
 起点课堂会员权益
起点课堂会员权益小米 MiMo-V2 系列:当国产大模型把”成本”这张牌打到极致
MiMo-V2-Flash 以对手 2.5% 的推理成本掀起大模型价格革命,却在代码修复和 Agent 场景展现出接近 GPT-5-High 的实力。这款采用 MoE 架构的工程奇迹,通过按需激活、多 Token 预测和革命性训练技术,正在改写智能时代的性价比规则。本文将深度解析其技术突破、开源战略与生态布局,揭示小米如何用三角形产品矩阵重塑 AI 落地逻辑。

一个价格只有对手 2.5% 的模型,能打赢这场大模型战争吗?
先说一个让行业不舒服的数字
MiMo-V2-Flash 的推理成本,仅为 Claude Sonnet 4.5 的 2.5%。
我第一次看到这个数字,是在某个深夜,坐在那儿盯着屏幕看了好一会儿——这不是优化,这是降维。
你可能会问:成本低不等于能用啊,性能不行还不是白搭?
这个问题问得好。我们等一下来拆。但在拆之前,得先搞清楚一件事:小米发布的 MiMo-V2,到底是什么?

一、搞清楚这次发布的”版本”问题
很多文章把 MiMo-V2 当成一个模型来写,其实这次是一个系列。截至 2026 年 3 月,小米 MiMo-V2 家族里已经有三位成员:
MiMo-V2-Flash(2025年12月首发)
这是打头阵的那个。总参数 309B,激活参数仅 15B,专为高效率推理、编码和 Agentic 工作流程设计。 说白了,它是用”轻激活、重架构”换来极致性价比的代表。
MiMo-V2-Pro(2026年3月发布)
旗舰选手,专门啃硬骨头。总参数超过 1T,激活参数 42B,采用混合注意力架构,支持 1M 超长上下文。在 Artificial Analysis 全球排行榜上位列第八,国内第二。
MiMo-V2-TTS(同期发布)
语音合成专项模型。基于自研 Audio Tokenizer 和多码本语音-文本联合建模架构,经过上亿小时语音数据训练,能实现同一句话内的语气转折和情感递变。
三款模型,方向各不相同:一个主效率、一个主极限、一个主语音。这不是同一件事的三个版本,而是三条完全不同的作战线。

二、技术层面,小米到底做对了什么?
我发现行业里有个坏习惯——一说大模型就只看参数规模,仿佛参数越多就越牛。这个逻辑在 2023 年还勉强成立,但现在已经开始失效了。
MiMo-V2-Flash 最核心的贡献,恰恰是打破这个逻辑。
2.1 “按需激活”:大而不笨的工程哲学
MiMo-V2-Flash 采用 1:5 的全局注意力(GA)与滑动窗口注意力(SWA)混合结构。
这个设计,用一个类比来理解:
想象一个超大型图书馆,里面有 30 万册书(对应 309B 参数)。传统大模型每次有人来查资料,都得把所有书都翻一遍,费时费力。而 MiMo-V2-Flash 的做法是——平时只激活常用区域的 1.5 万册书(激活参数 15B),真正需要跨领域深度检索时,才调动全局资源。
