
 起点课堂会员权益
起点课堂会员权益skill 装得越多越省 token?我交了三个月学费才搞明白
Claude Code的skill机制看似能节省token,实则暗藏玄机。8个skill装上后API账单激增30%,卸载到2个才恢复正常——这背后揭示了skill描述常驻、误触发和MCP混淆三大烧钱陷阱。本文将深度拆解skill与prompt的本质差异,教你识别那些偷偷消耗token的'二房东'技能。

我认识一个写后端的哥们儿,将将入坑 Claude Code 那阵子,跟打了鸡血似的,把市面上能找到的 skill 一口气装了 8 个。代码生成的、数据库迁移的、写测试的、画架构图的、解释报错的、查 API 文档的,他说自己这是”武装到牙齿”。
装完那天他在群里发:以后写代码省心了,token 也省了,官方都说渐进式披露能省 98%。
一个月后他在群里又发:API 账单涨了三成多,咋回事?
他自己琢磨了好几天没琢磨明白,最后干了一件挺反人类的事——把那 8 个 skill 卸载到只剩 2 个。下个月账单回落。
我听完这事儿心里咯噔一下。这不就是当年大伙儿装 Chrome 插件那剧本么——装的时候觉得自己赚了,用的时候发现浏览器越来越卡,最后清空插件那一刻才意识到,原来卡的不是 Chrome,是自己。
对了,我那哥们儿用的是 API,不是订阅版,所以每个 token 对他来说都是真金白银。你要是 Pro 用户感知可能没这么强,但机制是一样的,往下看就明白了。
这篇要说的就是这事儿。skill 不是不省 token,是它省 token 的方式跟你想的不一样。官方文档把好的那一面写得明明白白,issue 区里一片”为啥没省”的哀嚎也是真的。这中间的落差,不是 skill 这个机制有毛病,是用 skill 的人没搞清几件事。咱挨个唠。
一、skill 到底是个啥?跟你天天写的 prompt 差在哪
要把 skill 省不省 token 这事儿讲清楚,得先把 skill 是个啥讲清楚。我发现很多人把 skill 当成 prompt 的”豪华版”——这个理解是错的,错得还挺离谱。
prompt 你天天写。一个问题来了,你敲一段话,把背景、要求、格式、例子全塞进去,发给模型。模型读完,回你一段。这事儿完了,下一个问题来了,你又得重新敲一遍——或者把上一段 copy 过来改几个字。
