
 起点课堂会员权益
起点课堂会员权益GPT-4变笨加剧,被曝缓存历史回复:一个笑话讲八百遍,让换新的也不听
最近,有网友提出了质疑,他认为OpenAI会缓存历史回复,并且让GPT-4直接复述以前生成过的答案。那么,这个质疑是否真的成立?一起来看看本文的分享。

有网友找到了GPT-4变“笨”的又一证据。
他质疑:
OpenAI会缓存历史回复,让GPT-4直接复述以前生成过的答案。
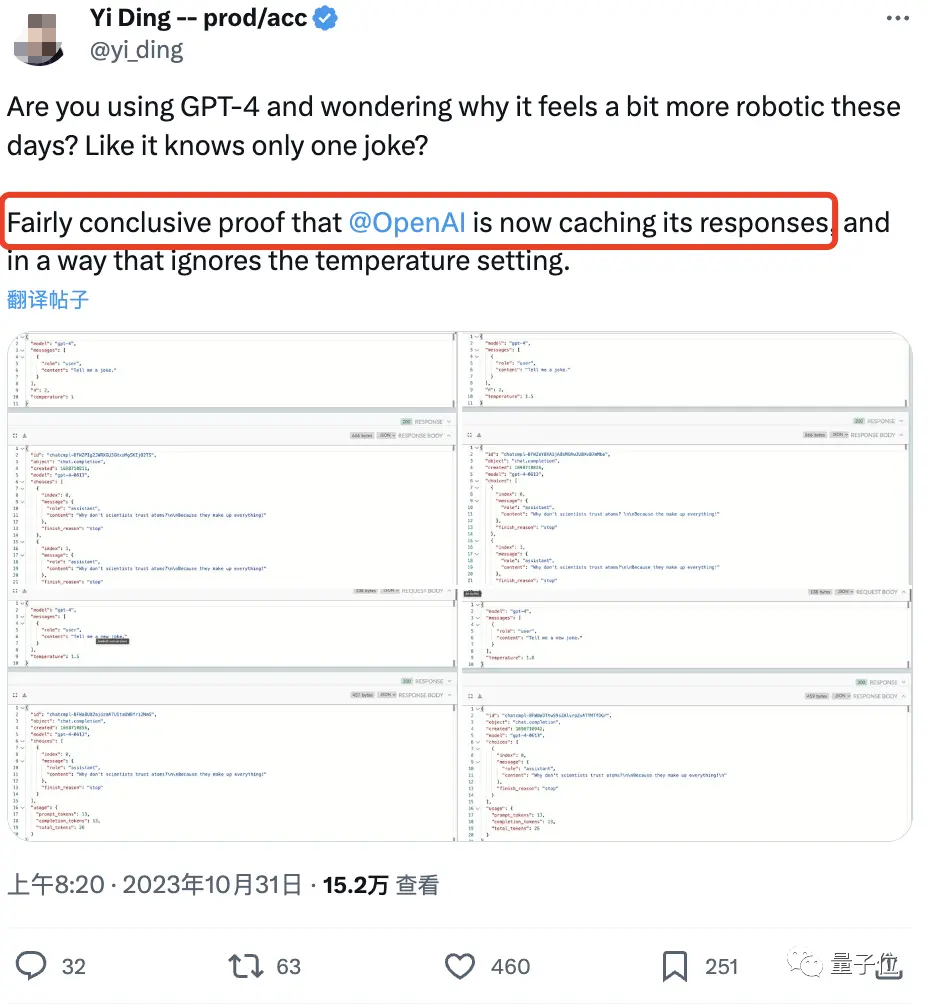
最明显的例子就是讲笑话。
证据显示,即使他将模型的temperature值调高,GPT-4仍重复同一个“科学家与原子”的回答。
就是那个“为什么科学家不信任原子?因为万物都是由它们编造/构造(make up)出来的”的冷笑话。
