
 起点课堂会员权益
起点课堂会员权益搜索推荐系统中,重排模块的定位以及常见策略
在推荐搜索系统中,我们常常可以见到重排模块,那么你知道重排模块的作用是什么吗?在本篇文章里,作者就介绍了重排模块的作用,以及常见的重排策略,一起来看看吧,或许会对想了解搜索推荐系统的你有所帮助。

很多人在最开始了解搜索推荐系统时,不明白为什么还需要单独设立一个重排模块,重排模块和精排模块能不能进行合并。本篇我们就详细介绍一下重排模块的作用以及常见的重排策略。
一、推荐系统常见架构
我们先介绍一下目前行业里先进的推荐系统架构是什么样的,分别介绍各个功能模块的定位。
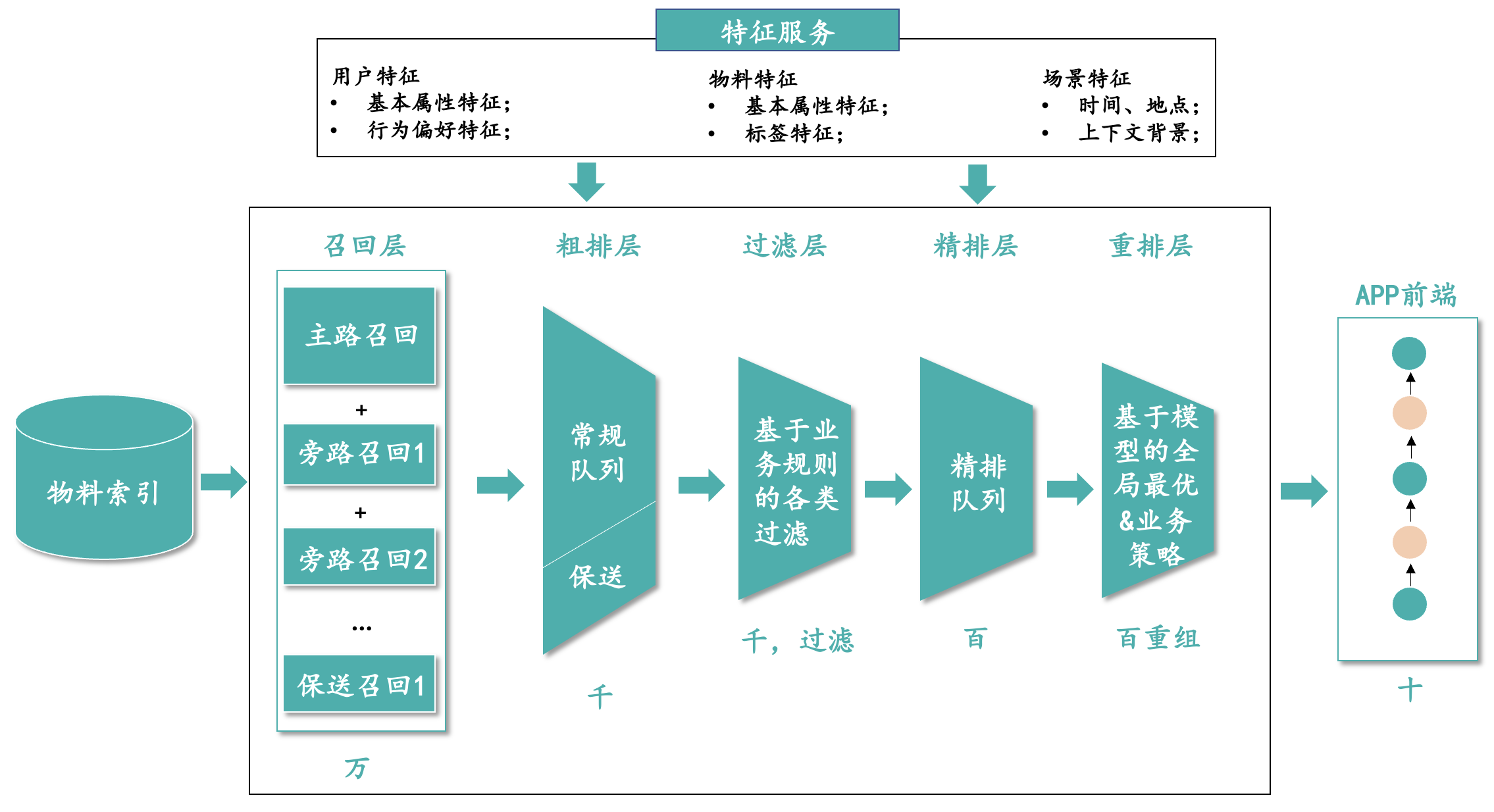
上图是目前工业界常见的推荐系统架构,整体系统链路上至少分为以下5层:
- 召回层:从亿级别的物料中初筛出用户感兴趣的物料,输出的物料在万级别,大幅降低物料量级,减少后续系统中的性能压力。一般都是多路召回架构,接近20路的召回策略。
- 粗排层:针对召回层返回的物料,预估召回点击率再进行排序,筛选出千级别的物料。
- 过滤层:基于一些硬规则过滤掉最后不能在前端露出的物料,比如内容领域命中了黑词、电商领域无库存的商品等。过滤层也可以放在粗排层之前。
- 精排层:将过滤层返回的所有物料进行CTR预估,然后按照Pctr进行排序,输出百级别的物料给到下一层。
- 重排层:重排层会基于全局最优和相关业务规则等对于精排返回的物料顺序进行再次调整,一般都只是微调。最终一次请求中返回在百级别以内的物料给到前端。
每一个模块都有自己的定位,早期的推荐系统就只有一个最简单的排序模块,发展到现在推荐系统架构已经非常精细化,不同模块各司其职。
二、重排模块的定位
在搜推系统的众多模块中,重排模块主要实现以下三个目标:全局最优 + 流量调控 + 用户体验。
1. 全局最优
精排实现的是单点最优,但是用户实际在浏览推荐信息流时是连续浏览多个商品。不同商品之间的排列组合将影响用户整体的点击率。
