
 起点课堂会员权益
起点课堂会员权益AI医疗问答项目系列之提升RAG召回准确率
医疗RAG召回准确率的提升不再是简单的技术叠加,而是对知识库、向量库、多路召回与知识图谱的精准协同。本文深度拆解四大核心模块的落地细节,从分级知识库的强绑定到轻量化知识图谱的语义关联,揭秘如何在不越界的前提下实现医疗科普内容的精准召回与合规过滤。

核心逻辑:
医疗RAG召回准确率的本质是:在合规前提下,让系统精准找到「最权威、最贴合用户问题、语义最完整」的医疗科普内容,同时避免漏召回核心内容、错召回无关/违规内容。
核心公式:
高准确率召回 = 「精准检索底座(分级知识库+向量库)」 + 「互补式多路召回」 + 「知识图谱语义关联」 + 「医疗专属重排序」
一、第一步:夯实精准检索底座(召回准确率的基础)
召回的核心是“找对范围、找对内容”,这一步要把之前搭建的分级知识库、向量库、切片做「召回友好型优化」,从源头减少无关召回/漏召回。
1. 分级知识库与检索范围的强绑定(缩小检索范围,杜绝无关召回)
基于你之前设计的「一级→二级→三级」分级知识库,结合意图识别+Query改写,精准限定检索范围(医疗场景最核心的召回优化手段):
执行逻辑:
用户Query → Query改写(标准化+step-back) → 意图识别(如“孕晚期宫缩科普”) → 直接定位到「孕期健康→孕晚期护理→孕晚期宫缩」三级库 → 仅在该三级库内检索,不跨库、不全局检索。
落地细节:
- 为每个三级库设置「唯一检索标签」(如“孕期-孕晚期-宫缩”),意图识别结果直接映射该标签;
