
 起点课堂会员权益
起点课堂会员权益人工智能的人工部分—数据标注(上)
编辑导读:人工智能的发展,是通过不断学习已知样本实现的。在监督学习的情况下,人工的数据标注是智能的前提与灵魂。本文作者对此进行了分析,希望对你有帮助。

当今社会人工智能领域蓬勃发展,各领域都在追求智能化,耳熟能详的有智能驾驶、智能家居、智能语音、智能推荐等。人工智能是通过机器学习,大量学习已知样本,有了预测能力之后再预测未知样本,以达到智能化的效果,机器学习可分为监督学习和无监督学习,无监督学习的效果是不可控的,常常被用来做探索性的实验。
在实际应用中,通常是有监督学习,有监督学习就需要做数据标注,所以智能的前提是人工,因为智能结果的输出是多次人工样本的输入,可以说人工的数据标注是智能的前提与灵魂,没有人工就没有智能,有多少人工就有多少智能。
一、数据标注的分类
数据标注从难易程度方面可划分为常识性标注与专业性标注。例如,地图识别领域的标注多为常识性标注,标注道路、路牌、地图等数据,语音识别标注也多为常识性标注。做该类型标注工作难点在于需要大量标注训练样本,因为应用场景多样且复杂,对标注员无专业技能要求,主要是认真负责,任务完成效率快、质量高的即为好的标注员。
医疗诊断领域标注多为专业性标注,因为病种、症状的分类与标注需要有医疗专业知识的人才能做,招聘领域标注也属于专业性标注,因为标注员需要熟知招聘业务、各岗位所需的知识技能,还需了解HR招人时的关注点,才能判断简历是否符合职位的招聘要求。该类型的标注工作需要有招聘领域专业知识的标注员,或者称为标注专家,标注工作的难点比较多,例如选拨培养合适的标注员、标注规则的界定、标注质量的控制等多方面。
数据标注从标注目的方面可划分为评估型标注与样本型标注。
评估型标注一般是为了评估模型的准确率,发现一些Badcase样例,然后优化算法模型,该类型标注工作为了节约标注资源可控制标注数量,一般情况下标注千量级的数据,样本具有统计意义即可,标注完成后需要统计正确率,以及错误样例,该类型标注的重点是错误样例的原因总结,分析每个Badcase出现的原因,并将原因归纳为不同的分类,有了原因分析方便算法同学分类型分批次的优化模型。
样本型标注即为模型提供前期的训练样本,作为机器学习的输入,该类型标注工作需要标注大量数据,一般情况下需要标注万量级的数据。为了样本的均衡性,标注样本多是随机抽取的,这样做的优点是可在一定程度上避免样本偏差,但缺点是要标注大量数据。如果是文本型样本,有时可借助算法抽取一些高频、高质量样本进行标注,这样可一定程度上减少标注工作量,但可能存在样本偏差。总之样本型标注是个苦力活,业界有句话这么说的:如果你和一个人有仇,那么劝他去干标注吧。
数据标注从标注对象方面可划分为文本标注、图像标注、语言标注、视频标注,从标注方式方面可划分为分类标注、标框标注、描点标注,这些标注分类基本都属于标注形式的差异,没有较强的专业度,所以不做较多讲述了。
二、数据标注规则的制定