prompt 是消耗品。你每次发问,它就被烧一次。烧的就是 token。
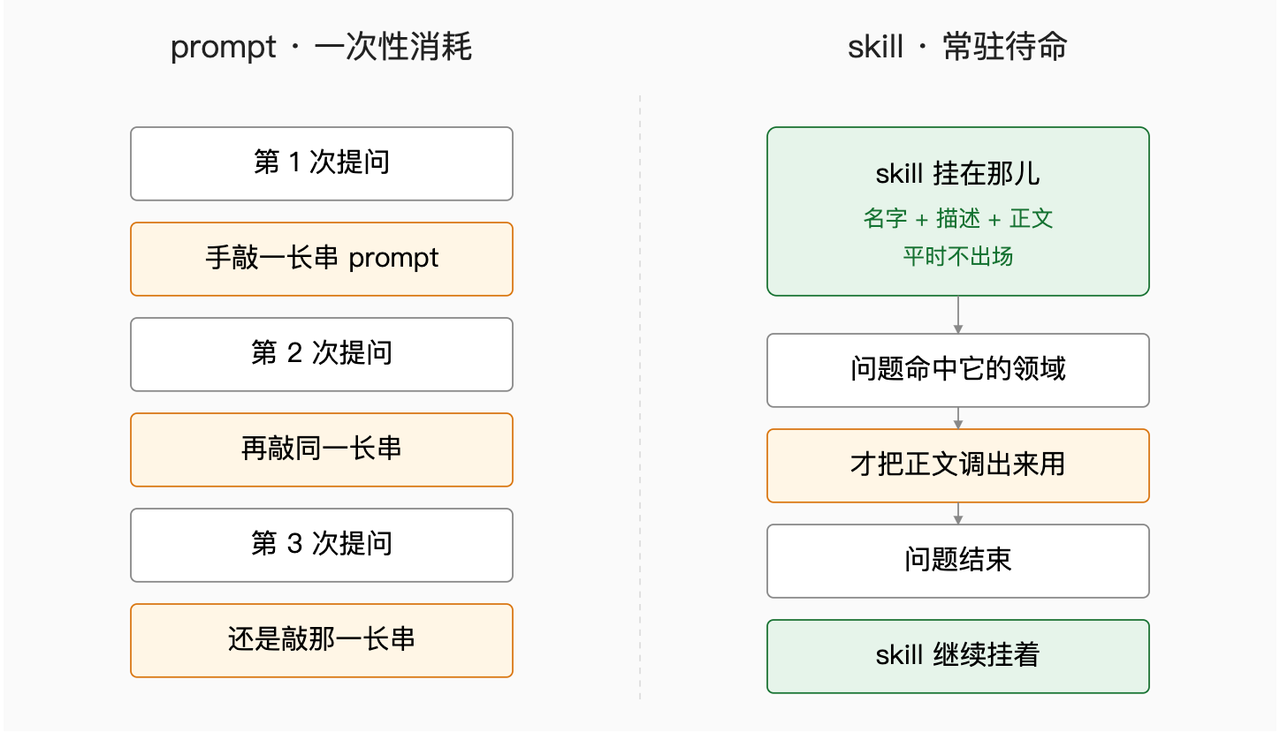
skill 不一样。skill 是你提前把一套”知识 + 流程 + 规范”打包好,挂在那儿。它有个名字、有段描述、有个正文。平时它就躺着,啥也不干。等你某次问题碰到了它管辖的领域,模型自己判断”哦这事儿归它管”,再把它的正文调出来用。
打个比方你就明白了。prompt 是你每次出门都得现穿一遍的衣服——没洗的脏的湿的,每次都得翻箱倒柜重新搭一套。skill 是你衣柜里挂好的成套西装——平时不动它,要正式场合了,往身上一套就出门。
差别看着小,账算起来差得远。
prompt 是显性消耗。你写多长,模型就读多长,烧多少 token 一目了然。这块儿没啥可讨论的,写多了费、写少了省,谁都懂。
skill 是隐性常驻。skill 的正文确实是按需加载的——你不碰它它就不出场。但它的描述不一样,描述是常驻的。你每发一次问题,模型都得把所有装着的 skill 描述扫一遍,决定要不要召唤谁。
这就是 skill 省 token 跟 prompt 省 token 走的不是一条路。prompt 省 token 靠”写得短”,skill 省 token 靠”挂得准”。挂得准,正文按需加载,省得明明白白。挂得不准,描述常驻烧钱,还可能误召唤把正文也拽出来,赔了夫人又折兵。
所以那些把 skill 当成”加强版 prompt”的人,第一步就走偏了。他们以为 skill 像 prompt 一样越多越好——多装一个就多一种能力。其实 skill 像衣柜——装太多衣柜挤不下,每天找衣服都费劲。
总之,这俩根本就不是一个路数的东西。搞不清楚这个,后面说啥都绕。
二、官方说的渐进式披露,省的是哪一段,没省的是哪一段
skill 省 token 这事儿,官方文档说得挺漂亮,叫渐进式披露。听着像个学术名词,其实意思特简单——东西按需要逐步亮出来,不需要的时候不亮。
具体怎么省呢?你想象一下没 skill 的时代,怎么干活的。
你要写一个 Python 测试,又想让模型遵循团队的某套规范——比如必须用 pytest、必须有 fixture、必须 mock 数据库、必须覆盖边界用例。这些规范加起来三五千字。没 skill 之前你咋办?把这三五千字全塞进 prompt 里,每次提问都塞一遍。一天问十次,烧三五万 token,光这一项。
