
 起点课堂会员权益
起点课堂会员权益从0开始搭建产品经理AI知识框架:语音识别与合成

AI PM认知系列第三篇,字数:2300+,速读需4分钟。
从早期苹果的Siri,到最近国内的智能音箱大战,越来越多AI语音产品走入了大家的生活。
近几天我也在思考,相比已有更落地方案的计算机视觉技术,AI的语音技术在产品应用中的本质是什么?这个思考我也跟一些语音领域的专家探讨过,而其中我个人的理解是:
AI语音技术的本质,通过效率的提升,场景的便捷,重新定义了用户体验。
为什么我这么理解?那我们先来看看语音有哪些天然属性:
- 提升效率:一分钟400字的速度靠打字是无法超越的,所以特定行业,语音的技术可以大大的提升人机的效率。
- 操作便捷:解放了你的双手,除了一些基本的操作,无需要每个字都操作键盘或点击屏幕了。
- 学习成本:对于不认字的老人和小孩,可以用语音来进行检索和进行操作,对于不会拼音的人,也可以使用语音识别。
所以,以下AI语音相关的分享,会围绕两个方面:
- 语音技术:语音识别和语音合成
- 语音技术应用和未来思考
1.语音技术:语音识别和语音合成
1.1 语音识别:ASK
语音识别(Automatic Speech Recognition)是以语音为研究对象,通过语音信号处理和模式识别让计算机自动识别人类口述语言。
简单来说,就是让机器可以听得懂人话。
其中比较核心的部分是语音听写:就是将语音信息转化为文字信息。
中文语音听写的技术原理,如下:
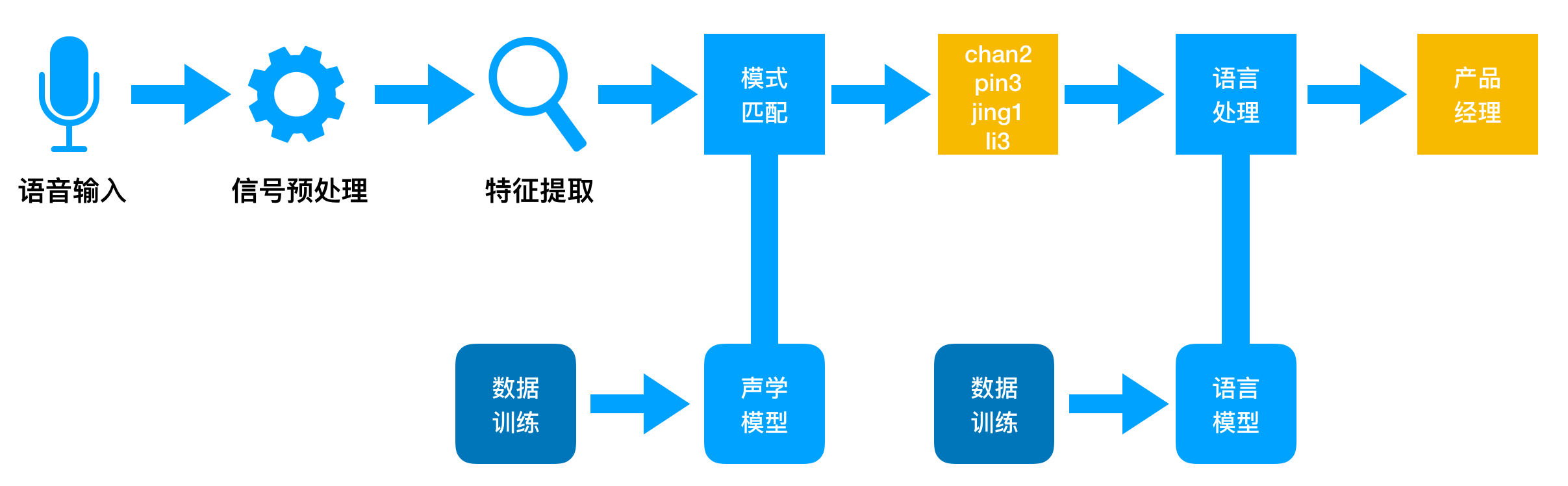
- 说出一段话,比如:「产品经理」,机器收到只是一段声波信号。
- 进行信号的预处理,如:降噪,消除回音…等。
- 特征提取,如:说了几个字,音调是什么…等。
- 通过声学模型匹配,输出“音”:chan2,pin3,jing1,li3。(拼音举例)
- 通过语言模型处理,最终得到文字:产品经理。
而这里的特征提取,声学模型和语言模型在技术实现上,有两种方法:
- 传统:隐马尔可夫模型(HMM)
- 端到端:深度神经网络(DNN)
目前语音识别技术主要是通过DNN实现的,特定场景下最高可以达到97%的识别率。
1.2语音合成:TTS
语音合成(Text-To-Speech)是计算机将自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术。
简单来说,就是机器讲文字朗读出来。
中文的语音合成技术原理,如下:
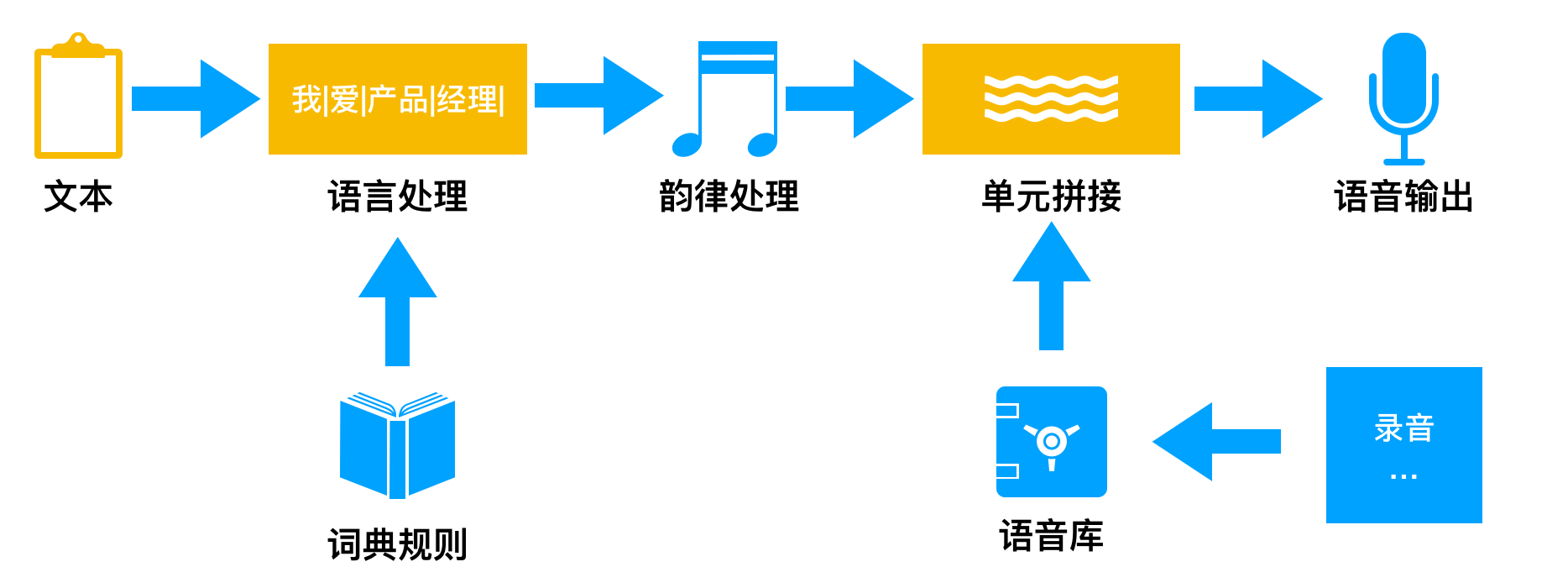
