
 起点课堂会员权益
起点课堂会员权益底模派 vs 驾驭派:AI 圈正在发生的最大分歧
AI驱动开发正在颠覆传统编程模式,但无数PM在兴奋之余却陷入『改A崩B』的恶性循环。Harness Engineering作为硅谷最新实践,将产品经理推向了「数字员工架构师」的全新战场——当代码生成变成廉价资源,真正的竞争力在于如何为AI构建规则、权限与验收标准的完整操作系统。本文深度拆解从Prompt Engineering到Harness Engineering的三次范式跃迁,揭示产品经理如何通过PRD思维为AI打造『不裸奔』的协作框架。

为什么你的 AI 每次都在“裸奔”?
不知道你最近有没有经历过下面这种让人血压飙升的对话。
你 :“用 Cursor 帮我写个带登录功能的待办清单小程序。”
AI :“没问题,代码已生成,请运行。”(你一跑,完美,成就感爆棚)
第二天你 :“在这个基础上,加一个一键分享到微信的功能。”
AI :“好的,分享功能已添加。”
你 :“卧槽,怎么连最基础的登录都登不进去了?报错了!”
AI :“抱歉,我刚刚修改路由时覆盖了登录逻辑,马上修复……”
第三天你 :“怎么分享出来的卡片是乱码?而且昨天修好的登录,今天怎么又卡死了?”
AI :“非常抱歉,我没有注意到样式冲突,正在重新生成……”
一周后,你看着满屏标红的报错,默默关掉了项目,再也没打开过。改 A 崩 B,解释 A 模块的逻辑要花半小时,而 AI 在新代码里又悄悄埋了三个新坑。
这不是你一个人的故事。这是过去一年里,无数 PM 在“AI 驱动开发”这件事上交的同一笔学费。
问题出在哪里?是模型不够聪明吗?并不是。 问题在于,你根本没进入正确的协作模式。
你把 AI 当成一个随叫随到的外包,却忘了给它一个稳定的办公桌、一套标准的作业流程、一套严密的质检工具。 没有这些,AI 每次都在”裸奔”——能力再强,也只是一匹没有缰绳的野马。
怎么给这匹马套上缰绳?这其实已经不是一个“提示词技巧”的问题,而是一个严密的“系统工程”问题。
在硅谷的最新实践中,这套专门为 AI 搭建自运转环境的体系,已经有了一个正式的名字:Harness Engineering(驾驭工程)。
一个让人坐不住的数字:0 行手写代码
Harness Engineering 到底有多大威力?我们先来看一个真实的极端案例。
2026 年初,OpenAI 的 Codex 团队在官方博客公布了一个内部项目。他们从一个空的代码仓库开始,交付了一个完整的、每天有真实用户在使用的产品,经历了上线、部署、故障、修复的完整生命周期。
整个项目大约 100 万行代码。 重点是:没有一行是人手写的。全部由 AI Agent 生成。 最初推动这件事的,只有 3 名工程师,花了 5 个月时间。
看到这里,你脑子里肯定会冒出一个问题:“既然代码都是 AI 写的,这 3 个人每天朝九晚五到底在干嘛?摸鱼吗?”