- 禁止“跨三级库检索”(如搜“宫缩”绝不检索“高血压”三级库),避免无关内容召回;
- 若意图识别置信度<80%,仅扩大到二级库(而非一级库),平衡精准度与召回率。
2. 向量库的精细化优化(提升语义匹配精准度)
医疗术语的语义匹配是召回的核心,需对向量库做3个关键优化:
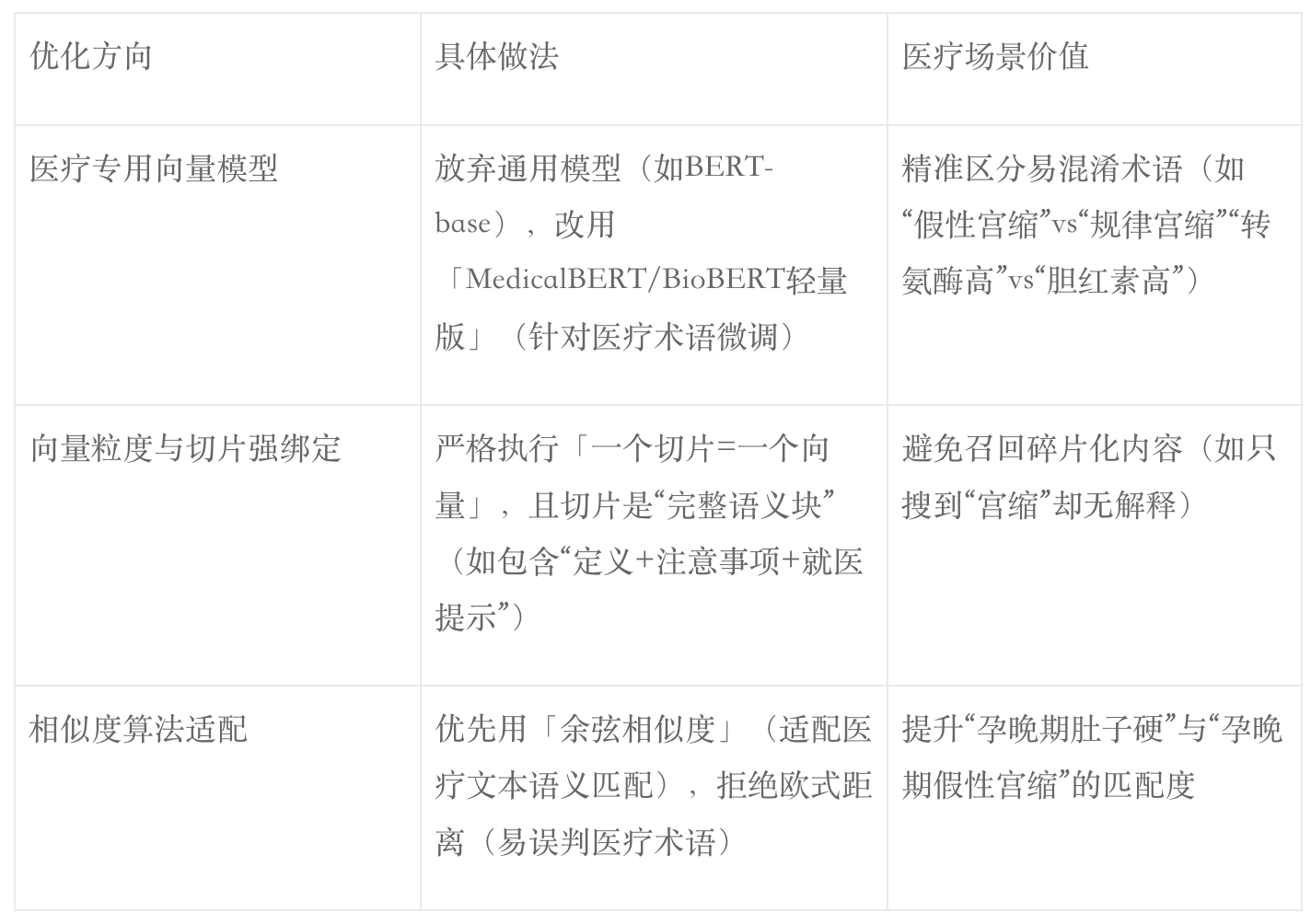
3. 切片的“召回友好型”设计(提升召回完整性)
切片不仅要语义完整,还要适配检索规则,补充2个设计:
- 核心关键词标引:每个切片手动标注3-5个核心关键词(与Query改写后的标准关键词对齐),如切片“孕晚期假性宫缩”标注:孕晚期、假性宫缩、腹部发紧、生理现象;
- 关联标签标注:为相关切片标注关联标签(如“孕晚期宫缩”与“孕晚期见红”标注同一关联标签),便于后续知识图谱关联召回;
- 合规过滤标签:标注“权威来源/通用科普/本地化内容”,便于后续重排序优先召回权威内容。
二、第二步:设计医疗场景专属的「互补式多路召回」(避免漏召回)
多路召回不是“简单叠加多个检索结果”,而是「用不同检索方式覆盖不同用户提问场景」,医疗场景仅需3条互补路径(避免冗余),且有明确优先级:
1. 核心路径:医疗向量召回(适配“语义相似”的口语化提问)
适用场景:用户用口语/倒装句提问(如“孕晚期晚上肚子硬邦邦的正常吗”);
执行流程:
Query改写(标准化+step-back)→ 转为医疗向量 → 检索对应三级库的向量子集 → 召回相似度Top3的切片;
