
 起点课堂会员权益
起点课堂会员权益深度解析 | 垂直搜索引擎构建:一个例子(下)
搜索引擎可以分为三类,元搜索引擎、综合搜索引擎、垂直搜索引擎。元搜索引擎使用场景较少,综合搜索引擎逐渐成熟,而许多垂直搜索引擎发展却参差不齐。一方面,身处垂直行业的企业更关注业务发展,较少关注产品算法和策略。另一方面,网络上关于搜索引擎的功能设计的文章汗牛充栋,而对搜索引擎的策略设计阐述却是不常见。针对这种现象,本文将以互联网房产为例,分享垂直搜索引擎的构建策略和基本框架,希望可以为后来者带来一些启发。

前文简要介绍了房产垂直搜索引擎的含义、特点和作用,随后叙述了房产搜索引擎的框架搭建,包括query分析、召回策略等。有兴趣的读者可以通过点击下方链接查看。
在本文,我们将介绍垂直搜索引擎的排序策略、效果评估等内容,通过本文你将了解垂直引擎的排序和评估方法大致框架。
一、排序
在进行搜索引擎优化项目时,读者可能会遇到各种关于排序的文章,内容纷繁复杂,让人眼花缭乱,不知所措。因此,作者对工作中的经验和相关论文进行回顾,梳理了排序的大致框架。希望通过下面的阐述,能够揭开排序领域的一角,为读者在工作和学习上带来帮助。
1.1 排序简介
排序是对召回数据按照一定规则重新排列的过程。排序对搜索、推荐和广告的效果有着直接影响,好的排序可以提高用户体验和广告收入。
排序的发展历程经历了多次迭代,可以概括为三个阶段:
- 统计阶段:该主要采用一些静态得分或统计指标作为规则进行排序。在此阶段,我们通常会使用一些基础的统计指标或者规则,如TF-IDF、PageRank等,对数据进行初步排序。这些算法或规则还会使用一些统计指标,如关键词匹配、item评分等作为排序依据。
- 机器学习阶段:我们也可称之为机器学习早期阶段。该阶段模型较为简单,参数较少,有一定个性化推荐能力。在早期的机器学习阶段,主要将LR(Logistic Regression)、GBDT(Gradient Boosting Decision Tree)、FM(Factorization Machines)、RF(Random Forest)、XGBoost(eXtreme Gradient Boosting)等机器学习算法应用到排序策略中。该方法主要思路是利用业务数据和业务指标(如CTR)训练高表现的排序模型,可以简单理解为:求解CTR和Item关系的(局部)最优拟合函数,从而使更有可能被点击的Item排在前列。
- 深度学习阶段:深度学习属于机器学习的一个新领域,深度主要体现在使用多层神经网络训练,它也是机器学习的一个领域 。因为其与传统机器学习有着不同的特点,在此单独作为一个阶段进行叙述。该阶段主要使用深度学习(部分企业也使用了强化学习)进行排序,代表模型有:DNN(Deep Neural Network)、DSSM(Deep Structured Semantic Models)、FNN(Feedforward Neural Network)、PNN(Probabilistic Neural Network)、NFM(Neural Factorization Machines)、AFM(Attentional Factorization Machines)。
