
 起点课堂会员权益
起点课堂会员权益数据产品经理:6大数据分析平台的“世界观”
本文从一个不太常见有十分重要的角度切入——数据模型,也就是讲解一些知名的数据分析平台究竟收集了哪些数据,以及为什么要收集它们。将这类内容成为:数据分析平台的世界观。

GrowingIO、神策、诸葛IO、TalkingData、友盟、Google Analytics for Firebase是数据分析领域广为人知的几家综合性平台,他们在用户行为研究与驱动业务增长等多个方面,都提供了丰富的分析工具和技术支持,成为许多知名企业的数据平台首选。
另一个特点是,我们都将移动场景下的用户行为分析作为重点之一,而非Web时代的行为分析(这也是Google Analytics for Firebase入选了,而没有选择Google Analytics 360的原因)。
在数据分析领域,“巧妇难为无米之炊”这句古话常被提起,用来比喻没有高质量的数据,就无法进行高质量的分析、得出高质量的结论。而这6家平台与单纯的数据可视化平台相比,其服务都覆盖了数据采集的部分,也就是从源头开始支撑整个数据分析。
因此,这个系列就从一个不太常见有十分重要的角度切入——数据模型,也就是讲解一些知名的数据分析平台究竟收集了哪些数据,以及为什么要收集它们。我将这类内容成为:数据分析平台的世界观。
至于数据分析“出彩”部分,各家也都有自己的侧重点——有偏重用户行为与画像的、有偏重广告与商业变现的、也有偏重营销工具的,各不相同。那么废话不多说,加下来我们就来探讨这几个数据平台的“世界观”。
本文中介绍的所有内容,都来自于这几家平台的帮助文档整理,链接如下:
- GrowingIO:https://docs.growingio.com/docs/
- 神策:https://www.sensorsdata.cn/manual/
- 诸葛IO:https://docs.zhugeio.com/
- TalkingData:http://doc.talkingdata.com/
- 友盟:https://developer.umeng.com/docs
- Google Firebase Analytics:https://firebase.google.com/docs/analytics/
如果你对其他平台感兴趣,也欢迎在评论里告诉我,它会加入我的to-do list。
一、这个世界是怎样的 for 数据分析平台
这是一个根本性的问题,直接决定了后续的所有内容。就像咱们中国古人,认为世界的基本就是阴和阳而已。阴阳的组合与生化,产生了世界万物。对于数据分析平台来说,也会有一些构成世界的基本元素。这些元素之间相互影响、相互作用,演化出了千变万化的数据分析。
首先,要对GrowingIO、神策和诸葛IO这三位同学加粗标红地提出表扬!!!
是因为他们仨都很贴心地在文档中提供了一个叫做“数据模型”的部分,极大的减少了爬API文档了解逻辑的时间。文档地址如下:
- GrowingIO:https://docs.growingio.com/docs/data-model/
- 神策:https://www.sensorsdata.cn/manual/data_model.html
- 诸葛IO:https://docs.zhugeio.com/datamanager/data_model.html
另外三家就提供的比较隐晦了,不过多多少少还是能找到相关信息的——这6家平台都采用了“事件模型”来收集数据。(部分数据是自动收集的,没有特别明确的数据模型,后边会详细列举。)
在这几家平台看来,这个世界就是一大堆错综复杂“事件”(Event)而已。用户是事件的施动者,而每个事件有自己的一些独有的信息。用一句话概括:有人搞了一些事情,我们来分析一下吧。
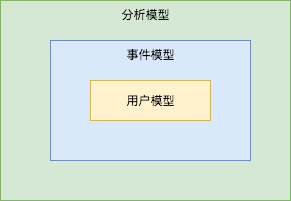