这叫 MoE 架构,即”混合专家模型”(Mixture of Experts)。核心逻辑很简单:不是每个问题都需要动用全部智能,聪明的模型应该懂得”够用就好”。
这个设计带来的直接结果:每秒 150 个 token 的推理速度,生成速度比同类闭源模型快 2 倍。
2.2 MTP:让”猜下一个字”这件事变得更快
模型生成文字,本质上是在不断预测”下一个词是什么”。传统方式是一个字一个字地预测,MiMo-V2-Flash 引入了多 Token 预测(MTP)机制。
说白了,就是让模型同时猜接下来的好几个词,再并行验证哪个猜对了。这相当于把一道选择题拆成几道并排的选择题同时做,再取最优解。研究人员重新定义了并行解码,通过引入多词元预测训练,提升了基础模型能力,并在推理过程中实现了并行验证。
2.3 MOPD:训练成本的”降本增效”
这个技术名字拗口,但背后的道理其实很接地气。
多教师在线策略蒸馏(MOPD)先通过监督微调或强化学习技术得到各领域的专家教师模型,再让学生模型基于自身的策略分布进行采样,利用多个教师模型提供的稠密型 token 级奖励信号完成优化。MOPD 训练只需不到传统 SFT+RL 流程 1/50 的计算资源,即可匹配教师模型的峰值表现。
1/50 的训练成本。这句话我第一次读到时停顿了一下。这意味着,别人花 5000 万训一个模型,小米用 100 万能训出一个不差的——这才是成本护城河的真正来源。
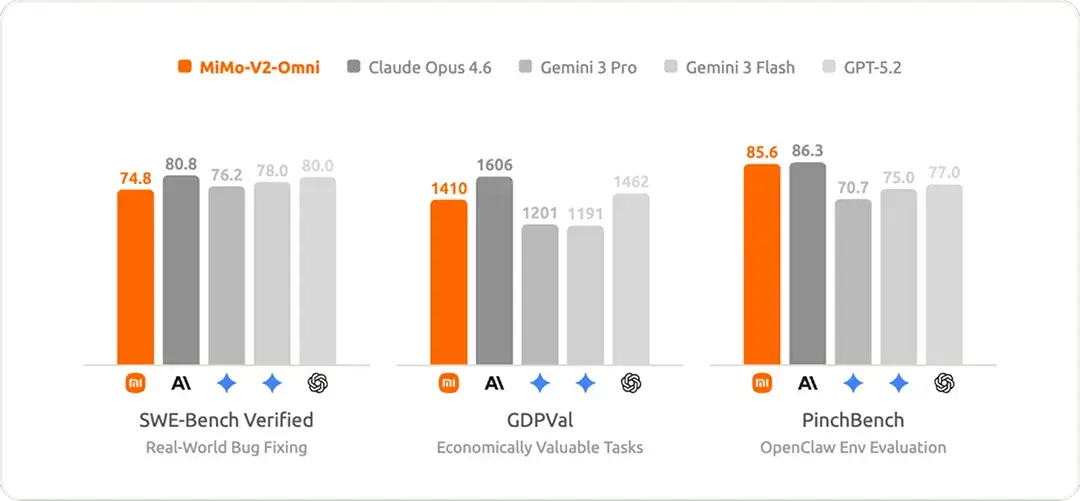
三、性能到底怎么样?别只看跑分
说完技术,回到前面那个问题:成本低,性能行不行?
我发现一个有意思的现象:MiMo 团队在性能展示上,刻意避开了一些它可能不擅长的”通用能力”测试,而是把火力集中在 Agent 场景和代码能力上。这不是藏拙,而是很清醒的策略定位。
代码能力:可以对标 Sonnet 4.5
在软件工程能力基准 SWE-Bench Verified 上,MiMo-V2-Flash 达到 73.4% 的成绩,在所有开源模型中位居第一,并接近闭源模型 GPT-5-High 的水平。
这个分数意味着什么?SWE-Bench 是让模型去修复真实软件仓库里的 Bug,不是做选择题,而是真正能被合并进代码库的修复。73% 的通过率,放在一年前这是旗舰闭源模型的水平。
在编程领域,MiMo-V2-Flash 能独立修复多数真实软件 Bug,性能接近 GPT-5-High。
Agent 场景:多步推理是核心差异点
面对 OpenClaw、Claude Code 等前沿的 AI 智能体框架,MiMo-V2-Pro 展现出令人惊艳的端到端任务统筹能力,能在零人工干预的条件下,独立完成复杂工作流的编排、长程逻辑规划以及精准的工具调用。
这是 V2-Pro 的定位:不是”聊天助手”,是”能干活的员工”。
整体使用体感已超越 Claude Sonnet 4.6,逼近 Opus 4.6,但模型 API 定价仅为其 1/5。
如果这个数据能被独立验证,意义非常大——因为价格不是差一点点,而是差了整整 5 倍。
它不擅长什么?