就如同人穿搭衣服一样,精排模块的视角,是单点为用户选择最好看的上衣、裤子和鞋子。
而重排模块是站在整体视角,为用户选择既好看然后风格又匹配的最优的上衣、裤子和鞋子的组合,所以重排模块最终需要在精排的排序基础上,按照用户的浏览行为为其挑选出最优的一组商品或者内容组合。
2. 流量调控
重排模块是对物料的最后一道排序环节,很多时候业务的特殊流量诉求都是在重排模块进行干预。比如电商场景中对于新品的扶持,淘宝当年做直播生态时对于直播内容进行加权。这些特殊的流量诉求需要干预整体排序时,最好的实现方式都是在重排模块进行干预。
3. 用户体验
精排和重排整体的排序逻辑还是基于模型预估的CTR,但是有时候完全按照CTR大小来进行排序的内容会比较极端,比如连续多坑都是同一种类型的商品或者内容,导致用户审美疲劳,这种就是线上的问题案例,解决这类case都需要在重排模块做一些频控策略。
电商推荐里需要针对同三级类目、同品牌、同封面图的商品进行打散,内容推荐场景里需要针对同类型、同封面图、同作者的内容进行打散。打散可以有效防止用户审美疲劳化,同时有利于探索和捕捉用户的潜在兴趣,对用户体验和长期目标都很关键。
三、常见的重排策略
针对上述介绍的三大类目标,我们分别介绍实现三大类目标常用的策略。
1. 全局最优-List Wise策略
List Wise本身不是一个具体的算法或者模型,只是一个模型的优化目标或者是损失函数的定义方式,List Wise关注整个列表中物料之间的顺序关系,需要结合上下文的信息。List Wise整个策略分为两个步骤:
1)序列生成
第一步是序列生成。假设用户在浏览淘宝APP首页”猜你喜欢“时,平均每次浏览4个商品,那么我们设定每个序列的长度为4。序列生成模型基于精排模型返回的商品数量进行排列组合。假设单次请求中精排模型返回12个商品,那么序列生成模型理论上可以生成:
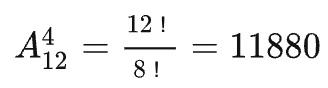
