
 起点课堂会员权益
起点课堂会员权益传统编程,可能比我们想象中更早终结
当AI编程工具从辅助角色跃升为开发主力,传统编程的终结正在加速。本文深度实测Cursor、Claude Code等主流AI编程工具,揭示从54万行代码重构到复杂系统开发的实战经验。通过对比分析不同模型的编程能力差异,探讨AI时代开发者如何从代码编写者转型为任务规划师,以及如何通过规则设定、上下文管理等策略最大化AI编程效率。
整个25年真正运行的好的Agent,并且一直在稳定消耗Token的应该就是AI Coding品类了,并且他一直在不停告诉我:也许,编程的终结可能比我们的想象要来得更早!

而真实场景下,身边很多非科班的人(不会代码)已经直接真实使用AI结对编程完成了产品上线…
相应着,代码一直被认为是世界底层最真实、最本质的真相,所以AI编程可以说是各个大模型厂商都在布局的重要赛道;
对应着几乎每一次基础模型的更新,在AI编程的能力上都有大幅度的提升,不断的刷新我们对AI编程边界的认知。
几个月前我还认为:AI 在编程领域更多只能承担辅助角色,并不能完整的实现我们的业务需求,对整体的开发效率提升不到30%。像Cursor这类工具,使用主要的方式也是集中在Tab自动补全,代码解释、局部功能函数的实现,很少让他去完成一个完整的需求。
但是随着模型能力的持续迭代,尤其是Claude4.5和Claude4.6 Opus的出现,逐步改变我的认知,在当前AI编程已经成为编码的主力,我们在日常开发中已经很少手写代码,有90%的代码都是让AI去编写,而我们更多的是在做需求描述、任务拆解、架构设计、Code review等工作…
本篇文章主要就是分享当前主流的AI编程的工具、模型选择,以及我在使用AI编程中总结出来的一些实践经验,以帮助各位更好的进入AI 编程。
编程工具
下面表格中列举了国内、国外主流的AI编程工具,他们主要以编辑器IDE、CLI、插件的产品形态存在:
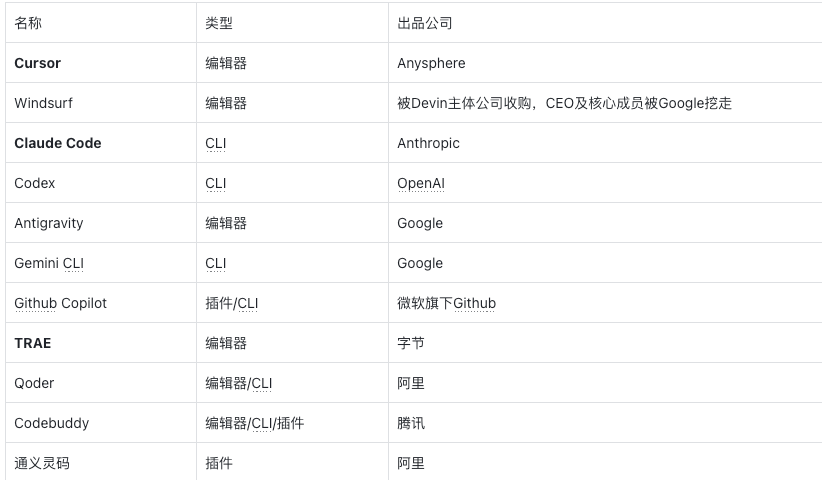
在众多AI编程工具中,Cursor是公认的好,是开发者群体日常使用最主力的AI编程工具之一,对于命令行偏爱的开发者,Claude Code 、Codex也非常受欢迎。
除此之外,国内也有一些不错的AI编程工具,比如字节的TRAE、阿里的Qoder,它们使用门槛更低,不需要魔法就能使用,只不过不能使用Claude系列的模型。
AI编程工具的演进方向,从最初的编辑器插件、到独立IDE、在到CLI,当前我们基本不在考虑使用插件,因为它的能力受到宿主编辑器太多的限制,当前更主流的使用方式是独立的IDE和CLI:

自从Claude code 爆火后,陆续很多AI编程工具都陆续支持了CLI这种形式,那么CLI相比IDE具有哪些优势?
1、Headless,更加通用,有命令行环境的地方都能跑
2、对于厂商来说开发维护成本低,第一:插件需要适配主流的编辑器,第二:开发独立IDE太重太复杂,而且程序员都有自己喜欢的编辑器,不容易迁移
3、更好的感知上下文及命令执行结果,方便进一步生成、修复或优化
所以,是不是有了CLI,就不用IDE了?
肯定不是,对于开发者而言,通常是两种方式相互结合使用,当然这里是根据自己的喜好自由组合,比如:我日常会使用Cursor + Claude Code,当然你用Codex + Claude Code都可以。
CLI更适合全程让AI写,人为介入更少,适合做一些复杂任务。而IDE的开发体验会更好,他具有可视化操作界面更加直观,更加适合人为介入较多的场景,比如:
1、AI写完之后,需要人工审查,要使用编辑器通过对比分析视图查看代码逻辑是否符合预期,方便接受或者拒绝单文件的修改内容
2、局部修改,具体到某个函数中的某几行代码,我们可以直接在Cursor中选择对应的行添加到上下文中,让AI修改