- 先通过规则把一段文字分词,如:我|爱|产品|经理。
- 把这段文字进行韵律的处理,标出是发什么音。
- 根据语音库的发音,进行单元的拼接。
- 最后就可以播放出这段语音了。
目前主要实现是两种方法:
- 拼接法:把录音的句子切碎成基本单元存储起来,再根据需要拼接起来。
- 参数法:通过录音提取波形的参数存储起来,早根据参数转化为波形。
拼接法的优点就是更自然,但是缺点是需要大量的录音,和存储。
参数法的优点就是存储小,但是缺点就是不够自然,听起来就是怪怪的机器发音。
另外谷歌发布的WaveNet是基于语音网络使用生成算法制作而成的,相对于以前的拼接法、参数法,在声音表现力上更具优势。
此外,语音合成的技术主要体现在四个方面:
- 表现力:不同年龄,性别特征以及语调,语速的表现,个性化。
- 音质:声音的清晰度,无杂音
- 复杂度:减少音库的体积,降低运算量及系统开销。
- 自然度:音律规则,间隔停顿。
目前的语音合成技术相对比较成熟,进一步优化的同时,大家的重点都放在了表现力上,以符合更多的场景应用,满足不同人对个性化的需求。
举个例子:
前一段时间,我打车时候看到司机师傅使用高德的语音导航,语音合成用的是一个小朋友的声音,我们就聊了起来,司机师傅说他才刚开始拉活,路不熟,他不喜欢郭德纲的声音,话忒多,他用小朋友的声音,一个是语速慢,另外一个是吐字清晰,不会因为听不清楚走错路。
这个就是在不同场景下用户对于表现力的个性化需求,因人而异。
1.3产品应用中涉及的语音相关技术
目前我们用微信语音或者是Siri时,都属于近场的识别,而智能音箱,车载设备,机器人的语音都属于远场识别,远场识别会受到,距离,噪音,混响…等问题,需要有其他的相关技术来配合完成,提高识别率。
麦克风阵列:由一定数量的麦克风组成,用来对声场的空间特性进行采样并处理的系统。用于在会议室、户外、商场等各种复杂环境下,解决噪音、混响、人声干扰、回声等各种问题。
麦克风阵列又分为:2麦克风阵列,4麦克风阵列,6麦克风阵列,6+1麦克风阵列。
随着麦克风数量的增多,拾音的距离,噪声抑制,声源定位的角度,以及价格,都会上升,所如如何选择要贴合实际应用的场景,找到最佳的方案。
举个例子:
猎豹小雅AI音箱,用的就是6+1麦克风阵列,因为要针对360度的3-5米的场景中使用。而很多家电,比如电视机都是贴墙放置的,2麦克风阵列的180度,就足够使用了。
而两者麦克风阵列技术要求和价格相差数倍。所以对于产品落地来讲,在提供解决方案的时候,选择最优的方案。
