
 起点课堂会员权益
起点课堂会员权益决策引擎——决策流路径规划的方案演进
决策引擎是整个风控系统的大脑,承载着风控策略编排和计算的任务,对决策的耗时与精度有着严格的要求。本文以决策流执行路径实现方案为切入点,探讨决策引擎高效执行的基本原理,一起来看一下吧。
决策引擎是整个风控系统的大脑,承载着风控策略编排和计算的任务,对决策的耗时与精度有着严格的要求,同时业务部门对数据源成本也有一定程度考量。网上介绍决策引擎通识的文章有很多,这里不再赘述,本文主要以决策流执行路径实现方案为切入点,探讨下决策引擎高效执行的基本原理。
一、背景
决策流的编排能力,可以满足策略运营人员对当前风险场景下的防控策略部署的灵活、高效。
“灵活”往往意味着不可控,从开发经验来看,产品的功能在既定的范围内,基本不会出现不可控的问题(除非是 BUG)。像 SQL 查询语言,对数据分析人员来说非常的灵活,抽象的语法可以满足任何数据组装查询组装需求,但此时危机正在蔓延:随时可能出现一个慢查询导致性能问题!
“灵活”和“高效”往往在程序内是互斥的,足够的灵活,往往是牺牲一定的效率得到的。产品与研发人员能做的,就是在两者中博弈,找到最佳平衡。
二、决策流执行演进
以下是策略运营人员配置的较常见的决策流图:

流程图看似简单,但是在实际执行程序执行过程中会遇到各种各样的问题和挑战,根本原因还是上下游业务对风控决策执行的耗时有严格的控制要求。
方案1:串行执行决策流
此阶段就像一个工作审批流,从开始节点一步一步的往下串行执行,直到终点。决策过程中,完全依赖节点路径的复杂度,假设一个节点的平均耗时为 100ms,那么如下红色执行路径需要耗时 500ms。

500ms 对风控来说是比较奢侈的,整个业务线一次请求耗时可能大半时间都被我们消耗掉了,这显然是不能接受的。可以想象,随着业务场景越来越复杂,策略人员对决策流的编排复杂度越来越高,导致整个决策流的决策路径越来越长,耗时呈线性增长,这种技术实现方案肯定是不能接受的。
总结:
1)优点
- 所见即所得,不会多执行也不会少执行;
- 串行执行对程序调试和日志友好,方便调试。
2)缺点
- 性能极差,策略人员可能无法接受。
方案2:并发执行决策流
活干不完,咱就堆人。同样的,一个线程干不完的,咱就堆线程并发计算。
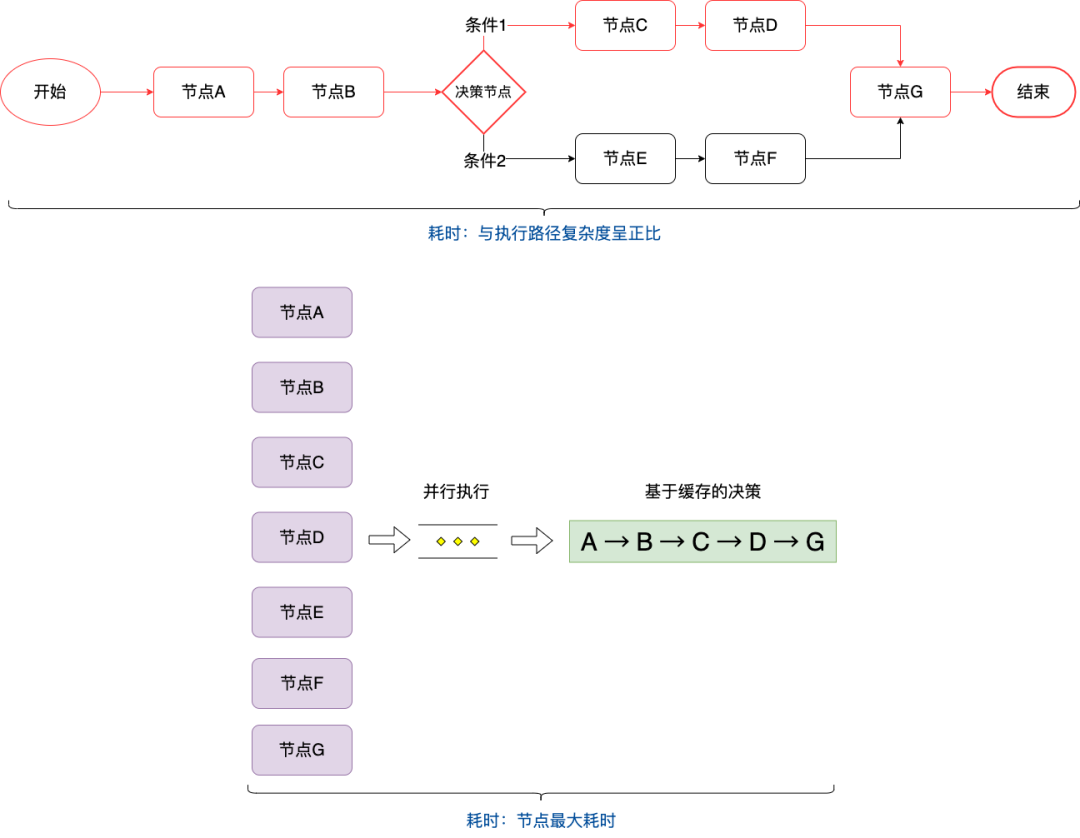