3、手动调整某些代码逻辑
因此,最佳实践是,在Cursor编辑器中开着命令行使用Claude Code:
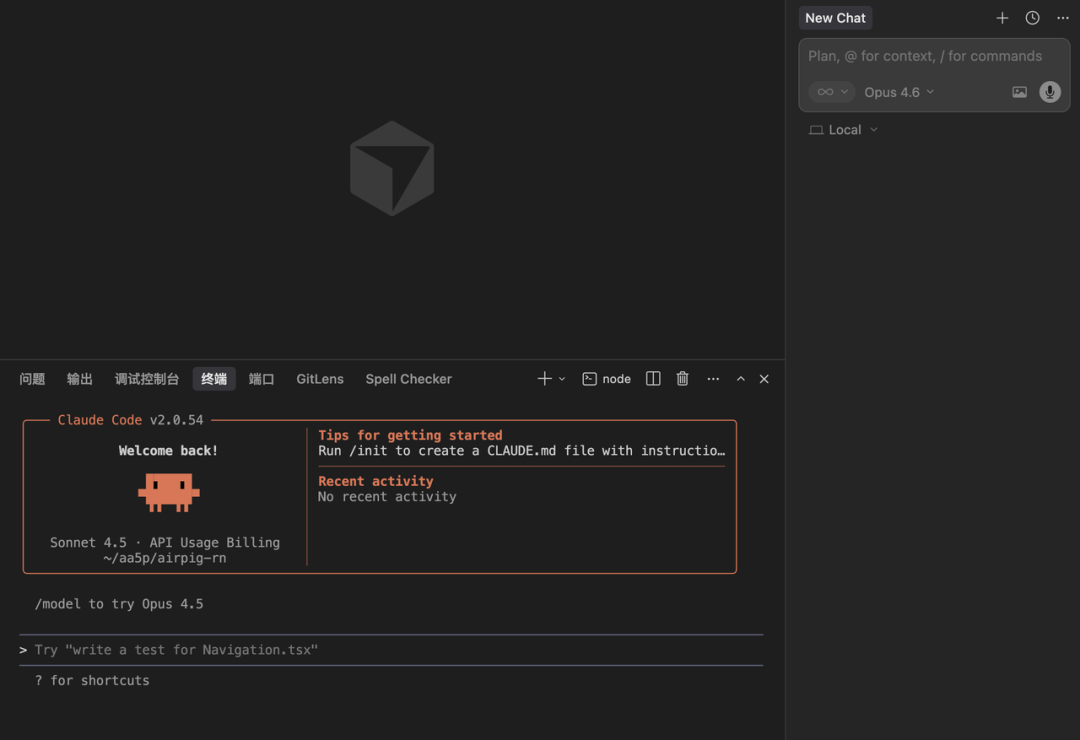
对于新手或者想要体验vibe coding的同学,不用太关注哪个更好、哪个更牛逼,选择一个能够快速使用的编程工具即可,比如Trae、Qorder等。
编程模型
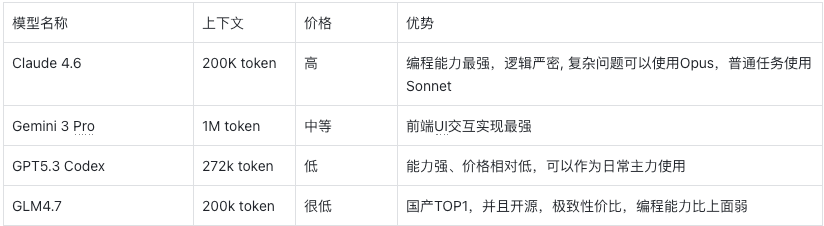
综合对比当前主流模型,可以从能力、价格与使用场景三个维度来做选择与决策:
首先是能力排名:整体表现上,Claude Opus 4.6 最强,其次是 GPT 5.3 Codex,再是 Claude Sonnet 4.6。
其次是价格梯度:GPT 5.3 Codex 成本最低,Claude Sonnet 4.6居中,Claude Opus 4.6 最高。
基于能力与成本平衡,模型使用策略建议如下:
1、日常开发与主流任务:优先使用 GPT 5.3 Codex 或 Claude Sonnet 4.6
2、高复杂推理或困难任务:直接使用 Claude Opus 4.6
3、前端复杂UI交互实现使用用Gemini 3 Pro
当前编码能力最强的模型仍然是Claude4.6系列,有条件的直接用最顶流的模型,可以减少调试和修复成本,省很多的事情。
如果对于价格敏感或者有数据安全方面的考虑,也可以使用国内大模型,比如GLM4.7、Kimi k2.5、Qwen3-Coder等,效果距离Claude4.5/4.6仍然有一定差距,但是满足日常任务开发基本没啥问题,算是性价比较高的替代方案。
我们在做模型选择的决策链路应该是:先确保数据安全与合规,其次保证生成质量,最后在看模型成本:
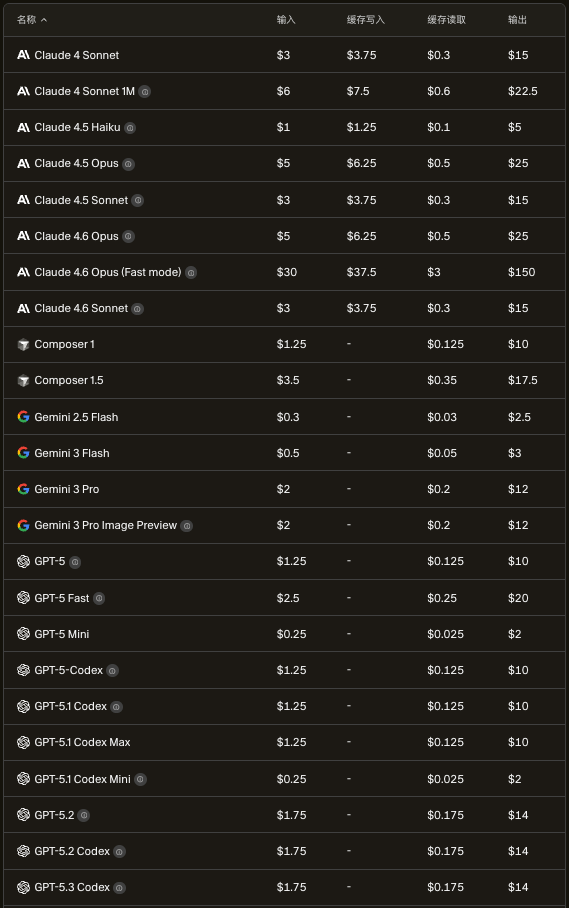
上图是来自Cursor官网,列出了每种主流模型的价格,针对输入、输出、缓存写入、缓存读取是不同的计费价格,从中我们可以发现,每种模型的输出价格最为昂贵,其次是缓存写入、输入,最便宜的是缓存读取。
除此之外,上下文窗口大小也是在某些场景下需要重点考虑的一个因素。这里上下文窗口是指 大模型 在一次处理中可以同时考虑的最大 token 数量(包括文本和代码),其中既包含输入提示词,也包含模型生成的输出内容。
Cursor 中的每个对话都有自己的上下文窗口。在一次会话中,包含的提示词、附加文件和回复越多,加入的上下文就越多,可用的上下文窗口就会被逐渐占满。
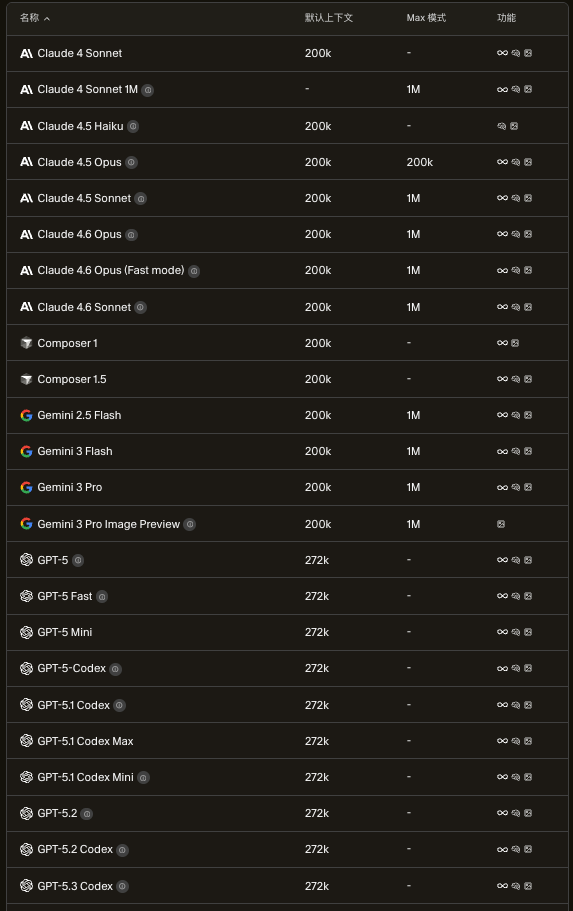
默认情况下,Cursor 使用 200k tokens(约 15,000 行代码)的上下文窗口。Max 模式会将少数模型的上下文窗口扩展到其支持的最大长度。
这样速度会稍慢、成本也更高。它对Claude4.6、 Gemini 2.5 Flash、Gemini 3 Pro尤其适用,因为这些模型具有超过 200k token 的上下文窗口
Token计算机制
我们知道不同 model 都有不同大小的上下文,上下文越大的模型自然能接受更大的提问信息,那么在 cursor 中我们的任意一次聊天,大致会产生如下的 token 计算:
初始 Token 组成:初始输入 = SystemPrompt + 用户问题 + Rules + 对话历史
用户问题 : 我们输入的文字 + 主动添加的上下文(图片、项目目录、文件)
Rules: project rule + user rule + memories
工具调用后的 Token 累积:cursor 接收用户信息后开始调用 tools 获取更为详细的信息,并为问题回答做准备:总 Token = 初始输入 + 所有工具调用结果