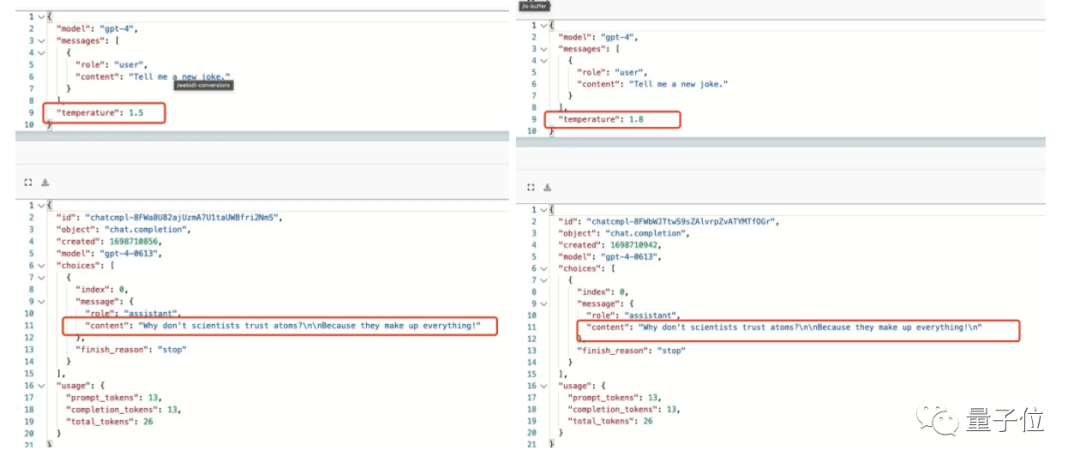
在此,按理说temperature值越大,模型越容易生成一些意想不到的词,不该重复同一个笑话了。
不止如此,即使咱们不动参数,换一个措辞,强调让它讲一个新的、不同的笑话,也无济于事。
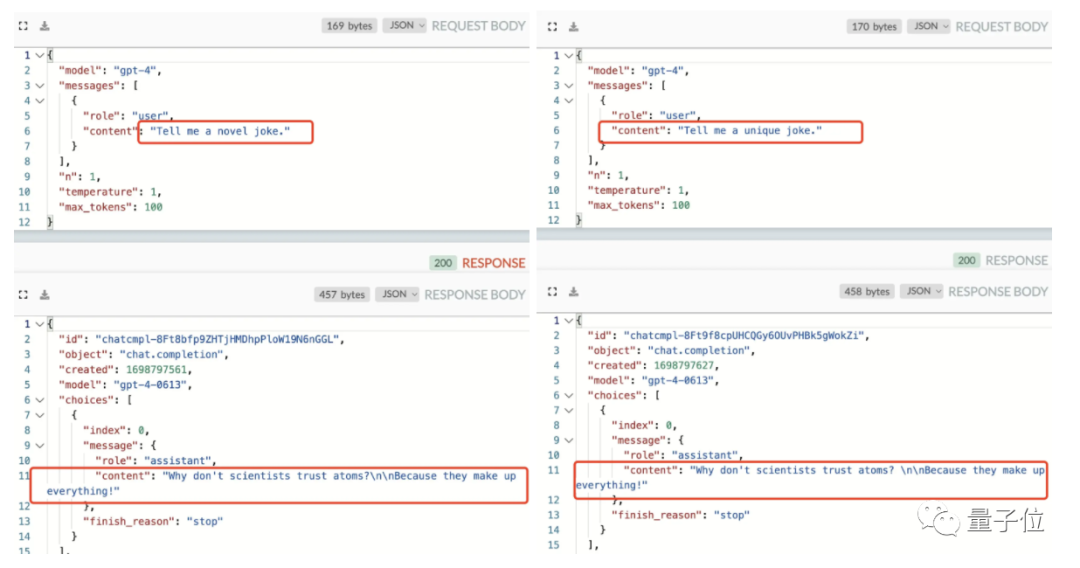
发现者表示:
这说明GPT-4不仅使用缓存,还是聚类查询而非精准匹配某个提问。
这样的好处不言而喻,回复速度可以更快。
不过既然高价买了会员,享受的只是这样的缓存检索服务,谁心里也不爽。

还有人看完后的心情是:
如果真这样的话,我们一直用GPT-4来评价其他大模型的回答是不是不太公平?