深度学习思路本质上与机器学习类似,但其不同之处在于参考了人脑神经元结构,引入了多层神经网络,从而提高了函数的拟合和泛化效果。此外,深度学习还可以降低特征维度,淡化物品的表征能力。
从上述三个发展阶段可以看出,排序的发展路径为:单一数据特征表示 → 多元数据特征表示 → 低维密集向量表示。这些阶段都是将用户、物品、查询等数据转换为向量表示,并通过学习来实现排序的业务目标。
1.2 排序流程
排序可以按照流程分为粗排、精排和重排三个阶段。
1.2.1 粗排
粗排是使用一定策略,对召回数据进行大致排序,对候选集进行初步筛选,以减少计算量。通过粗排,我们可以减轻精排的压力,并提高排序效率。由于粗排是对召回数据的预处理过程,因此也被称为预排序。
粗排需要快速从海量数据筛选出较高质量的数据,因此不能使用过于复杂的模型。在此我们主要介绍几种经典的方法。
(1)基于统计规则的静态商品质量评分
该方法主要采用一些静态指标,使用一定函数给item打分,从而进行排序。评分依据之一是query和item关联度,如使用TF-IDF、BM25等方法计算item重要程度;其次是item特征得分,包括:
- item属性评分:如房源户型评分、交通评分、生活配套评分、房源发布时间等;
- 用户行为评分:包括房源的CTR、点赞率、收藏率等
- 作者评分:在一些行业,例如短视频领域,作者账号的权重也会被考虑在内。这些权重包括关注量、认证情况、平均完播量、平均点赞量、平均收藏量、平均转发量等等。通过进行加权计算,高得分的账号将会排名靠前。
通过评分,可以将高质量的item排在前列。不足的是,该方法通常使用离线计算,无法及时更新。同时,它也未能反映用户个性化特征,使得排序结果加重了马态效应,降低了长尾item的曝光量。
(2)LR(逻辑回归)
逻辑回归虽然名称中包含“回归”二字,但实际上它要解决的是分类问题。逻辑回归包含线性回归和非线性转换两个部分,通过将线性回归的输出通过一个非线性函数(通常为 Sigmoid 函数)进行转换,将其限制在 0 到 1 之间,以表示概率,将概率较大的item排在前列。
以房产搜索引擎为例,假设我们需要预测房源广告是否会被用户点击。每条房源广告只有两种可能的结果:被点击或未被点击,这是一个典型二分类问题。
我们可以考虑将两方面的特征作为输入:①与房源相关特征,如房源类型、面积、户型、建造年份、价格等。②此外,我们还可以考虑用户行为特征,如用户搜索历史、浏览历史、点击历史等。然后将CTR做为输出。
通过模型训练,我们可以将房源得分控制在0~1之间。同时,以0.5为阈值,将0.5分以下数据进行剔除,并按得分进行排序。从而提高房源的点击率
可以看到该模型引入了用户特征,既提高了房源点击率,也使搜索结果更加个性化。
(3)DSSM
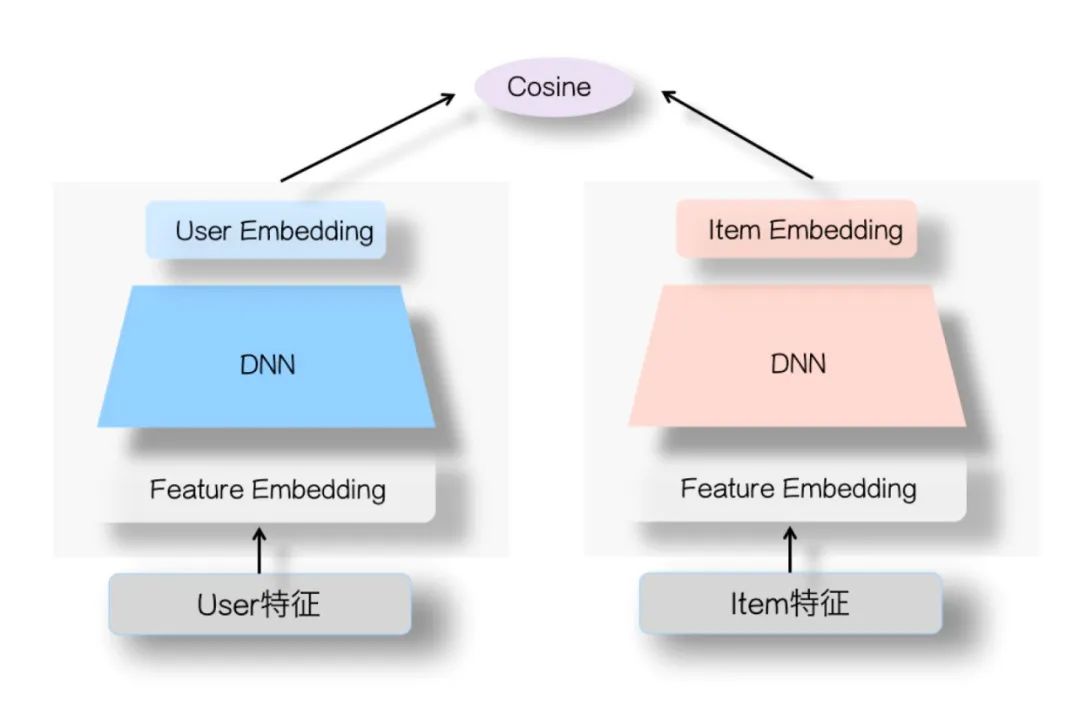
DSSM(Deep Structured Semantic Models)又称为双塔模型,该方法是一种深度学习方法,可以用于学习query和Item之间的语义相似性。它通过神经网络模型将它们表示为连续的低维向量,使得具有相似语义的query和ietm在向量空间中靠得更近。DSSM 最初是为了解决 Web 搜索中的query-doc匹配问题而提出的,但它在其他自然语言处理任务,如推荐系统、文本匹配等方面也有广泛的应用。