skill 来了之后,这套规范你打包成一个 skill,挂在那儿。你下次只要问”帮我写个测试”,模型一看描述,哦这归”Python 测试规范”这个 skill 管,把它的正文加载进来,开始干活。
省在哪?省在你没问到的那 99 次问题里,这三五千字一个 token 都没烧。
这个机制是真的。官方没骗人。
但官方没说透的是另一面——描述是常驻的。
每个 skill 都得有个描述,告诉模型”我是干啥的、啥情况下该召唤我”。这个描述虽然短,几十到一两百 token 不等,但它每一次对话都在场。你装一个 skill,对话上下文里就常驻一段描述。装五个,常驻五段。装二十个,常驻二十段。
这就是那个”长账”。
单次对话里这点描述塞进去无关痛痒,比起一个完整 skill 正文动辄几千 token,确实是九牛一毛。但只要你装得多、用得勤,它就在那儿默默累加。
我估摸着算了一下——这数字不精确,你别拿去跟官方掰扯,但逻辑是对的:假设每个 skill 描述平均 80 token,你装了 20 个,每次对话光描述这块就 1600 token 常驻。一天跟 Claude 唠 50 个来回,那就是 8 万 token 在烧”我有这些 skill 待命”这件事——而其中也许只有 5 个 skill 当天真的被召唤过。
剩下的 15 个,整天躺着收”挂号费”。
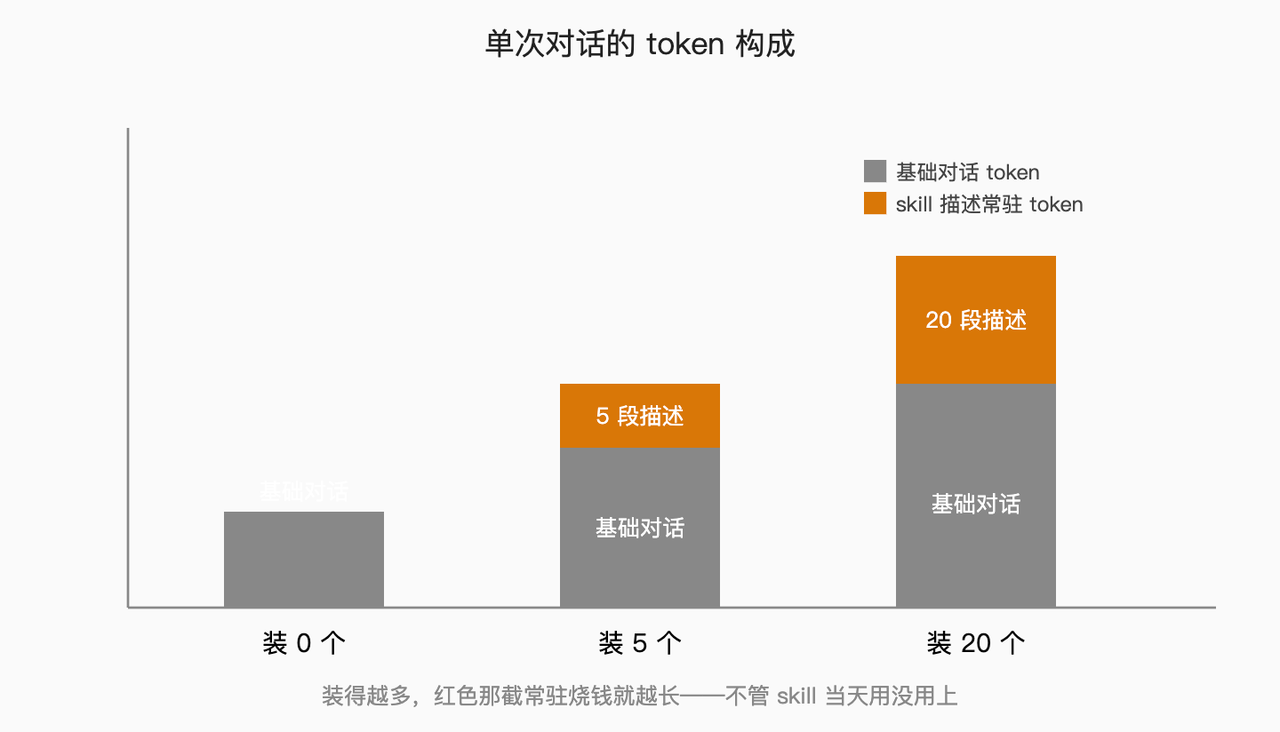
所以渐进式披露省的是变量——skill 正文按需加载,没用到的就不烧。但它没省常量——描述是固定开销,装多少就常驻多少。
省了大头,还是省了。这账长期看大概率是赚的。但前提是——你装的 skill 真的会被用上。如果你装了一堆”以备不时之需”,结果两个月一次都没召唤过,那这堆 skill 的描述就是纯纯的烧钱常量,半点用没有。
这就解释了开头那哥们儿账单为啥涨。他装的 8 个 skill 里,大概有一半儿是”看着挺酷就装上”的——画架构图的、画 ER 图的、生成单元测试覆盖率报告的,这些他实际工作里一个月用不上一次。但它们的描述每天每时每刻都在他的上下文里站岗。
所以 skill 省 token 是真的,但它只在你真用得上的那部分身上省钱。装多了,省的没省那么多,烧的反而比想的多。但这还不是最离谱的——最离谱的是下面这件事。
三、烂描述比不装还烧钱——误触发是隐形税