这里要说句公道话。MiMo-V2-Flash 仅在”人类最后一场考试”这类不使用任何工具辅助的通用推理测试,以及创意文本生成评估 ARENA-HARD 中略逊色于 DeepSeek-V3.2。
开放式问答、创意写作、哲学推理——这些需要”发散性思维”的场景,MiMo 还不是第一梯队。这个定位很坦诚:它是个工程师型选手,不是文学家。
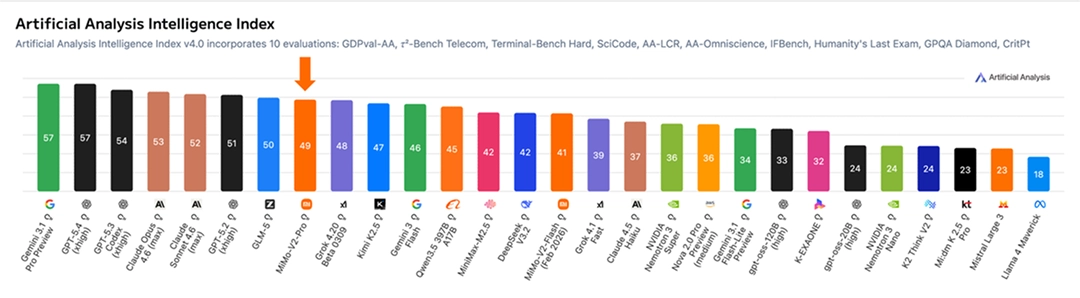
四、开源策略:这步棋比技术更值得细看
技术本身固然重要,但这次让很多人真正震惊的,其实是定价和开源策略的组合拳。
4.1 MIT 协议:比很多人想象中更激进
MiMo-V2-Flash 采用最宽松的 MIT 协议,允许商业修改与再分发,甚至将推理代码同步贡献给 SGLang 社区。
MIT 协议和 Apache 2.0 的区别,对大多数开发者而言是感受不出来的。但对企业法务而言,这是完全不同的两件事——MIT 协议意味着可以直接拿去做商业闭源产品,几乎没有限制。
这步棋很聪明。你开放得越彻底,开发者生态就建得越快,未来的应用场景就越多,反过来又能喂养模型迭代。这是个正向飞轮。
4.2 定价:把”白菜价”这个词写实了
API 定价国内为输入 ¥0.7/M tokens,输出 ¥2.1/M tokens;海外为输入 $0.1/M tokens,输出 $0.3/M tokens。
做个对比:GPT-4o 的定价大约是输入 $2.5/M tokens,输出 $10/M tokens。MiMo-V2-Flash 的海外定价,输入成本约为 GPT-4o 的 1/25。
当然,这不是同一性能档的模型直接对比。但对于大量”够用就好”的场景——比如批量代码审查、文档处理、API 调用链——这个价格差距就是商业决策的关键变量。
4.3 生态接入:快速铺点
MiMo-V2 系列已登陆 Xiaomi miclaw、MiMo Studio、金山办公、小米浏览器,并通过 OpenClaw、OpenCode、KiloCode、Blackbox、Cline 接入。
这个接入列表里,有几个点值得关注:金山办公(WPS 的母公司)意味着向 C 端办公场景渗透;Cline、Cursor 兼容意味着开发者工具链已经打通。
这不是简单地”上线一个 API”,而是在快速占领各种使用场景的入口。
五、小米 AI 的底层逻辑:三角形的每条边
很多人看小米做大模型,第一反应是”手机公司凑热闹”。其实不然。
如果把小米 MiMo 家族放到更长的时间线上看,会发现一个很清晰的战略三角:
MiMo-7B(2025年4月):端侧推理先锋,专为移动设备优化,能耗仅为竞品 1/5,已深度集成至 HyperOS 3.0,成为手机的”思维中枢”。MiMo-VL-7B(2025年6月):多模态视觉语言模型,在 GUI 交互和复杂推理上刷新开源记录,为智能体提供”眼睛”。MiMo-V2-Flash(2025年12月):云端 MoE 引擎,以极致设计为智能体提供”大脑”。
端侧 → 多模态 → 云端推理,这三款模型分别解决了 AI 落地的三个核心问题:手机上跑不跑得动、看不看得懂图像、复杂任务完不完成得了。
当手机通过 MiMo-VL 识别物体后,可以无缝调用云端的 MiMo-V2-Flash 进行复杂分析,整个过程延迟可控、成本极低。
这才是雷军说”AI 的未来在手机端”的完整语境。不是把大模型塞进手机,而是用端侧模型做感知、云端模型做推理,两层协同、无缝衔接。
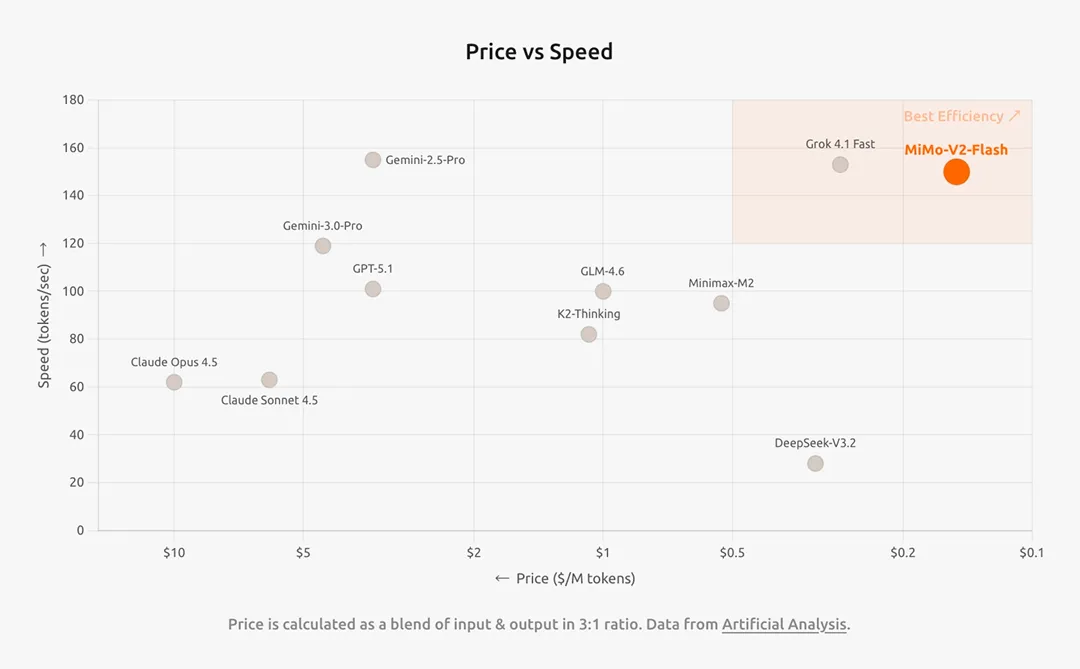
六、行业影响:三件事会因此改变
