
 起点课堂会员权益
起点课堂会员权益一手实测Nano Banana 2,我总结了8大新玩法
当Nano Banana 2以价格腰斩、速度翻倍的姿态登场,这款被戏称为'香蕉2'的AI图像生成器正在重新定义创作效率。本文通过一手实测,深度解析其在画幅自适应、批量生成、联网搜索等八大场景的应用潜力。从清明上河图风格的城市长卷到一致性角色创作,看新一代模型如何突破技术边界,为内容生产带来降维打击。

最近,AI圈有三大奇观:养龙虾,等种子,玩香蕉。
而今天,「香蕉2」正式发布了,官方名字Gemini 3.1 Flash Image。
一看这个名字,你就能明白,谷歌这是把Nano Banana的能力 + Flash的速度,直接合体了。
我们的老朋友lovart.ai,也第一时间接入了2,付费会员依旧0积分体验。
先给大家简单做一个总结:
1)2整体性能和Pro差距不大,部分场景甚至略有退步。
2)多文字生成,依旧容易乱码(尤其是中文)。
3)核心是价格直接砍半。一张1k图,Pro要0.134美元,2只要0.0672美元。
4)同时,速度大幅提升。API可以做到2秒出图,每分钟能够稳定输出347-356张图。
5)新增4:1、1:4、8:1、1:8等超宽/超窄比例,覆盖更多设计场景。
6)新增512px低分辨率选项,加上已有的1K、2K、4K,开发者可以按需选择。
7)内置web图片搜索,可以实时从网上搜索参考图来生成图片。
8)一致性增强,单任务可保持5个角色和14个物体的一致性。

01 一手实测
虽然整体性能没有质变,但2在「玩法层面」的扩展,明显更有意思了。
下面,给大家分享我实测下来最有价值的几个玩法。全部基于Lovart平台完成。
1)一键修改素材画幅
比如,这是2的海报,1:1比例。

我们想把它换成16:9的比例,上线平台换成Lovart,同时保持原图的画面结构、UI元素和文字不变。而且原图是我从x上下载的,分辨率很差,只有680×680,我想把它换成2K的。
于是,上传参考图,输入提示词。提示词:修改画幅尺寸为16:9,文字改为中文,2K。

初版给我们的图,有些文字没对。没关系,我们点击这张图,选择“文字编辑”,直接替换文字就可以了。

而且,我还注意到,他们家又上新了一些编辑功能,更实用了。

来看下最终版的图片。

这下子清晰多了,而且文字也全部换成了中文,整体结构也与原图保持一致。
对于设计师来说,2+Lovart的这套玩法真的非常实用。过去,我们想要调整这样一张海报图的尺寸,如果拿不到PSD源文件,基本无解。
即使有PSD源文件,也要忙活几个小时。而现在,只需要几秒钟。
对于设计师来说,这已经不是提效,是降维打击。
2)一键设计极宽幅图片
这次,2新增了4:1、1:4、8:1、1:8等超宽/超窄比例,加上原有的1:1、16:9、9:16、4:3、3:4、3:2、2:3等比例,设计场景一下子宽了很多。
特别是8:1和1:8这个极宽幅比例,拿来干Banner图、电商详情页、装修全景图、商场围挡、户外广告和游戏侧壁非常好使,能给人一种极致的沉浸感。
还是前面这个图的风格,我们结合2的模型要点,来设计一张8:1比例的Banner图。
提示词:
参考这个图{参考图}的布局和设计风格,提炼下面的文字,设计一张8:1的Banner图,来介绍Nano Banana 2模型的核心要点。——
简单总结一下Nano Banana 2:
1)整体性能与Nano Banana Pro没多少区别,部分场景甚至还略有退步。
2)多文字情况下,依旧容易出现乱码,尤其是中文。
3)核心是价格下降,输出一张1k图,Nano Banana Pro要0.134美元,Nano Banana 2只要0.0672美元,降了一半。
4)同时,速度也大幅提升。API可以做到2秒出一张图,一分钟能够稳定输出347-356张图。
5)画幅比新增4:1、1:4、8:1、1:8等超宽/超窄比例,覆盖更多设计场景。
6)分辨率新增512px低分辨率选项,加上已有的1K、2K、4K,开发者可以按需选择。
7)内置了web图片搜索,它可以实时从网上搜索参考图,来生成图片。
8)单任务中,最多可以保持5个角色和14个物体的一致性。
还行,但不够精美。

