
 起点课堂会员权益
起点课堂会员权益AI语音:从分段交互到端到端的全面解析
AI 语音技术正在重新定义人机交互的未来。从智能音箱到车载系统,语音交互的进化不仅提升了用户体验,更在技术层面上实现了突破。本文将深入解析端到端语音大模型的核心逻辑和技术突破,探讨其在社交娱乐和智能家居等场景中的应用与前景。

在人工智能飞速发展的今天,语音交互已成为人机沟通的重要方式。从智能音箱到车载系统,从手机助手到社交应用,AI语音技术正悄然改变我们的生活。
打开智能音箱说一句 “播放今天的新闻”,车载助手自动响应 “导航去公司” 的指令,社交软件里语音消息实时转文字 ——AI 语音早已渗透到生活的方方面面。
传统语音交互链路:如同“传声筒游戏”
流水线的运作原理
传统的语音交互系统遵循着“音频前端处理→语音识别(ASR)→文本处理(NLP)→语音合成(TTS)”的流程,就像一个精细分工的工厂流水线:
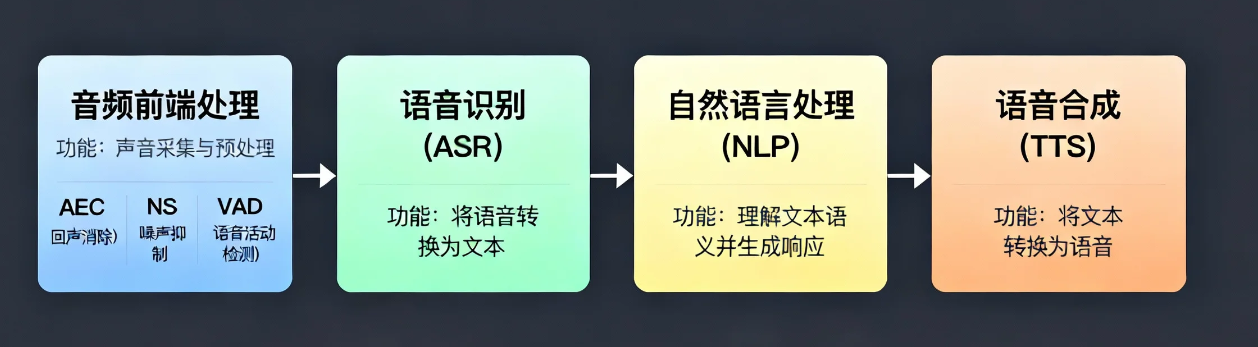
音频前端处理:相当于系统的“净化车间”,负责在语音识别之前对原始音频信号进行清洁和增强
- 声学回声消除(AEC):消除麦克风采集到的系统自身播放的语音回声
- 噪声抑制(NS):抑制环境噪声(背景人声、风声、键盘声等),保留纯净人声
- 语音活动检测(VAD):检测语音信号的存在,区分语音段和静音段
语音识别(ASR):相当于系统的“耳朵”,负责将净化后的声音信号转换为文字
自然语言处理(NLP):相当于系统的“大脑”,理解文字含义并生成回复
语音合成(TTS):相当于系统的“嘴巴”,将文字回复转换为语音
这个过程很像我们儿时玩的“传声筒”游戏:第一个人听到一句话,传给第二个人,第二个人再传给第三个人。信息在传递过程中会逐渐失真。
传统架构的三大痛点
虽然这种“各司其职”的模式技术成熟,但它存在几个明显的弊端:
1)信息丢失严重人的语音不仅是文字,还包含语调、情绪、音色、停顿等丰富信息。ASR 只能提取文字内容,而情绪、语气等副语言信息被完全丢弃。例如,当用户用愤怒的语气说“我不生气”时,机器只会识别文字,无法感知情绪,导致回复不合时宜。
