
 起点课堂会员权益
起点课堂会员权益从 DeepSeek R1 看推理模型:更强、更贵、更慢?
2024年后的大模型分工趋势愈发明显,推理模型作为其中的关键一环,因其在多步骤、复杂问题上的稳定性而备受关注。本文深入剖析推理模型的本质、优劣势及应用场景,并以DeepSeek R1为例,揭示推理能力的训练路径与实现方法。从纯强化学习到SFT+RL的组合拳,再到蒸馏技术的低成本部署,带你全面理解推理模型的演进逻辑与实战价值。

2024 之后,大模型开始明显分工:同样是 LLM,有的更擅长写代码,有的专攻多模态,有的围绕检索增强(RAG)和智能体做落地。
进入 2025,这种分工更彻底,不再追求一个模型通吃所有任务,而是让不同模型在不同类型问题上更锋利。
推理模型,就是这波分工里最值得单独理解的一类。它在复杂、多步的问题上往往更稳,但也更慢、更贵;如果用错场景,可能会“想太多”,反而更容易翻车。
这篇文章来自一篇外网的文章,原文过于专业,我进行了“转译”以帮助大家理解,原文可点击文末的“阅读全文”查看。
01 推理模型到底是什么:不是更聪明,而是更会多步骤做题
先用个例子把什么是推理说清楚:
- 像“法国首都是哪儿”这类直接取知识的问答,本质是检索或记忆,不太需要推理。
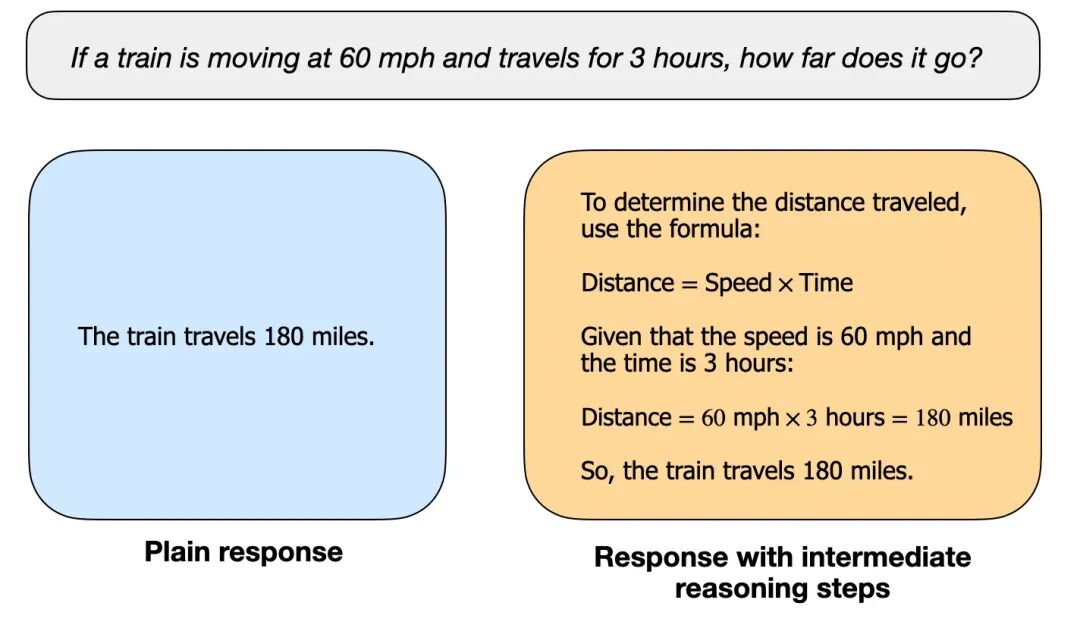
- 像“火车每小时 60 英里,开 3 小时走多远”这种,你得先识别关系(路程=速度×时间),再算出结果,才是推理:有步骤、有中间过程、有多次判断。
所谓“推理模型”,通常指它在更难的推理任务上更强,比如:谜题、数学证明、高难代码题、需要连续决策的复杂问题。
很多普通模型也能写步骤,但推理模型更偏向:遇到复杂问题时,能把任务拆开、逐步验证、减少中途走偏的概率。
推理步骤的呈现方式也分两种:
1. 把中间步骤写出来,让你看见它怎么推导;
2. 模型在内部多轮尝试,但不给你展示完整过程,只给最终答案。
02 推理模型的优劣势
可能不少人和我最初一样,面对任何问题都无脑选择推理模型,认为思考时间更长=更准确。