11880种组合,这个数字过于庞大了。为了减轻系统的计算负担和考虑到模型的耗时影响,实际工作中我们不可能穷举所有的序列类型,一般情况下我们还是会从精排模型中排序靠前的候选集中进行挑选,然后再设置一些策略性的筛选条件去大幅降低序列的候选集。假设我们就从精排返回排名前6的商品中,进行序列生成:
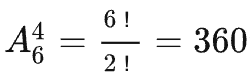
360组合。我们基于这360种组合再进行效果评估。
2)序列评估
第二步就是对生成的序列候选集进行效果预估,首先需要构建一个序列评估模型,目前序列评估模型中常用的算法是RNN(Recurrent Neural Networks,循环神经网络)。
RNN模型的一大特点是以序列数据为输入, 通过神经网络内部的结构设计可以有效捕捉序列之间的关系特征。所以RNN模型非常适合作为序列评估模型来实现List Wise。
首先序列评估模型的输入是每一个序列以及精排模型预估的CTR值,模型融合当前商品上下文,也就是排序列表中其它商品的特征,来从列表整体评估效果。序列评估模型最终是针对单个序列里的每一个商品输出一个对应的预估CTR,然后将每个序列里各个商品的CTR在一起加权最终得到一个综合的CTR分数进行排序。
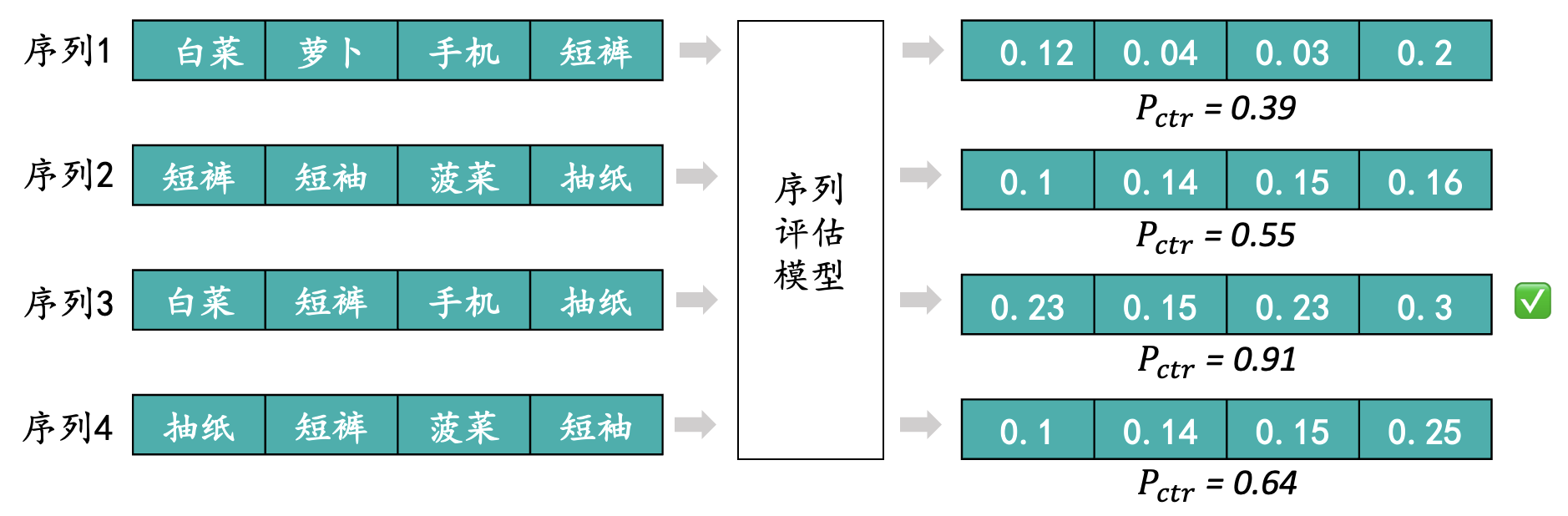
如上图所示,将四个相同长度的不同序列输入到评估模型中,模型针对序列中的每个商品重新给出新的Pctr,然后将单个序列里的Pctr进行相加得到综合分数,最终取得分最高的序列返回给到前端,如上图所示得分最高的为序列3。
需要注意的是序列评估模型仍然是预估CTR,只是此时的CTR预估是结合了上下文信息,而不是像精排模型那样仅是单点的CTR预估。不过序列预估模型也是对精排模型的Pctr进行微调,不会大幅调整精排模型输出的Pctr。
2. 流量调控—动态调权
流量调控的策略实现方式一般就一种,直接在重排层上针对需要获得更多曝光的内容比如新品、新内容等进行相应权重的调整,原本预估的CTR再乘以更高的系数分比如1.2,使其得分更高。加权可以快速让某一类型物料得到更多曝光。