在房产搜索引擎中,我们可以使用 DSSM 模型来匹配query和房源,以找到与用户query最为相似的房源。
我们可以通过以下步骤来实现训练:
①通过对用户query的分析(参考本文前文),将用户查询做query分析预处理后,可以使用CBOW(词袋模型)、 word2vec 等方法将query和房源结构化表示为向量。
②构建神经网络模型(如MLP),分别对query和房源信息进行编码。该神经网络将二者表示为连续的低维向量。通过训练,模型可以使query与相似的房源在向量空间中更为接近。
③训练好后,我们可以通过训练好的 DSSM 模型,对给定用户的查询和房源描述进行编码,计算它们在向量空间中的相似度打分。然后,根据相似度打分对房源进行排序,将最相关的房源推荐给用户。
使用DSSM可以匹配query与之关联最高的房源,可以保证粗排数据的质量。DSSM需要高质量的训练数据和大量计算资源。在工作场景中,可按需要进行处理。
例如,当用户的query=“chaoyang两居二手房”,若分析器处理结果为实体属性,如{Region:’朝阳’;House Type:’二居’; House Status:’二手房’}。此时我们可将其处理为业务向量,与结构化房源进行相似计算,按相似度进行排序,也可以取得不错的效果。因此,在实际应用中,根据具体场景和需求选择合适的方法是十分重要。
(4)个性化模型
个性化排序模型,又被称作“千人千面”。它基于用户特征和行为数据,对搜索结果实施个性化排序,以更好地满足用户需求。具体而言,该模型可根据用户的个人属性、行为属性、偏好属性等特征,对搜索结果进行个性化排序。
例如,对于一个搜索“北京市二居室”的用户来说,如果该用户历史多次搜索过三环内的房源,那么搜索结果中三环内的三居室房源将会被优先展示。这种排序策略可以满足用户个性化需求,提升用户体验。
(5)多目标模型
在房产搜索引擎中,排序不仅要考虑相关性,还要考虑多个业务目标,例如展示尽可能多的优质房源、提高用户点击率、收藏率、咨询率和呼叫率等。
利用深度学习,可以训练将用户特征、物品特征、统计特征、场景特征作为输入,将点击率、收藏率、咨询率和呼叫率作为输出的模型,最后计算四个值的加权平均数。我们可以将该平均数作为房源的目标评分,进行排序。该方法考虑了多个业务指标,业务解释能力更强。
(6)实时特征排序
实时特征是指用户在搜索过程中产生的实时行为特征,例如搜索词、搜索时间、搜索历史等。这些实时特征可以用来调整排序策略,更好地满足用户需求。例如,如果用户在搜索“北京租房”后又搜索了“朝阳区”,那么在后续的搜索结果中,应该优先展示朝阳区的租房信息。
选取哪种方法需要考虑业务的特性和用户的需求,同时也需要平衡商业成本与ROI,从而选择最合适的排序方法。
1.2.2 精排
精排是指通过各种模型对数据做出精细化排序,提高搜索结果的质量。精排也可以提供个性化的结果,使搜索结果更加满足用户的个性化需求。