本着空间换时间的思想,预先将决策流内的节点全部预加载完成,将结果缓存住,真正执行决策流的时候,请求缓存直接计算执行,大大节省了决策时间。
此时影响决策性能的卡点在最耗时的那个节点,只需集中人力解决掉这个节点的性能问题就能降低决策流执行时间了。
总结:
1)优点
- 性能一流,空间换时间,最大化地提效。
2)缺点
- 算力很大:所有节点都并发请求,对下游系统的负载要求很高;
- 浪费巨大:当笔请求决策在节点 A 就被拒绝了,但是后续所有节点都计算了一遍,很浪费;
- 成本高:又比如有些收费节点,提前调用了,但是并未使用,成本极大;
- 未考虑节点依赖问题:假设节点 C 依赖 节点 A 的结果,此处会导致并发加载节点 C 时没有相应的入参而出错。
方案3:依赖分析&并行
方案二除了不考虑成本问题外,最大的痛点在于依赖关系问题,这是致命的。此时需要在运行时动态分析决策流节点之间的依赖关系。
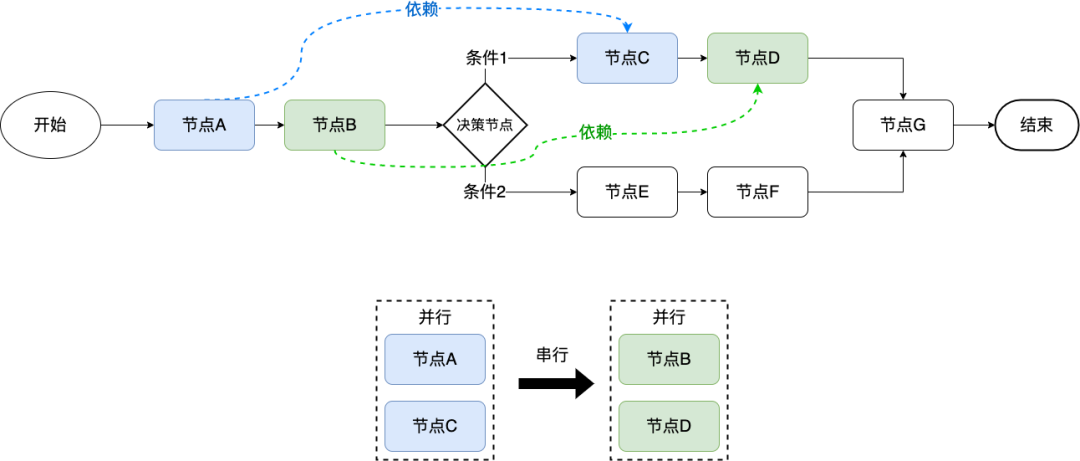
从图中可以看出,节点 C 依赖节点 A,节点 D 依赖节点 B,其它节点相互不依赖,那么此时可以通过依赖分析出节点与节点之间的分组关系,通过分组头结点先后顺序串行执行。
节点依赖分析:
那么如何实现节点的依赖分析及先后执行顺序呢? 流程图本身可以就是一个DAG(有向无环图),节点执行的先后顺序可以用BFS(广度优先遍历)遍历出一维数组,然后遍历分析每个节点的入参和之前的节点的出参是否有关联,有关联的归并到之前节点组链表的“尾巴上”,否则即为不依赖,可并行执行。
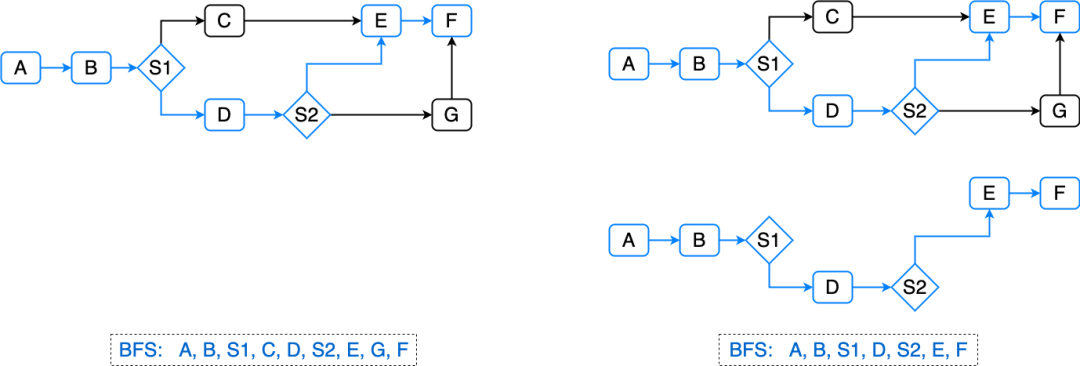
此时整个决策流执行耗时情况如下:
决策流执行耗时 = 并行组1耗时 + 并行组2耗时 + … + 并行组 N耗时
总结:
1)优点
- 解决了决策流中并行处理中前后依赖问题。
2)缺点
- 对策略人员的配置有一定的要求,需要尽量规避掉依赖关系,或者减少依赖分组;
- 依然没有解决方案 2 的成本问题,每个节点还是加载了一遍,算力浪费严重。
方案4:路径预测&动态剪枝
方案 2、3 都是全量并行加载各节点数据,对算力和成本的消耗是巨大的,实际在运行的过程中,公司在成本这块肯定是不能接受的,可能资损召回都不定能抵得上服务器和外部资源的开销。