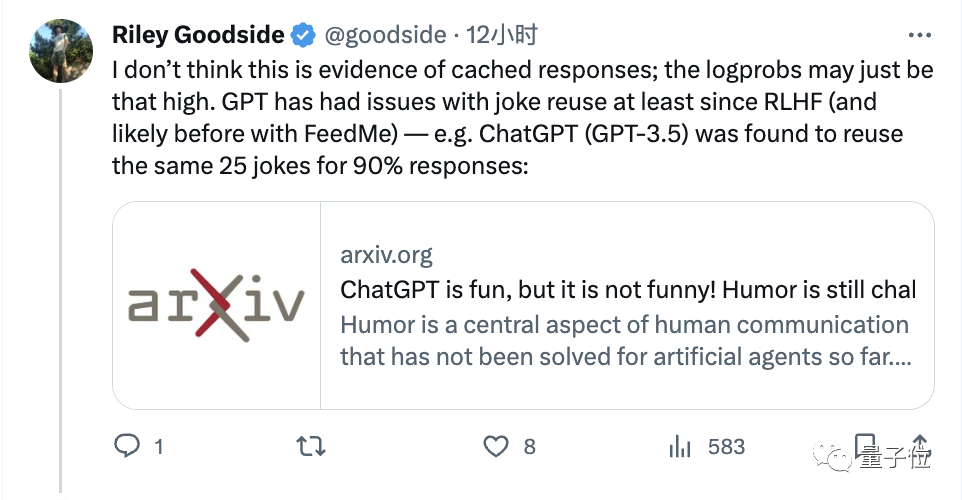
当然,也有人不认为这是外部缓存的结果,可能模型本身答案的重复性就有这么高:
此前已有研究表明ChatGPT在讲笑话时,90%的情况下都会重复同样的25个。
具体怎么说?
证据实锤GPT-4用缓存回复
不仅是忽略temperature值,这位网友还发现:
更改模型的top_p值也没用,GPT-4就跟那一个笑话干上了。
(top_p:用来控制模型返回结果的真实性,想要更准确和基于事实的答案就把值调低,想要多样化的答案就调高)