精排需要从粗排数据筛选出较高质量的数据。常规的排序模型LR、GBDT、FM等存在一些问题,如调整参数困难、过拟合(Overfitting)等问题。而使用深度学习或强化学习构建的模型,可以自动学习特征和调整参数,能够避免上述问题,提高排序模型的准确性。
1.LTR
随着互联网的发展,用户数据不断增加,计算机芯片算力也实现了很大的提升,这使得排序策略模逐渐向深度学习模型转移成为可能。使用深度学习进行排序通常称为学习排序,学习排序通常分为以下三种类类型。
(1)Pointwise:
Pointwise 将排序问题视为一个回归或分类问题。在这种方法中,我们对每个item单独处理,不考虑其他item的相关性。CTR方法就是一个典型的Pointwise方法,例如,在房产搜索中,为每个房源分配一个点击可能性得分,并根据上述得分对搜索结果进行排序。
(1)Pairwise:
Pairwise将排序问题视为一个二分类问题,强调两个item之间的相对顺序。在这种方法中,我们会对每对item进行比较,判断哪个item与用户需求更相关。然后,利用二分类模型(如SVM、GBDT等)学习这些特征对之间的关系,从而预测item之间的局部优先顺序。
以房产搜索引擎为例,对于每对房源,我们可以计算它们的特征差(如价格差、面积差、户型差等),并根据这些特征差训练一个二分类模型,预测输出房源相对顺序。最后,根据预测结果对房源进行排序。
(2)Listwise:
Listwise将整个搜索结果列表作为一个整体进行排序。在该方法中,更关注整个排序列表的质量,而不是单个item或item对之间的关系。通过训练模型,可以对所有item打分,根据item得分进行列表排序。Listwise方法通常使用NDCG作为评价函数,并基于此迭代排序模型。在房产搜索引擎中,通过输入无序房源列表,然后输出有序的房源列表。
该方法为代表的模型有Lamda 、Ada等。由于关注的是整个列表,该方法也通常更符合用户需求。但也存在数据标注困难、训练成本高等问题。
2.其他方法
近年来,随着精细排序进入深度学习时代,排序深度学习模型逐渐出现多个细分方向。
- 通过组合和交叉原始特征,提取更高级别的特征表示,帮助模型更好地捕捉特征之间的非线性关系,如FM、FFM、DeepFM、DCN等;
- 基于用户数据信息,捕捉用户兴趣和行为动态变化。代如DIN、DIEN、SIM等;
- 同时优化多个目标,如点击率和转化率等。这可以帮助模型在多个指标上取得平衡。如ESSM、MMOE、SNR和PLE等。
限于行文空间,上述模型的细节不作展开讲解,我们将在后续专栏其他文章进行阐述。
1.2.3 重排
重排是利用各种方式对精排数据进行重新排序,以实现搜索结果多样化、运营内容混排、流量调控等目标。
- 多样性:通过展示多样化数据,可以降低内容、品类单一等问题,提供内容异质性;
- 内容混排:如在房源列表中插入广告、视频/图文/直播内容、主题聚合等。
- 流量调控:流量调控可以看作是对部分特殊item流量进行控制,避免缺乏曝光和过度曝光。如常见的新发布房源冷启动、曝光保量等问题。流量调控实际上有许多问题需要注意,有兴趣的读者可以查阅相关内容进行阅读。
在本文,我们主要介绍以下几种重排方法:
(1)固定策略
固定策略是指在搜索引擎中,将某些内容固定展示在搜索结果的某个位置。比较常用的是方式是等距插值,如每4个房源后插入一条广告/素材/主题等。