通过分析决策流图,可以发现,分流节点的功能是排它,即决策数据流向只会选择一条路径执行,那么此时我们能在并行执行之前确认哪些路径在当次决策请求中不会经过,则可以排除掉不会经过路径上的节点,从而减少不必要的算力和成本。
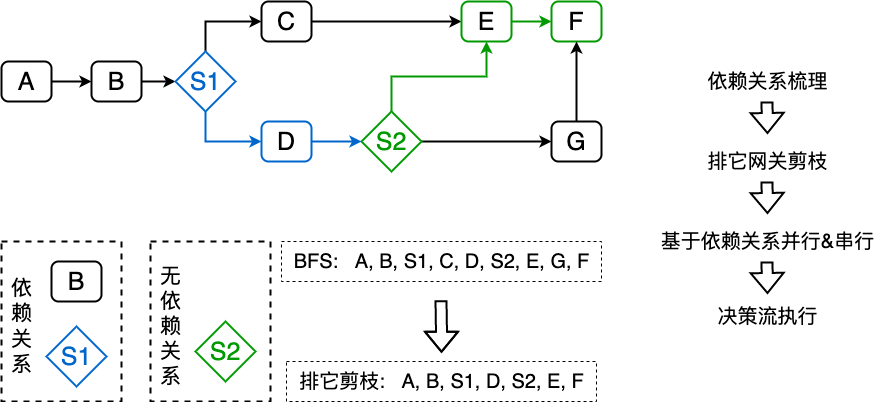
排它网关剪枝如上图,优先找出排它网关节点 S1, S2,分析入参是否依赖上游节点,此时 S1 依赖节点 B,S2 无依赖,则可按照排它节点分组并发执行决策出排它路径,此时 S1 节点对应的节点 C 被“剪枝”,S2 节点对应的节点 G 被“剪枝”。
总结:
1)优点
- 算力最小化,只并发加载行进路径中的节点算力。
2)缺点
- 行进路进中的节点未考虑成本问题,可能在前置节点已经拒绝,后直接点算力浪费。
方案5:饿汉式&懒汉式
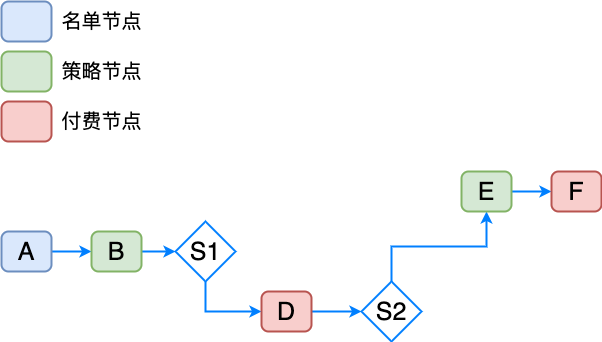
按照方案 4,已经解放了一大部分不会走到分支的算力,但是在正确的决策路径上,依然存在浪费,举例如上:
A 节点是名单节点,如果命中名单,直接通过或者拒绝,后续节点并行加载都是浪费的,节点 D 和 节点 F 都是付费节点,并发调用,成本极高,可能在途中就被拒绝而未实际用到付费结果。
此时,需要标识出付费节点(或者任何需要控制资源的节点),改为懒加载模式,即在前置并发加载所有节点时剔除懒加载节点,在决策流路径真正执行到该节点时再去计算,确保调用了一定是有效的,此时,构建节点时需要区分设置节点类型是饿汉式or懒汉式。
总结:
1)优点
- 基本规避了上述方案涉及到的问题,在最大化利用率和性能之间取得平衡。
2)缺点
- 决策流的编排需要通力合作,导致性能问题的点可能随着编排而山下浮动,需要异动监控机制。
三、总结
本文梳理了决策引擎编排决策流过程中为了提高决策性能和节约成本上做出的一些列优化方案,针对不同的场景,可自由选择激进的方案 or 性能和成本兼顾的方案。
最后啰嗦一句,脱离规划的设计再好,也未必能能真正的落地,这就对产品经理的产品规划能力提出了极高的要求,产品经理一定要从实际出发,充分资源、环境与体验等因素,制定切实可行的方案。
作者:王小宾;微信公众号:一起侃产品
本文由@并不跳步交叉步 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