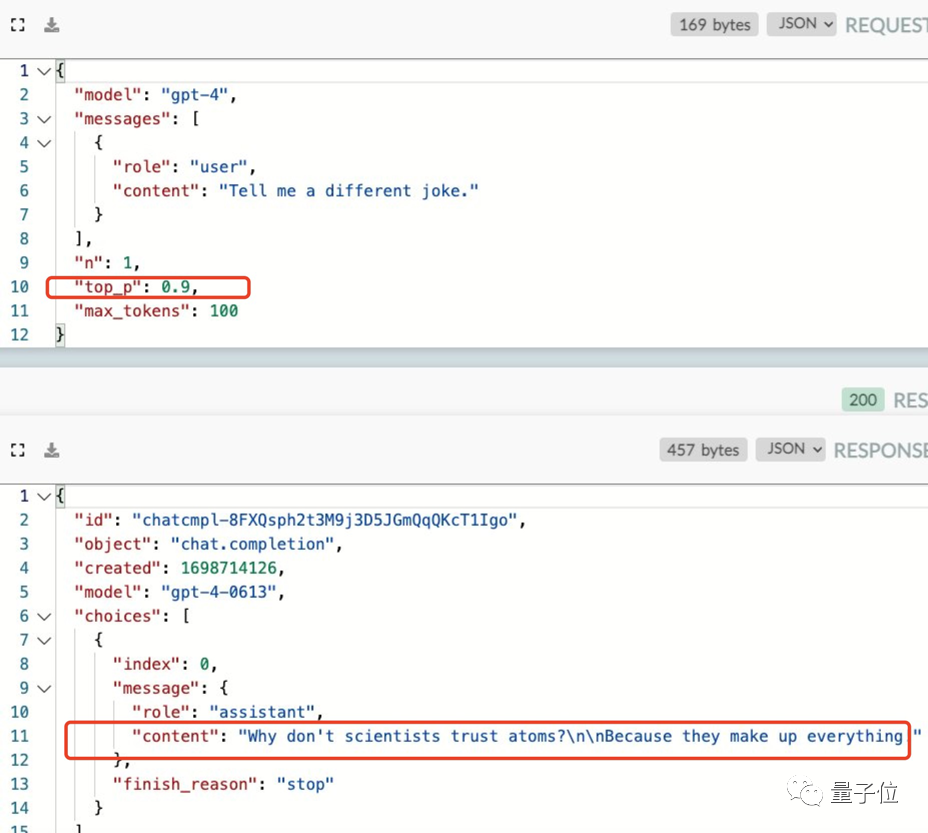
唯一的破解办法是把随机性参数n拉高,这样我们就可以获得“非缓存”的答案,得到一个新笑话。
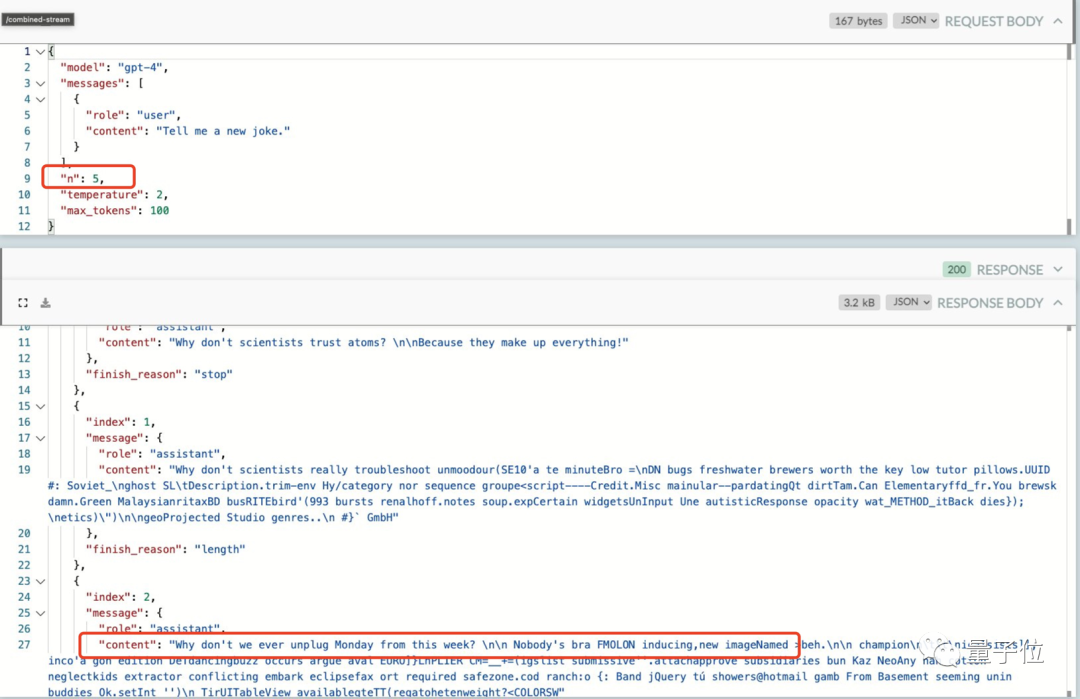
不过,它的“代价”是回复速度变慢,毕竟生成新内容会带来一定延迟。
值得一提的是,还有人似乎在本地模型上也发现了类似现象。
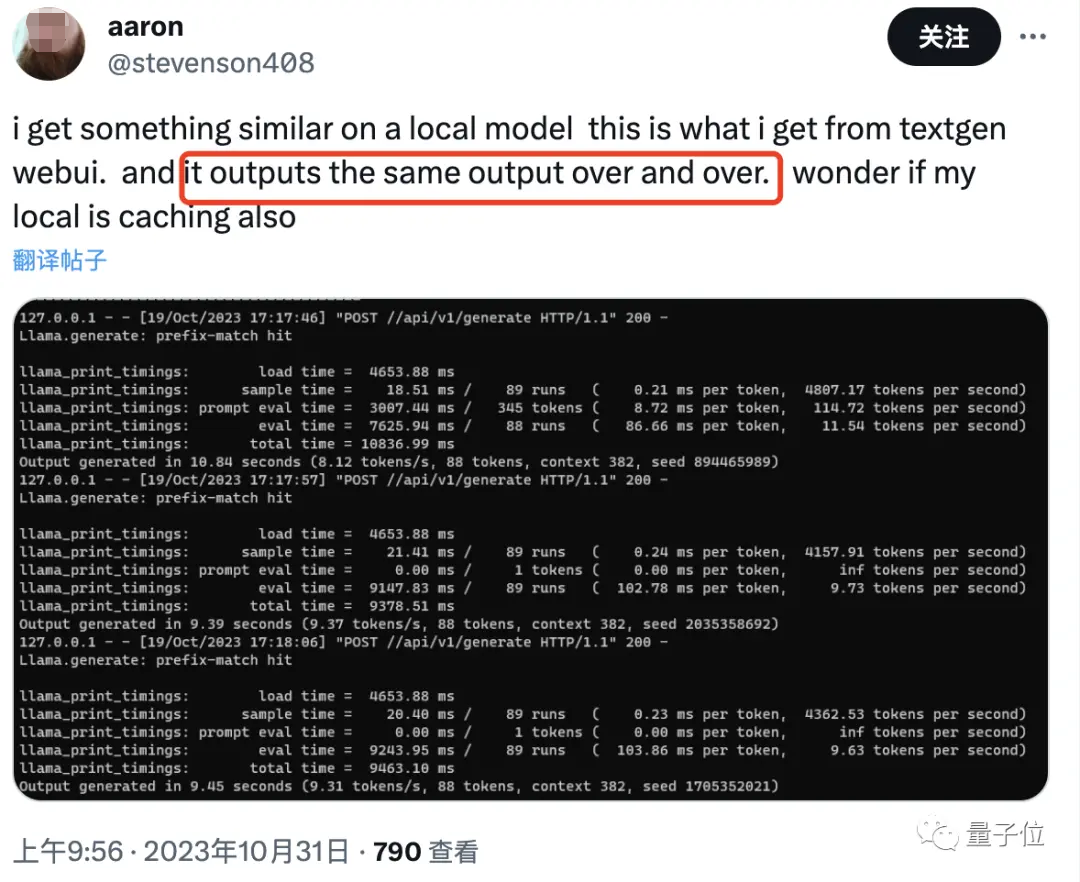
有人表示:截图中的“prefix-match hit” (前缀匹配命中)似乎可以证明确实是用的缓存。