因此,我们可能只输入了一句很短的提示词,但是最终真实参与推理的 Token 可能高达数万,并且随着对话轮次增加,大模型输出的内容也会加入到上下文中给到大模型进行下一轮输出,跟滚雪球一样,上下文体积越滚越大。
接下来,我们介绍几个常见的编程工具:
Cursor
在基础环境上,Cursor需要先解决上网环境问题,一个是VPN,节点选择欧美区域,cursor中的network Http协议选择1.1,不能使用Http/2。
基于VScode二次开发,操作体验一致,插件生态共享,cursor支持把之前的vscode的配置直接导入过来,保留之前的环境配置。
模式
Cursor提供了四种模式供我们使用,它们的使用场景以及工具范围如下:

在对话框左下角我们可以手动切换,也可以使用快捷键,Shift+Tab切换模式。我们在让AI实现之前,需要先评估做的任务属于那种场景,选择对应模式后在执行。
建议:有时 Agent 生成的内容和我们想要的不一致,这种情况,与其通过后续提示一点点修补,不如重新把需求描述清楚。先回滚这些更改,然后把需求写得更具体、更清晰,再重新执行。这样通常比在中途修改更快,而且代码也会更干净。
对于较大的改动,多花一些时间制定一个精确、范围清晰的计划。最难的部分往往是先弄清楚应该做什么改动——这更适合由人来完成。给出合适的指令后,再把具体实现交给 Agent。
添加对话上下文
我们通过快捷键Command + L可以打开对话侧边栏,在输入框中我们就可以输入我们的要求,让AI去实现。
输入框中除了输入文本,我们可以使用快捷键 “@”选择更多的上下文信息,比如项目文件夹、文件、外部参考文档、命令行输出信息、Git分支差异等,具体如下:

除了上面这种方式添加,我们也可以通过直接拖拉拽文件或文件夹到输入框中,对于更加细粒度的代码,比如某个函数,我们可以选中这几行代码,手动添加到输入框中。
手动指定上下文是非常好的实践,它可以缩小修改范围,让AI理解更加精准,实现质量更高。
当然不指定上下文也行,但是并不推荐,因为实现效果相对更差,它需要依赖我们的提示词加入更多的精准描述,才能通过语义检索到对应的代码文件或代码块。
添加命令
在输入框中输入”/”即可唤起命令选择列表,这些命令通常是可复用的工作流,我们可以自定义,命令以普通 Markdown 文件的形式定义,可以存放在三个位置:
1.项目命令:存放在你项目的 .cursor/commands 目录中
2.全局命令:存放在你主目录下的 ~/.cursor/commands 目录中
3.团队命令:由团队管理员在 Cursor Dashboard 中创建,并会自动对所有团队成员可用
创建命令的步骤如下:
1.在项目根目录下创建一个 .cursor/commands 目录
2.添加一些具有描述性名称的 .md 文件(例如 code-review-checklist.md、create-pr.md)
3.使用纯 Markdown 编写内容,描述该命令应该执行的操作
4.当你输入 / 时,命令会自动出现在聊天中
commands 目录结构示例:
命令文档内容示例:# 代码审查清单## 概述全面的代码审查清单,用于确保代码质量、安全性和可维护性。## 审查类别### 功能性- [ ] 代码实现预期功能- [ ] 已处理边界情况- [ ] 错误处理恰当- [ ] 无明显 bug 或逻辑错误### 代码质量- [ ] 代码可读性好且结构清晰- [ ] 函数简洁且职责单一- [ ] 变量命名具有描述性- [ ] 无重复代码- [ ] 遵循项目规范### 安全性- [ ] 无明显安全漏洞- [ ] 已实现输入验证- [ ] 敏感数据处理得当- [ ] 无硬编码密钥
使用也非常简单:

忽略文件
项目中存在一些敏感文件,比如密钥、Token的配置信息,为了防止信息泄漏,这些内容我们是不希望被AI读取的,应该如何做呢?