优化点:
- Query向量生成前,先做“医疗术语标准化”(如“肚子硬”→“假性宫缩”),保证与切片向量在同一语义空间;
- 相似度阈值设为≥0.7(医疗场景严格阈值,避免召回低相似内容)。
2. 兜底路径:医疗关键词召回(适配“精准术语”提问)
适用场景:用户用标准医疗术语提问(如“孕晚期假性宫缩的注意事项”);
执行流程:
从改写后的Query中提取核心关键词(如“孕晚期、假性宫缩、注意事项”)→ 检索切片的关键词标引 → 召回完全匹配≥2个关键词的切片;
优化点:
- 关键词仅用「医疗标准术语」(基于你的《医疗口语-标准词映射表》);
- 禁止“模糊匹配”(如“宫缩”不匹配“分娩宫缩”),避免错召回。
3. 规则路径:意图-知识库绑定召回(适配“明确场景”提问)
适用场景:用户提问场景明确(如“本地产检预约流程”);
执行流程:
意图识别为“本地化-产检预约” → 直接召回「就医引导→产检流程→本地产检预约」三级库的所有切片(仅Top2);
优化点:
- 仅针对“本地化/就医流程/医保政策”等场景使用,避免滥用;
- 召回结果必须是“权威本地化内容”(如本地卫健委发布的流程)。
4. 多路召回结果的初步过滤(医疗红线)
所有召回结果先经过2道过滤,再进入融合:
- 合规过滤:剔除含“诊断/治疗/用药剂量”的切片;
- 权威过滤:优先保留“国家卫健委/三甲医院”来源的切片,淘汰非权威内容。
三、第三步:引入医疗知识图谱做「语义关联召回」(补全核心内容,避免漏召回)