答案是:他们在 “带新人” 。
把当前的 AI Agent 想象成一个能力极强、手速极快,但对你们公司业务一无所知的“超级新人”。
- 如果你不给他定规矩 ,他就会按自己的野路子随便写。
- 如果你不给他定边界 ,他就会把支付模块的代码写到用户资料库里。
- 最可怕的是 ,如果代码库里有一段写得极烂的祖传代码,他不会判断“这个不该学”,而是会照着这个坏模式,一秒钟给你生成十个变体。
这 3 名工程师的核心工作,根本不是敲键盘写业务代码,而是为这个“超级新人”打造一套 Harness(马具)。他们每天的工作是搭建规则、编写导航文档、配置自动化检测工具、设计反馈机制。马的能力越强,马具就越重要。没有缰绳的千里马,只会把你狠狠摔在地上。
从微观管理到制度化授权:AI 协作的三次跃迁
为什么我们今天必须谈 Harness?因为如果你还停留在研究“怎么写 Prompt”,你就已经被时代淘汰了。
人机协作的范式,已经悄然完成了三次底层跃迁。这不仅是技术的演进,更是管理学的重构。
第一阶段:Prompt Engineering(提示词工程)
你的日常 :“你现在扮演一个资深前端专家,深呼吸,一步一步来,按照以下格式给我输出一段 Vue 代码……”
管理学视角 :这是典型的 “指令型管理” (微观管理)。模型能力弱且没有记忆,你必须事无巨细地发号施令,像个操碎了心的保姆。指令是一次性的,关掉对话框,一切归零。
第二阶段:Context Engineering(上下文工程)
你的日常 :“这是我们公司的知识库文档,这是历史代码,你去里面找一下相关的规范,然后再回答我的问题。”
管理学视角 :这是 “支持型管理” 。随着百万 Token 的普及,你不再纠结怎么说话,而是致力于构建情境。协作重心从“优化输入”变成了“配置环境”。
第三阶段:Harness Engineering(驾驭工程)
你的日常 :“这是你的沙箱环境,这是测试工具,这是验收标准。你自己跑,跑通了把结果交给我,报错了自己看日志修。去吧。”
管理学视角 :这就是 “制度化授权” 。当模型具备了深度自主规划能力(Agentic),你不需要告诉 AI 怎么做,你只需要给它授权工具、框定运转边界(Guardrails)。剩下的,AI 会通过心跳机制(Heartbeat)自主唤醒,7×24 小时执行闭环。
为什么说 Harness 是产品经理的绝对主场?
看到这里,很多非技术出身的 PM 可能会慌:
“‘驾驭工程’?‘自动化检测’?这听起来太硬核了,这是不是开发大佬们的地盘?我一个画原型的 PM 凑什么热闹?”
恰恰相反。 Harness Engineering 的本质,是把模糊的现实世界“编码化”为清晰的规则。而这,正是产品经理每天都在做的基本功。
我们经常听到开发吐槽:“代码就是最好的文档,写什么 PRD?” 但在 AI 时代,这句话反过来了。AI 看不懂你那缺乏业务逻辑的“屎山代码”,它需要的是结构化的业务规则。
当“写代码”本身变成廉价的自来水,决定产品成败的就不再是“怎么写”,而是“边界在哪里”、“验收标准是什么”。
我们把 Harness 的三大核心要素拆开看,你会发现它与 PM 的核心技能简直是 1:1 完美同构的
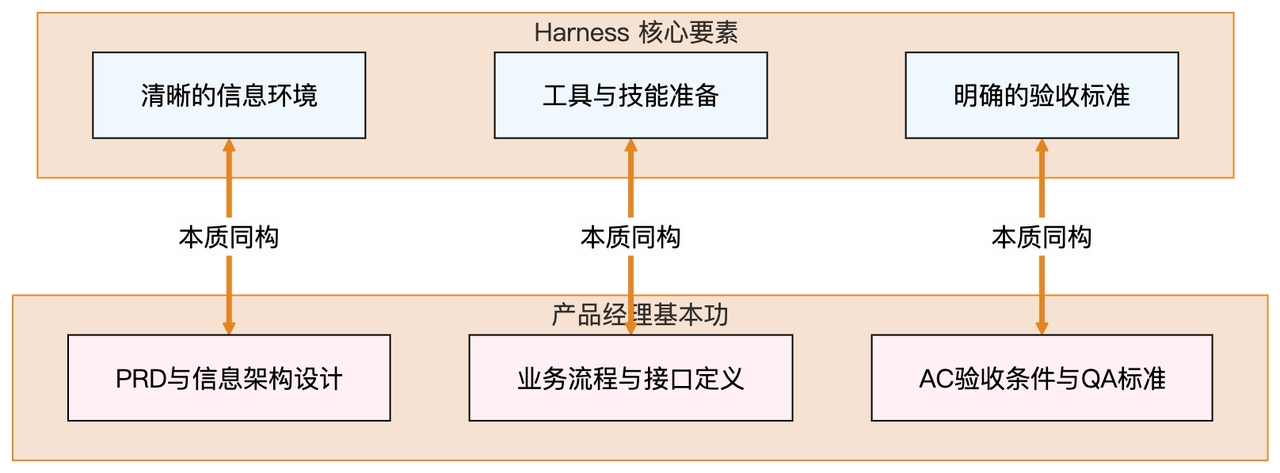
- 对话场景还原:清晰的信息环境 = PRD 与信息架构。AI 视角 :“主人,你让我改支付逻辑,但我不知道旧版的逻辑在哪啊?” PM 能力 :把隐性知识显性化,梳理出结构清晰、按需读取的系统文档。这不就是高级 PRD 吗?