但实际用下来却发现并非如此,有时候反而会觉得它“想太多”。
推理模型更擅长的任务有:
- 需要一步步推导的任务,比如谜题、数学、严谨逻辑链;
- 需要把复杂问题拆成多段步骤、再逐段推进的任务;
- 复杂决策类任务,比如要综合多个条件反复权衡;
- 面对没见过的新问题时,泛化能力更好,更会举一反三;
推理模型的不足:
- 更慢:因为它会生成更多中间步骤或内部尝试更多轮;
- 更贵:步骤多意味着 token 多、算力消耗更高;
- 知识问答未必更好:纯知识问题可能不会更强,甚至可能“编得更像真的”;
- 简单问题会过度思考:本来一句话能回答,它可能绕一圈,反而把自己绕晕
所以:只有当问题需要多步推导/多轮判断时,才值得上推理模型;否则优先用普通模型更省、更快、更稳。
03 从 DeepSeek R1 看推理模型
要理解推理模型怎么练出来,DeepSeek R1 是个很好的样本:公开材料足够细,能看到一条相对完整的训练路径。
它不是只发了一个 R1,而是三个版本:
- DeepSeek-R1-Zero
- DeepSeek-R1(主力版本)
- DeepSeek-R1-Distill(蒸馏小模型版)
这三个版本连起来,基本就是推理能力从哪来的一张路线图。
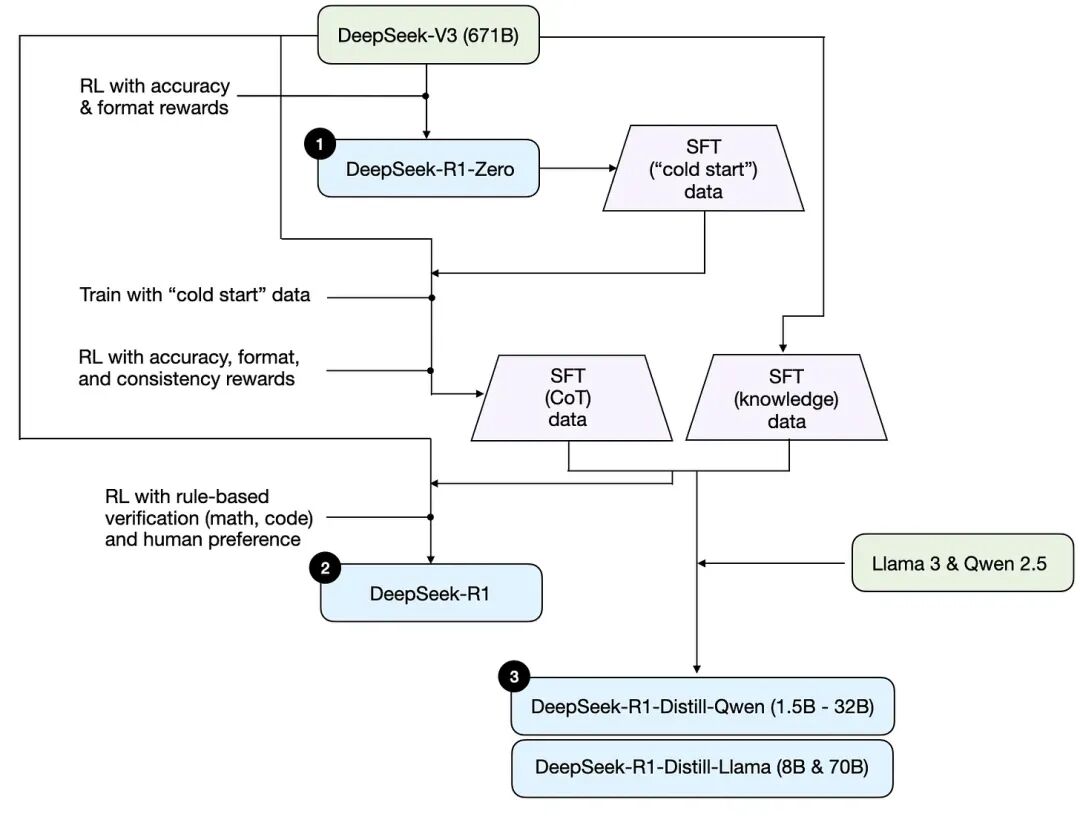
1. R1-Zero:只靠强化学习,也能“逼出”推理行为
R1-Zero 是一个很有代表性的实验:在底座模型(DeepSeek-V3,671B)上,直接用强化学习训练,不走常见的“先监督微调(SFT)再强化学习”的路径。
关键在于奖励怎么给(模型做得好,奖励高;做得差,奖励低):
- 准确性奖励。代码题:用编译器/在线判题验证对不对;数学题:用确定性的规则系统判断结果对不对。
- 格式奖励。用“评委模型”检查输出格式是否符合要求,比如要求把推理步骤放在特定标签里
这一套的意义在于:即使没有先教模型“怎么写推理步骤”,它也可能在训练中逐渐形成推理痕迹,出现某种“推理行为涌现”的现象。
