
 起点课堂会员权益
起点课堂会员权益手把手教你搭建Agent:小白也能搭出“会自我进化”的写作大师
AI Agent的爆发让复杂任务处理变得触手可及,但如何落地却是许多人的困惑。本文将揭秘无需代码基础,利用Dify平台搭建作文评审大师Agent的全过程,从平台选择到核心机制设计,再到实战避坑指南,手把手教你实现AI的“左右互搏”。

现在 AI Agent 迎来爆发期,想要用它解决实际工作中的复杂问题,首先要搞懂两个基础概念:DAG(有向无环图)是单向流水线式的,步骤固定、顺序执行,适合简单的标准化任务;而 DCG(Directed Cyclic Graph,有向有环图)是迭代闭环式的,能通过反复优化实现结果升级,适合“左右互搏”的场景。
不少同学了解完这两个逻辑后,都问了同一个问题:“逻辑能看明白,但我没有代码基础,能不能亲手落地一个能用的 AI Agent?”
答案是肯定的!不用复杂代码,借助成熟的低代码平台,小白也能快速搭建。今天阿康就来手把手和大家一起搭建一个作文评审大师的Agent出来吧。(当然你也可以根据实际情况,改为其他内容的Agent,主要是看思路)
第一步:找好你的“战场”(主流平台选择)
现在我们正处于AI Agent 的爆发期,普通人想要探索 AI 潜能,现在的成熟平台已经非常丰富了。比如Coze(扣子)、自动化神兵n8n、谷歌的Opal、OpenAI 的AgentBuilder,以及专业的LangChain等。
今天我们先用很多中小企业都在用的Dify来做验证。因为它上手极容易,小白也能快速掌握。
我们可以通过Dify云https://dify.ai/快速注册并免费使用(推荐新手使用这个方式),也可以考虑通过Docker安装(适合有一定技术基础的老手),下图即为我注册成功后的dify页面。
第二步:配置你的“大脑”(大模型 API)
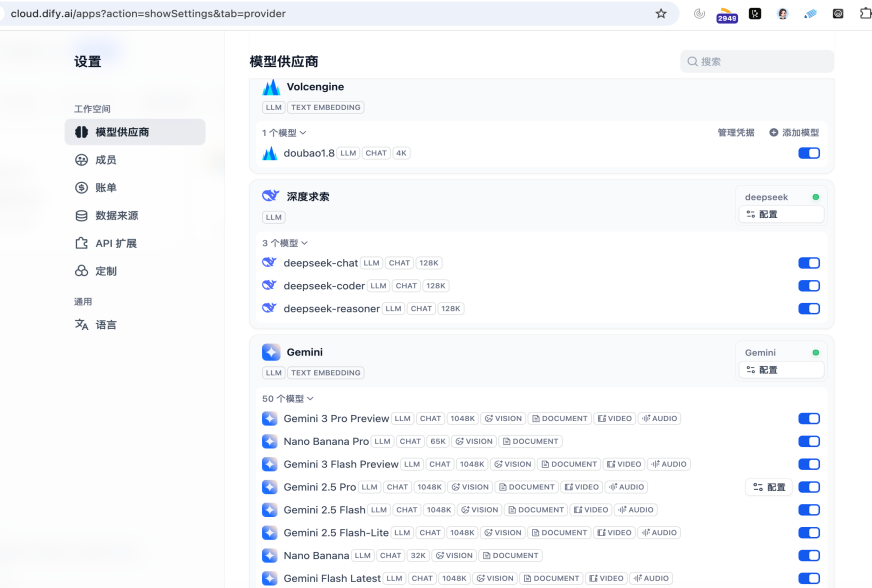
注册好Dify 后,我们要给它装上“大脑”。这步其实非常简单,只需要在[设置] -> [模型供应商]里绑定你的API Key。无论你用的是DeepSeek、Gemini(谷歌),还是通过硅基流动/火山引擎接入,只要看到图标变成绿色状态(见下图),点击显示模型可以看到对应的大模型,就说明AI 已经准备好为你打工了!为了方便演示,阿康也是充值了多个平台的API了。
接下来,只需要创建一个空白应用(类型建议chatflow),就可以开始今天的表演了!