- 工具与技能准备 = 业务流程定义 :AI 视角 :“主人,我想验证一下页面,但我没有浏览器权限;我想查报错,但我没有日志接口。” PM 能力 :提前规划好整个业务流转需要哪些节点、哪些权限。这和设计一套后台系统的权限与工具模块如出一辙。
- 验收标准 = AC(Acceptance Criteria) :AI 视角 :“主人,代码我写完了,没报错,我觉得挺好的,交差了!”(实际上 UI 已经错位到了天边) PM 能力 :制定量化的验收标准。“当用户点击 X 时,必须在 Y 毫秒内反馈 Z,且按钮颜色必须是 #FF0000”。PM 平时写需求时定下的 AC,直接转化为 AI 的自动化验收规则。
可以说,Harness 时代,产品经理正在从“需求的搬运工”进化为“数字员工的架构师”。
实操一:给 AI 一张地图,而不是一本百科全书
怎么具体落地 Harness?我们先解决第一个痛点:AI 为什么总是记不住规矩?
很多人踩过的第一个坑,就是把所有的架构规范、产品要求、设计指南,一股脑塞进一个巨大的 System Prompt 或者 AGENTS.md 文件里。
你的内心 OS :“只要我把所有的规矩都写在这个 2 万字的文件里喂给它,它就全知道了,以后就不会犯错了!”
结果适得其反。这叫 上下文稀释 。 你想想,一个新人入职第一天,你甩给他一本 200 页的《公司规章制度大全》,跟他说:“全在里面了,你自己看”。你猜他会怎么做?大概率翻两页就去摸鱼了,遇到问题还是来拍你肩膀:“哥,这个配置在哪啊?”
AI 也是一样。重点太多等于没有重点,它面对超长文档大概率会宕机,最后还是会忽略关键约束。
正确的做法是 渐进式披露 :给 AI 一张索引地图。
主索引文件只保留 100 行左右,不写具体规则,只告诉 AI“遇到什么问题,去哪里找什么文档”。
更关键的是,这份地图必须像代码一样被维护。过时的文档比没有文档更致命。你可以专门安排一个“图书管理员 Agent”,定期巡查文档与实际系统的匹配度。
实操二:AI 制造的技术债是指数级的,必须建立反馈闭环
如果你用 Agent 写过代码,一定有这种绝望感: 人类开发者引入坏代码的速度是线性的,一天也就写几百行,Code Review 还能兜住;但 Agent 的产出量是人类的十倍,它会无脑复制现有的坏模式, Agent 制造的技术债是指数级增长的。
你 :“AI,你写的这堆是什么垃圾?为什么到处都是重复的工具函数?”
AI :“报告主人,我看代码库里以前就是这么写的,我帮您发扬光大了,生成了 50 个类似的!”