但需要把话说完整:R1-Zero 更像“证明纯强化学习能把推理行为练出来”,并不等于它就是最强可用的推理模型。
要做成稳定好用的产品级推理能力,还得继续往下走。
2. R1 主力版:SFT + 强化学习,才是更现实的强推理路线
真正作为主力的 DeepSeek-R1,用的是更常见、也更稳的组合拳:
监督微调(SFT)+ 强化学习(RL)
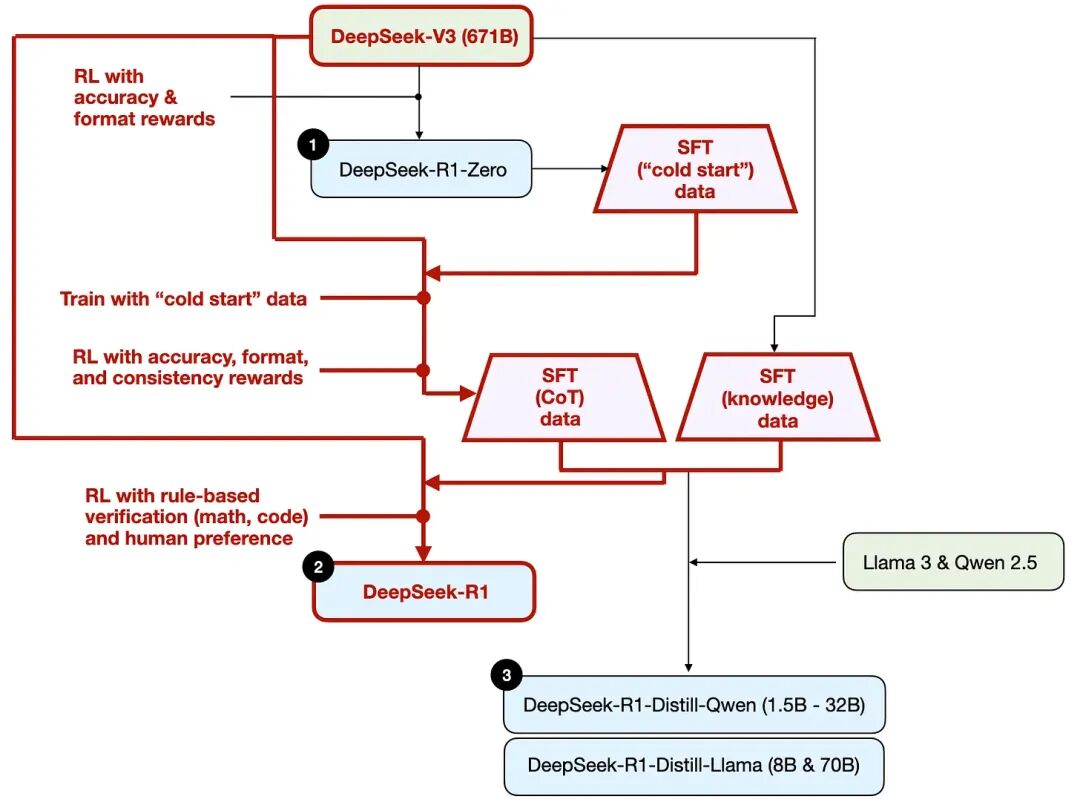
整体过程可以按“先把路铺平,再把它跑顺”来理解:
第一步:用 R1-Zero 生成“冷启动”的监督数据
因为一开始没有足够的推理示例数据,就先用 R1-Zero 生成一批可用样本,作为 SFT 的起点。
第二步:先做一次 SFT,再上强化学习
先用监督数据把“基本回答方式”和“推理格式”稳定下来,再用强化学习把难题能力往上推。
强化学习阶段除了准确性、格式奖励,还加了一致性奖励,比如避免中英夹杂、保持输出风格一致。
第三步:扩大高质量 SFT 数据,再做一次 SFT
这里给了一个很关键的量级信息:
- 生成60 万条带推理链的 SFT 样本
- 另生成20 万条偏知识型的 SFT 样本
合计约80 万条再做一轮指令微调,让模型既能推理,也不至于知识问答完全失常。
第四步:最终再做一轮强化学习
用可验证任务(数学、代码)把做对题的能力进一步拉稳。
如果你熟悉 RLHF,可以把它理解为一种更强调推理链数据 + 更强调可验证奖励的版本:
- SFT 阶段更重推理链样本
- RL 阶段更重能客观判对错的任务带来的稳定反馈
3. R1-Distill:把大模型“教出来的能力”,迁移到小模型里
蒸馏版的核心不是“高阶技巧”,而是一个朴素的工程思路:
- 让强模型生成大量高质量推理样本;
- 再用这些样本去微调更小的开源模型,例如 Llama、Qwen 的不同参数规模版本;
- 让小模型也具备不错的推理能力,便于部署、便于低成本使用。
这里的“蒸馏”更像“用老师模型产出训练数据”,它的价值有两点很实际:
- 小模型更省钱、更好部署(硬件门槛低很多)
- 这是一个清晰的对照:不靠强化学习,只靠高质量推理数据,能把小模型推到什么水平
上限也要说清楚:蒸馏模型整体不如主力 R1 强,但“相对体量”已经非常能打,很多时候拿来做应用足够好用。
04 推理能力到底怎么做出来
把上面这些抽象成行业可复用的路径,基本就是四条主路线:
路线 A:推理时多花算力
不改模型、不训练,只是在用的时候让它多想几步。常见做法包括:
- 引导模型一步步推导,这也会生成更多 token;
- 多答案生成 + 投票,取多数或取更一致的答案;
- 用搜索策略挑更优解,有些会引入过程评分/过程奖励模型;
这类方法很多发生在应用层:同一个模型,产品做法不同,效果也会不同。
现实里也常见效果更强但更贵(也会更慢),因为推理过程更长。
路线 B:纯强化学习
R1-Zero 属于这一类。优点是路线干净,研究意义大;但要做到稳定可用、覆盖面广,通常还不够。
路线 C:监督微调 + 强化学习(SFT + RL)
这几乎是目前最稳、最能做出顶级推理模型的一条路。
R1 主力版就是样板:先用 SFT 把形态和基本能力拉平,再用 RL 把难题和稳定性往上推。
路线 D:纯监督微调 / 蒸馏
这条路的现实价值是:成本低、门槛低,适合做小而强。
但它也有天然限制:强依赖老师模型和数据质量,想做“下一代突破”更难。
最后,分享三条我自己如何“提问”更容易得到想要结果的经验:
1. 很多时候不给示例反而效果更好,给了示例可能把模型带偏;
2.把问题和输出格式讲清楚,尤其是需要你要表格、要步骤、要结论、要检查项时,把格式写明白。
3.尽量只用一种语言,同一条提示中英混用,推理过程更容易混乱或输出不稳定。
以上,祝你今天开心。
作者:张艾拉 公众号:Fun AI Everyday
本文由 @张艾拉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议






- 目前还没评论,等你发挥!


