
 起点课堂会员权益
起点课堂会员权益人工智能中的机器学习核心领域、流程与分支(基础入门篇)
人工智能作为当下新质生产力的代表,其技术更新已经历过很多个版本,随着ChatGPT的火热,AI逐渐进入大众视野,并在衣食住行方方面面影响着人们。AI 是让计算机模拟人类智能的技术,它包括机器学习、自然语言处理、计算机视觉、语音识别等多个领域,通过使用大量的数据和算法,AI 可以让计算机学会像人类一样思考、学习和解决问题。机器学习作为人工智能领域的核心,是使计算机拥有智能的基石,本文对机器学习的核心领域、术语和深度学习与强化学习作简单介绍,不涉及复杂的数学模型,通俗地讲解AI底层知识原理。

一、机器学习
机器学习是人工智能核心,是使计算机具有智能的根本途径,最早可追溯到17世纪,贝叶斯、拉普拉斯关于最小二乘法的推导和马尔可夫链,这些构成了机器学习的使用工具和基础。
可以简单地说AI主要是让计算机去认识我们的数据,我们画一幅画,大家能认识,但是在计算机眼中,这是一个像素点所形成的矩阵,计算机视觉是把我们的图像数据和视频数据,转换成计算机能认识的一些特征或者向量;自然语言处理就是我们把文本数据交给计算机,让计算机能够读懂去认识我们的文本,所以自然语言处理是把文本数据转成计算机所认识的特征;语音识别是把我们的语音信号数据转换成计算机所认识的特征;同样,数据挖掘是把工业当中各个设备,记录的一些传感器的数据转换成计算机所认识的特征。
但是不能把这个四个领域孤立去看,计算机视觉就是解决图像问题,自然语处理解决文本问题,语音识别解决语音数据问题,AI领域被我们分成这么多分支,就是由于输入的数据,即它们的载体是不同的,但是目标一样,就是不论以什么形式作为载体的,人工智能都要把数据转换成一个计算机可计算、可去推理的一个特征、一个向量或者说一个矩阵。
AI领域范围很大,应用也很多,但核心都是机器学习,机器学习里边的核心就叫深度学习了,目前深度学习落地的项目比较多。

1. 机器学习中三大核心领域
机器学习解决的主要问题可分为分类、回归和聚类三个领域。
- 分类:在有限的类别当中选择一个固定的类别。
- 回归:在一个有限的区间当中,预测出来一个值,但这个值并不是固定的一些类别。
- 聚类:在没有标签的时候,做分类。

分类和回归既有数据又有标签,聚类只有数据,目前分类和回归是做得比较多的领域。
2. 机器学习中的有监督与无监督
有监督问题:给定标签,大部分算法事先给出标签。
无监督问题:在没有标签的情况下也能完成建模任务。
来举个例子,我们上学的时候做练习册,做完要对答案,看看错了什么好下回改,这就是有监督,既有数据—我们的练习册,也有标签—我们的答案,就像计算机,它在学的时候知道哪里学对了,哪里学错了,对了的下次就不太注意,错了的会重点修正一下,这叫有监督。
什么叫无监督呢?大家做练习册,做完就拉倒,也没有答案,结果什么样不用管,这就叫无监督。在有监督问题中,需要给数据打标签,相当于告诉计算机标准答案,但打标签是非常耗时间和精力的事,无监督比较节省人力,但是效果远没有有监督的好。