刚才说常驻的描述每天躺着收挂号费,那是温和的烧法——一点一点烧,你不细看账单根本注意不到。
下面这种烧法是暴力的——一下子就给你撅好几千 token,你都不知道为啥。
这事儿叫误触发。
误触发的原理特简单:你的 skill 描述写得模糊,模型分不清啥时候该召唤它。本来不归它管的问题,模型一犹豫,也把它召唤进来了。这一召唤可不是召唤个描述,是把整个 skill 的正文——动辄几千上万 token——全部塞进上下文。
你问一句”今儿天气咋样”,结果它给你召唤进来一个写测试的 skill。这 skill 正文五千字,全是 pytest 怎么用、fixture 怎么写、mock 怎么 mock。跟天气有一毛钱关系吗?没有。但这五千字已经塞进去了,已经烧了。
这就是隐形税。你交了钱,连个吭都没听见。
烂描述长啥样?我光凭记忆就能给你列出一堆,但最常见的就这几种。
一种是描述太宽泛。比如有个 skill 叫”代码助手”,描述写的是”帮助处理各种代码相关问题”。这描述等于没写——啥问题不算代码相关?你随便问一句”我这函数咋优化”,它跳出来;你问一句”数据库咋选”,它也跳出来;你问一句”Linux 命令怎么用”,它还跳出来。这 skill 一天召唤十几次,召唤进来又没派上用场——因为它根本不是为这些具体场景准备的。
还有一种是关键词堆砌。有些人写 skill 描述跟写 SEO 标题似的——把所有沾边的词都堆上:”Python、JavaScript、Go、Rust、TypeScript、代码生成、代码审查、性能优化、bug 修复、架构设计……” 堆得越多,模型越分不清重点。结果就是只要问题里有任何一个词命中,它就跳出来。
最隐蔽的一种是意图模糊——描述只说了”做什么”,没说”什么情况下不该用”。一个好的描述应该是”当用户问 X 类问题、且不是 Y 情况时召唤我”。但大部分人写的描述只有前半句,后半句省了。模型没有边界,就只能宁可错杀不可放过。
这几种烂描述合起来一个效果——你装了一堆 skill,它们互相之间没有清晰的边界,每次对话都在抢着出场。出场不仅没解决问题,还每次给你白烧几千 token 的正文。
我那哥们儿账单涨三成,大头其实就在这儿。他装的 8 个 skill 里有 3 个描述写得稀烂——”帮你写更好的代码””提供专业建议””解决你的开发难题”——这描述比没描述还坑,因为它让模型完全无法判断边界。结果就是几乎每次对话都把这仨揪进来,每次都烧三千多 token,三千多 token 啥也没干,就是白塞了一段不相干的指令。