2)误差逐级放大 ASR 听错后,存在很大的概率使得后续的 NLP 和 TTS 都会基于错误信息处理,最终结果可能完全偏离用户本意。(目前产品的策略会通过LLM的意图识别,提升准确率,但是存在错误信息的无法理解&概率,依旧无法规避);
3)响应延迟明显三段式处理意味着数据需要在多个模块间传递,每个模块都需要处理时间。整体延迟通常达到数百毫秒甚至更长,严重影响对话的自然流畅度。在真实对话中,人们期望即时回应,这种延迟会让人感到“机器就是机器”的隔阂。
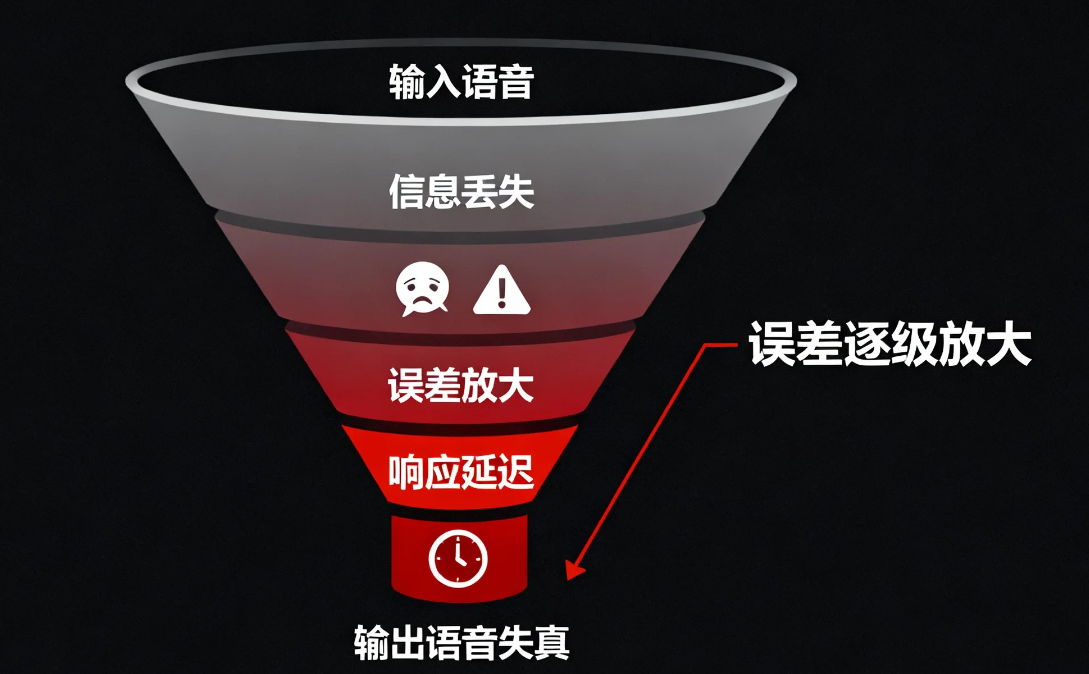
这些问题的根源在于:传统系统把连续的语音信号强行拆解成文本再重组,丢失了语音本身的连续性和丰富性。
端到端语音大模型:实现“语音进,语音出”的跨越
为了解决传统流水线的痛点,研究者们提出了 “端到端” 语音大模型(以 SpeechLM 为代表)—— 它就像一个 “超级大脑”,不需要分段处理,直接把 “声音输入” 变成 “声音输出”,中间没有多余环节。
核心逻辑:跳过 “文字中转”,让声音直接对话
传统架构是 “声音→文字→理解→文字→声音”,而端到端模型是 “声音→理解→声音”,跳过了 “文字中转” 这一步。就像两个人直接用方言聊天,不用先翻译成普通话再沟通,效率更高、信息损失更少。
举个例子:用户用激动的语气说 “今天升职了,想庆祝一下!”,传统架构会先把声音转文字(丢失 “激动” 情绪),NLU 理解 “庆祝需求”,再生成文字 “恭喜呀!想去哪里庆祝?”,TTS 合成平淡的语音;而端到端模型会直接捕捉 “激动” 的语气特征,理解 “庆祝” 意图,生成同样激动的语音回复 “哇!恭喜升职!要不要推荐附近的餐厅呀?”,情绪更贴合。
SpeechLM的核心理念是摒弃多模块串联的传统架构,建立直接从语音到语音的端到端系统。这就像将需要多个翻译的跨国会议,变为双方直接对话——减少中间环节,提升效率保真度。
关键技术突破:语音分词器
语音分词器是SpeechLM的“基石技术”,解决了将连续语音信号转换为离散Token的核心难题。这个过程类似于文本处理中的分词,但技术实现更为复杂。
为什么需要语音分词?
