
 起点课堂会员权益
起点课堂会员权益谷歌王炸级图像模型Nano banana(附:技术原理揭秘)
Nano Banana,这个神秘的图像模型横空出世,以多图融合、角色一致性、自然语言直出等强大功能惊艳全网。它如何做到如此稳定真实?背后又有哪些技术亮点?让我们一起探寻其背后的故事。
前段时间,你可能已经被“Nano banana”刷屏了!
不亚于当时“GPT 生成吉卜力漫画”的那波热度。公众号、小红书、X 上清一色的“神图”轮番轰炸,更绝的是:它不需要大家写一堆“魔法咒语”,靠自然语言就能多步编辑、还让角色稳稳的保持一致。
不信你看。
(1)将多张图的元素合成到一张图中原图⬇️

合成的图⬇️

“多图融合”能力强!能把人、物、背景在一个画面里合成,而且画面协调。
(2)线稿 + 真人→ 同姿势“真人照片”
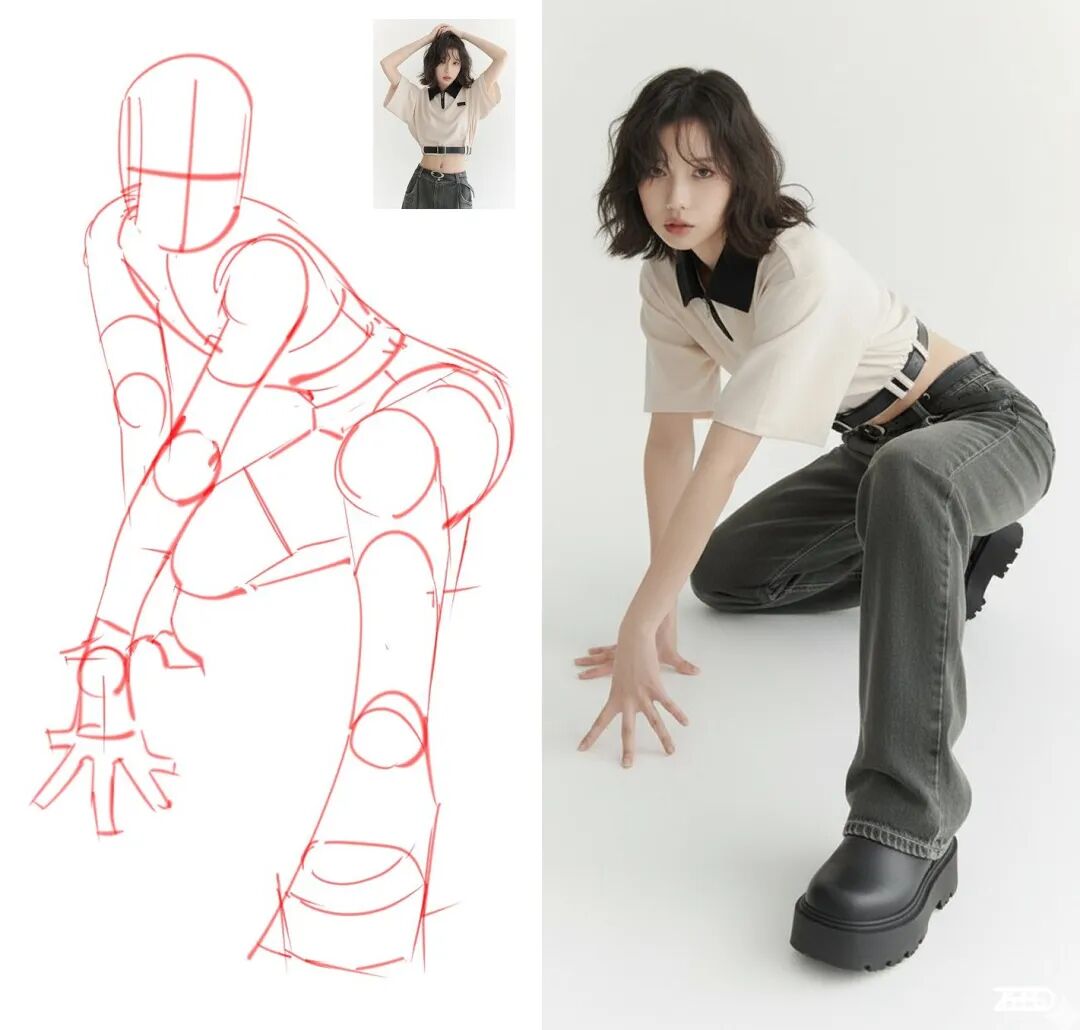
“世界知识 + 结构理解”强,看得出从抽象线稿到真实人像的姿势几乎一致。
(3)给同一个人换不同发型/风格

