
 起点课堂会员权益
起点课堂会员权益被高估的Pika,被低估的多模态AI
最近,多模态 AI 成为了大模型圈的关键词之一,在最近一些产品如 Pika 1.0、谷歌 Gemini 的表现中可以看到,多模态 AI 正在为 AI 应用带来更多可能性。怎么理解多模态 AI 给我们带来的想象力?产品如Pika 1.0 的表现又如何?一起来看看本文的解读。

多模态 AI 正处于爆发前夜。
从 GPT-4V 的“惊艳亮相”,到 AI 视频生成工具 Pika 1.0 的“火爆出圈”,再到谷歌 Gemini 的“全面领先”,多模态 AI 都是其中的关键词。
尽管 Pika 1.0 的宣传视频被一些用户认为是“炒作”,亦或谷歌承认 Gemini 的演示视频“经过剪辑”,但不能否认,它们丰富了人们对多模态 AI 的想象力。
“之前很多公司都在卷文本大模型,GPT-4V 的出现代表多模态大模型可落地,毫无疑问明年大家都会卷多模态AI,原因很简单,因为 OpenAI 说明这条路是能够走得通。”微博新技术研发负责人、AI 首席科学家张俊林说。
在行业主语为“落地”的当下,多模态 AI 正走向场景化、实用化、商业化。例如,在医疗领域可以通过结合图像、录音和病历文本,提供更准确的诊断和治疗方案;在交通领域,结合图像和传感器数据,带来更智能、更安全的自动驾驶体验;在教育领域,将文本、声音、视频相结合,呈现更具互动性的教育内容。
但是业界一直在提多模态的概念,远没有近期几个现象级产品的演示那么直观:多模态不仅可以为 AI 应用带来更多可能性,还是实现通用人工智能的重要路径。
一、Pika:实力还是炒作?
最近的 AI 圈的饭局上,大家聊到多模态 AI ,往往都会提到一家硅谷的初创公司—— Pika Labs。
公司初创团队只有 4 个人,创始人兼 CEO 郭文景有“女学霸”“斯坦福退学创业”“上市公司创始人女儿”等个人标签; Pika 三轮融资已筹款 5500 万美元,估值在 2-3 亿美元之间;投资者包括 Quora 创始人兼CEO Adam D’angelo 、 OpenAI 科学家 Andrej Karpathy、Hugging Face 联合创始人兼CEO Clem Delangue、YC 合伙人 Daniel Gross 等人。
这些都加起来,可以说 Pika 的爆火是在发展过程中,讲了一个技术、商业、资本、用户都感兴趣的故事,而且赶上了一个好的时机。
“今年6月份之后,AI生成图片的投资变得比较保守,很多投资人会更关注 AI 生成视频。”从事 AI 生成视频研究的浦林(化名)告诉「甲子光年」,自有 AIGC 概念开始,无论是 AI 生成图片还是 AI 生成视频都很热,但是基于技术的发展程度,业内预计今年年底,AI 生成视频会有一个不错的 demo 出现。“这个 demo 足够吸引很多的流量,甚至出圈,有这样的信心,那投资的逻辑就能走下去了。可以说, Pika 占到一个很好的时间点。”
Pika 1.0 推出的当天,科技圈大佬们纷纷为其站台。
自然语言处理领域著名学者 Christopher Manning 称赞 Pika 的两位创始人郭文景和孟晨琳推动了高质量视频的快速发展;OpenAI 科学家 Andrej Karpathy 在社交平台上转发了 Pika 1.0 的演示内容并表示:“每个人都能成为多模态梦想的导演,就像《盗梦空间》中的建筑师一样。”
Pika 1.0 火爆出圈,离不开一段官方宣传视频。视频中,用户只要输入“马斯克穿着太空服,3D 动画”,就生成了一段视频。
Pika 1.0 官方宣传视频中其它演示也可以用“惊艳”来形容,视频发布后,已经有媒体迫不及待地称“AI 生成视频的 ChatGPT 时刻即将达来”。
但是,Pika 真的如宣传视频上所展现的那么“惊艳”吗?