我们可以在项目根目录中使用 .cursorignore 文件来控制 Cursor 可访问的目录和文件。默认情况下,Cursor 会自动忽略 .gitignore 中的文件以及下方默认忽略列表中的文件。package-lock.jsonpnpm-lock.yamlyarn.lockcomposer.lockGemfile.lockbun.lockb.env*.git/.svn/.hg/*.lock……
除了防止敏感信息泄漏之外,在大型项目或者monorepo项目中,我们通过排出文件,可以减少索引代码范围,可以加快索引速度并提高文件发现的准确性。
对于 .cursorignore 中列出的文件,不会被创建索引(即向量化),同时Cursor 会阻止以下访问来源:
1.语义搜索
2.Tab、Agent 和 Inline Edit 可访问的代码
3.通过 @ 提及引用 可访问的代码
需要注意的是:Agent 使用的终端和 MCP server 工具不会受到 .cursorignore 的限制,仍然可以访问代码。
因此配置信息最好不要放在代码中,最好在项目构建时动态注入,即使要放在项目中,务必做好账号权限管控。
并行Agent
在 AI Coding 的加持下,我们的开发效率明显提高。
我们通常需要同时开发多个功能需求,并且希望它们彼此互不干扰。传统做法就是为不同的功能需求创建不同的分支,但问题在于同一时间工作区只能切换到一个分支,无法真正并行。
为了解决这个问题,Cursor 推出了“并行代理”功能,允许我们在本地同时运行多个代理,每个代理都在自己独立的 worktree 中工作,可以各自进行编辑、构建和测试,完全互不影响。
这样一来,多个功能就能并行开发,同时我们也可以使用不同的模型跑相同的提示词,看哪个模型输出的效果最优,当然这个有点费Token,在复杂任务场景下可以尝试。
worktree 是 Git 的一项功能,允许同时使用同一仓库的多个分支。每个 worktree 都有自己独立的一套文件和变更。
下面举个例子说明:
基于分支feature/test-worktree-1修改内容:
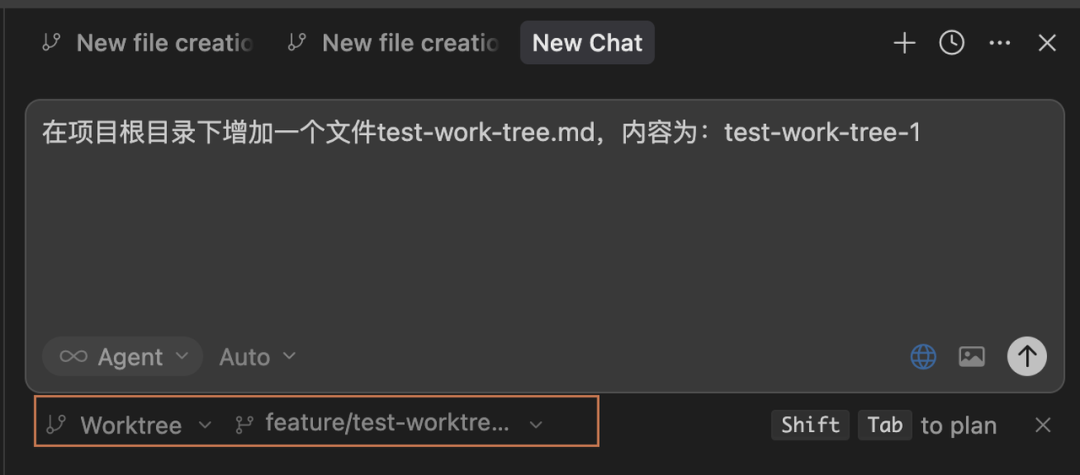
基于分支feature/test-worktree-2修改内容:
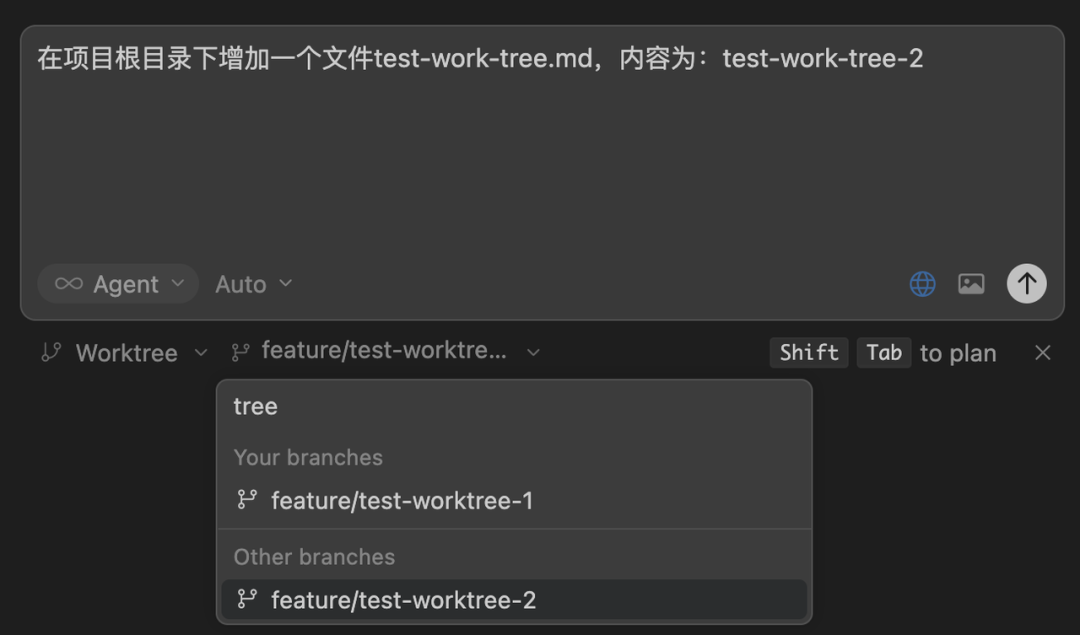
那么这两个agent任务就会在不同的工作区并行运行,彼此间不会影响,当 agent 运行完成后,点击“Apply”按钮,就可以将 agent 的更改应用到本地分支。
通过在终端运行git worktree list 我们可以看到其实是在用户根路径的.cursor目录下面创建了两个不同的工作区域,从而实现了并行运行且互不干扰,但是这种方式要注意磁盘空间的占用,使用完成后记得及时清理。

Claude code
前面我们介绍了Cursor编辑器的常见功能使用,这里也讲解下一下Claude code的基本用法,这个工具最近非常火,火爆的原因是它生成的代码质量高,并且有非常长的上下文,可以一口气完成长时间任务。
Claude code效果好我认为主要是两方面构成,第一用了最顶级的模型Claude,第二是Claude code在编码Agent的工程化能力很牛逼,这两个因素叠加才使其效果很好。