二、机器学习流程
机器学习流程可简单分为四个步骤:
- 数据获取
- 特征工程
- 建立模型
- 评估与应用
1. 数据获取
1)数据获取方式
除开openAI或者Google等世界顶尖AI科技公司,数据相对于算法和开源的项目更重要且有价值,我们去接触一些实际项目的时候,跟企业合作课题做过最多一件事就是签保密协议。
很多有资源的大厂都会有专门数据的标注员,或者外包出去,但是创业型公司会让大家一起标注数据。数据的来源包括但不限于企业的业务数据、购买的数据、摄像机拍的图片数据、由机器传感器获取上传到服务器的数据、后台的日志、爬虫等,但无论什么方式获取,在有监督学习中都需要打标签。
我们一般把数据分成三个部分,分别为:训练集、验证集和测试集。
训练集是给模型提供、让它学习的数据,验证集是优化模型性能的数据集,它不参与学习确定参数的过程,测试集用于验证模型的最终效果。举个例子,我们学习的时候,需要做海量的练习册,这些练习册就是训练集,验证集就是平时期中期末考试的时候看看学习的效果怎么样,有哪些知识点需要弥补或调整,测试集就是最终的高考。通常三者的比例训练集最高,取7:2;1或者6:2:2,按照实际情况来调整,三个数据集不能重叠。
2)数据预处理
我们获取到数据一般都是杂乱无章,没有规律可循,怎样让计算机更好地识别呢?
让我们看看计算机适合处理什么样的数据,举个例子,有个标准化的公式:(x-μ)/θ,μ是均值,下图中,左边是原始数据,中间是减μ去均值,可以发现原始数据的图像并不以原点为中心对称,但是在各个维度去掉均值之后必然以原点为中心对称,右图再进行缩放来减少需要的算力等资源,在计算机眼中对称的数据是能更好地学习的,就像在人眼中,对称的更容易让大脑记住识别。
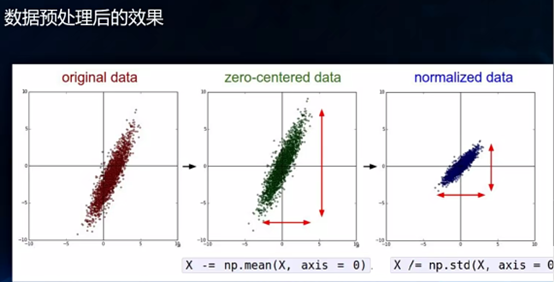
以上就是一种简单的数据预处理的方法,直白地说就是将杂乱无章的数据通过一些数学公式的变换尽可能地将原始数据达到比较有结构或对称的效果,让计算机学起来容易些。一般数据决定了项目的一个上限,算法和模型只是让我们去逼近于这个上限,所以数据处理是整个AI领域必不可少且非常重要的一环。
在计算机看来,数据一般会服从某种分布或规律,我们希望模型能从中学到这种规律或分布,以便有新数据的时候能预测新数据属于什么类别等。
但机器学习并不是万能的,比如在股票行情当中,由于人、市场、政策等诸多因素一直在变,而机器学习的本质是学习历史数据当中分布及规律,用这个规律处理新的数据,我们期望新的数据跟历史数据有几乎一样的特征,这样对于从历史数据中训练的模型能更有效地分辨新数据,而彩票是随机的,如果它服从于某一种分布或规律,那人人都可以轻松中奖。
2. 特征工程
简单地说,特征工程就是计算机从一个预处理后的数据中提取它能理解的特征的过程,这些特征可以很好的表示已经有的数据,比如我们看到的图像、视频、声音等,从而去预测未知的数据,在实际应用中,特征通常按照业务需要来提取。
比如我想预测某位同学的学习成绩,但是我有这位同学特别多的指标,比如游戏的段位等级、学习时间、身高年龄体重家庭住址等等,这些指标不一定跟他成绩都相关,我们需要在所有的数据当中选择一些最重要的特征。
再比如,某新能源科技公司给每个车间流水线上都安装了自动化设备,这些设备去捕捉传感器每个流水线上的一些运行指标,如果他们的需求是想提升工厂的运行效率,该选哪些特征呢?整条生产线上总共有1000多条特征,在这么多特征中选择是件很困难的事,跟业务非常挂钩。
程序员们要实现一个功能,通常不用自己去写源码,会套用现成源码,俗称“调包”,但是在调包之前要先把数据做好,做好数据不是件容易的事,需要非常多的业务知识储备,这些是做好特征工程的前置条件,很多业务的瓶颈就卡在这一步。
3. 建立模型
我们先引入一个简单的公式:y=wx+b,在这个任务当中,y代表实际的值,x代表输入的数据,w是权重参数,b是偏置参数。其中x-输入数据和y-实际值是已知的数据,基于这两个已知条件,我们需要找出什么样的权重参数w和偏置参数b正好符合于目前这个等式,建模就是给定输入数据以及对应的结果,来得出能达到这样的拟合结果的参数的过程,如果已知了权重参数和偏置参数,我们就可以预测以后需要的值。
在十年前,权重参数可达到千万级别的一个量级,而现在chatgpt的权重参数已达千亿级,模型就像是一个黑盒子,我们给一个输入传到盒子里边,它给出一个预测,但是对于千亿级被的盒子究竟做了什么,目前我们人类还不能理解它,所以模型是不一定可解释的。
4. 评估模型
模型不可解释,所以我们对于预测出来的结果不能保证,但我们可以把实际数据拿到模型中去验证,这就是模型的评估。在不同的业务场景中,评估的方法是不同的,最常用的评估指标有准确率、召回率、损失值等。
- 准确率:预测出正确的结果占总样本的百分比。
- 召回率:又叫查全率,是指正确预测出样本占实际这个样本的百分比。