skill 描述写不好,不是没省钱的问题,是反过来比不装还烧钱的问题。不装它,你顶多是 prompt 写得长点儿——你写多少烧多少,明明白白。装了它写得烂,你每次对话都被一个莫名其妙的 skill 正文”加塞”,你都不知道自己付的是啥钱。
这事儿听起来挺玄学,其实有个挺简单的自检方法——你打开 Claude 跟它聊一天,每次它召唤 skill 的时候你都问一句”刚才召唤这个 skill 是必要的吗”。聊一周下来你心里就有数了——哪几个 skill 出场频率高得离谱,那就是描述有问题,得重写或者直接卸载。
可大部分人不会这么干。大部分人装上 skill 就完事儿了,从来不回头审。所以才有那么多人抱怨”skill 不省 token”——不是它不省,是你自己装了几个会偷东西的二房东,还纳闷自己钱包咋瘪了。
四、和 MCP 比一比,你才看清 skill 到底省在哪
说到这儿得插一句——skill 跟 MCP,我见过太多人混着用,混完了账单双倍涨,还不知道咋回事。这事儿得单说。
咱先把这俩拆开看。
MCP 是工具调用协议。它解决的问题是——模型本身没有的”动作能力”,比如查天气、读文件、调数据库、发请求。装一个 MCP,相当于给模型递了一把锤子。它需要锤东西的时候,把锤子拿起来用一下。
skill 是知识装载机制。它解决的问题是——模型本身没有的”专属知识或流程”,比如你团队的代码规范、某个项目的架构图、某个行业的术语表。装一个 skill,相当于给模型挂一本你们公司的内部手册。它需要查的时候,翻出来对一下。
MCP 是工具,skill 是手册。这俩性质就不一样——前者让模型能干事儿,后者让模型知道事儿。
烧钱的逻辑也完全不一样。
MCP 省的是动作 token——本来模型要费一大段文字描述”我现在要去查天气,怎么查呢,先 curl 这个 API,然后解析返回的 JSON……”,有了 MCP 它直接调一个函数,几个 token 搞定。省的是描述动作的那段啰嗦。
skill 省的是上下文 token——本来你要把团队规范打在每次 prompt 里,几千字常驻,有了 skill 这几千字平时挂着,需要时才进场。省的是反复贴长文档的那段冗余。
这俩省的根本不是同一段。
那啥叫混着用双倍烧钱?