医疗知识图谱不是“复杂诊疗图谱”,而是「轻量化科普知识图谱」,核心作用是“补全关联内容、过滤错误关联”,提升召回的完整性与准确性。
1. 医疗轻量化知识图谱的构建(适配科普场景,不做复杂设计)
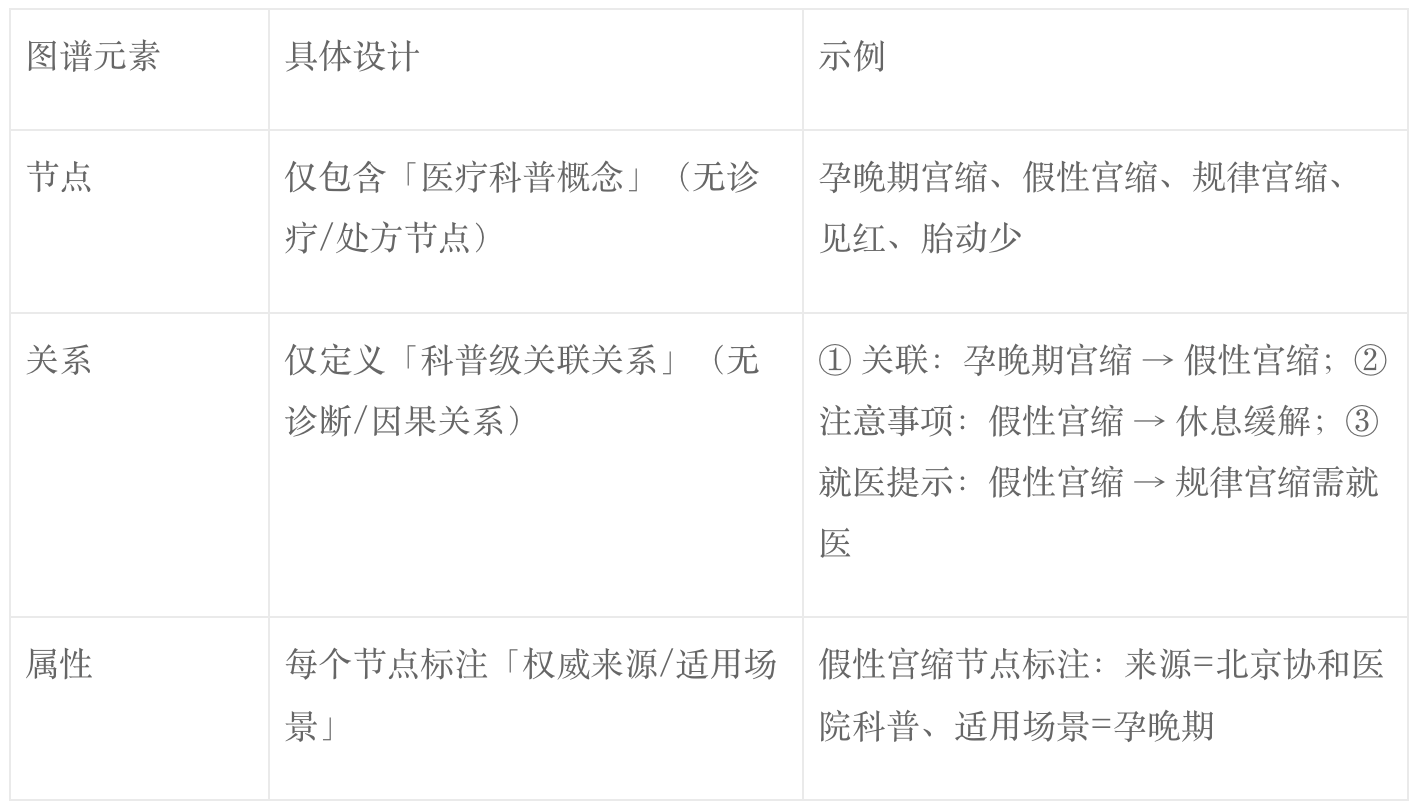
2. 知识图谱辅助召回的2个核心作用
作用1:关联补全(避免漏召回核心关联内容)
执行逻辑:多路召回得到“孕晚期假性宫缩”切片 → 知识图谱检索“假性宫缩”的关联节点(如“规律宫缩”“见红”) → 补充召回“规律宫缩的就医提示”切片;
价值:用户问“假性宫缩”,系统不仅召回假性宫缩的内容,还补全“如何区分假性宫缩和规律宫缩”的核心内容,避免漏召回关键就医提示。
作用2:错误关联过滤(避免错召回无关内容)
执行逻辑:多路召回若误召回“分娩宫缩”切片 → 知识图谱校验“分娩宫缩”与“孕晚期假性宫缩”无科普关联 → 过滤该切片;
价值:杜绝“宫缩”相关的无关内容(如分娩、流产)被召回,保证精准度。
3. 知识图谱与多路召回的融合方式(不增加复杂度)

关键:知识图谱仅“补全Top1关联切片、过滤错误切片”,不召回过多内容(避免冗余,浪费Token)。
四、第四步:医疗专属的召回结果重排序(保证优质内容在前)
融合后的召回结果池(通常3-5个切片),需按医疗场景的优先级重排序,确保“最权威、最贴合、最合规”的内容排在前面:
1. 重排序的核心维度(按优先级排序)
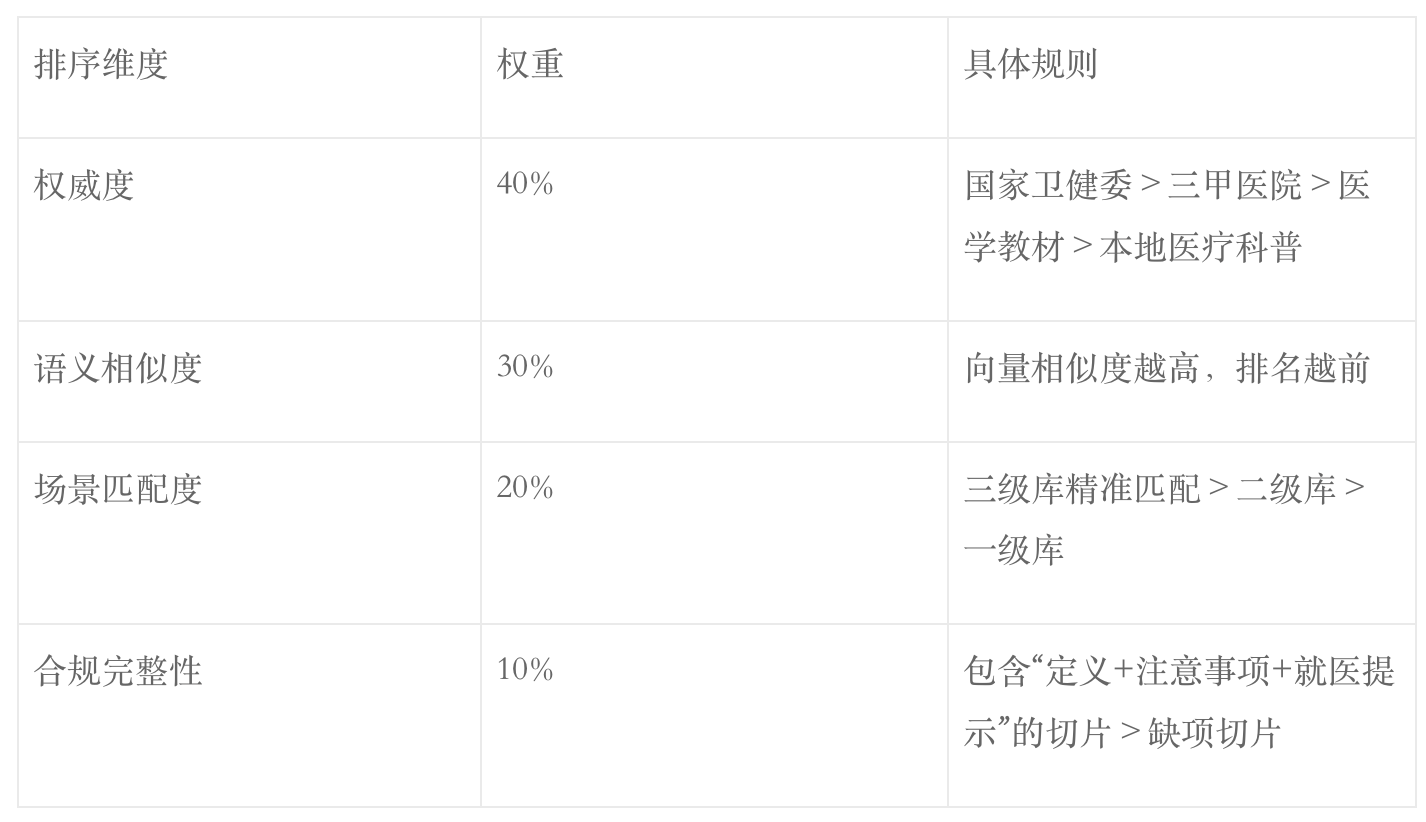
2. 重排序执行方式(轻量、可落地)