- 语音本质上是连续信号,而大语言模型只能处理离散Token
- 传统ASR和TTS使用不同的特征表示,无法共享“表示空间”
- 语音特有的情绪、韵律等信息无法通过文本传递
三大核心组件:端到端模型的 “三剑客”
端到端模型能实现 “声音直接对话”,全靠三个核心组件,我们用 “搭积木” 来理解:
1)语音分词器:把声音切成 “可识别的积木”
声音是连续的,就像一整块木头,机器无法直接处理。语音分词器的作用就是把这块 “木头” 切成一个个标准化的 “小积木”(离散 Token),让机器能像处理文字一样处理声音。
比如 “我想去海边” 这句话,语音分词器会把连续的声音切成 [wo, xiang, qu, hai, bian] 对应的 Token(每个 Token 是一个数字 ID),这些 Token 不仅包含 “说什么” 的语义,还包含 “怎么说” 的语气、语速特征 —— 比如 “想去” 两个字的音调升高,体现出期待感。
这个组件解决了传统架构的核心问题:ASR 只关注语义,TTS 只关注声学特征,两者 “各说各的”;而语音分词器让 “语义” 和 “声学特征” 打包在同一个 Token 里,机器能同时理解 “说什么” 和 “怎么说”。
2)语言模型:负责 “思考” 的核心
语言模型就像 “积木搭建师”,接收语音分词器的 Token,理解用户意图,然后生成新的 Token 序列(回应的语义 + 声学特征)。
它的工作流程很简单:比如用户输入 Token 序列 [wo, xiang, qu, hai, bian](我想去海边),语言模型会先理解 “用户想前往海边”,再生成回应的 Token 序列 [hao ya, na ni xiang qu na ge hai bian?](好呀,那你想去哪个海边?),这个序列不仅包含文字语义,还标注了 “好呀” 要带微笑语气,“哪个海边” 要稍作停顿。
语言模型有两种工作方式:一种是 “两阶段”(先生成语义 Token,再生成声学 Token),就像先画设计图,再搭积木;另一种是 “单阶段”(直接生成声学 Token),就像直接搭出完整造型,更逼真但可控性稍弱。
3)语音合成器:把 “积木” 拼成 “真实声音”
最后一步是语音合成器,它把语言模型生成的 Token 序列,还原成自然流畅的语音。就像把一堆积木搭成完整的模型,合成器会根据 Token 里的语义和声学特征,生成对应的声音波形。
现代合成器都用 “神经音频解码器”,比如 Meta 的 EnCodec、Google 的 SoundStream,它们能生成 24kHz 高保真音频,不仅能还原音色、语速,还能保留叹气、笑声等细节。比如 Token 里标注了 “激动语气”,合成器会提高音调、加快语速,让回复听起来更真实。
模型的 “学习之路”:三阶段训练法
端到端模型不是天生就会 “听和说”,需要经过三个阶段的训练,就像从 “婴儿学语” 到 “成熟沟通”:
1)第一阶段:模态对齐预训练 —— 学会 “听懂声音”
目标是让模型同时理解声音和文字,就像婴儿同时学说话和认字。训练时会用海量数据:一方面是纯语音数据(播客、广播),让模型学习声音的规律(比如 “你好” 的发音特征);另一方面是语音 – 文字配对数据(比如 “你好” 的声音 + 文字),让模型建立 “声音→文字”“文字→声音” 的映射。
这个阶段会让模型学会 “语音延续”:给前半段声音,预测后半段(比如给 “今天天气”,预测 “真好”),就像婴儿模仿大人说话的节奏。
2)第二阶段:指令微调 —— 学会 “服从指令”
预训练后的模型能 “听懂”,但还不会 “回应”。这个阶段要训练它服从人类指令,比如 “用悲伤的语气复述‘今天天气真好’”“简短回答用户的问题”。
训练数据会做成 “指令 – 回应” 对:比如输入 “[指令:温柔提醒带伞][声音:今天下雨]”,目标输出 “[声音:今天下雨啦,记得带伞哦~]”。为了让模型适应不同场景,还会混入不同语气、不同口音的数据。
3)第三阶段:对齐与强化 —— 学会 “说人话”
最后阶段要解决 “模型胡言乱语” 的问题,让回应更符合人类偏好。比如用户问 “推荐一家餐厅”,模型不能推荐不存在的店铺;用户生气时,回应不能太敷衍。