今年 7 月,Pika Labs 就在 Discord 推出服务器,短短几个月时间内收获了 50 万用户。不过,想使用最新的 Pika 1.0 ,在官网可能还需一段时间的排队。但在 Discord 上,许多用户已经晒出了测试视频。
目前,Pika 1.0 还只能生成 3 秒展示视频。在社群中,用户 A 输入提示词: A dragon fly in sky(一条龙在天上飞)。这个表达是比较清晰明确的,但输出的视频结果却和龙毫不相关,更像一个克苏鲁生物。
而用户 B 输入了更为细致的提示词:female priest – dnd character – in battle pose – character select default animation – camera zoom in – motion 1(女性牧师 – 龙与地下城角色 – 战斗姿势 – 角色选择默认动画 – 摄像头放大 – 动作1)。
这次 Pika 1.0 输出的视频结果大体相符要求,但细节依然有明显缺陷,角色的手部构图“惨不忍睹”。不过,“AI 不会数数”是存在已久的问题,并非 Pika 独有的“瑕疵”。
但也不乏效果惊艳的案例,比如用户 C 提供了图片并输入提示词:stranded medieval ship, violent sea, rain, clifs, slow motion, -motion 2 -gs22 -camera pan right Image: 1 Attachment(搁浅的中世纪船只、汹涌的海浪、雨水、悬崖、慢动作、动作2 、gs22 -摄像机向右平移、图像:附件1),生成的视频效果较为精美。
AI 教育者 Chase Lean 在试用了 Pika 1.0 后难掩激动之情,他在社交媒体上直言这是他“使用过的最好的 AI 视频生成器”。
浦林一直在关注Pika及相关产品,从demo和实际使用感受来说,Pika 1.0 已经属于“行业领先水平”。
对于AI生成视频工具,最为简单的评判标准就是“生成的内容是否真实”。在技术上,Pika 在单帧画面拟真程度、美学质量以及视频的动作感上表现出色,在文生视频、图生视频的能力和运镜上也有不错的能力展示。除算法外,社区活跃度也被认为是初创公司核心竞争力的一部分,包括维护 Discord 社区等。目前,Pika 的社区活跃度位列业内前茅。
在图像和视频生成方面,业内主流技术路线为Diffusion Model(扩散模型)。不过Pika联合创始人孟晨琳在接受采访时透露:“Pika 也不能完全算 Diffusion Model,我们开发了很多新东西,是一种新的模型。”
不过在浦林看来,Pika 与其它AI生成视频工具(如 Runway )“在技术上没有本质差别”,一些自媒体对 Pika 和 Runway 的对比分析“纯粹是经验归纳”。
这也就会带来一个问题,长期关注AI领域的投资人辰逸(化名)向「甲子光年」表达了他的担忧:“Diffusion Model 不是智能的。它主要根据过去图像的经验拟合出符合人类审美的图像,并不具备理解语言和智能思考的能力。而当我们在使用 ChatGPT 时,会有在和真人对话的感觉,虽然这个「人」的智商可能忽高忽低。”
辰逸认为,尽管Pika爆火离不开产品实力,但“炒作”成分更多些。
“就像炒土豆丝,每个人使用的厨具、调味料等可能大不相同,但原材料归根结底都是土豆。”辰逸比喻道,“理解语言的根本问题并没有解决,图像学还缺少一个飞跃的时刻。”
而在回答“AI 视频生成什么时候会迎来 GPT 时刻”的问题时,Pika团队还是比较清醒的,孟晨琳认为,目前视频生成处于类似 GPT-2 的时期,“很可能在未来一年内有一个显著的提升”。
Pika 的能力在某种程度上被高估了,但 Pika 带来的破圈效果是从业者乐于见到的。浦林五年前就进入了 AI 生成视频领域,最近这半年是他觉得这个领域“最火”的一段时间,尽管他也觉得 Pika “在宣传上比较用力”,但是从专业角度分析,他相信 4 个人的团队做出 Pika 是“没问题的”。
二、争夺AI视频生成高地
从技术视角来看,有业内学者认为,相对于文本、代码和图片生成,文生视频(Text-to-Video)是 AIGC 的“高地”,因为这个领域存在着算力需求大、高质量数据集短缺、可控性较差等挑战。
浦林认为,AI视频生成领域还有一个难题,即生产和研究之间存在的差距。
研究者往往难在第一时间将研究成果应用于实际,因为不同的视频制作者,比如电影、动画、短剧的制作者,有着不同的制作流程,而研究中可能只涉及一种特定的生产方式,比如文本到视频。
浦林近期也在产业中调研,通过和电影制片方的交流不断优化自己的研究方向。“解决难题的关键在于开发的工具能否真正满足视频制作者的需求,并与其实际工作流程相契合。”浦林告诉「甲子光年」,“当你的研究越靠近生产的时候,它会产生更大的经济价值。”