- 损失值:指预测的结果跟真实值比,损失值越小,则模型效果越好。
为了理解这几个指标来举个简单的例子,某块地里面有一堆土豆和西红柿,其中有990个土豆和10个西红柿,现在我们的任务是要把土豆从这一堆里面识别出来,如果按照准确率的指标,计算机准确地识别出了900个土豆和5个西红柿,那准确率也是90.5%,但是显然这么高的准确率并不能反映我们的任务情况,所以使用召回率指标更能说明问题,即在990个土豆里面准确识别出土豆的能力,而不考虑识别出了多少西红柿。
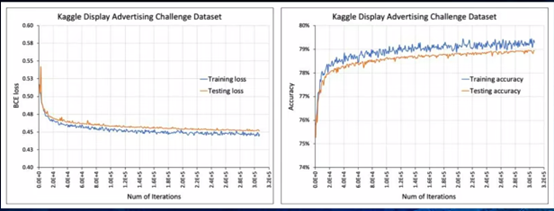
上图中,随着模型训练迭代次数的增加,验证集和测试集的损失值越来越小(左),预测准确度越来越高(右)。我们希望模型能100%正确,但这肯定达不到。
5. 调参
我们通过训练集和测试集来验证模型的准确度,为了使模型更好地拟合数据,需要对模型的参数进行调整,调参很多时候是靠经验或者一些技巧,谷歌曾经提出自动调参的方法,这需要用大量的算力去拟合和尝试,调参对于普通的科技公司来说是很有挑战的一件事。
通过一个例子来说明,我们需要调五个参数,每个参数有五个可能的值,需要5的5次方组实验才能包含所有的结果,那么训练一个模型需要多长时间呢?假如是单卡单GPU,即便是非常强的算力,一般都得以天为单位,而不是以分钟或以小时,假如一天能训练好一个参数的一个可能的值,这已经属于极快了,那训练完参数每个参数五种可能性需要3125天,但是我们不可能过八九年之后再回来看训练好的这个模型,所以说很多时候就是通过经验来调参。
有些规模大的科技公司,比如谷歌facebook用分布式计算方法,2016年谷歌专门为了AI训练而推出了TPU处理器,它采用矩阵乘法的计算方式,为训练节省大量的时间和精力,但这种级别的处理器只有世界龙头企业才能负担得起。
三、深度学习
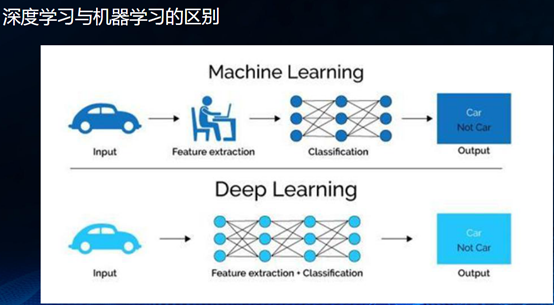
如果说传统的机器学习从获取数据到评估的每一步都需要人工参与,深度学习只要把数据交给模型就行,两者要解决的问题依旧是分类和回归两大核心任务,但深度学习中间过程不用人为去干涉,相当于找了“一条龙”的服务,深度学习模拟人脑的神经网络结构,把很多问题简单化,节省了很多时间和人力成本,可以说,深度学习就是神经网络专场。
深度学习网络结构:
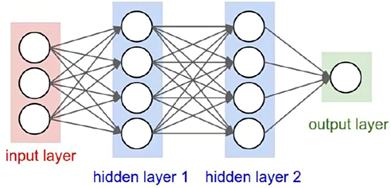
深度学习需要大量的数据和算力,由于目前算力、传输速度等因素,深度学习还不能完全取代传统机器学习。对于计算资源有限、数据规模小的公司来说,机器学习是一种性价比最高的算法,我们常看的短视频特效,如果把这些特效放在本地机器去跑,大部分机器都跑的非常慢,达不到实时性的要求,可能再过几年,随着硬件设备和通信技术的发展,算力和传输速度达到一定程度后,传统机器学习算法没有存在的意义,深度学习会完全取代传统机器学习。
目前深度学习主要应用在计算机视觉、NLP、语音识别领域。
四、强化学习
也许大家都听说过2016年谷歌的人工智能产品AlphaGo与韩国棋手李世石进行的一场围棋比赛事件,AlphaGo获得比赛的胜利,一时间强化学习成为很多公司追捧的热点。
不同于机器学习,强化学习不需要预先给定任何数据,而是通过接收环境对动作的反馈获得学习信息并更新模型的参数,如果说机器学习是输入样本数据-模型-输出数据的链路,强化学习则并不关注某一个样本的结果,而是看全局的结果。
举个例子,我们让一个机器人在一个房间找出口,这个机器人撞门上、踢着人等等给它扣十分,最后走出这个门,给它加100分,它经过了大量尝试之后,最终成功地找到出口,这就叫全局的结果。
强化学习需要大量的模拟数据来训练,通过与环境的交互获得经验,从而让全局收益最大,虽然这个机器人一开始会撞玻璃,但是它撞的时候发现会越扣分,那以后就不会去撞玻璃,当它发现只要走出门就能加很多分,那他会朝着走出门这个结果,将收益最大化。
强化学习的过程需要设计奖励和惩罚机制,是需要监督学习的,并且规则越清晰明确效果越好,由于它不关注训练过程和依赖规则的局限,很多场景无法用强化学习来训练完成,比如自动驾驶,我们可以在训练的时候用假人,遇到撞人、压线、闯红灯等情况给它扣分,按规则正常行驶的时候加分。但是在实际当中,如果出现一些在训练当中没有的突发状况,就不是惩罚扣分的事了,所以目前来看,强化学习在规则明确的游戏领域比较适用,比如游戏当中使用技能会掉多少血等等,这些都是可以量化的指标。
以上简单地介绍了机器学习核心领域、一些术语、机器学习流程与深度学习和强化学习,这只是人工智能领域最基本的要素,之后我还会持续分享AI的有关算法、模型和应用领域。
本文由 @Deii_薇 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









机器学习就像是教电脑“打游戏”,让它从菜鸟变高手,不过有时候它也会“卡关”哦!