优先用「规则式重排序」(无需复杂模型,医疗场景足够):
- 先筛选出“权威度≥三甲医院”的切片;
- 在权威切片中,按语义相似度排序;
- 最后校验场景匹配度,调整顺序;
进阶(规模化后):用「医疗轻量排序模型」(如MedicalBERT微调),输入“Query+切片”,输出排序分数。
五、完整执行流程(串联所有环节)
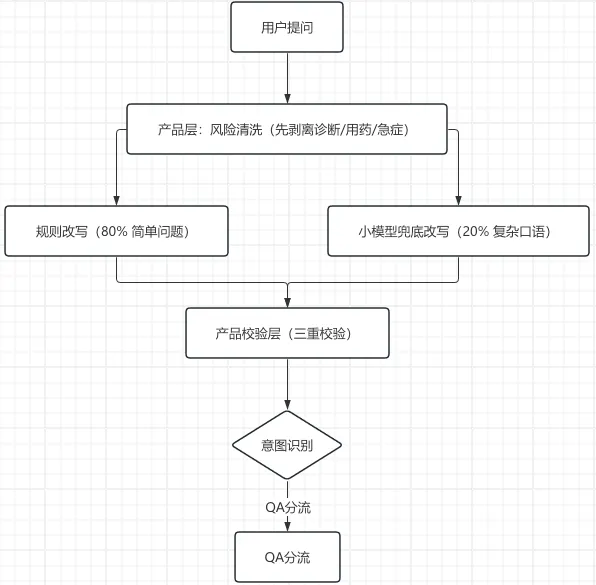
六、医疗场景召回优化的避坑点(面试加分)
- ❌ 避免“为了召回率盲目扩大检索范围”:医疗场景“精准>全量”,宁可少召回也不错召回违规/无关内容;
- ❌ 避免知识图谱过度复杂:仅做科普级关联,不构建“病因/诊疗”关系(易越界);
- ❌ 避免多路召回结果叠加过多:最终仅保留Top2-3切片(多了会导致模型乱编,浪费Token);
- ✅ 必须保留“召回结果可追溯”:记录每个切片的召回路径(向量/关键词/规则),便于后续分析漏召回/错召回原因。
总结
- 医疗RAG召回的核心是“精准范围+精准匹配”,分级知识库绑定意图识别是最基础也最有效的手段;
- 多路召回需“互补而非冗余”,仅保留向量、关键词、规则3条路径,避免增加复杂度;
- 知识图谱仅做轻量化科普关联,核心是补全关键内容、过滤错误关联,不越界;
- 重排序优先“权威度”,医疗场景下“内容权威”比“语义相似”更重要。
本文由 @而立与拾遗 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