6.1 「调 API 的门槛」会继续下降
以前一家中小企业想用 GPT-4 级别的能力做 AI 产品,光是 API 成本就可能让 ROI 算不过来。现在有了 MiMo-V2 Flash 这种量级的选择,很多原本”做不起”的场景,变得可以做了。
对独立开发者而言,影响更直接:以前一个月 API 费用几百美元,现在可能降到几十元。这个量级的变化,会让一批新产品从沉没成本中解放出来。
6.2 「Agent 应用」的落地速度会加快
Agent 应用最贵的不是单次对话,而是多步工具调用链。一个复杂任务可能调用几十次 API,费用叠加下去,很容易失控。
极低的推理成本让智能体可以”思考”更久、更深入,而不必担心费用爆炸。
这句话说的是真实的工程痛点。以前 Agent 开发者必须在”允许多少步推理”和”控制成本”之间做艰难取舍,而 MiMo 的出现,把这个取舍空间大幅拉大了。
6.3 「国产大模型」的形象会被重新定义
坦白说,国产大模型在海外社区的形象,一度停留在”追随者”而非”创新者”。但这次情况有点不同:
MiMo-V2-Flash 的 SWE-Bench 成绩是开源第一,MOPD 训练方法是真正的技术创新,MIT 协议开源是主动向社区输出——这三件事加在一起,对外的叙事逻辑已经开始改变。

七、给不同角色的实操建议
如果你是开发者
现在就可以做的事:
- 去 Xiaomi MiMo Studio 开一个账号,申请 API Key,先用 Flash 版本在你的核心 use case 上跑跑看。
- 如果你在用 Cline、OpenCode 这类 Agent 框架,MiMo-V2-Pro 已通过 OpenClaw、OpenCode、KiloCode、Blackbox、Cline 接入,切换的技术成本接近零。
- 对比你现在用的模型,在代码补全和多步 Agent 任务上做 A/B 测试,记录实际的准确率和成本。
暂时不要做的事:
不要因为基准测试亮眼就立刻替换掉所有现有的模型调用。先在一个边缘服务上做灰度测试,看真实业务数据再说。
如果你是产品经理或业务决策者
核心问题只有一个:你的 AI 功能目前是成本敏感型的吗?
如果每月 API 费用已经显著影响你的盈利模型,那 MiMo-V2-Flash 是一个非常值得认真评估的替代选项。
如果你的产品对错误率极度敏感(比如涉及金融、医疗),那在积累足够的内部测试数据之前,保持谨慎是正确的。
如果你是研究者或关注行业的人
MOPD 这个训练方法,值得认真读一下对应的技术报告。1/50 的训练计算成本匹配教师模型峰值表现——如果这个数字经得起严格验证,这不是一个小的工程进步,而是整个模型训练效率研究的一个新数据点。
结语:这场比赛的计分方式变了
过去几年,大模型竞争的计分方式很简单:谁的参数多、谁的基准测试高、谁的 MMLU 分数漂亮,谁就赢了下一轮融资、赢了媒体版面。
但我觉得,这套计分方式正在悄悄改变。
真正的竞争,开始向”落地成本”和”生态覆盖”倾斜。
一个模型再强,如果每次调用都贵得让人心疼,开发者就会绕开它;一个模型哪怕不是最顶尖,但如果便宜、稳定、生态好用,它就会被大量集成进产品——然后反过来获得更多训练数据、更多场景反馈,形成飞轮。
小米 MiMo-V2 做的事,本质上是在重新定义”性价比”这条赛道的天花板。它用 2.5% 的推理成本、MIT 协议开源、快速的生态接入,告诉整个行业:前沿智能不一定要贵,也可以是一种基础设施。
这场比赛远没结束。但这一局,小米打得有章法。
本文由 @秋叶的枫 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