常识性标注的规则比较简单,标注一部分样本即可总结出较通用的规则,但专业性标注的规则比较复杂,制定专业的标注规则需要遵循以下三原则:多维分析与综合分析相结合,因子权重影响因素场景化,问题类型标签化、结构化。以下是招聘领域简历与职位匹配度标注规则的指导思想,具体细节规则会在《数据标注(下)》中阐述。该标注规则比较符合标注规则制定的三原则。
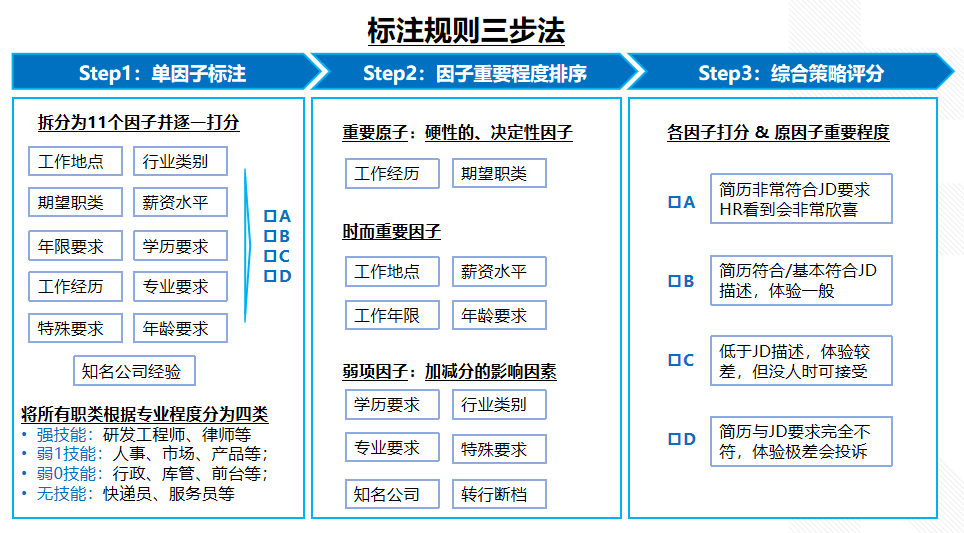
第一,多维分析与综合分析相结合。
简历与职位的匹配度影响因素肯定是多维的,不能只参考工作经历或专业要求一个因子,或者某几个因子,要多维分析,最终再给出综合评分结果。当然简历与职位的匹配标注也不可能一上来就能给出综合的评分,不能纯感性的告诉标注员:你觉得是简历与职位非常匹配就给分,不匹配就不给分,这在逻辑上也不合理。所以要先给单一因子打分,然后参考每个因子的评分结果,最终再进行综合分析给出评分结果。
第二,因子权重影响因素场景化。
前面有提到简历与职位匹配度评估需要给每个因子打分,那每个因子打分结束后怎么给出综合评分呢,给每个因为赋予权重吗?然后按权重计算总分?答案是否定的,我们要结合具体场景把所有因子进行归类分析,比如设定一些重要因子,如果重要因子不匹配可能就直接不给分,比如工作经历代表的是一个人的胜任力,如果该候选人不具备该岗位的胜任力,总分肯定是0分。还有一些因子虽然不是很重要,但会影响评分,有些因子时而重要时而不重要,比如年龄,HR想要1-3年经验的行政专员,候选人40岁,该情况肯定会影响最终评分且很有可能总分是0分。所以把所有影响因子结合场景进行归类分析是十分必要的。
第三,问题类型标签化、结构化。
标注结果一般情况下会以分数的形式展示,ABCD,或者0123,然后一组数据没有得到满分是因为什么呢?哪里不匹配呢?所以前期制定标注规则时一定要把原因分析考虑进去,列出所有不匹配的原因,形成结构化的原因标签,有利于最终分析Badcase的分类与占比,然后算法或者策略团队在优化时可以优先解决占比高或影响恶劣的case。
数据标注是一项看似简单实际却十分复杂的工作,涉及标注分类、标注规则制定、标注原因分析、标注系统搭建、标注团队管理等,尤其涉及到专业领域的标注则更困难,本篇主要介绍了标注分类、标注规则制定,细节的标注规则以及标注系统的搭建,标注团队管理会在后续更新,希望大家持续关注,感谢阅读!
本文由 @艳杰 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。

















你好可以方便问一下如何设计规划一款标注工具呢
数据标注看似很难,但是根据作者的一篇文章理解了不少,作者的文章讲的很详细。
感谢认可,感谢评论!
数据标注这一个环节算是人工智能一个很大的突破了,继续加油
感谢鼓励,共同加油!
人工智能依托的还是人工,至于数据标注这一部分,一定也是需要人工的样本的
是的,有多少人工就有多少智能!
又是人工智能,这个话题真的一直都在引发热议,人工智能的技术也在不断的升级
是的,随时随地被人工智能监控着,哈哈!
把所有影响因子结合场景进行归类分析是十分必要的。
是的,这只是某些场景的举例,还有很多细分场景。