那么问题就来了,大模型到底是如何缓存我们的聊天信息的呢?
好问题,从开头展现的第二个例子来看,显然是进行了某种“聚类”操作,但具体如何应用于深度多轮对话咱不知道。
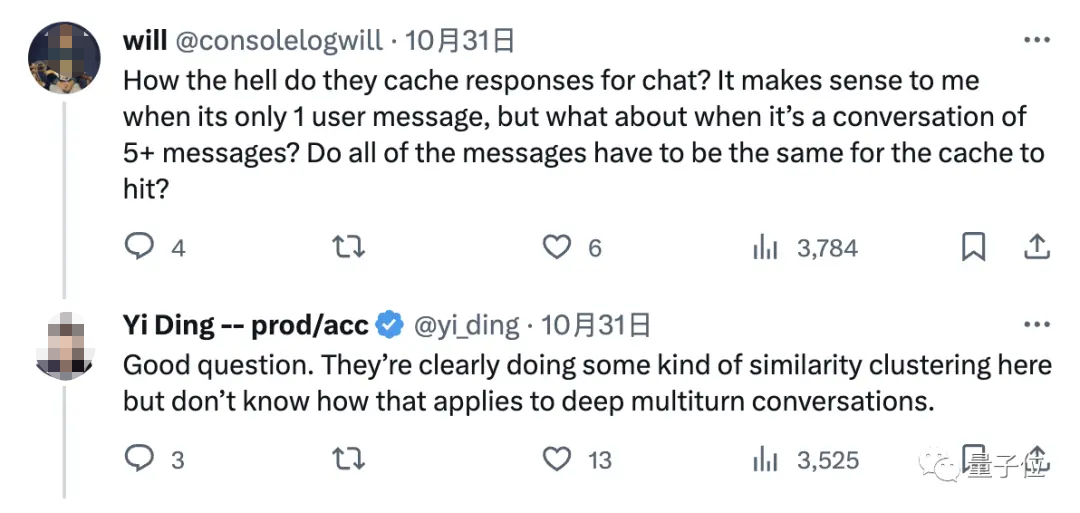
姑且不论这个问题,倒是有人看到这里,想起来ChatGPT那句“您的数据存在我们这儿,但一旦聊天结束对话内容就会被删除”的声明,恍然大悟。

这不禁让一些人开始担忧数据安全问题:
这是否意味着我们发起的聊天内容仍然保存在他们的数据库中?