我见过最典型的一种用法——把 MCP 当 skill 用。比如有人写了个 MCP,里面塞了一大坨团队规范文档,让 Claude 每次调这个 MCP 就把规范拉出来。表面上看挺聪明——MCP 是按需调用的嘛,平时不在上下文里。
问题是 MCP 调用一次就完整塞进上下文。你这不就是把一个本该用 skill 解决的”知识装载”问题,硬塞进了一个 MCP 的壳里?结果就是每次调用都把几千字规范塞进去——而真要写 skill 的话,模型可以只加载相关的几段。
反过来也有——把 skill 当 MCP 用。比如有人写了个 skill 叫”调用内部 API”,正文里全是各种 API 的 URL、参数、示例。Claude 召唤这个 skill 把正文加载进来——加载进来又能咋样?它还是没法真的去调那个 API,它没工具啊。这事儿本该用 MCP 解决的——给它一个真正能发起请求的函数。结果你给了它一堆没用的文档,加载一次烧一次。
这俩用反了,等于花了两倍的 token,干了一半儿的活儿。
正确的活法是——动作的事儿归 MCP,知识的事儿归 skill。你要让 Claude 真的去做一件事,写 MCP。你要让 Claude 知道一件事,写 skill。这俩配合起来才不冲突。
说白了就是,别混用。混了吃亏的是你自己。
五、真正烧 token 的从来不是 skill,是用 skill 的那个人
技术机制是冷的,使用习惯是热的。
skill 这个机制本身没啥可争论的——它就是个按需加载的封装层。它不会主动多烧你的钱,它的所有行为都是被动响应。响应啥?响应你怎么配置、怎么描述、怎么管理。
同一个 skill,给两个不同的人用,账单能差出好几倍。
一个人装之前会想——这玩意儿我是真用得上吗?一周能用几次?描述边界清楚吗?跟我现有的 skill 有没有重叠?想清楚才装。装完一周回头看——这周用了几次?没用上的那次是不是误触发?描述需不需要调?
另一个人装之前不想——这玩意儿看着酷,先装上。出问题再说。装完一个月——账单涨了。账单涨完——抱怨 skill 不省 token。
你看,俩人面对的是同一个 skill,得到的是俩世界。差别在哪儿?差在敢不敢卸载。
我那哥们儿最后干的事儿,就是把那 8 个 skill 卸载到 2 个。卸载的过程他跟我说挺难受的——每卸一个都觉得”万一以后用得上呢”。但他后来想明白了——以后用得上的时候再装回来,比每天让它白白烧着钱强。
会装 skill 的人现在满地都是。点几下鼠标的事儿,谁不会。
会卸载 skill 的人少。因为卸载这事儿要求你承认——我之前装这个就是冲动消费。
承认这事儿挺难的。装的时候你脑子里全是”以后用得上”的幻想,卸的时候你脑子里全是”万一用得上”的恐惧。装是加法,卸是减法。AI 工具时代大部分人只会做加法。
但 token 这账,加法是要付钱的,减法才是省钱的开始。
写描述这事儿也一样。一个 skill 描述好不好,不在于词多不多、看着专不专业,在于你有没有想清楚它的边界——它要管啥、不管啥、什么情况下绝对别召唤它。这件事的难处不在于技术,在于你愿不愿意花一下午时间,把这几行字反复打磨。
大部分人不愿意。装 skill 三十秒,写描述五分钟,从此以后让模型自己慢慢误触发去吧——反正烧的不是自己电费。
但 API 账单是自己付的。
所以这篇文章绕了一大圈,结论就这一句话——skill 省不省 token,从来不是 skill 这个东西本身的问题,是你这个人有没有认真配置它的问题。
你愿意花时间想清楚装啥、卸啥、描述咋写、跟 MCP 咋分工——它就老老实实给你省钱。
你不愿意——它就老老实实给你烧钱。
中间那只手是你的。
最后说回开头那哥们儿。他卸载完之后,剩下的 2 个 skill 一个是”团队代码规范”,一个是”项目架构上下文”。这俩他每天都用十几回,描述写得也清楚——只在跟当前项目代码相关的提问里召唤,其他场景一律不出场。
省下来的钱呢?他拿去续了个 Pro 订阅。
这就是 AI 工具时代一个挺扎心的事儿——你以为你在用工具,其实工具在筛选用人。
会用的人越用越省,不会用的人越用越亏,机制是同一个。
你抱怨 skill 不省 token 那个样儿,跟当年抱怨 ChatGPT 答得烂那个样儿,是一回事儿。问题从来不在它身上。
中,今儿就唠到这儿。下次再有人跟你说”装 skill 能省 98% token”——你别急着装,先问他一句:你 skill 描述写得咋样?
本文由 @兜得Grace 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