这三层之间的关系,是这样定义的:
- 统计模型基于事件模型
- 事件模型基于用户模型
其中事件和用户,我们可以称之为两个“实体”(Entity)。他们之间的关系可以用E-R表示为:
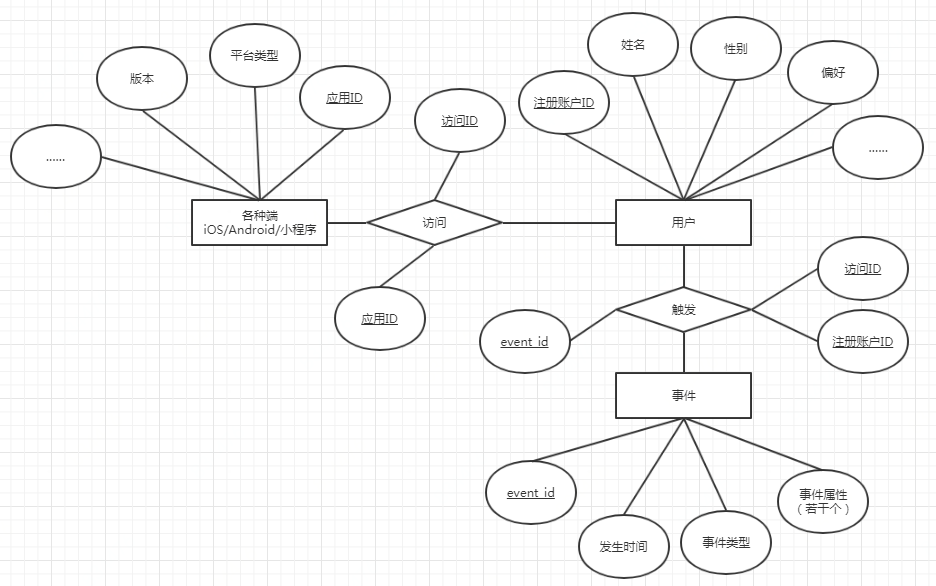
二、事件(Event)
对于事件模型,理解事件(Event)这个概念当然是最重要的。那么什么叫一个事件呢?
那些在数据分析中耳熟能详的用户行为,都可以叫做一个事件。比如,启动App、注册、登陆、浏览、转化(创建订单、完成支付、发布内容等)、留存、分享、订阅、收藏等等。
当然,这就存在一个问题了——不同的业务形态,会产生不同的用户行为。有的关注交易,有的关注UGC内容,有的则只是看用户的点点划划。那么对于这几家第三方平台来说,如何给出一套模型能覆盖所有事件呢?
其实每家平台会把这些事件分为两类:那些已经确定的、不管什么业务类型都会需要的事件,当做了“预留事件”(每家的叫法略有差别,比如:在TalkingData指的就是“灵动分析”部分的数据)。比如:打开App、注册、登陆、浏览(PV/UV)等。也就是说,只要接入了这个平台(并将SDK进行了正确的初始化),就可以收集到这些事件的数据,进行监控和分析。
另一类,就是“自定义事件”(同样每家的叫法略有差别)。这一类涵盖的就是与不同的业务类型高度相关的那些事件了,比如:单纯的UGC内容平台,就没有订单和支付这些事件;而对于纯粹的电商平台,其关注的核心也不会是超大篇幅的内容产出。这些就应当作为自定义事件。
其中自定义事件是需要在收集之前,先在平台上“注册”这些事件的,这也是为了方便对事件进行管理。
但不管是预留事件还是自定义事件,都保留了基本的事件数据结构,一个事件主要包含四部分信息,称作事件的属性(E-R图中与事件连线的椭圆形):
- 时间信息:这将是时间序列分析中的关键,这个信息代表了这个事件是什么时候发生的;
- 用户信息:这部分主要是为了关联事情的发动者是谁,以便支持后续从用户角度开展的分析;
- 事件类型:这也是每个事件的一个基本属性,比如:App启动是一个类型,用户登陆也是一个类型。
- 事件属性:这部分的定义比较宽泛,所以也留了较大的自由度。比如:我们前面讲到的两个例子,如果是创建订单的事件,则会包括订单号、订单金额、商品编号等等;如果是UGC类型的事件,则可能包括内容发布的板块、是否原创、引用链接等等。
至此,我们可以简单的理解,所谓“事件”,其实可以就按表面意思理解,就是发生了一些事的概念。而后续在进行分析的时候,就得根据分析的需要,重新整理事件的数据。
三、用户模型
用户模型是第二大概念,也是最爱分析的第二大主体。上一段说到在数据收集之后,进行分析的时候,需要重新对数据进行整理,面向用户的数据汇总就是主要方式之一。通过这样的汇总,我们得到的是用户画像、用户偏好等这些初步的结论,再进行深入分析。
下面先搞清楚两类用户:访问用户与登录用户。
在用户模型中,用户分为两类:登录用户与访问用户。
所谓登录用户,就是已经注册并取得了注册账号的用户,比如:我们注册了QQ就有QQ号,注册了淘宝有淘宝账号等等。对于这样的用户,正因为他们已经有了一个几乎不可能改变的账号,之后所有的行为和属性信息,都会尽可能地与这个不变的账号关联起来。
这引出一个题外话——账户体系的重要性。在互联网社交刚崛起的阶段,有很多平台致力于做统一账户。关键在于这个跨平台的账户ID关联了用户的所有行为,这种方式对于渴望降低CAC、实现交叉引流的平台有很大帮助。
但对于那些大平台,就是流量的“净输出”方,而且那些初期需要引流的平台,一定是把第三方账号关联到自己的账户体系上,这就凸显了同一账号的信息中介作用。在大厂开始外推自己的账户体系、信息逐渐开始“对称”起来的时候,统一账号就没有存在空间了。
说到用户注册和登录,这就产生了另一个问题:当用户没有登陆,甚至还未注册,那怎么办呢?