由于Claude code默认模型就是Claude系列,但是Anthropic公司禁止在中国使用Claude 模型,导致很多同学无法使用到Claude code,下面介绍如何在Claude code中使用其它厂商的模型,这里以GLM4.7接入为例:获取智谱提供的API-KEY
平台地址:https://bigmodel.cn/usercenter/proj-mgmt/apikeys环境参数替换
Claude Code支持供应商替换,把供应商的端点在环境变量里进行替换,然后把第一步拿到的密匙写进去。在Claude code中接入其它模型也是类似的做法,不过配置略有差异,具体查看模型厂商的接入文档,国内模型厂商基本都支持接入Claude code。export ANTHROPIC_BASE_URL=https://open.bigmodel.cn/api/anthropicexport ANTHROPIC_AUTH_TOKEN=“上面获取到的sk开头的key”
最佳实战
接下来我们看看ai 编程的一些最佳实践,这里并不局限于某种编程工具,而是通用的。
1. 设置Rules
Rules本质上是一种可复用的上下文机制,也就是在每次对话时都会把rule规则添加到提示词中。
在整个开发过程中,我们通常会总结出很多具有普适性的约束或偏好,比如:避免冗余注释、不要留下TODO等。
这类约束如果每次对话都重复说明,不仅效率低,也容易遗漏。因此,我们可以把它们沉淀为统一的规则(Rules),让模型在后续交互中自动继承和遵循,从而减少重复沟通的成本(时间+Token),并提升代码输出的稳定性。
比如,下面这些常见的约束就非常适合固化为规则长期使用:
1.不要留下 TODO,必须完整实现代码逻辑。
2.始终使用中文回答问题。
3.除非明确要求,否则不要生成测试文件或说明文档。
4.不要输出总结性段落。
5.始终遵循最小化修改原则。
6.具体的项目技术栈要求、代码风格、组件规范、架构设计等等
我们在编写这些规则时,也需要遵循一些原则,比如下面是Cursor提出的最佳实践:
1.将规则控制在 500 行以内
2.将较大的规则拆分为多个可组合的规则
3.提供具体示例或参考文件
4.避免模糊的指导,像写清晰的内部文档那样写规则
5.在聊天中重复使用提示时,复用已有规则
6.通过引用文件而不是复制其内容来使用文件——这样既能让规则保持简短,又能在代码变更时避免规则失效
规则中应该避免的内容:
1.整篇照搬风格指南:改用 linter。Agent 已经了解常见的风格约定。
2.逐条记录所有可能的命令:Agent 知道 npm、git、pytest 等常见工具。
3.为极少出现的边缘情况添加说明:让规则聚焦在你经常使用的模式上。
4.重复你代码库中已有的内容:引用标准示例,而不是复制代码。
然而设定好规则之后,我们也不能一股脑的让所有的规则每次都应用到上下文中,因为有些规则是在特定场景中才会使用。
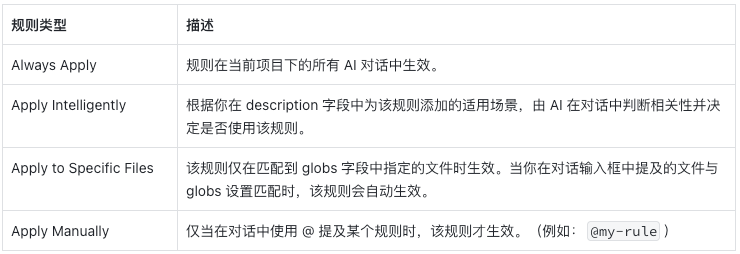
因此我们需要指定规则的生效条件,这里以cursor为例说明,cursor将规则生效方式分为了四种:
创建规则的方式有多种:
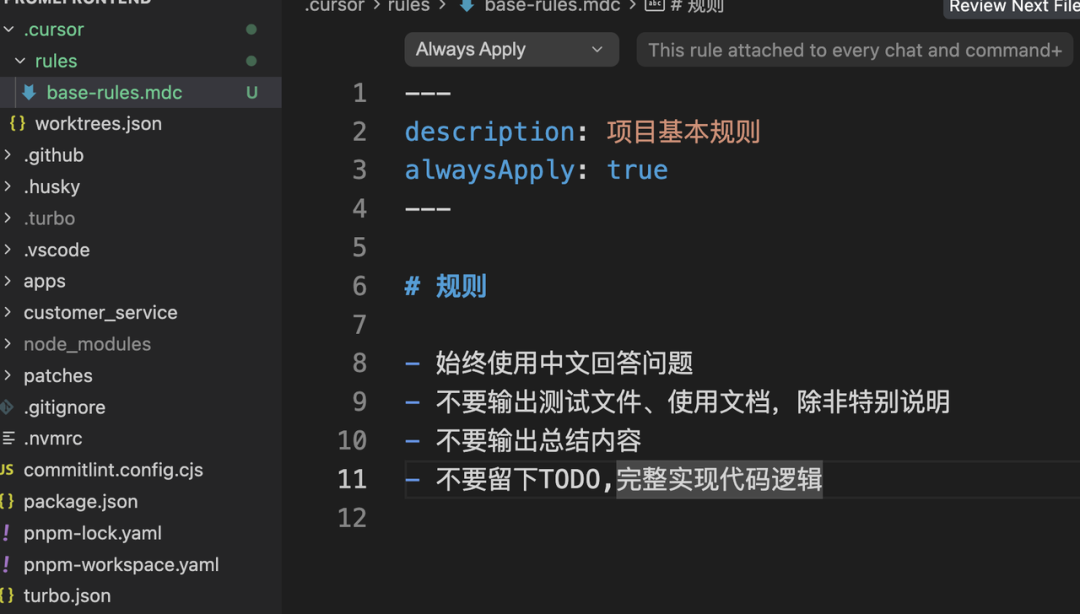
方式一:我们可以通过手动添加,在项目根目录.cursor/rules目录下创建mdc格式的规则文件,具体格式如下
方式二:在Cursor Settings => Rules中设置,分别填写文件名称、规则内容、生效方式