角色一致性高,多次编辑脸都没有任何变形。
(4)动漫直接直接生成真人
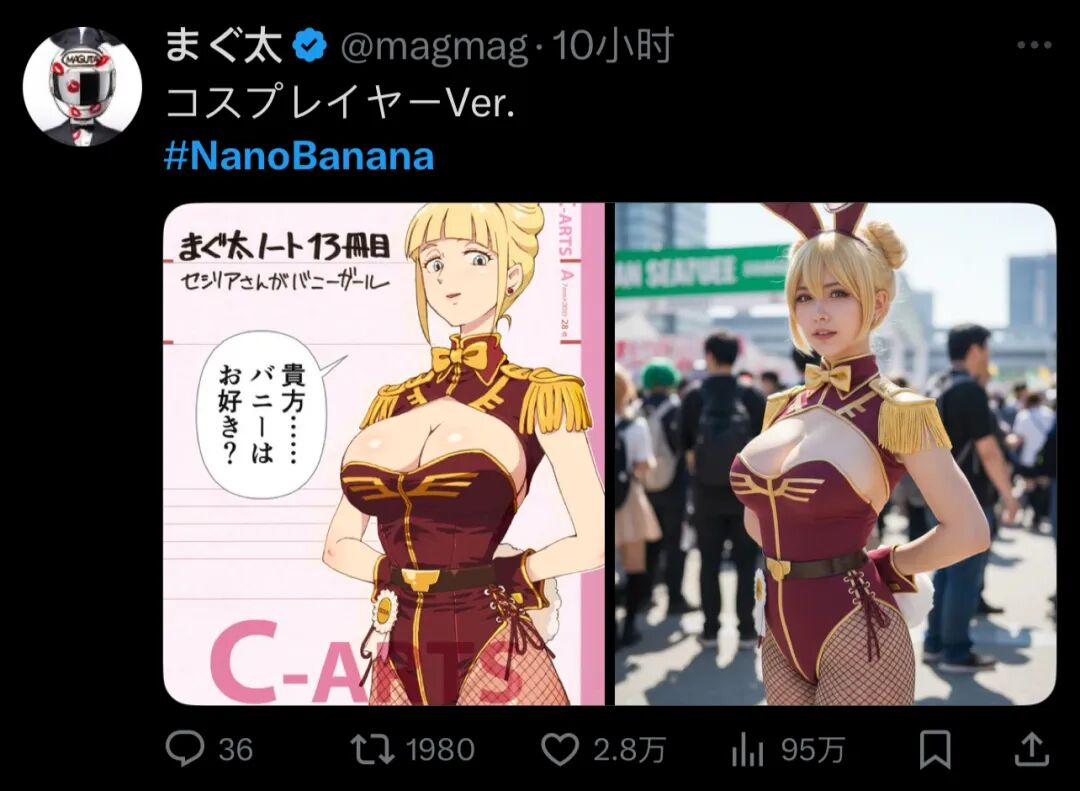
“风格迁移+ 多模态理解”能力超强。
(5)生成动物/真人手办

从Nano banana生成的照片看得出来,它令全网“尖叫”的主要原因是:多图融合 + 角色一致性 + 自然语言直出(不用调一堆参数!)。这对动漫、广告、电商、品牌物料制作,都是实打实的生产力升级。
Nano Banana 是什么?为啥突然走红
Nano banana最初是一个神秘代号——8 月中出现在 LMArena 匿名评测,大家靠风格与表现猜到是 Google DeepMind 在“压测”的新图像模型。它凭角色稳定性、自然语言与空间理解、以及“质量/速度/价格”三项平衡迅速出圈,热度甚至盖过同期很多视频模型。
随后 Google 正式“认领”,对外命名为Gemini 2.5 Flash Image,并在 Gemini App、Google AI Studio 与 Gemini API 上线。
该模型的定位是在Gemini 2.5 Flash基础上,新增“图像作为输出”(生成 & 编辑),原生多模态,强调多图融合、角色/风格一致、基于世界知识的编辑;模型本体仍是稀疏 MoE + Transformer 的多模态架构,1M token 上下文、可“开关思考”并设置推理预算。