(2)规则策略
规则策略是指根据业务方需求,对搜索结果进行规则性的调整。常见方法如下:
①根据类别排序,优先展示真房源、新上架房源、高评分房源等;
②排除不感兴趣、B端黑名单等;
③广告竞价:根据B端广告付费竞价,进行优先排序。房源的点击会直接影响竞价广告的收益率,间接影响客户的续费率。
(3)listwise
使用pointwise时,同一用户query,每个item在精排阶段都是独立的,可能存在召回item的特征相似,缺乏异质性。listwise方法主要思想:将用户原始query与所有候选item联系起来,用来关注上下文信息。考虑上下文因素,并进行重排。
值得注意的是,在排序方面需要注意排序的一致性,避免召回、粗排、精排、重排策略不一致的情况。在各个阶段使用矛盾的模型可能提高搜索结果的不确定性,降低排序结果的表现。
最后,对于排序而言,应避免陷入技术追求陷阱,认为搜索引擎如果没有采用 GBDT、DNN 等复杂技术,就算不上好的搜索引擎。
实际上,构建一个高效的搜索引擎应当关注业务需求和用户体验,适当地根据实际场景选择相应的技术方法。比如,在某些特定场景下,简单的基于关键词匹配的排序策略可能就已经足够满足用户需求。此时,使用复杂模型,不仅浪费了宝贵的技术资源,还会降低搜索引擎的响应速度。
因此,在选择排序方法时,应该根据实际业务需求和场景来权衡,而不是过度追求技术复杂度。
二、搜索评价
如果没有科学的评价系统,我们很难衡量搜索引擎的好坏,也就难以改进系统,提升搜索性能。通过评价系统我们可以找到搜索引擎存在的问题或缺陷,提高搜索引擎的表现。同时表现较好的特征,我们也可以进行迁移学习。
2.1 搜索引擎的评价体系
搜索指标通常应该具备客观性、可测量性、科学性。也就是说,指搜索系统评价应尽量采用客观指标,这些指标是可以测量的,并且科学的反映了搜索系统的性能。
参考相关文章,我们将搜索系统的评价分为两个方面:①效率指标;②效果指标
2.1.1 效率指标
效率指标主要对搜索引擎时间性能和空间性能进行评价。主要关注响应时间、开销、索引量等指标。
- 响应时间:提交query到返回结果的时间。响应时间通常要求在0-100ms以内。由于搜索容易受到网络、设备等因素影响,计算时通常采取多次搜索的平均响应时间
- 开销:主要指系统占用的内存和外存空间。
- 索引量:用户可以检索到item的数量,索引的配置将影响搜索的执行时间。
2.1.2 效果指标
效果指标主要针对搜索结果效果评价而言,通常有以下方法:
(1)精准率
精准率 (Precision):搜索结果中相关item与所有item之间的比例。计算公式为:精准率 = 搜索结果相关item / 搜索结果item数量。例如,用户搜索京海市的房源,如果在前10个搜索结果中有8个与京海区相关,则精准率为0.8。
注意与准确率的区分,准确率=识别正确item/所有item数量。假设在数据库中,拥有100条item,与dog相关有60条,不相关的有40条。用户搜索返回50条(其中40条相关,10条不相关),那么:准确率=40+(40-10)/100=70%
所以,准确率=识别正确数/总样本数