靠人眼一行行去 Review?3 个工程师面对每天十几个庞大的 PR,根本看不过来。
Harness 的核心引擎,在于 把“人”从循环中抽离出来,建立机器自动检查、自动指导修复的闭环。
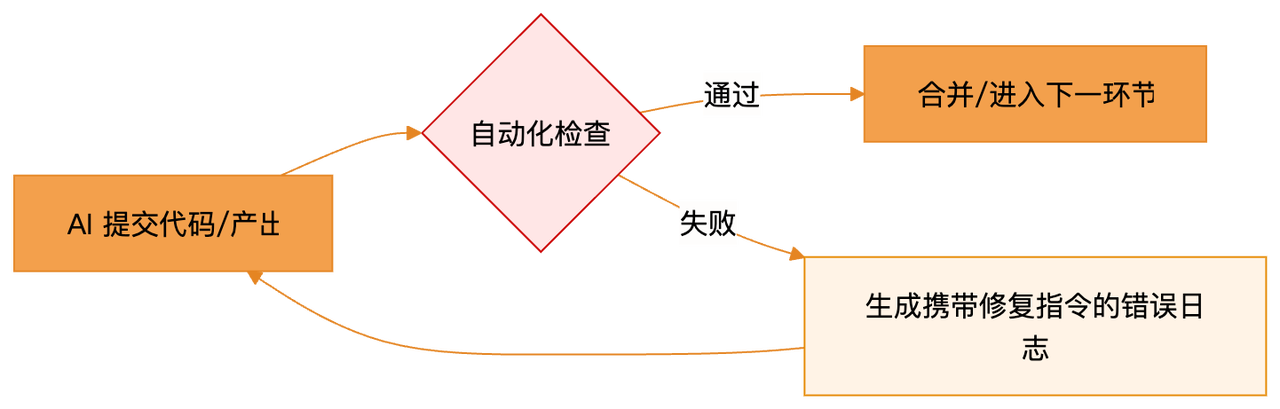
注意那个关键细节:错误日志不是写给人看的,是写给 AI 看的。
测试工具 :“你这段代码跨模块调用了,不符合黄金法则第三条,打回去!”
测试工具 :“不仅打回去,你还需要把 A 模块的调用改为通过 API 网关请求,立刻执行!”
AI :“收到,马上修改重试。”
为了确保万无一失,顶尖团队通常会设置 三层质检架构 :
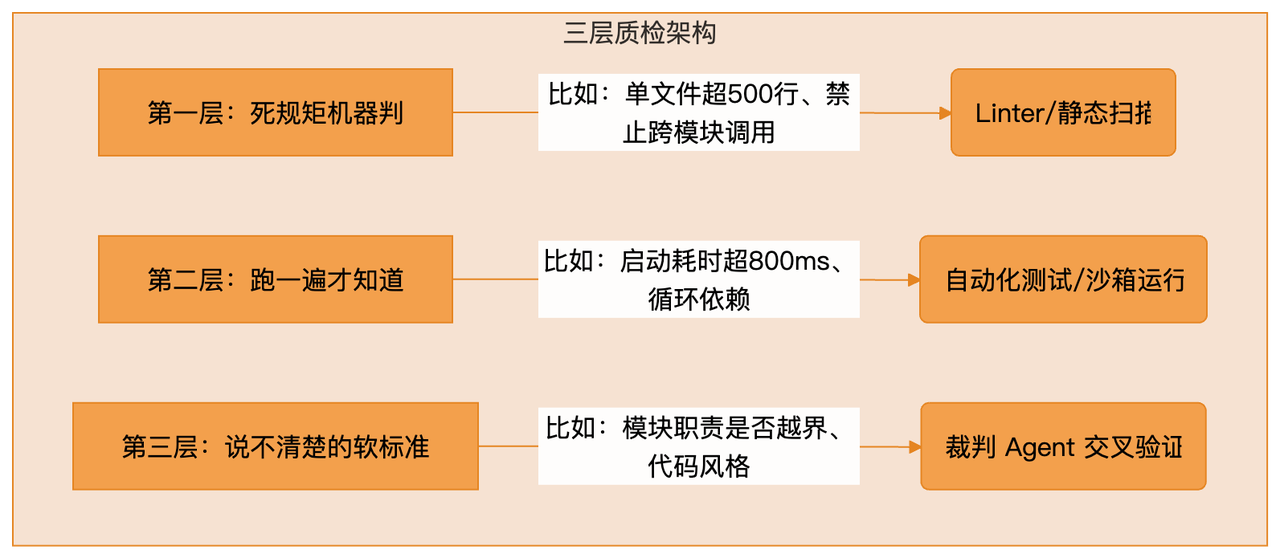
同时,必须给 AI 装上“眼睛”和“手”。接入 Chrome DevTools 让它能自己看 UI,接入 LogQL 让它能自己查日志。
以前你是 Human in the loop(人在循环内) ,AI 做一步你确认一步,少了你就停工; 现在你要变成 Human on the loop(人在循环上) ,AI 自己在一个任务上连续工作 6 个小时(通常是你睡觉的时候),不断报错、不断自我修复,直到跑通所有测试,才亮起绿灯请你来看大盘。
真实踩坑:两个几乎每个团队都会踩的坑
说完方法,说说血泪教训。
这两个坑,几乎每个开始认真做 AI Agent 项目的团队都会踩,区别只是踩得深还是浅。
坑一:多个 Agent 之间”鸡同讲讲”
当你有多个 Agent 协作时——比如一个负责分析需求、一个负责生成内容、一个负责质量审核——它们之间的数据传递格式如果不统一,系统很快就崩。
典型的场景是这样的:主 Agent 把分析结果传给子 Agent,但主 Agent 输出的格式不固定。有时候是一整段自然语言描述,有时候是半结构化的数据,字段名也不固定,有时候叫 style ,有时候叫 video_style ,有时候这个字段直接不出现。子 Agent 拿到这个结果,不知道该读哪里,只能自己猜。猜对了还好,猜错了就生成出偏差的结果,甚至直接报错停掉。
排查起来特别痛苦,因为你不知道是主 Agent 的问题、子 Agent 的问题,还是中间传递的问题,全链路都得看一遍。
解法:像定义系统架构一样,严格定义 Agent 之间的通信协议。 把每一步的输入输出封装成固定对象,字段名、数据类型、必填项全部写清楚,不允许歧义。子 Agent 只读这个对象,不接受其他格式的输入。做完之后,Agent 之间的传递几乎不再出错,一旦出错也能在几分钟内定位到具体字段。