Nano banana在文生图与图片编辑两个大类均拿到 Overall Preference 第一(人评偏好)。分项里,角色(Character)、产品再语境化(Product Recontextualization)等维度也很顶。据Google官方介绍:它的主要能力是
- 自然语言局部编辑:去人/去污渍/改姿势/补色,像素级精准地“改一点,其它都能保持不变”。
- 多图融合:把人或物“搬家”到新场景,还能自动调朝向、光影,使画面看起来自然协调。
- 角色/风格一致:同一人物跨角度、跨场景仍是“那个人”。
- 世界知识:模糊指令也能对上,比如“Make it nano(把它‘纳米化’)”这类带梗的提示词也能正确出图。
- 快:单张几秒级,支持“试-错-再试”的创作节奏,比追求“一步到位”更贴近真实工作流。
Nano banana价格也十分良心,目前官方定价为每张图像0.039美元(约0.28元人民币)。这一价格显著低于同类模型,例如OpenAI的图像生成成本约为0.19美元,而Nano Banana的成本仅为前者的约20%。
为什么它“更稳更真”:背后的技术点
顺着热度,Google DeepMind 的官方播客Release Notes刚好也上了一期幕后访谈:主持人Logan Kilpatrick和参与 Nano banana 的同学(Kaushik Shivakumar、Robert Riachi、Nicole Brichtova、Mostafa Dehghani)聊了它是怎么做出来的、做对了哪些关键点,以及接下来要打磨的方向。
节目里把大家关心的几个能力——交错生成(interleaved generation)、角色一致性、像素级可控编辑(pixel-perfect control)——都拆开讲了,非常解渴。

总结播客的内容如下:
1)把“文本渲染”当成隐藏标尺。团队在训练中有意识地把“文字渲染”当代理指标:文字是一种高度结构化的视觉信号,要求笔画形状/间距/对比度都得像素级稳定;一旦文字渲染好,往往“顺带提升”整体结构质量与细节控制能力。这比纯主观的人评更快、更可量化,让整个模型的迭代有了“北极星指标”。
2)交错生成(Interleaved Generation):统一上下文里的“串行出图”。传统出图常见“并行”多张,彼此互不记忆;Flash Image 改为“串行”,让第二张“看”到第一张,第三张“记得”前两张,于是组图的一致性与叙事性自然提高。我们会看到“同一个人”在不同姿态、角度、场景中依旧是“那个人”。
3)像素级编辑体验:只动该动的像素。传统生图工具中,用户最痛的点之一是“我只想改 A,它顺带改了 B”。新版本在pixel-perfect editing上明显更稳 —— 用户修改窗帘颜色,床不会被“顺手”换皮;即便偶尔不完美,几秒一轮的出图速度也把试错成本打下来了。
4)失败集驱动的评测。训练团队长期收集 X上的真实失败案例做测评集,诸如“编辑元素跟原图光影/风格不融”的老问题,会被列成必过项;这让迭代更贴近真实需求,而不是“只在基准上好看”
5)多模态互哺。为什么它能“更懂你的话,还更会画”?研发的解释是:看图学常识,出图校理解,语言中的“报告偏差”由图像补齐,形成理解与生成的双向强化。
6)架构与“思考预算”。把算力花在刀刃上2.5 系列是稀疏 MoE多模态架构,可打开/关闭“思考”并设置推理预算,在质量、延迟、成本之间做“可调”权衡;1M 长上下文为复杂多轮编辑与多图融合提供了“记忆空间”。
7)团队的“下一步”心法:聪明感 & 事实性。Mostafa 说他们追的是smartness(智能感):有时模型不照抄你的指令,但给出更好的结果;Nicole 则强调事实性,希望它把图表/信息图做得“能上班”的级别。这两条,分别对应“创意上的判断力”和“信息上的可靠性”。
本文由 @AI产品泡腾片 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