商汤科技数字文娱事业部副总裁李星冶表示,多模态 AI 中门槛比较高的就是文生视频,“现在一些广告视频的制作,只要录入文本就能生成视频,当然目前效率还没有那么高,视频像素可以达到 4K 或者 8K,但是动画效果还比较简单。”
AI 视频生成领域,赛道也愈发拥挤起来。尽管 Pika 备受瞩目,但接下来它仍需面对不断增多的竞争。
Runway 推出了动态笔刷新功能 Motion Brush,用户只需在图片上轻轻一划,即可将其转化为动态视频。另外,Runway 还与电影制作公司展开了紧密合作。
Stability AI公司发布了其 Stable Video Diffusion 视频模型,用户可根据需要调整各种参数,如迭代步数、重绘幅度等,以协助创作者精确掌控画面生成过程,包括风格、姿势和线条等特征。
除此之外,现象级文生图工具 Midjourney 也正在着手开发视频功能;Meta 也推出了两项基于人工智能的视频编辑新功能。
而在开源方面,AnimateDiff、MAKEAVIDEO、MagicAnimate等也在布局 AI 视频生成赛道。
三、多模态AI的想象
对于投资人来说,多模态AI也是今年下半年的关注焦点。
长期关注AI领域投资的心资本合伙人吴炳见认为,大语言模型只是AI版图的一部分,基础模型的第一性原理是“predict next token(预测下一个词)”,这个原理有可能带来其它模型。
“如果未来 Transformer或者另外一套算法能够准确预测下一帧,那么视频模型就出来,就有机会解锁下一个抖音级别的内容平台;如果能准确预测下一串动作序列,那么具身智能模型就出来了,就解锁通用机器人了;如果能准确预测下一个蛋白质序列,那么蛋白质模型就出来了,新药研发又可以迈进一大步了;如果能准确预测下一个像素,那么3D模型就出来了,就解锁元宇宙的构建了。”吴炳见说。
在吴炳见看来,待版图完全解锁后,就会有多个基础模型,而很多方向的边际成本会趋近于零,不断解锁新的应用层的机会。
国内的 AI 厂商也在加强对多模态 AI 的投入。昆仑万维在海外进行了 AI 多模态场景探索,其中包括了AI游戏(Club Koala),之前已经在德国科隆游戏展上亮相,预计将于明年上半年进行测试。“这里不仅包括了常见的对话,通过大模型赋能的 AI NPC,也包括 3D 生成等 AIGC 技术,尤其是在 AI 3D 生成方面,我们做得比较领先。”昆仑万维董事长兼 CEO 方汉介绍。
「甲子光年」还关注到一些技术大佬入局。例如,清华大学计算机系 Bosch AI 教授、清华大学人工智能研究院副院长朱军创立的生数科技,专注于多模态层面,致力于打造可控的多模态通用大模型;前字节跳动前视觉技术负责人、AI Lab 总监王长虎创立了爱诗科技,聚焦于生成式 AI 的视觉多模态算法平台。
尽管多模态大模型使AI能够根据图像内容推理复杂问题,但仍无法像视觉感知系统那样在图像上精确定位指令对应的目标区域。因此,香港中文大学贾佳亚团队提出LISA(Large Language Instructed Segmentation Assistant)多模态大模型。LISA通过引入一个<SEG>标记来扩展初始大型模型的词汇表,并采用Embedding-as-Mask(嵌入作为掩码)的范式赋予解释多模态大型模型分割功能,最终展现出强大的零样本泛化能力。
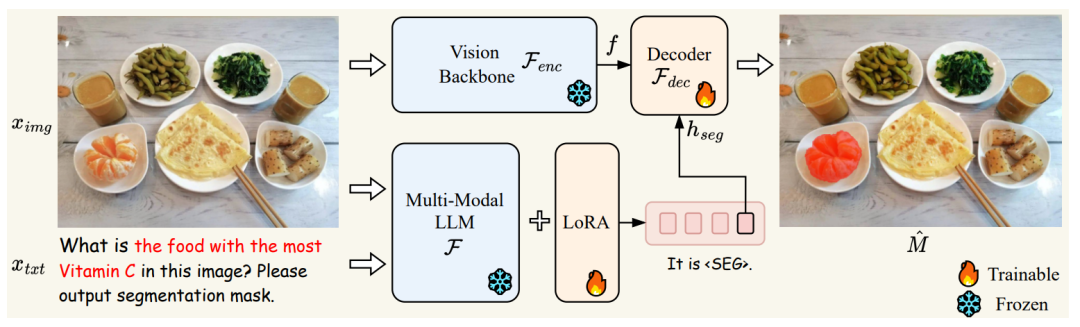
LISA技术方案概述,图片来源:受访者提供
在垂直应用场景上,云知声通过医疗知识增强的山海大模型北京友谊医院打造的门诊病历生成系统,可以在不改变医生问诊方式情况下,通过医生与患者的对话录音,抽取关键问诊信息并生成病历,将医生从病历撰写工作中解放出来,把更多时间留给患者。
谷歌近期重磅推出的 Gemini 也显示了多模态模型在各应用场景中的潜在价值。如何真正打通物理世界和数字世界之间的屏障,关键在于有效处理多模态 AI 能力。用底层的感知能力衍生出操作,从而实现与物理世界最自然的交互方式。
在多模态 AI 爆发之前,不要温和地走进这个良夜。
*应受访对象要求,文中浦林、辰逸为化名
*参考资料:
- 专访Pika Labs创始人:探索视频生成的GPT时刻,海外独角兽
- LISA:通过大语言模型进行推理分割,香港中文大学贾佳亚团队
作者:苏霍伊;编辑:王博
原文标题:被高估的Pika,被低估的多模态AI|甲子光年
来源公众号:甲子光年(ID:jazzyear),立足中国科技创新前沿阵地,动态跟踪头部科技企业发展和传统产业技术升级案例。
本文由人人都是产品经理合作媒体 @甲子光年 授权发布,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


