可观测特征后,潜在结果独立于处置状态;
- 共同支撑域条件:给定可观测特征 Xi= x,个体接受处置的概率大于0并小于1。用于确保同时存在处置组和控制组
方法及操作步骤:匹配法主要可分为直接匹配法和倾向得分匹配法两种。直接匹配法:根据可观测的特征值直接匹配;如果可观测特征只包含少数几个非连续变量,可进行直接匹配,但当可观测特征维度增加时,要在多维进行直接匹配就存在操作性困难;倾向得分匹配法:通过函数关系将多维变量变换为一维的倾向得分(propensity score)之后,再根据倾向得分进行匹配。
倾向得分匹配操作步骤:第一步:估计倾向得分(首先,确定模型-Probit/Logit;其次,选择纳入模型的变量);
第二步:匹配前均衡检验:根据匹配得分将样本分为若干区间,保证每个区间里处置组和控制组的平均倾向性得分相同,并检验每个区间内,处置组和控制组的特征变量是否均衡;
第三步:评估共同支撑域条件,考虑使用有共同支撑域的样本;
第四步:选择匹配方法(分块匹配法、近邻匹配法、卡尺匹配法、半径匹配法、核匹配法);
第五步:匹配后均衡检验:确定匹配样本后检验处置组和控制组变量是否均衡;
第六步:根据条件期望公式计算处置效应。
2.2 双重差分法
方法概述:寻找自然发生的实验或者现有的观察数据根据反事实推断框架建构实验条件,寻找良好控制的对照组的准实验。在干预前后都有实验组、对照组面板数据的情况下,通常采用双重差分法估计这类干预项目的因果效应。
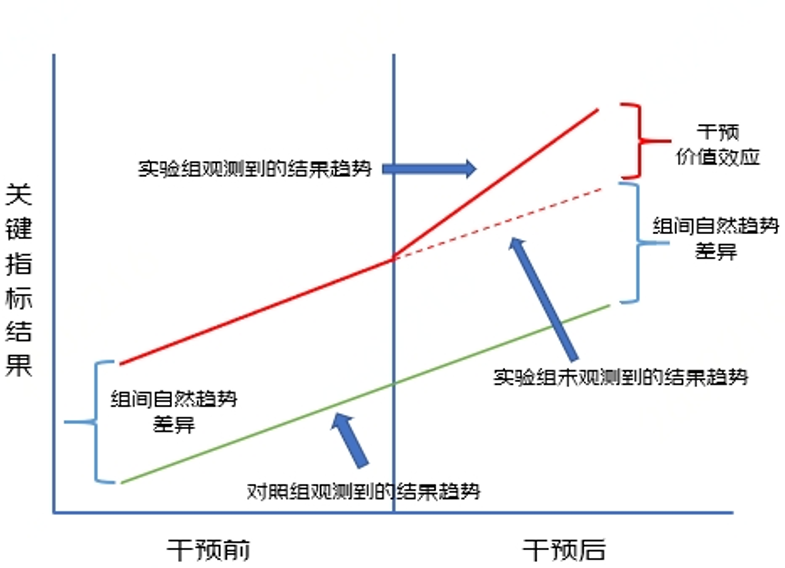
基本原理:利用实验组和对照组的变动趋势差异来衡量因果效应,即用干预后两组被解释变量之差减去干预前两组被解释效应之差来反应由被解释变量干预后由此变量所带来的效应大小。
成立假设:
- 共同趋势假设:没有解释变量干预,对照组和实验组的自然变动趋势保持一致;
- 共同支撑域假设:给定可观测特征 Xi= x,个体接受处置的概率大于0并小于1。用于确保同时存在处置组和控制组。
方法及操作如上图所示:首先,计算第一重差分,即自然趋势差异——干预前实验组被解释变量均值-干预前对照组被解释变量均值;其次,计算第二重差分,即干预后差异——干预后实验组被解释变量均值-干预后对照组被解释变量均值。最后,计算双重差分——干预后差异-自然趋势差异。
2.3 断点回归法
断点回归(regression discontinuity design):是一种研究非随机实验那接近随机实验数据的方法,适用于研究某类特定社会科学事件的因果,这些事件的特点是,个体是否受到事件的影响,取决于其某个可观测特征的连续变量是否大于给定的临界值。