有时候也可以在召回模块进行调整,比如针对某一类物料单独设计一路召回策略,提升召回侧的供给。但是毕竟召回侧离最终展现还需要经历很多个模块,无法确保最终一定可以展现以及展现量,所以一般都是召回和重排层同时做策略。
但是加权策略不能一直在整个流量分发机制中存在,当实现了业务目标后,我们需要重新审视线上的各种加权策略,然后下线一些加权策略,不然长久会破坏系统整体的生态。
3. 用户体验—滑窗打散策略
用户体验里我们主要介绍滑窗打散策略。目前市场上主流的打散策略都是基于硬规则的打散,也有基于用户个性化兴趣的打散方式,但是还是容易出Bad Case。
下面我们以电商同三级类目商品打散来进行举例,假设平台要求连续4坑同一三级类目商品最多只能有2个,连续8坑同一三级类目商品最多只能有4个。针对这类打散我们一般使用滑动窗口法。
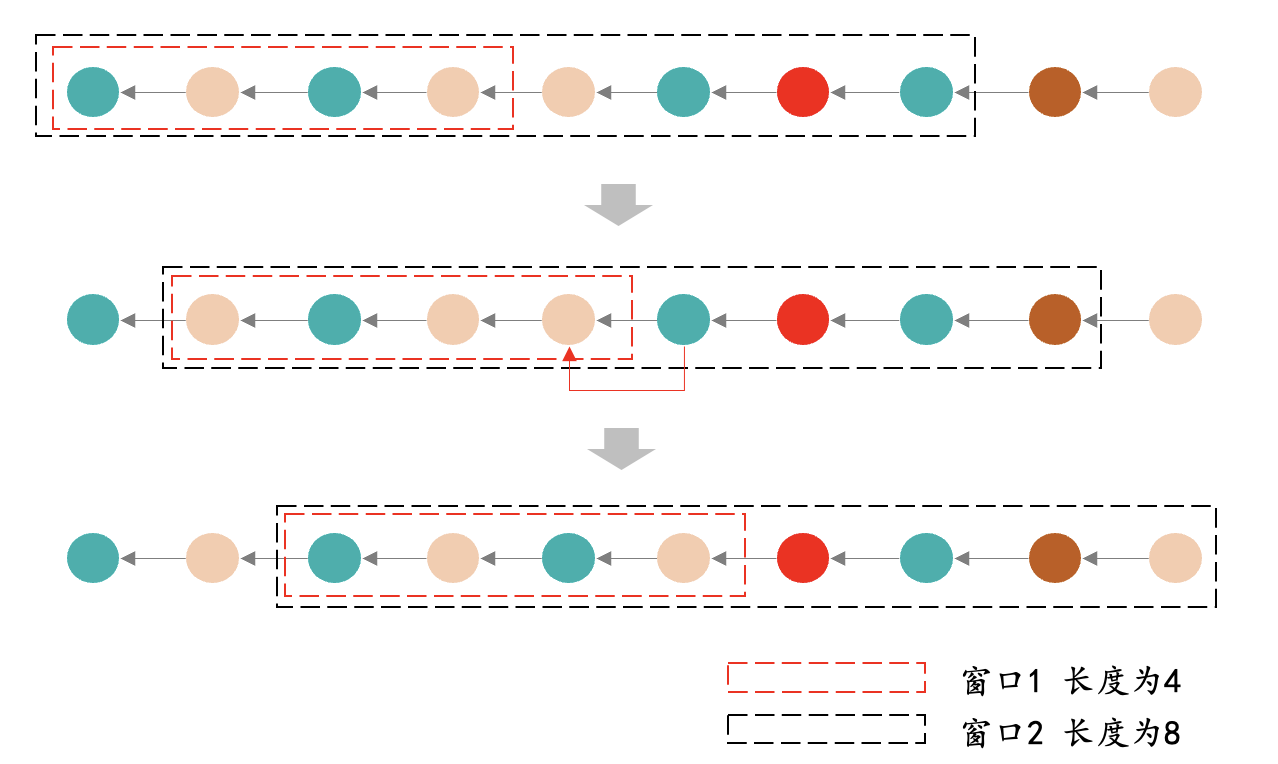
如上图所示,我们构建两个窗口,一个长度为4,一个长度为8,每个圆圈代表一个商品,不同类目的商品用不同颜色来表示。
两个窗口全部从第一个商品开始往后移动,首先判断窗口1和窗口2里的商品是否符合规则要求,如果符合则继续滑动窗口,经过第一次移动后我们可以看到窗口1里面商品的类目分布已经不符合规则要求,按照顺序将后面符合要求的商品往前移动进行替换。
按照上述流程一直进行窗口滑动,对位于窗口内不符合要求的商品进行顺序调换。
滑动窗口法容易出现末尾扎堆的情况,因为一直在用后续的物料去满足前序的规则,将不满足规则的物料进行后移,最终可能会导致末尾物料的顺序无法调整,因为已经没有后续候补物料可供调整了。
上述就是对于搜索推荐系统中重排模块的整体介绍,重排模块以其独特的定位为搜索推荐系统的精细化运作发挥重要作用。
专栏作家
King James,公众号:KingJames讲策略,人人都是产品经理专栏作家。算法出身的搜广推策略产品专家。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









大佬,请问你用的是什么画图工具?
PPT