这里会用到 “偏好对” 训练:比如给模型两个回应,一个是 “自己搜”(不好),一个是 “推荐附近 3 家高分餐厅,需要吗?”(好),让模型学会偏向更好的回应。同时会加入安全过滤,避免生成违规内容。
端到端模型的优势:解决传统架构的 “老大难”
相比传统分段式架构,端到端模型的优势很明显:
- 无信息损失:能保留语音中的情绪、语气、语速等细节,回应更贴合用户状态。比如用户疲惫地说 “导航回家”,模型会用舒缓的语气回复 “好的,已为你规划最短路线,预计 30 分钟到家”。
- 无误差积累:跳过中间模块,不会因为 ASR 识别错误导致后续跑偏。比如用户说 “宜家商场”,即使发音不标准,模型也能直接通过声音特征识别,不会变成 “一家商场”。
- 低延迟:三个组件一体化,数据不用在模块间传递,延迟能降低 50% 以上。比如智能座舱中,用户说 “打开天窗”,端到端模型能在 0.5 秒内回应并执行,体验更流畅。
AI 语音的行业落地:从 “能用” 到 “好用”
无论是传统分段式架构,还是端到端大模型,最终都要落地到实际场景中,而各自也都有着各自的缺点。
传统分段式级联架构,存在着链路不稳定问题、高延迟、误差传播与积累、信息损失等问题,但不可否认的是,相对于端到端大模型,它的确定性&可掌控性要高。
端到端语音大模型,相较于分段式级联语音交互链路,避免了误差传播、保留并利用了丰富的信息,但不可避免的存在着“黑盒”特性、对算力&数据需求巨大、稳定性与可控性存在挑战;
而一切的一切是否可商用,是否可成为我们的产品&生产力,取决于该模型最后是否“能用”,且“好用”。
社交娱乐:“有声社交” 的崛起
语音社交是近年来的新趋势,AI 语音技术让 “说话” 成为核心交互方式。
典型产品:Airchat(有声版 X),用户不能打字,只能语音发帖和回复。背后用的是端到端模型,能实时把语音转文字、支持多语言翻译(比如英语语音转中文文字),还能保留语音中的语气特征(比如激动、调侃)。
技术亮点:语音分词器能处理长语音(最长支持 1 小时),语言模型能理解语境(比如用户回复 “那可不一定”,模型能关联上一条帖子的内容),TTS 能合成和用户语气匹配的回复(比如用户用调侃的语气发帖,回复也会带调侃)。
用户价值:解决 “社恐” 用户的沟通压力,不用打字就能表达观点;多语言翻译让跨语言沟通更顺畅,比如中国用户用普通话发帖,外国用户能听到英语语音 + 看到英语文字。
智能家居:“全屋语音控制”
智能家居中,AI 语音让 “动口不动手” 成为现实,从单一设备控制升级为全屋联动。
传统架构应用:比如小米音箱,支持 “打开客厅灯”“关闭窗帘” 等单一指令,ASR 优化了家居环境的噪音抑制(比如电视声、厨房噪音),语音唤醒支持自定义(比如 “小爱同学” 改成 “回家啦”)。
端到端模型应用:支持复杂联动指令,比如 “晚上 8 点,打开客厅灯、关闭窗帘、播放舒缓音乐”,模型能直接理解并执行,不用分多次指令。同时能识别不同家庭成员的声纹,比如孩子说 “打开儿童房灯”,会自动调到柔和亮度;大人说 “打开客厅灯”,会调到明亮模式。
结语:AI 语音,让沟通更自然
从传统的 “分段流水线” 到端到端的 “超级大脑”,AI 语音的进化本质上是 “模仿人类沟通方式” 的过程 —— 人类沟通不需要 “先听成文字再理解再说话”,而是直接 “声音对声音” 的交流,端到端模型正是还原了这种自然状态。
如今,AI 语音已经从 “能听懂” 升级到 “会聊天”,从 “被动执行” 升级到 “主动服务”。在智能座舱、社交娱乐、智能家居等场景中,它正在悄悄改变我们的生活方式,让 “动口不动手” 成为常态。
未来,当 AI 语音能完全捕捉我们的情绪、理解我们的潜台词、用我们喜欢的语气回应时,人机沟通将变得和人与人沟通一样自然。而这一切,都源于技术对 “自然沟通” 本质的追求 —— 毕竟,沟通的核心从来不是 “准确”,而是 “懂你”。
本文由 @一葉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