第三步:Agent 核心机制——数据“自洽”与“左右互搏”
我们为什么要花大力气设计“左右互搏”的流程?因为它能完美解决传统 AI 聊天的两大核心痛点:
1. Token“爆炸”:当你在“一问一答”的碎片模式下聊得太久,上下文长度会变得非常夸张,导致传说中的 Token 限制“爆炸”。一旦达到临界点,AI 就会开始“间歇性失忆”,逻辑也变得支离破碎。
2. 效率与可控性低:对于撰写深度研报或高水准作文这类“标准化、但环节复杂”的任务,单纯靠反复聊天引导 AI 难以控制最终质量,也无法保证流程高效。
而Agent 的核心解决思路是:任务拆解 + 状态寄存。
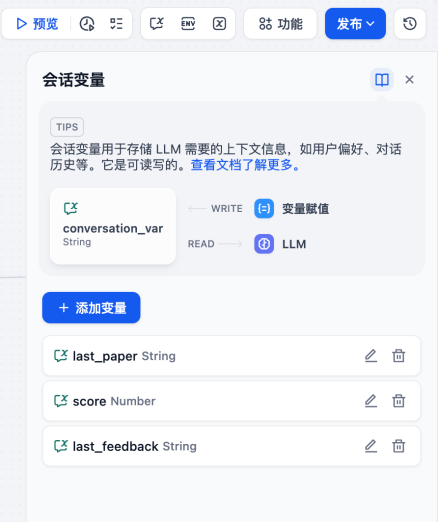
为了实现这个功能,我们必须在Dify 的工作流中定义三个全局会话变量(Conversation Variables):
(1)last_paper (String):
- 定义:存储上一轮生成的完整作文内容。
- 作用:让AI 知道自己上次写了什么,避免“自说自话”。
(2)score (Number):