这个时候,ta就是一位访问用户了。
那么访问用户又是谁呢?
问题就在这——我们不知道TA是谁,TA没有登陆,我们已经掌握的历史数据却都是与注册账号相关的。也就是说,这些数据都无法跟这个访问用户对应上。
在应用中主要是这两方面具体问题:
- 历史数据关联问题,特别是与业务有关的数据(比如:订单),一般都是与注册账号ID关联的,而这个访问用户的ID很不稳定,会频繁变动。
- 访问用户ID的产生依赖于平台。也就是说,用户使用同一家的App,在没登录的情况下,在iOS、Android和其他平台上上会被当做是两个人,这对于数据分析显然是个灾难。
这就好像,我们用身份证买了一张机票,如果你不出示身份证,人家自然不会给你办理手续,即使用护照或者其他证件也不行。(惨痛的真实经历…)
当然,在互联网的领域中从不会“坐以待毙”。对于这样的“无名氏”用户,许多平台已经开始支持记录和管理历史访问设备,也就是你用的手机、平板电脑等设备有自己的ID(比如网卡的MAC地址)。如果某位访问用户使用同一部手机打开了App,我们也可以通过手机的设备号近似的关联到登录用户身上。
这种从设备到人的映射关系,有些是在账号体系中“强管理”的——关联设备数量有限制,而且需要明确授权。比如:Apple ID。也有“弱管理”的,只是在App中展示一下。更低效的做法,是把关联的工作放到数据分析阶段,再耗费大量计算资源做这个层次的关联。
至此,简单理解,登录用户=认识,访问用户=不认识。
用户也会有自己的属性,这些是人们喜闻乐见,喜欢分析的内容。对于一位用户,属性包括以下两种:
- 基本固定不变的属性,典型是人口统计学属性,如性别、年龄段、地理位置等。
- 通过一定的业务含义加工出来的用户属性,典型是用户分群、用户标签属性。
四、分析
上边还剩一个“端”的实体,但是其自身的分析价值更偏向技术层面,我们暂时忽略。
分析这部分可能是整篇文章比较吸引人的地方,但其实,说完了前面几方面的内容,才可以开始将分析。这个时候,能分析什么、怎么分析这类问题,才能落到具体的东西上。
我们回到前面的这张E-R图:
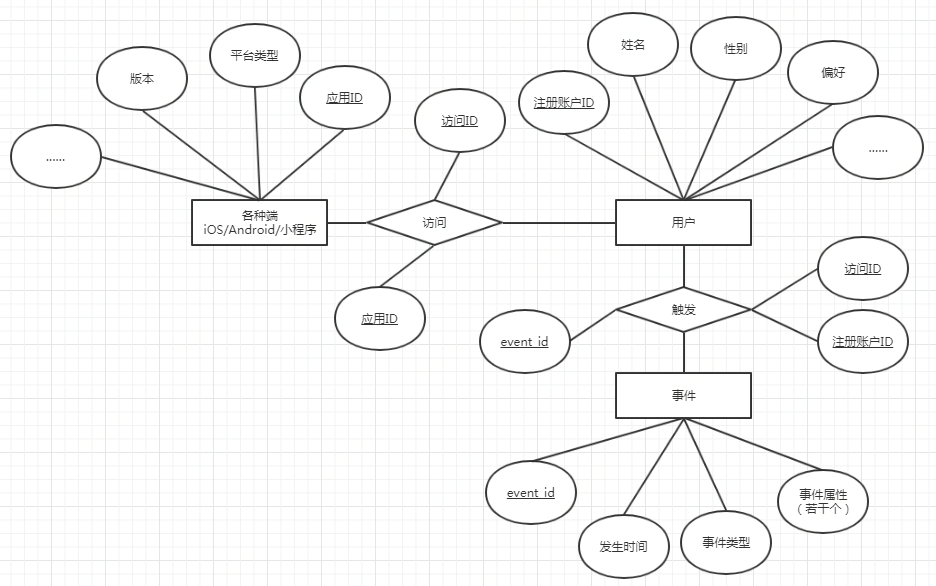
图中的实体(用矩形表示)和实体关系(用连线表示)概括了我们要分析的内容。这张图里有三个主体:端、用户和事件。这也就意味着,我们的分析过程有三个切入点:产品(内容)自身、用户自身以及用户行为。