而由于该变量在临界值两侧是连续的, 因此个体针对该连续变量的取值落入该临界点任意一侧是随机发生的,即不存在人为操控使得个体落入某一侧的概率更大, 则在临界值附近构成了一个准自然实验。如下图所示,我们可根据某一连续变量的临界值去划分出是否接受过解释变量影响的两组人群,并根据其在被解释变量的值的差异去计算解释变量所带来的效应大小。

操作步骤:第一步,用散点图显示解释变量和被解释变量关系;
第二步,在散点图基础上,进一步去除散点噪音,采用多项式回归或分区均值拟合的方式对数据进行“平滑拟合”并绘制关系图。
第三步,进行断点回归模型基本假设检验:检验解释变量的概率分布连续性及个体特征变量连续性;
第四步,计算断点处置效应:采用全局多项式回归或局部多项式回归的方法来估计被解释变量在断点处的跳跃程度的大小及显著性。
2.4 工具变量法
基本原理:核心思路是通过工具变量“清理”解释变量,将解释变量中与干扰项相关的部分剔除,仅保留与干扰项不相关的部分去估计解释变量对被解释变量的因果影响。
如下图所示,在因果推断过程中,常常会遇见与解释变量和被解释变量均相关的不可观测变量,如“好胜心”对“教育水平”和“职业收入”。
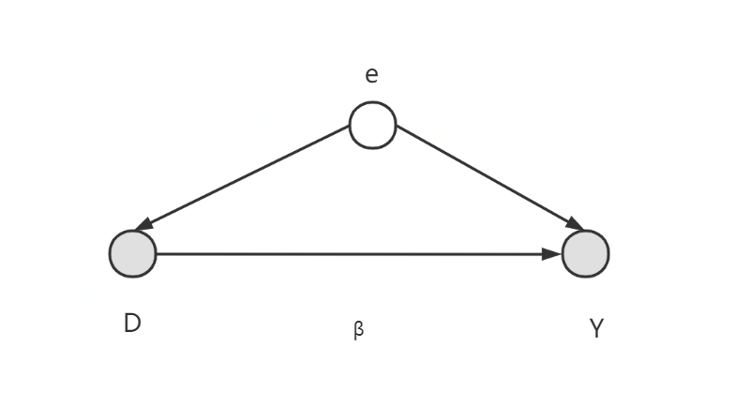
在此种情景下,有D到Y的因果路径,也有干扰项E所带来的混淆路径,因此需要截断。
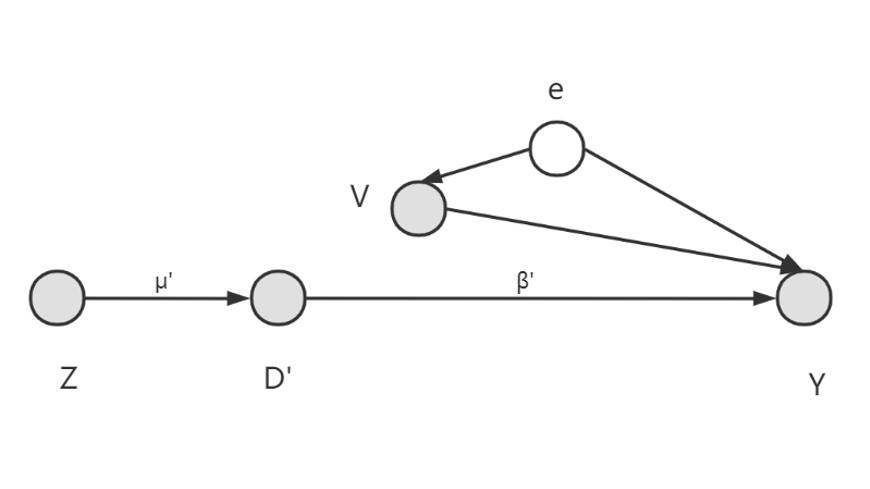
工具变量的整体思路是引入一个用于剔除被解释变量中与干扰项相关的部分。如上图所示,工具变量Z将原有解释变量D分为与干扰项不相关的D’和与干扰项相关的V,从而让D’独立于干扰项,可采用D’到Y的系数β作为解释变量D对于被解释变量Y的因果效应值。而要充当工具变量,需要具备如下两个前提条件:1.外生性:工具变量和干扰项不相关;2.相关性:工具变量和解释变量相关。
操作步骤:第一步、定义研究问题,描述机制并设置基本模型,对基本模型进行OLS回归,得到初步结果。第二步、寻找有效的工具变量:并利用原理、理论或常识证明变量的相关性和外生性。第三步、使用工具变量对模型进行估计,同时进行必要的统计检验(解释变量内生性检验-HAUSMAN检验/工具变量相关性、外生性检验)。第四步、将工具变量估计结果与OLS结果进行对比,理解结果为何有差异。
综上,在没有实验条件或在既往数据中,也可通过因果推断的方法去提高决策判断力,保证产品交付质量。
本文由 @鲤鱼说 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