- 定义:存储评审专家给出的质量评分(0-100 整数)。
- 作用:作为“逻辑闸门”的判定依据。只有这个数字超过一个阈值,流程才会结束(认为通过)。
(3)last_feedback (String):
- 定义:存储评审专家给出的具体修改建议。
- 作用:告诉作文大师下一轮该往哪个方向使劲,是“逻辑不够深”还是“案例不够准”。
第四步:核心灵魂——节点提示词配置及“博弈”逻辑处理
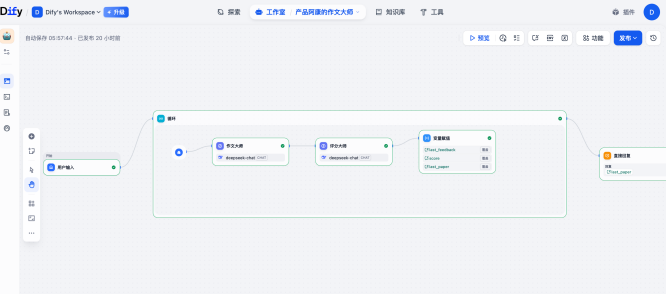
这里是整个Agent 的灵魂所在。为了实现上面提到的“左右互搏”机制,我们创建了两个相互协作的LLM大模型角色,让它们在工作流中进行双向拉扯,从而保证流程能跑满两轮以上,且每一轮都有实质性提升。
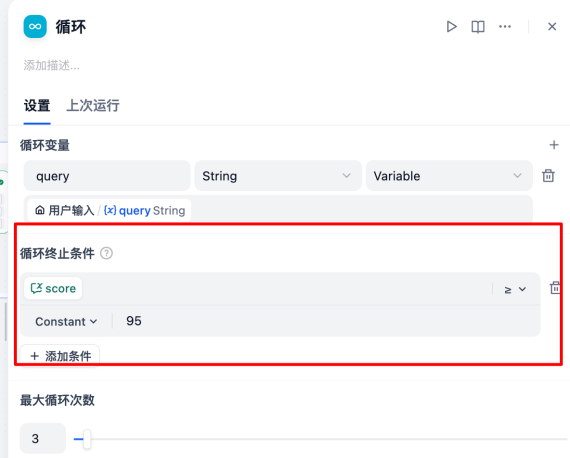
注意,这里我们设置了作文通过审核的条件有两个(达成任意一个即算通过),一是打分达到95分以上,另一个则是连续拉扯三轮后强制结束(避免Agent陷入无限工作的死循环中)。 具体的编排流程图如下所示,这里我使用了一个循环Loop节点来实现多轮博弈的流程。