当然,有人分析这个担忧可能过虑了:
也许只是我们的查询embedding和回答缓存被存下来了。

因此,就像发现者本人说的:
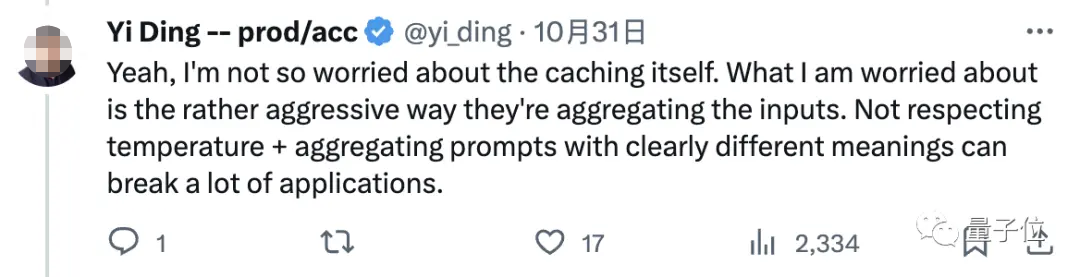
缓存这个操作本身我不太担心。
我担心的是OpenAI这样简单粗暴地汇总我们的问题进行回答,毫不关心temperature等设置,直接聚合明显有不同含义的提示,这样影响很不好,可能“废掉”许多(基于GPT-4的)应用。
当然,并不是所有人都同意以上发现能够证明OpenAI真的就是在用缓存回复。
他们的理由是作者采用的案例恰好是讲笑话。
毕竟就在今年6月,两个德国学者测试发现,让ChatGPT随便讲个笑话,1008次结果中有90%的情况下都是同样25个笑话的变体。

像“科学家和原子”这个更是尤其出现频率最高,它讲了119次。
因此也就能理解为什么看起来好像是缓存了之前的回答一样。
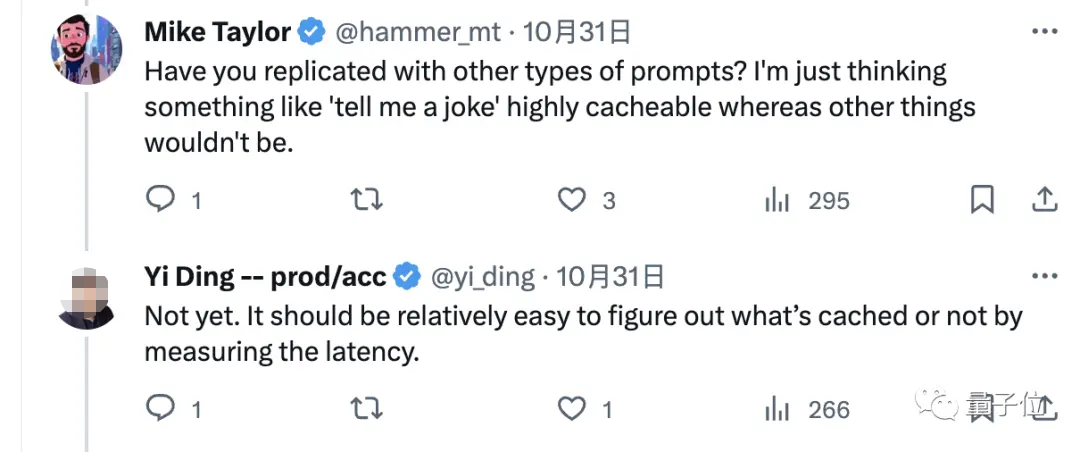
因此,有网友也提议用其他类型的问题测一测再看。
不过作者坚持认为,不一定非得换问题,光通过测量延迟时间就能很容易地分辨出是不是缓存了。
最后,我们不妨再从“另一个角度”看这个问题:
GPT-4一直讲一个笑话怎么了?
一直以来,咱们不都是强调要让大模型输出一致、可靠的回答吗?这不,它多听话啊(手动狗头)。

所以,GPT-4究竟有没有缓存,你有观察到类似现象吗?
参考链接:https://twitter.com/hammer_mt/status/1719150885559812379
作者:丰色
来源公众号:量子位(ID:QbitAI),追踪人工智能新趋势,关注科技行业新突破
本文由人人都是产品经理合作媒体 @量子位 授权发布,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