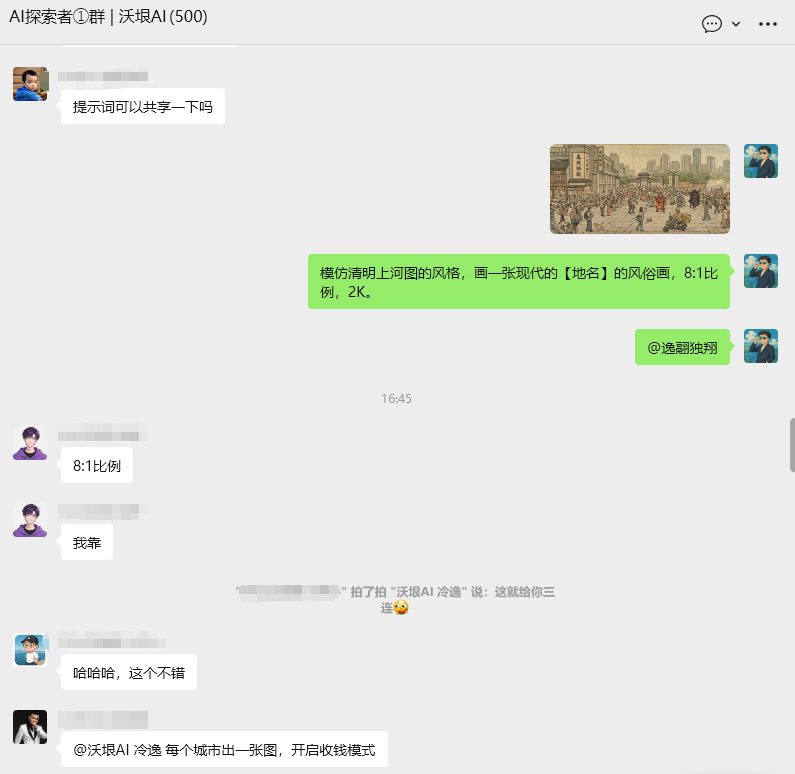
于是,我又设计了一版提示词。提示词:模仿清明上河图的风格,画一张现代的【地名】的风俗画,8:1比例,2K。
这是重庆山城

这是上海外滩。

这是杭州西湖。

这是成都春熙路。

我把这套提示词和样图丢群里,很多小伙伴都觉得太了。
实际上,基于这套提示词还可以延伸出很多玩法。比如航拍版杭州。提示词:模仿高清摄像机的风格,画一张现代杭州的著名地标图,4:1比例,4K。

by@绛烨
吉卜力版佛山顺德。提示词:模仿高清摄像机的吉卜力风格,画一张现代顺德著名地标图,4:1比例,4K。

by沃垠AI群友@邓
提示词:生成一张8:1的深圳天文台的日落图。

3)一键联网查找参考图
这次,2还有一个独特功能,就是内置了Web图片搜索。
模型不再只是靠训练数据里的「记忆」来画图,它可以实时从网上搜索参考图,然后基于这些真实图片来生成新的图。
这个能力,不仅能让2降低幻觉,也能拓展使用场景。
比如,生成成都今天的天气信息图。提示词:设计一个关于今日成都天气的信息图,包括温度、湿度和穿衣建议。