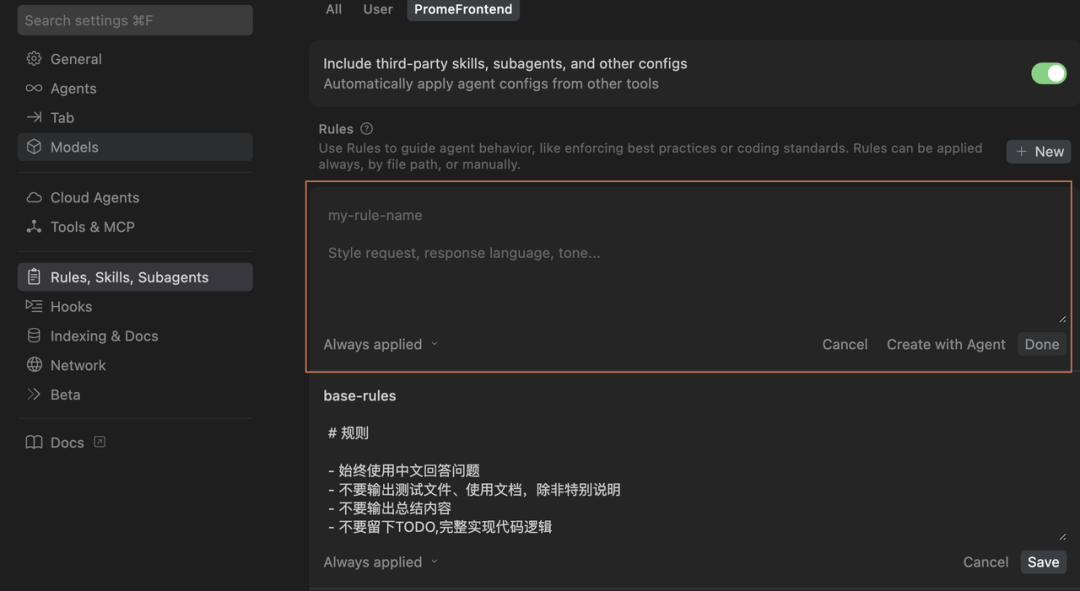
方式三:通过Cursor官方提供的create-rule skill创建,这个skill把官方推荐的rules最佳实践进行了封装,使用也很简单,在聊天窗口中直接输入/creste-rule,然后描述你要创建规则内容以及生效方式即可。
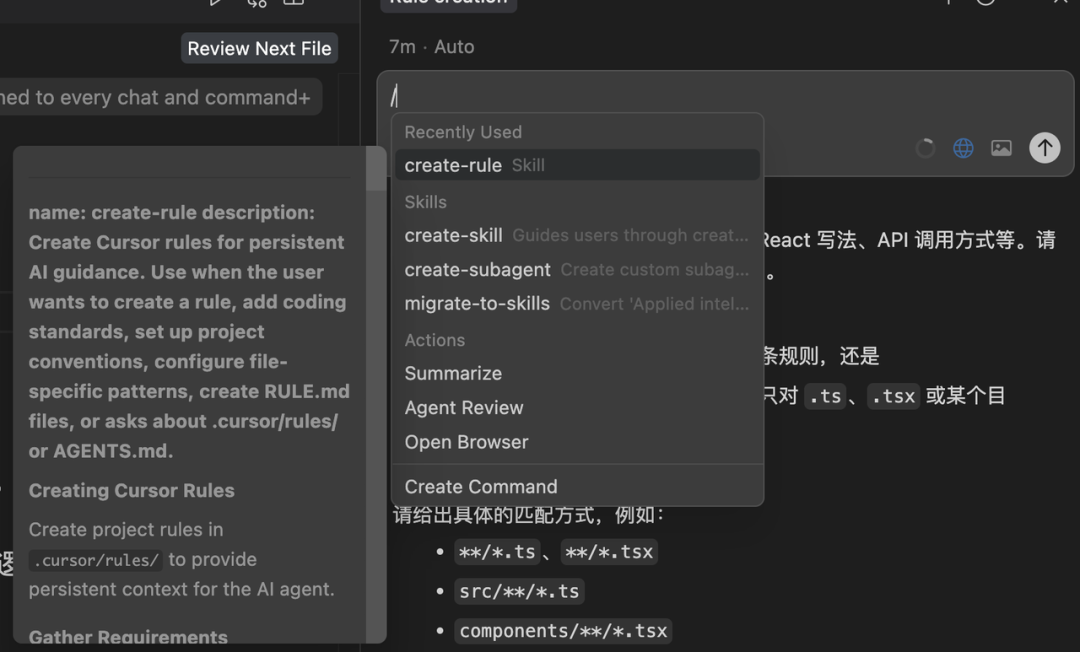
创建规则时,需要注意两种类型,一种是用户规则,这种适合个人特有的习惯和风格,会在所有项目中生效,它的对应规则文件在用户的根目录下面。
另外一种是项目规则,它是跟随项目的,会受到版本控制,通常情况我们会把规则都设定在项目规则中,方便团队协作使用。
需要注意的是,用户规则的更新不是立即生效的,可能要等几分钟,估计这里用到了RAG,离线进行索引构建。

另外,在实际开发过程中,我们可能会同时使用多种开发工具,而每种开发工具的rules有一些差异,比如cursor编辑器中的rules是放在.cursor中的,而Claude code中的rules是放在.claude中的,那需要注意这些规则的同步,在团队协作中最好能够统一1-2种编辑器的使用,减少这些rules的维护负担。
2. 新开会话或回退
我们在使用编程工具可能都有一种感受,在同一个会话中聊得越久,模型越容易遗忘之前说明的细节,甚至产生幻觉,我们就会觉得这个AI工具好蠢,然后就开始骂它:“你他妈的不要乱改啊”。
其实这种情绪的提示没有任何作用,要真正解决这个问题,我们需要从原理上来理解这种现象。
根本原因在于:随着对话轮次增加,会话上下文不断变长,早期输入的信息权重被后续内容逐渐稀释,模型对最初需求的关注度下降,于是表现出记忆模糊或理解偏差。
这里比较的好解决方案:
1.如果是新的功能,最好是重新打开一个新的会话,因为每个会话的上下文是独立的,模型不会被旧信息干扰。此时,大模型的注意力会更加集中到我们要完成的需求上,输出质量更高。
2.如果是同一个功能,但是我们已经聊了很多轮次了,并且发现大模型的输出越来越差,此时应该立即停止追加指令。可以使用下面两种方式:
- 采用回滚的方式,比如回退到开始出错的地方,然后一次性把后面补充的需求描述清楚,让大模型重新实现
- 另外一种做法是:让模型总结输出我们的需求,并且把修改的代码全部拒绝,然后新开一个会话,把完整的需求输入重新实现。
这两种方法通常都比在多伦对话中不断纠错更高效。
这里回滚在IDE类型的工具里操作很方便,点一下“Revert”按钮即可。不过如果使用的是 Claude Code 等 CLI 类型的工具,回滚起来就没有这么方便,可以考虑在中间步骤多进行commit。
3. 复杂问题拆分为多个简单问题
在实践中我们发现,一次性让AI实现一个很大或者很复杂的需求,实现的效果相对较差,并且会留下很多TODO,代码质量很烂。
针对这种情况,我们通常的做法是,对大需求进行任务拆解,每个任务尽量独立,呈递进关系,然后把每个任务使用新的会话让AI依次实现。
通过任务拆解有下面几个好处:
- 拆分的任务颗粒度越细,AI 完成度和完成质量越高
- 每次修改的代码量相对较少,code review更加方便,如果一次性修改大量代码,我们很难做code review
- 一次性完成需求往往产生很多 bug 和不正确的代码,AI 特别容易基于错误堆错误(将错误的代码作为上下文继续制造错误),导致怎么改改不对的烦躁情况,小范围利于人为监管和把控。