这其实就是 PM 最熟悉的那件事—— 定义接口规范 ,只不过这次的对象是 AI,不是人。
坑二:输出质量忽高忽低,抓不住规律
同样的输入,今天 AI 给出的结果惊艳,明天给出的结果拉胯。你找不到原因,也不知道怎么复现。这种不稳定在 Multi-Agent 项目里最让人头疼。
根本原因是: Agent 对”什么是好输出”没有明确认知。 它不知道什么叫合格,只能靠自己的理解猜测,而不同的请求里这个猜测的结果就会波动。
解法有两个方向。一是模型选型——换更强的底模,稳定性确实会提升,但成本也跟着上去,而且强模型也不是万能的,某些特定场景下还是会飘。二是 System Prompt 微调——把”好”拆解成具体维度,把模糊的指令写具体,把容易出错的边界情况加进去,用几个好的样本告诉它”这种质量才算及格”。
两个方向结合起来用,效果明显好了很多。
质量不稳定的本质,是目标模糊。 这和传统研发中”需求写不清楚”导致的返工,是完全同构的问题。PM 对这个问题最有发言权,也最有能力解决它。
最后,说一件更重要的事
当 AI 能够自主完成代码编写、测试和部署,人的价值正在发生一次根本性的位移。
以前,人的价值在于”怎么做(How)”。
以后,人的价值只剩”做什么(What)”和”为什么做(Why)”。
有一个细节值得认真想一想:即便是现在最强大的 AI Agent,部署之后如果没有任何外部目标注入,它不会自行运转,也不会”想要”做什么。模型本质上是一个缺乏内在动机的工具。这意味着,即便有一天出现了”无所不能”的模型,在没有人类意图注入的情况下,它倾向于什么都不做。
人,永远是那个产生动机、设定目标的角色。
Harness Engineering 训练的,正是这种能力:把人类的意图,精确编码成 AI 能持续执行的系统规则。洞察需求,翻译目标,定义验收——这不就是 PM 最核心的能力吗?
在不远的将来,产品经理这个角色也许会有一个新名字: 意图架构师 。我们不再只是在和 AI 聊天,我们在构建一个承载人类创造力的智能工厂。
AI 是手段。你,才是目的。
学会 Harness,不是为了让自己更像机器。
是为了让自己,更像人。
本文由 @桃子AI产品 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









产品经理转型意图架构师,Harness Engineering助力掌控AI协作!