当然,我们最常分析的,还是产品与用户关系,以及用户自身的行为这两个大主题。而这两个行为的数据,主要来源于“用户触发事件”这个过程。(下边那些就不是正统的E-R图了哈,能传达含义就行。)
1. 统计分析
统计分析是最基本的分析手法了。
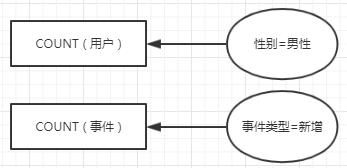
要做的基本就是指定一些属性的值,然后对实体进行计数。比如:我们要求用户的性别=男性,然后对满足要求的实体计数。再或者,我们要求事件类型=新增,然后统计事件实体的数量,算出来的就是今日的新增用户数DNU(隐含一个去重的过程)。
另一类统计分析是分析用户的行为路径,比如:用户从打开App,到最终支付成功,经理的怎样的路径呢?
这就是通过关联事件实体,并对事件进行统计而得出的,比如下图这个关系:

2. 归因分析
归因分析需要给发生的事情找到原因,一般的最终目的是通过这种挖掘出来的因果关系,对未来进行预测。比如:如果我们发现了女性用户更可能购买我们的产品,那么在资源有限的情况下,我们就应当着重向平台上的女性用户推广我们的产品。
另一类例子,就是关于事件和事件之间的,比如经典的“LinkedIn 魔法数字”案例——1周内增加5个社交好友的用户更容易留存。
针对第一类案例,我们实际上是通过关联事件实体和用户实体来实现的:
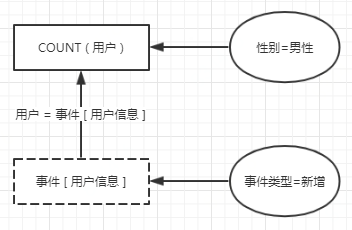
而对于第二类行为之间的归因分析,使用过行为之间的交叉来过滤用户,最终仍旧是通过统计用户数量来得出结论的:
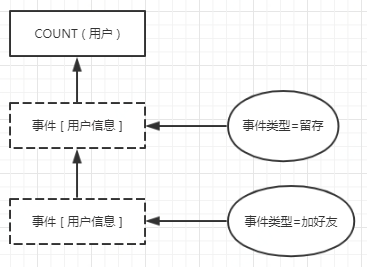
如果你经手过大数据量,可能已经想到了,这样的事件统计计算量会非常非常大!在实战中,更多情况是将这种行为的数量当做用户的一种属性,这也就是前面提到的第二类用户属性。
修改之后的逻辑如下图:
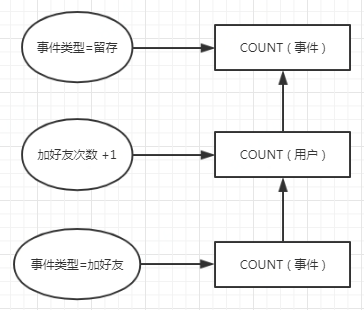
但不管哪种分析,都会面临一个问题——用户属性很不稳定,会改变的。比如:用户的年龄段。在用户第一次加好友的时候,其年龄段属性为“21-25岁”,真实年龄为25岁,正处在年龄段交替的时间点;当再次加好友的时候,真实年龄已经变成了26岁,其年龄段属性也随之变成了“26-30岁”。
这就产生问题了:当用户完成了5次社交好友之后,这5次的社交好友应当归因到“21-25岁”呢?还是归因到“26-30岁”年龄段呢?