语音激活检测:在用微信时候,你会点击语音的按钮,来让语音开始识别。而在远场的时候,没有办法进行相关的操作,所以需要判断什么时候有语音,什么时候没有语音。
语音唤醒:通过关键词来唤醒你的语音设备,比如:嘿~Siri,这时候语音识别才开始工作。
语音唤醒难点在于,唤醒的响应时间,功耗要低,唤醒的漏报和误报率……等。
2语音技术应用和未来的思考
目前的语音识别技术,相对成熟应用还在近场语音:

而语音产品的未来方向的挑战:
- 远场语音:智能家居,车载语音…等
- 语音理解:与机器交互更“自然”的沟通
未来远场语音的场景比想象的更为复杂,虽然语音识别的相关技术在智能音箱的家居场景下表现的还不错,但家居环境毕竟相对安静可控,但是其他的远场语音就没有这么顺利了。
例如:
车载识别,在开车的环境下太多噪音,发动机的声音,打开车窗的风声,车胎声,路面声音,这些噪音都会影响到语音的识别。
而解决的方法,是要在识别之前,消除掉这些噪音,但这样就会产生一个问题,那么多种声音,机器怎么知道要消除哪些?保留哪些?
现在的方法是怎么做的? 扛着个麦克风,去各个车型里面录噪音,然后把各种车,各种场景下的噪音给机器去学习,让机器分辨出哪些声音是要消除的。但不同环境,路面,不同的汽车发出的声音又都不完全一样,有大量的工作和太多不可控的情况。
将来如果想在更多场景,比如酒吧,体育场,就会更复杂,除了环境音,还有更多人说话,比如“鸡尾酒效应”,所以未来的语音之路,会面临更多挑战。
语音的理解就涉及到另外一个AI技术了“自然语言处理”,目的是与机器沟通时候,它可以更好的理解你的意思,并给出相对的判断或反馈,避免像现在的聊天机器人出现的所答非所问,上句不接下句的情况,而有关自然语言处理,是一个更大的课题,也是AI目前的主要瓶颈之一,会再下一个分享中具体进行讨论。
以上就是我有关AI语音的分享,是AI PM认知系列的第三篇,如果任何的疑问或建议,欢迎随时沟通探讨。
相关阅读:
作者:兰枫,微信公号:蓝风GO @LanFengTalk,前腾讯游戏,新浪微博PM,Elex产品总监,8年的游戏,社交,O2O等产品相关经验,连续创业者。
本文由 @兰枫 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Pixabay,基于CC0协议









你好,阁下真实大名是?公司急招产品经理,可否取得联系。深声科技hrm-windy,公司主营人工智能语音识别与合成。工作地点广州天河区,如有意向烦请发简历至邮箱windy@deepsound.cn.或者添加微信weixinzhanlq.也有劳推荐人才。
ASR?