4. 提供清晰的上下文
AI编程工具在首次加载项目时,系统会将我们的代码库进行建立索引:它会把源码按逻辑结构拆分成多个语义片段(例如按类、函数、模块或上下文块),再利用向量模型将每个片段转化为向量表示 ,然后存入向量数据库中。
这样做的目的,是让后续查询能够基于“语义相似度”而不是简单关键词匹配,从而更精准地定位相关代码。
当我们向 AI 提问时,背后会经历一套完整流程:包括问题向量化、意图解析、多路召回、相似度匹配、上下文拼接,以及必要的调用链分析或依赖关系追溯。
本质上,这一整套机制可以看作一个面向代码库的知识检索系统,属于典型的 RAG工作模式——先检索,再生成。
因此,在向 AI 描述问题时,信息越具体,检索路径就越短、越准确。最好能给出具体的功能模块、文件名、目录路径、函数名、代码片段,让模型能够通过语义检索等方式,用较短的路径找到代码,避免在检索这部分混杂太多弱相关内容,干扰上下文。
除了清晰的描述之外,我们可以手动添加需要修改的文件和目录,通过前面讲到提及添加上下文信息。
5. 与AI进行需求澄清
在真正让 AI 开始干活之前,我通常会先让它跟我一起把需求聊清楚、把实现方案对齐。因为很多时候,我们给出的描述其实是带歧义的,或者信息不完整。
如果一上来就直接让它写代码,十有八九结果都会偏离预期。尤其是需求模糊时,AI 经常会自己脑补细节、替我们做决定,最后就变成我们还得花时间纠正它、补充上下文,不仅来回沟通很耗精力,还白白浪费 Token,尤其使用Claude 4.6 Opus模型,浪费的都是钱啊。
在需求澄清阶段,AI 会反过来问我们一系列问题,帮我们把遗漏的信息补齐,让需求变得更清晰。同时它也会给出实现方案,我们可以先看看这个方案是不是我们想要的。
如果发现哪里不对,就及时调整;确认没问题后,再让它基于已经澄清好的需求和方案去执行实现。
这样的好处是,一次性成功的概率会高很多,而且整个过程是我们在掌控节奏,而不是被AI牵着走。整体效率其实更高,心里也更踏实。
6. 频繁Commit
在用 AI 辅助编程时,养成频繁提交代码的习惯也非常重要。
通过 commit 把当前阶段的代码保存下来,如果后续 AI 在修改代码时不小心把原本已经跑通的功能改坏了,我们也不用慌,只要回到之前的提交记录就能快速恢复,而不是被迫手动一点点排查、重写甚至凭记忆还原。
其实一开始我是觉得频繁提交非常麻烦,后面也是踩过几次大坑之后才明白的。这里最好的实践就是最小功能编码实现、按照最小功能进行提交,而不是等到所有功能需求完成后才一次性提交。
并且现在的编辑器基本都支持基于修改的文件内容自动生成commit message,非常方便,而且还非常语义化,不用像之前绞尽脑汁的去想应该写什么内容,或者干脆写一句毫无信息量的“修改文件”。
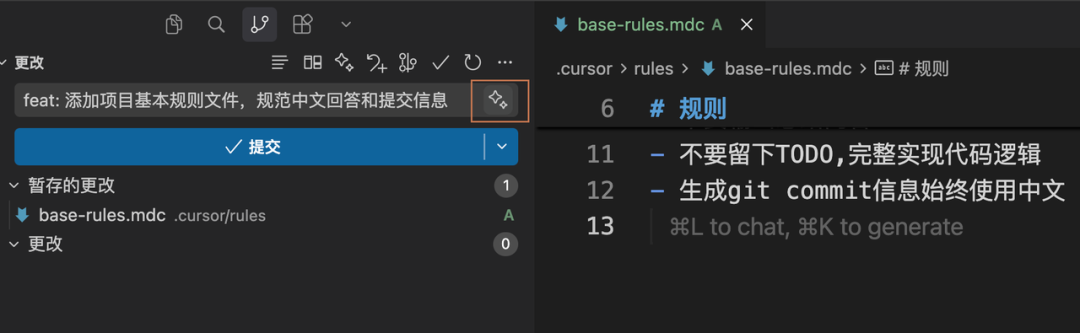
常用的一些MCP
上面我们介绍了一些AI编程的最佳实践,下面推荐一些日常高频使用的MCP。
Context7
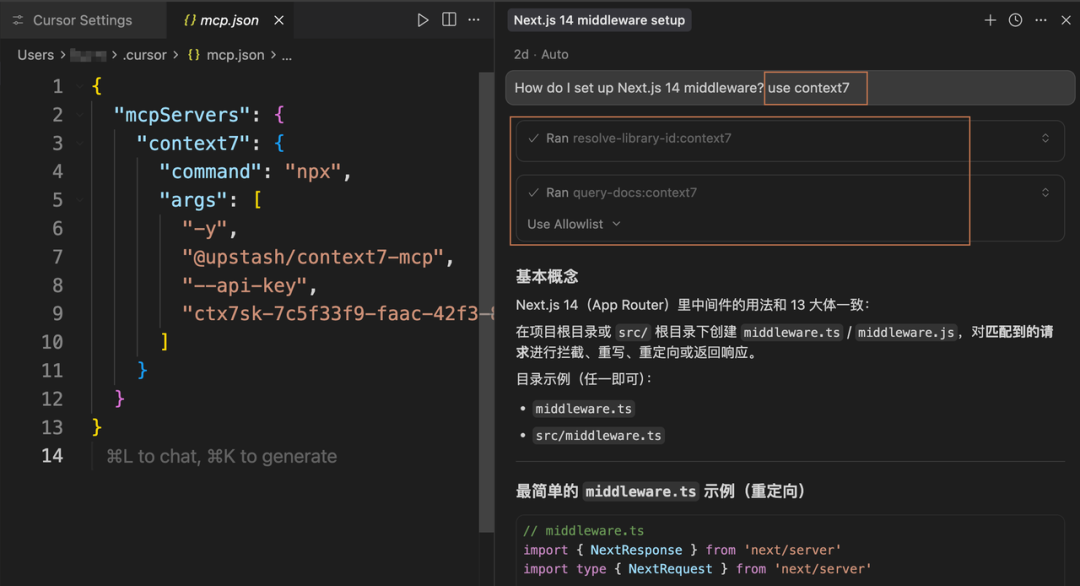
Context7是个MCP,前面提到的AI编辑器中都可以接入使用,我们可以把它理解成一个专门给 AI 编程“补课”的工具。
它的核心作用是:在我们问问题或者让 AI 写代码的时候,它会自动去对应的官方文档里查询最新、最相关的内容,然后把精简后的资料一起作为上下文给到大模型。