2会先搜今天成都的真实天气数据,再生成准确的信息图,而不是瞎编一个数字。
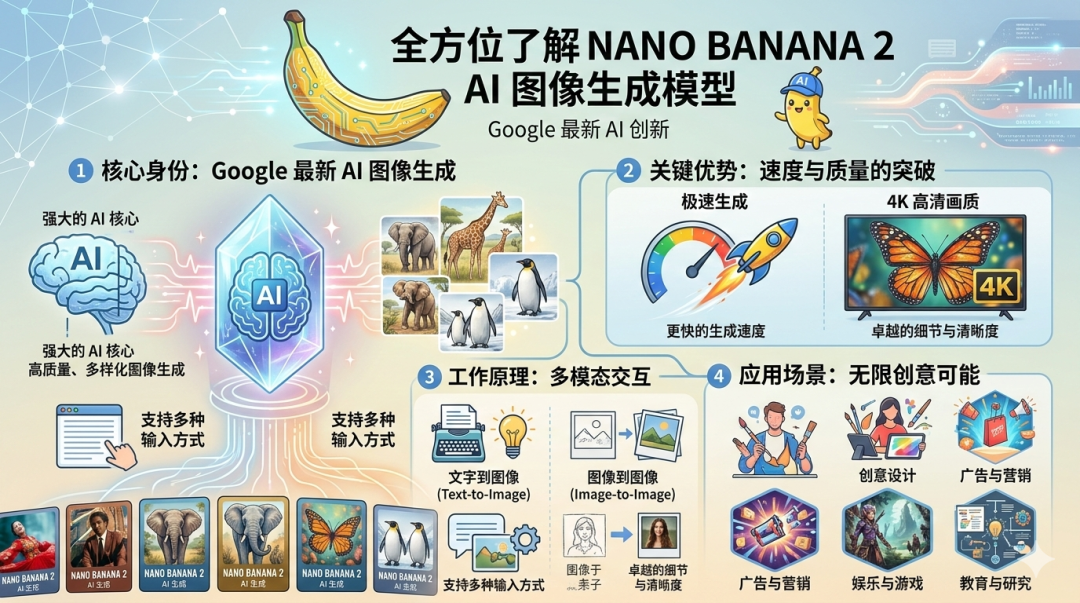
也可以让它做一些信息图和图鉴。提示词:设计一张信息图,介绍Nano Banana 2模型。
提示词:设计一张图鉴画,介绍黄腰柳莺。

4)一口气批量出图
这点,是我觉得最被低估的能力。
还记得春晚cos“天命人”的宇树武Bot吗?

现在,它要去闯荡江湖了,我们在Lovart上用2模型,可以一口气生成20张分镜图。提示词:以这张图片的机器人为主角,参考《雪中悍刀行》的场景,以水墨黑白条漫的极繁主义风格,展示机器人闯荡江湖的过程,生成20张动画分镜,如同剧中形象般生动。
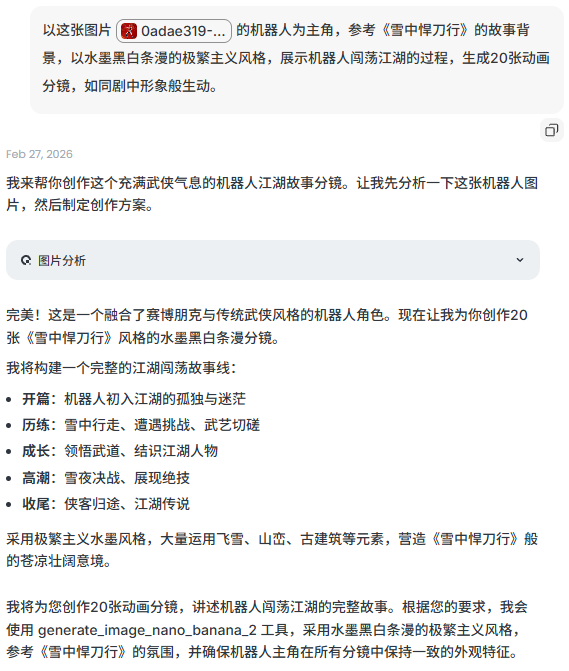
所有分镜均保持了主体一致、风格统一,有完整的故事线。

又比如,我们有一张女主图片,可以在Lovart上一口气生成8个场景的图片。提示词:生成图中主体人物在公园、樱花树、图书馆、办公室、日式餐厅、火车、飞机、巴黎街头8个场景的图片,统一尺寸16:9,保持服装和外貌完全一致。
女主一直穿着相同的白色衬衫和黑色裙装,发型和面部特征也统一,并未“换脸”。

理论上,Lovart Agent支持超长上下文,可以一次性生成100张以上的图片,依然能保持一致性。
加上Lovart又有很多视频模型,生成后的图片可以直接创作视频。用它来搞漫剧、短剧,已经是内容生产线级别的能力了。
这点,跟Gemini只能一张一张图的生成,体验还是不同的。
写在最后
整体体验下来,我的结论是:
2依然是当前最能打的图像模型,能力独一档。
在做到更快、更便宜的同时,性能并没有降智,反而新增了一些更实用的功能。
配合Lovart独家的画布功能和编辑功能,可以有更多的玩法。
而且,它对提示词几乎不挑。一句模糊的描述,一个感觉,一个方向,它都能接住。
只要你有想法,它就能有结果。
关键在于:你,到底想用它做什么。
本文由人人都是产品经理作者【沃垠AI】,微信公众号:【沃垠AI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