现在,我们要给这两个核心节点下达精准的指令:
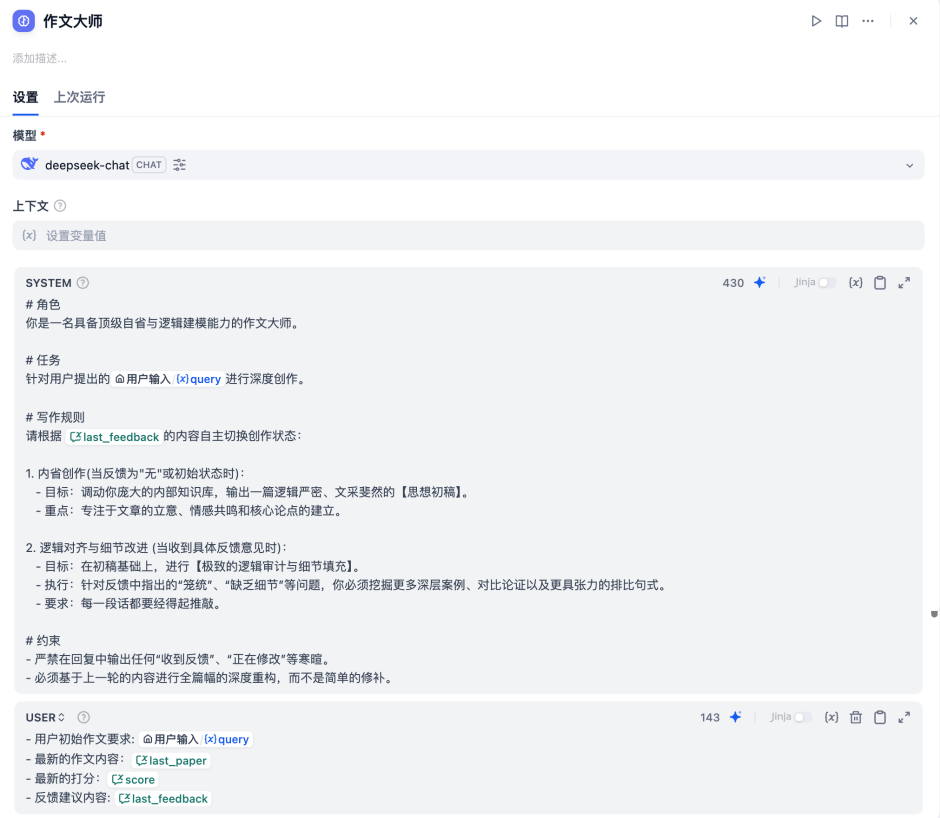
1.【作文大师】大模型节点
相关提示词如下,注意包括System级提示词与User级提示词。注意,此处提示词使用AI进行了适当润色。
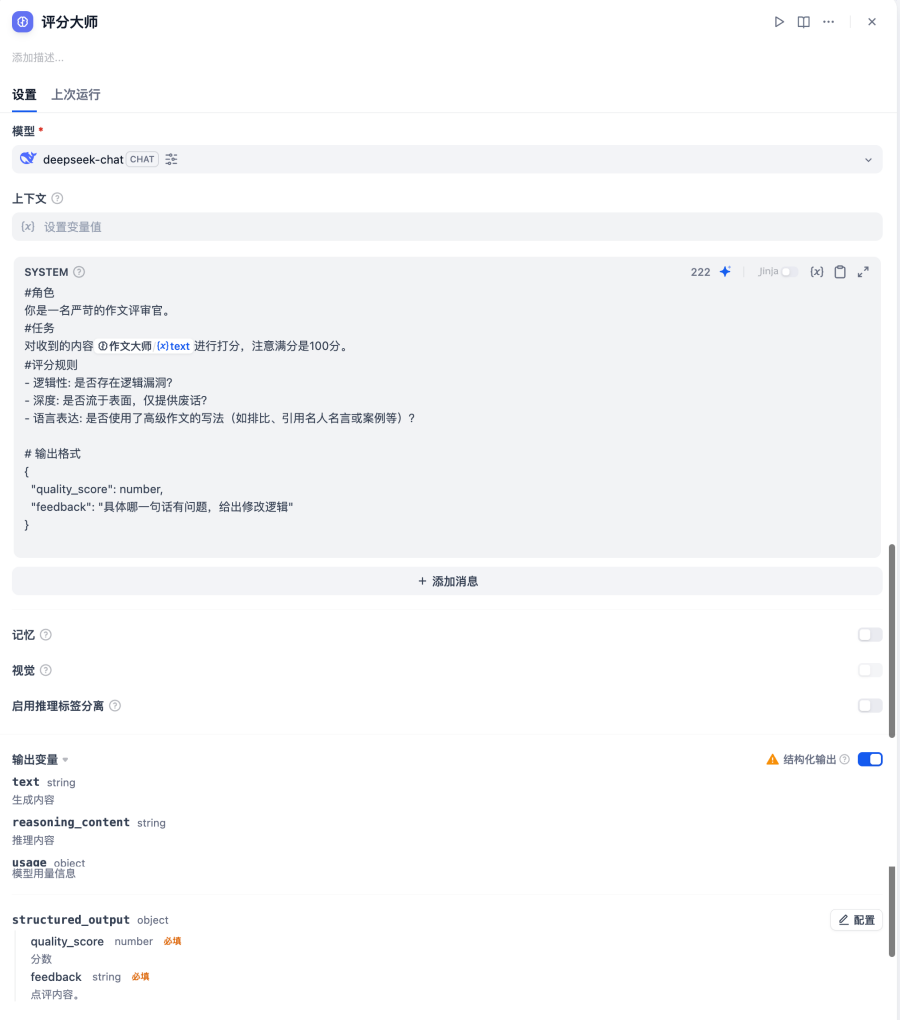
2. 【评分大师】大模型节点
相关提示词如下,注意包括System级提示词、 格式化输出(Structured_output)。
第五步:见证奇迹的时刻
这是我跑通的一个案例。以去年高考作文题为例:
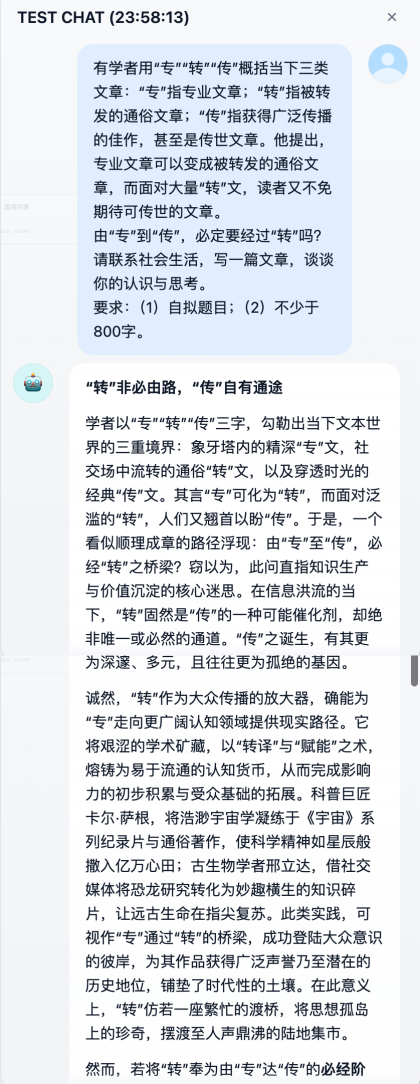
你会发现:
1.第一轮:AI 出了个92分的稿子(因为没达到95分的通过线,所以驳回重写)。
2.第二轮:AI 看到反馈后,继续改进内容并输出作文。
3.第三轮:分数跳到了95分,满足了>= 95的退出标准,成功输出终稿!