这会直接对我们的分析结论产生影响。
类似的问题也出现在一些其他分析上,比如:用户的浏览行为。当用户启动App之后,可能在所有内容之间穿梭很久,最终才决定购买或者其他转化。
那么,这次转化究竟应当归属于哪些页面或按钮呢?
为了避免这种问题,有些平台(如:GrowingIO)在配置自定义事件时提供了明显的配置项(称为“埋点事件”的“归因方式”);也有的平台讲这件事的决定权交给了使用者,可以在代码或者事件定义的过程中给出;更有如Google Analytics for Firebase这样的平台,会提供一套专门的“归因模型”,来处理这类转化归因的问题。
关于归因的问题会单独整理一部分内容。这部分整理还会衍生出一些其它的思考,比如:你的业务增长,真的应该归因给社群裂变吗?
——–[UPDATE 2018-11-21]——–
经评论的同学提醒,关于 GrowingIO 平台的归因,这里补充一些详细信息:
登录用户的归因模型:
【归因目的】随着用户行为的产生,用户自身的属性也会跟着改变(比如年龄、地域等),两个时间段是无法严格对齐的,导致一个行为可能对应了多个属性值(随时间延续而产生),所以才需要用归因模型来约定,每个行为具体对应哪个属性值。官方例子是用户从银卡升级为金卡,那么从现在看,用户在银卡阶段的交易应当归属银卡阶段还是金卡阶段呢?
【备选方案】两种方案:最近(只时间间隔最小,归银卡);最终(归金卡);
【参考文档】https://docs.growingio.com/docs/data-definition/user-variable/loginuserid#gui-yin-mo-xing
转化归因方式:
【归因目的】当用户实际转化之后,我们会追溯促成转化的原因。在这个分析过程中,用户可能历经了多个活动、多个按钮和页面、反复搜索了多个商品等。应当如何认定是哪个事物促成了用户转化呢?因此这里还有归因的逻辑。一个重要的区别在于,“转化”与单纯的“事件”不同,“转化”通常会对应价值的产生,比如用户支付。所以这种归因,不仅仅是建立关系,还要将这种产生的价值,按照一定的分配方式分给所有相关方。
【备选方案】最近(依然是时间间隔最小的含义)、最终和线性(平均分)归因。同时,官方给出了三种备选方案的应用场景:
- 使用最初归因模型,某个内部活动带来了多少注册,多少订单。
- 使用线性归因模型,内部搜索的效果怎样,某个具体的搜索词带来了多少订单,营业收入。
- 使用最近归因模型,同一个内部活动的不同入口分别带来了多少内部活动详情页面的浏览。
【参考文档】https://docs.growingio.com/docs/data-definition/custom-event/convert-variable#gui-yin-fang-shi
广告监测中的归因逻辑:
【归因目的】广告投放与利益绑定的更紧密,但同样面临如前所属的“1对多”的困境,而且同样需要有一定的规则来分配产生的价值。从GrowingIO平台提供归因方式判定,更偏重于比较独立的纯粹广告,而不适用于与业务流程或产品形态深度结合的类推荐流程。如果是深度结合的流程,可以想象Last Click会直接忽略在转化路径上的其他影响因素,把转化归功于“立即支付”这样的按钮。
【备选方案】Last Click(最近点击)规则 + 反作弊 + 15天时间窗
【参考文档】https://docs.growingio.com/docs/ads-tracking/app-marketing#4-gui-yin-luo-ji
归因是什么?在这篇中我们继续探讨《数据产品经理:从归因模型延伸到转化漏斗》 。
本文由 @御豪同学 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









特别好
好文章
非常好
总结的很清楚,赞👍
谢谢老板~
M
我们公司准备搭建基于行业的Saas服务平台,我想问的是针对这篇文章,我们是否可以使用类似谷歌这样的数据采集与分析平台,先进行试错迭代,业务发展起来再组建团队自己开发数据采集与分析系统?可行不,这样做
我觉得是可以的。ROI的平衡点,是搭建自己的数据采集平台的成本投入,与SaaS平台产生的效益持平。如果这个SaaS还没被证明可以产生足够的价值,那么数据采集这块可以尽量降低成本。