这样一来,AI 写出来的代码更准确,也更接近真实可用的版本,而不是靠旧知识或猜测乱写。主要是它还能通过语义或关键词自动筛选相关的信息,减少上下文长度。
因此,在实际开发中,Context7 通常作为 AI 和技术文档之间的一层中间桥梁,帮我们少查资料、少踩坑,特别适合用新框架或经常升级依赖的项目。
使用方式如下,以Cursor为例,在我们的提示中加入use context7即可,它会自动去调用相关的工具获取最新的文档信息。
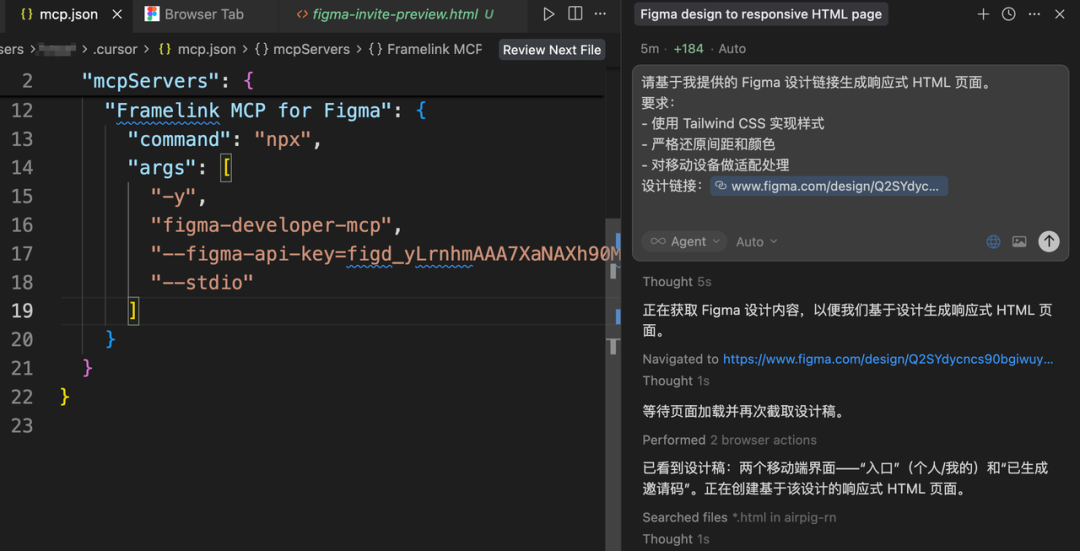
Figma-Context-MCP
这个mcp偏向前端开发,主要用于UI设计稿还原使用。
在前端开发过程中,很大一部分工作都在还原UI设计稿的效果,通过这个MCP我们可以自动拿到Figma设计稿的关键信息,包括布局结构、原始尺寸、颜色、文案信息、字体大小、边框属性等信息。
然后把这些信息给到大模型按照我们的提示词要求进行UI实现,整体效果虽然目前还达不到100%还原,实测下来当前能做到60%左右的还原度,剩下的仍需要我们手动调整,但是这给我们也节省了很大一部分时间。
这种方式相比直接截图的效果会相对更好,尤其是对于适配有要求的场景,因为截图需要依赖模型的识别,很多设计信息会失真,而通过mcp获取原始设计稿的信息会更加精准。
结语
我们深刻感知到AI编程能力的快速提升,并且可以预计的是一定会越来越强,过去那些依赖人工编写代码的环节,正在被AI逐步接管。无论我们相不相信、接不接受,这都是大势所趋,是技术发展的长期方向。
这里要讨论的不是“AI会不会取代程序员”,而是编程这件事正在发生结构性变化。
AI降低了技术门槛,在编程这件事情上,所有人都是平权,人人都能使用AI编程搭建自己的应用,这意味着写代码这项能力本身不再像过去那样稀缺。
对于开发者来说,需要重新思考的问题是:当实现成本大幅下降,我们的价值应该体现在哪里?如何与AI更好的协作?
在当前,AI辅助编程大致呈现出两种使用方式:
1.一种偏随意、偏即时反馈,适合探索和试错,也就是我们说的vibe coding;
2.而另一种则强调约束、结构和规范,更接近工程实践。vibe coding可以提升效率,但很难支撑复杂系统的长期运行;
3.后者虽然前期成本更高,却更符合真实生产环境的要求。
开发者终究要为系统稳定性、可维护性和迭代成本负责,为线上的事故背锅,因此真正可靠的AI协作方式,一定是可控的,而不是随意的。
与此同时,开发工作的重心也在发生变化。以前写代码更像一条线性流程:分析需求、实现功能、调试测试、上线交付,更多的精力都在编码实现上。
而现在,更多的是在描述需求,编写规范,拆解任务,然后让AI去完成具体实现,最后人工审核代码。如果前期设计混乱、需求描述不清、任务拆分粗糙,即便AI能力再强,也只能在错误上继续叠加错误。
所以,AI编程工具能力的升级也促使了开发者角色的变化。AI正在接管执行层,而开发者正在被推向决策层。以后真正拉开差距的,不是谁写代码更快,而在于你能否带好AI,让整个开发过程高效、稳妥、有序。
程序员不会消失,但是会减少:不会用AI的人,会被淘汰;只会用AI的人,不够稀缺;能驾驭AI完成复杂系统的人,才会成为关键。
本文由人人都是产品经理作者【叶小钗】,微信公众号:【叶小钗】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