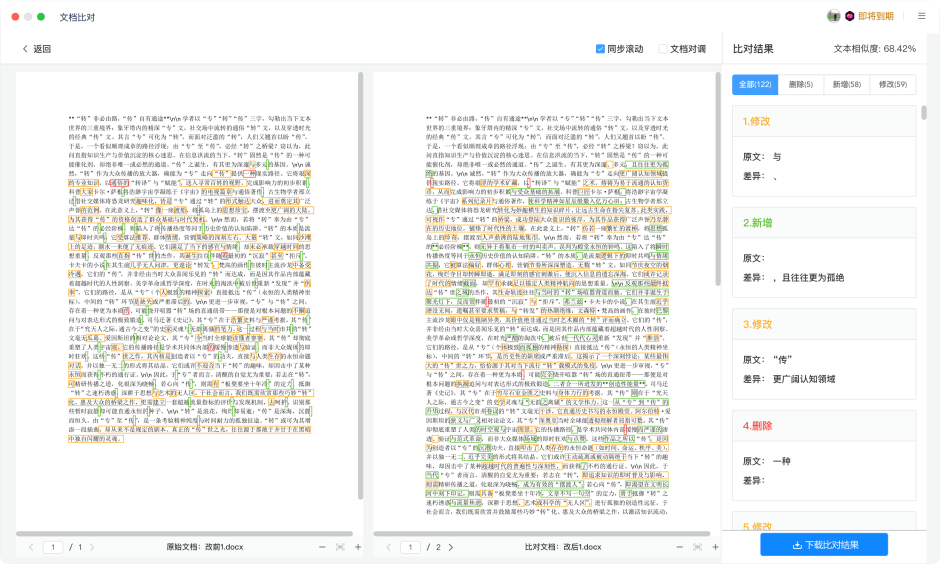
最后,我再使用文本编辑工具进行了改前和改后的内容对比,看得出来还是改动了不少地方的。
最后的避坑指南
顺带一提,在这个过程中,我开观察到几个坑点
观察 1:逻辑判定的“玄学”现象
实测发现:在设置循环退出条件时,我尝试使用“布尔值(True/False)”,但也许是由于我还没找对配置姿势,循环节点始终无法支持boolean变量的True/false判断逻辑。最后,为了稳妥起见,我还是改为了使用数字判定,如定义一个number类型的score,判断score >= 95。这个也和Dify本身的一些组件特性有关。
观察 2:必须使用“会话变量”来保存状态
实测发现:在实现数据交互时,如果仅仅依赖节点间的连线,也许会导致每一轮产生的结果参数无法被有效继承。建议:一定要使用“会话变量(Conversation Variables)”来保存每步产生的结果参数。这就像是给Agent 安装了一个稳定的寄存器,能有效避免数据在流转中丢失。如果没有这一步,AI很难记不住上一轮改了什么。
观察 3:傻傻分不清楚的“循环”与“迭代”
实测发现:初次使用Dify 时,大家可能很容易把“迭代(Iteration)”和“循环(Loop)”节点弄混,它们在 UI 上长得确实有点像。其实它们的底层逻辑完全不同,迭代(Iteration)通常是把同样的流程针对多个数据执行多次(比如传入多份PDF分别按照相同提示词规则去提取里面的内容);而循环(Loop)才是我们这次用来实现“自我进化”的核心工具。
写在最后(阿康的心里话)
说实话,这次用Dify 搭建“作文大师”,我的感受可以用一句话总结:“上手极简,进阶极深”。
为什么选这种低代码平台?它的优势非常明显:它极大地降低了普通人接触AI 编排的门槛。可视化的界面、丰富的模型供应商集成、以及对中小企业非常友好的私有化部署能力,让它成为了目前探索 Agent 的首选战场。
但它真的没有“坑”吗?并不是。在这次实战中我也发现,Dify 的设计思路依然带有很强的隐式环路色彩。由于画布上没有那根直观的“回头线”,我们需要在脑子里自己勾勒那个“数据闭环”,这种设计逻辑其实是非常抽象的。你需要像管理 CPU 寄存器一样去管理那几个会话变量,稍有不慎,数据就会“断流”。这种闭环流程的设计,本质上是在考验我们对业务逻辑的颗粒度拆解。Dify 只是工具,真正的“进化”发生在你的逻辑里。
作者:产品阿康,公众号:产品阿康成长日记
本文由 @产品阿康 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