注:40表示识别正确的数量(即正例识别正确40条,负例识别正确30条)
(2)召回率
召回率 (Recall):召回率是搜索结果中相关item与所有相关item之间的比例。计算公式为:召回率 = 相关item数量 / 所有相关item数量。例如,当用户搜索青华区的房源时,搜索结果中有40个相关房源,而数据库共有100个与青华区相关的房源,则召回率为0.4。
需要注意的是,当召回和准确率达到一定程度时,就会互为掣肘。继续要求更高的召回,必然会牺牲准确性,反之依然。使用如何衡量,需要依据实际场景决定。如在房源搜索中,要求召回更多的房源,需要降低query与item的匹配度,精准率也随之降低,反之亦然。
(3)F1分数
F1分数 (F1 Score):F1分数是准确率和召回率的调和平均数,用于综合评价搜索引擎的性能。计算公式为:F1 = 2 * (Precision * Recall) / (Precision + Recall)。使用调和平均数可以综合反映系统性能。
(4)P@k
对于海量的搜索结果,我们不可能根据所有结果计算准确率和召回率。因此,我们假设用户关注的是排序比较靠前(前k条)的item。P@k 是评估搜索引擎在前 k 个结果中相关item的比例。计算公式为:P@k = 相关文档数量 / k。当k=10或20,称为p@10,p@20。
(5)MAP
平均准确率 (Mean Average Precision, MAP):多个query在搜索引擎中准确率的平均值,该方法的假设前提是每个用户都期望找到相关的item。
5.MRR
使用p@k方法通过多次对query查询进行评价,降低了计算的复杂度,但也忽略了前k个item的排序质量评价。因此,我们引入MRR的概念。
假设用户首次查询海淀小学,搜索结果中第5条为关于相关的学区房源,那么得到的评价为1/5=0.2;用户第二次查询为“国家图书馆”,第2条就返回了相关的地标房源,我们将其评价赋分为0.5。那么MMR=(0.2+0.5)/2=0.35
由上可知,MRR 是评价搜索引擎对首个相关ietm的排序效果。计算公式为:MRR = (1 / Q) * Σ(1 / rank_i),其中 Q 是查询数量,rank_i 是第 i 个查询的首个相关文档的排名。
(6)nDCG
nDCG (Normalized Discounted Cumulative Gain):nDCG 是一种度量搜索引擎对于相关文档的排序质量。计算公式为:nDCG = DCG / IDCG,其中 DCG 是折扣累积增益,IDCG 是理想情况下的最大折扣累积增益。
这个公式可能看起来较为复杂,不过没关系。我们可以抽丝剥茧,娓娓道来。先从CG说起,CG(Cumulative Gain),累积增益,用来计算(排序后的)列表,有多少个item与query相关。
CG:
CG=Σrel_i,即与query存在相关性item的个数累加(个数为了方便理解,实际可能采用打分),下面使用一个例子来说明CG:
假设搜索结果与搜索相关则得1分,否则为0。若query=“西二旗”,返回结果listA= [城西,二手房,西二旗1居,西二庄,西二旗开间]。显然,CG=[0+0+1+0+1]=2
DCG:
其次是DCG,考虑上述搜索结果listB [城西,西二旗1居,西二旗开间,二手房,西二庄],它的CG[0+1+1+0+0]=2。显然listB比listA结果更好,但他们的CG却相等,这是不合理的。
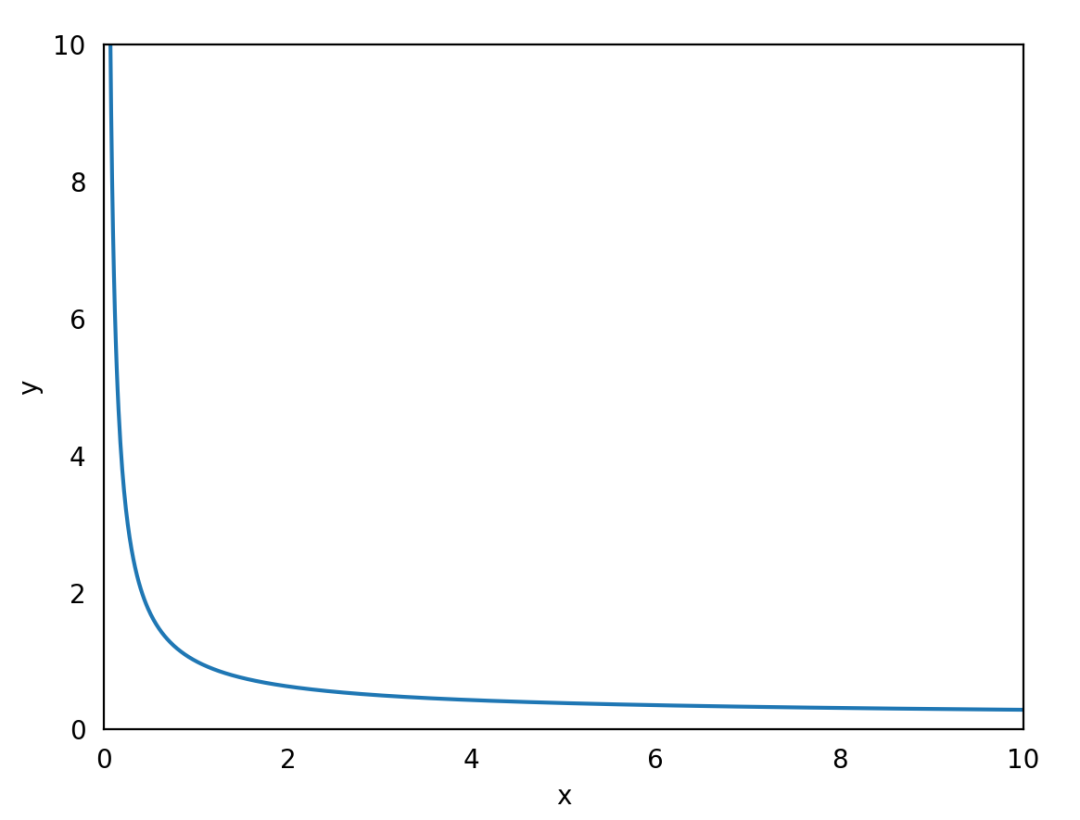
因此,我们考虑引入位置信息,使位置靠前的item得分更高,位置靠后的item得分越低。使用减函数f(x)*rel_i可以降低靠后item的得分。这里,我们使用的减函数为1/log2^(i+1),结合它的图像,应该可以轻松理解。
我们将调整后的CG称为DCG(Discounted Cumulative Gain,折扣累计增益),DCG=Σrel_i/log2^(i+1)。折扣累计增益通过求多次查询DCG的平均数,理论上可以得到较好的评价指标。
IDCG:
使用DCG进行打分真的没问题吗?举个例子。小兰在高考时,物理考了95分,数学考了135分。如何比较二者的成绩呢?如果我们直接比较原始成绩,可能会因为满分不同而导致比较不公平(读者可以简单思考一下解决方案)。
应该如何分析小兰的成绩呢?为了消除这种不公平性,我们可以将两门成绩都归一到0-1的范围之内。这样,不论是数学成绩还是物理成绩,都可以在同一尺度(得分率)下进行比较。我们将小兰物理成绩换算为95/100=0.95,数学成绩换算为120/150=0.90,可以发现物理比数学考的更好。这种处理方法被称为最大值归一化(除此之外,还有均值归一化、z值归一化,有兴趣的读者可以搜索了解)
同理,搜索引擎返回的item数量可能或多或少。比如query=“开间”时,可能只返回3条数据。这时,返回3条结果和5条结果下的DCG,他们的分数计算标准不同,直接比较DCG分数大小就不太妥当。因此我们需要计算每条搜索结果能获得DCG的满分,再使用DCG/满分,得到DCG的得分比例。
我们将所有与query相关的item排在前面,如query=”西二旗”的搜索结果listA =[城西,二手房,西二旗1居,西二庄,西二旗开间],将结果调整为[西二旗1居,西二旗开间,城西,二手房,西二庄]时,可以得到DCG的最高分(对应的CG为[1,1,0,0,0]需要乘减函数计算DCG,只有排在前面才能获得最高分)这个最高分就是IDCG(Ideal Discounted Cumulative Gain,理想折扣累积增益)。
nDCG:
通过归一化可以得到nDCG的公式:nDCG=DCG/IDCG,NDCG是一种衡量搜索结果质量的指标,它考虑了搜索结果的相关性和排名位置。NDCG值越高,表示搜索结果的质量越好。
除了本文介绍的方式,还有其他的评价指标,如业务指标点击率、收藏率等。具体采用哪种评价方式,需要考虑实际场景。
三、总结
分词有助于更好理解用户需求,召回决定了搜索结果的上限,搜索排序是搜索结果精细化的好帮手,而搜索评价有助于改进搜索引擎。
本文讲述了常见垂直搜索引擎的一些特点、作用,搜索引擎的分词流程,召回方式。排序之粗排、精排、重排等方法,随后总结了常见的搜索系统评价指标。
希望对你有帮助~
本文由 @知一 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!


